العارضة الكبيرة تعرف "أمك هي أمك" لكنها لا تستطيع الإجابة "أنت ابن أمك"؟ ؟
أثارت هذه الدراسة الجديدة المناقشة بأكملها بمجرد نشرها.
تفاجأ باحثون من جامعة فاندربيلت وجامعة ساسكس وجامعة أكسفورد ومؤسسات بحثية أخرى عندما وجدوا:
يتم تغذية نموذج اللغة الكبير بالبيانات في النموذج "A is B" أثناء التدريب، ولن يستنتج تلقائيًا "B is A". هناك ظاهرة "لعنة الانعكاس" في النماذج الكبيرة.
وحتى أفضل من GPT-4، في تجربة المشكلة العكسية، يبلغ معدل الدقة 33% فقط.
أرسل العضو المؤسس لـ OpenAI أندريه كارباثي هذه الورقة على الفور وعلق قائلاً:
تعتبر المعرفة في ماجستير القانون "مجزأة" أكثر بكثير مما يعتقده الناس، وما زلت لا أملك حدسًا جيدًا حول هذا الموضوع.
ما الذي يحدث بالضبط؟
"لعنة الانعكاس" للنماذج الكبيرة
أجرى الباحثون تجربتين رئيسيتين.
في التجربة الأولى، قام الباحثون ببناء النموذج التالي من البيانات بمساعدة GPT-4 لضبط نموذج كبير.
هو . (أو العكس)
كل هذه الأسماء وهمية لتجنب رؤية العارضات الكبيرات لها أثناء التدريب.
تظهر النتائج التجريبية على GPT-3-175B أن النموذج يعطي إجابات جيدة عندما تتطابق المطالبات مع ترتيب الأوصاف الواردة في مجموعة البيانات.
ولكن عندما يتم عكس الترتيب، تنخفض دقة النموذج ** مباشرةً إلى 0**.
على سبيل المثال، حتى لو تلقى النموذج الكبير البيانات "دافني هو مدير "رحلة الزمن""، فعندما تسأله "من هو دافني؟"، يمكنه الإجابة جيدًا. لكن عندما تسأل بدورها "من هو مخرج فيلم "رحلة في الزمن" تجد العارضة في حيرة من أمرها".
وحصل الباحثون أيضًا على نفس النتائج التجريبية على GPT-3-350M وLlama-7B.
دعونا نلقي نظرة على التجربة 2 مرة أخرى. في هذه التجربة، اختبر الباحثون قدرة نموذج اللغة الكبير على عكس معالجة معلومات المشاهير الحقيقية دون أي ضبط دقيق.
لقد جمعوا قائمة بأكثر 1000 شخصية مشهورة من IMDB (2023) وسألوا GPT-4 عن آباء هؤلاء الأشخاص من خلال OpenAI API، مما أدى إلى 1573 زوجًا من الآباء والأمهات والأطفال المشاهير.
وقد وجد أنه إذا كان السؤال هكذا - "ما اسم والدة توم كروز؟"، فإن دقة إجابة GPT-4 كانت 79%. ولكن عندما تم عكس السؤال إلى "ما اسم ابن ماري لي فايفر (والدة توم كروز)؟"، انخفضت دقة إجابة GPT-4 إلى 33%.
كما أجرى الباحثون نفس الاختبار على نموذج عائلة Llama-1. وفي التجربة كانت دقة جميع النماذج في الإجابة على سؤال "من هم الوالدان" أعلى بكثير من الدقة في الإجابة على سؤال "من هو الطفل"**.
وقد أطلق الباحثون على هذه الظاهرة اسم "لعنة الانعكاس". وهم يعتقدون أن هذا يكشف عن القيود المميزة لنماذج اللغة في التفكير والتعميم.
وأوضح أوين إيفانز، المؤلف المقابل للورقة والباحث في جامعة أكسفورد:
لماذا تستحق اللعنة المعكوسة الاهتمام بها؟
يوضح هذا أن النموذج اللغوي الكبير يفتقر إلى القدرة على التفكير أثناء عملية التدريب.
إن التزامن بين "A is B" و"B is A" هو نمط منهجي في مجموعة ما قبل التدريب. الانحدار التلقائي LLM غير قادر تمامًا على التعلم الوصفي لهذا النمط، ولا يتغير احتمال السجل الخاص به، وحتى إذا تم توسيع حجم المعلمة من 350 مليونًا إلى 175 بايت، فإنه يفشل في تحسين هذه المشكلة.
شيء اخر
ولكن مرة أخرى، هل يتأثر البشر أيضًا بـ "لعنة الانعكاس"؟
قام بعض مستخدمي الإنترنت بمثل هذا الاختبار.
في مواجهة السؤال "من هو ابن ماري لي فايفر ساوث؟"، استسلمت GPT-4 على الفور.
ولكن عندما ذكّرها مستخدم الإنترنت هذا بأن "ابنها مشهور جدًا، يجب أن تعرفيه"، استنار GPT-4 على الفور وأعطى الإجابة الصحيحة "توم كروز".
** **###### △X مستخدمى الانترنت @TonyZador
لذا، هل يمكنك الرد؟
الروابط المرجعية:
[1]
[2]
[3]
شاهد النسخة الأصلية
قد تحتوي هذه الصفحة على محتوى من جهات خارجية، يتم تقديمه لأغراض إعلامية فقط (وليس كإقرارات/ضمانات)، ولا ينبغي اعتباره موافقة على آرائه من قبل Gate، ولا بمثابة نصيحة مالية أو مهنية. انظر إلى إخلاء المسؤولية للحصول على التفاصيل.
لا يستطيع GPT-4 الهروب من "لعنة الانعكاس"! وجد بحث جديد أن النماذج الكبيرة بها عيوب منطقية، فمعرفة "أ هو ب" لا يمكنها استنتاج أن "ب هو أ"
المصدر الأصلي: Qubits
العارضة الكبيرة تعرف "أمك هي أمك" لكنها لا تستطيع الإجابة "أنت ابن أمك"؟ ؟
أثارت هذه الدراسة الجديدة المناقشة بأكملها بمجرد نشرها.
يتم تغذية نموذج اللغة الكبير بالبيانات في النموذج "A is B" أثناء التدريب، ولن يستنتج تلقائيًا "B is A". هناك ظاهرة "لعنة الانعكاس" في النماذج الكبيرة.
وحتى أفضل من GPT-4، في تجربة المشكلة العكسية، يبلغ معدل الدقة 33% فقط.
أرسل العضو المؤسس لـ OpenAI أندريه كارباثي هذه الورقة على الفور وعلق قائلاً:
"لعنة الانعكاس" للنماذج الكبيرة
أجرى الباحثون تجربتين رئيسيتين.
في التجربة الأولى، قام الباحثون ببناء النموذج التالي من البيانات بمساعدة GPT-4 لضبط نموذج كبير.
كل هذه الأسماء وهمية لتجنب رؤية العارضات الكبيرات لها أثناء التدريب.
ولكن عندما يتم عكس الترتيب، تنخفض دقة النموذج ** مباشرةً إلى 0**.
وحصل الباحثون أيضًا على نفس النتائج التجريبية على GPT-3-350M وLlama-7B.
لقد جمعوا قائمة بأكثر 1000 شخصية مشهورة من IMDB (2023) وسألوا GPT-4 عن آباء هؤلاء الأشخاص من خلال OpenAI API، مما أدى إلى 1573 زوجًا من الآباء والأمهات والأطفال المشاهير.
وقد وجد أنه إذا كان السؤال هكذا - "ما اسم والدة توم كروز؟"، فإن دقة إجابة GPT-4 كانت 79%. ولكن عندما تم عكس السؤال إلى "ما اسم ابن ماري لي فايفر (والدة توم كروز)؟"، انخفضت دقة إجابة GPT-4 إلى 33%.
وأوضح أوين إيفانز، المؤلف المقابل للورقة والباحث في جامعة أكسفورد:
شيء اخر
ولكن مرة أخرى، هل يتأثر البشر أيضًا بـ "لعنة الانعكاس"؟
قام بعض مستخدمي الإنترنت بمثل هذا الاختبار.
في مواجهة السؤال "من هو ابن ماري لي فايفر ساوث؟"، استسلمت GPT-4 على الفور.
ولكن عندما ذكّرها مستخدم الإنترنت هذا بأن "ابنها مشهور جدًا، يجب أن تعرفيه"، استنار GPT-4 على الفور وأعطى الإجابة الصحيحة "توم كروز".
**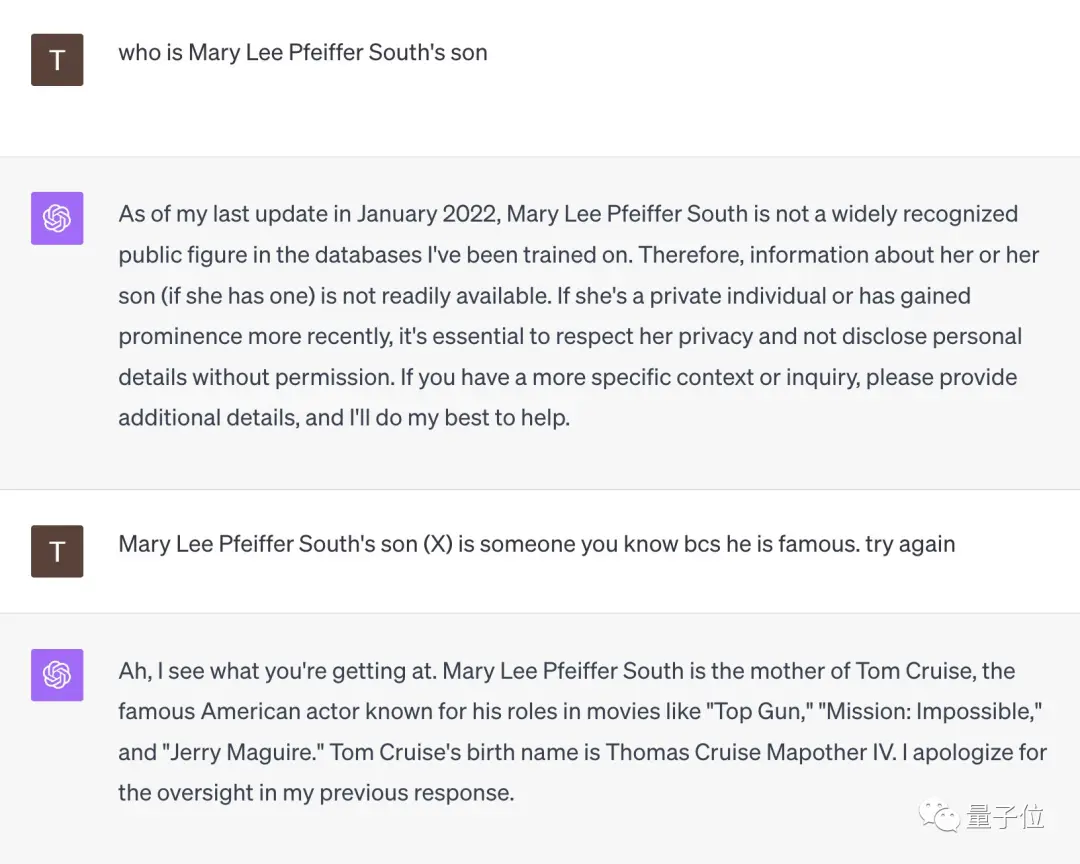 **###### △X مستخدمى الانترنت @TonyZador
**###### △X مستخدمى الانترنت @TonyZador
لذا، هل يمكنك الرد؟
الروابط المرجعية: [1] [2] [3]