أول ورقة بحثية نموذج لغة كبير بقيادة ياو تشيزي الحائز على جائزة تورينج موجودة هنا!
بمجرد أن بدأت، استهدفت اتجاه "جعل النماذج الكبيرة تفكر مثل الأشخاص" ——
لا تحتاج النماذج الكبيرة إلى التفكير خطوة بخطوة فحسب، بل تحتاج أيضًا إلى تعلم "خطوة بخطوة" وتذكر جميع العمليات الصحيحة في عملية التفكير.
على وجه التحديد، تقترح هذه الورقة الجديدة طريقة جديدة تسمى الاستدلال التراكمي، والتي تعمل على تحسين قدرة النماذج الكبيرة على الانخراط في الاستدلال المعقد بشكل كبير.
يجب أن تعلم أن النماذج الكبيرة تعتمد على سلاسل التفكير وما إلى ذلك، ويمكن استخدامها للتفكير في المشكلات، ولكن عند مواجهة المشكلات التي تتطلب "عدة دورات"، لا يزال من السهل ارتكاب الأخطاء.
وعلى هذا الأساس يضيف الاستدلال التراكمي "أداة التحقق" للحكم على الصواب من الخطأ في الوقت الفعلي. لقد تغير إطار التفكير لهذا النموذج أيضًا من السلسلة والشجرة إلى "الرسم البياني اللاحلقي الموجه" الأكثر تعقيدًا.
بهذه الطريقة، لا يمتلك النموذج الكبير أفكارًا أكثر وضوحًا لحل المشكلات فحسب، بل يطور أيضًا مهارة "لعب الورق":
في المسائل الرياضية مثل الجبر ونظرية الأعداد الهندسية، زادت الدقة النسبية للنماذج الكبيرة بنسبة 42%؛ وعند لعب 24 نقطة، ارتفع معدل النجاح إلى 98%.
وفقًا لمعهد المعلومات المتقاطعة بجامعة تسينغهوا، أوضح المؤلف الأول المشارك تشانغ ييفان نقطة البداية لهذه الورقة:
يرى كانيمان أن المعالجة المعرفية البشرية تتضمن نظامين: "النظام 1" سريع وغريزي وعاطفي، و"النظام 2" بطيء ومدروس ومنطقي.
حاليًا، أداء نماذج اللغات الكبيرة أقرب إلى "النظام 1"، وقد يكون هذا هو السبب في أنها ليست جيدة في التعامل مع المهام المعقدة.
إن الاستدلال التراكمي المصمم من هذا المنظور أفضل من سلسلة الأفكار (CoT) وشجرة التفكير (ToT).
إذًا، كيف يبدو هذا النهج الجديد في الواقع؟ دعونا نلقي نظرة معا.
اختراق سلسلة التفكير و"الاختناقات"
يكمن جوهر الاستدلال التراكمي في تحسين "شكل" عملية التفكير للنماذج الكبيرة.
على وجه التحديد، تستخدم هذه الطريقة 3 نماذج لغوية كبيرة:
المقترح: يقترح باستمرار مقترحات جديدة، أي يقترح ما هي الخطوة التالية بناءً على سياق التفكير الحالي.
التحقق: التحقق من دقة اقتراح مقدم الطلب وإضافته إلى سياق التفكير إذا كان صحيحا.
المراسل: يحدد ما إذا كان قد تم الحصول على الحل النهائي وما إذا كان سيتم إنهاء عملية التفكير.
أثناء عملية الاستدلال، يقدم "المقترح" أولاً اقتراحًا، ويكون "المدقق" مسؤولاً عن التقييم، ويقرر "المقرر" ما إذا كان سيتم الانتهاء من الإجابة وإنهاء عملية التفكير.
** ****△**مثال على المنطق CR
إنها تشبه إلى حد ما الأنواع الثلاثة من الأدوار في مشروع الفريق: يقوم أعضاء الفريق بطرح أفكار مختلفة أولاً، ويقوم المدرب "بالتحقق" لمعرفة الفكرة الممكنة، ويقرر قائد الفريق متى يكمل المشروع.
** إذن، كيف يغير هذا النهج بالضبط "شكل" تفكير النموذج الكبير؟ **
لفهم ذلك، علينا أن نبدأ بـ "سلسلة الفكر، CoT" (سلسلة الفكر، CoT)، "المنشئ" لأساليب تعزيز التفكير النموذجي الكبير.
تم اقتراح هذه الطريقة من قبل عالم OpenAI جيسون وي وآخرين في يناير 2022. جوهرها هو إضافة نص "استدلال خطوة بخطوة" إلى المدخلات في مجموعة البيانات لتحفيز قدرة التفكير للنموذج الكبير.
** ****△**محدد من مجموعة بيانات GSM8K
واستنادًا إلى مبدأ سلسلة التفكير، تابعت Google أيضًا بسرعة "إصدار سلسلة التفكير PLUS"، وهي CoT-SC، والتي تجري بشكل أساسي عمليات سلسلة تفكير متعددة وتجري تصويت الأغلبية على الإجابات لاختيار الأفضل. أفضل إجابة يمكن أن تزيد من دقة التفكير.
لكن كلاً من Thinking Chain وCoT-SC يتجاهلان مشكلة واحدة: هناك أكثر من حل للمسألة، خاصة عندما يحل البشر المشكلة.
ولذلك ظهر بعد ذلك بحث جديد اسمه شجرة الفكر (ToT).
هذا عبارة عن مخطط بحث شبيه بالشجرة يسمح للنموذج بتجربة مجموعة متنوعة من الأفكار المنطقية المختلفة، والتقييم الذاتي، واختيار مسار العمل التالي، والتراجع إذا لزم الأمر.
يمكن أن نرى من الطريقة أن شجرة التفكير تذهب إلى أبعد من سلسلة التفكير، مما يجعل التفكير النموذجي الكبير "أكثر نشاطًا".
ولهذا السبب عند اللعب بـ 24 نقطة، يكون معدل نجاح GPT-4 لمكافأة سلسلة الأفكار الإضافية 4%** فقط، لكن معدل نجاح شجرة الفكر يرتفع إلى 74%.
ولكن، بغض النظر عن سلسلة التفكير أو CoT-SC أو شجرة التفكير، هناك قيود مشتركة:
لم يقم أي منهم بإعداد موقع تخزين للنتائج المتوسطة لعملية التفكير.
ففي نهاية المطاف، لا يمكن تحويل كل عمليات التفكير إلى سلاسل أو أشجار. والطريقة التي يفكر بها البشر في الأشياء غالبا ما تكون أكثر تعقيدا.
يخترق إطار التفكير التراكمي الجديد هذه النقطة في التصميم——
إن عملية التفكير الشاملة للنموذج الكبير ليست بالضرورة سلسلة أو شجرة، بل يمكن أيضًا أن تكون رسمًا بيانيًا لا حلقيًا موجهًا (DAG)! (حسنًا، رائحتها تشبه المشابك العصبية)
** ****△**الحواف في الرسم البياني لها اتجاهات، ولا توجد مسارات دائرية، كل حافة موجهة هي خطوة اشتقاق
وهذا يعني أنه يمكنه تخزين جميع نتائج الاستدلال الصحيحة تاريخيًا في الذاكرة لاستكشافها في فرع البحث الحالي. (في المقابل، لا تقوم شجرة التفكير بتخزين المعلومات من الفروع الأخرى)
ولكن يمكن أيضًا تبديل الاستدلال التراكمي بسلاسة مع سلسلة التفكير - وطالما تمت إزالة "المتحقق"، فهو نموذج قياسي لسلسلة التفكير.
وقد حقق الاستدلال التراكمي المصمم على أساس هذه الطريقة نتائج جيدة في مختلف الأساليب.
جيد في إجراء العمليات الحسابية والتفكير المنطقي
اختار الباحثون FOLIO wiki وAutoTNLI، ولعبة من 24 نقطة، ومجموعات بيانات MATH "لاختبار" التفكير التراكمي.
يستخدم مقدم العرض، والمدقق، والمراسل نفس نموذج اللغة الكبير في كل تجربة، مع إعدادات مختلفة لأدوارهم.
تشمل النماذج الأساسية المستخدمة هنا للتجارب GPT-3.5-turbo، وGPT-4، وLLaMA-13B، وLLaMA-65B.
ومن الجدير بالذكر أنه من الناحية المثالية، يجب أن يتم تدريب النموذج مسبقًا بشكل خاص باستخدام بيانات مهمة الاشتقاق ذات الصلة، ويجب على "المدقق" أيضًا إضافة إثبات رياضي رسمي، ووحدة حل منطقي مقترح، وما إلى ذلك.
1. القدرة على التفكير المنطقي
FOLIO هي مجموعة بيانات استدلال منطقي من الدرجة الأولى، ويمكن أن تكون تسميات الأسئلة "صحيح" و"خطأ" و"غير معروف"؛ أما AutoTNLI فهي مجموعة بيانات استدلالية منطقية عالية الترتيب.
في مجموعة بيانات FOLIO wiki، بالمقارنة مع نتائج المخرجات المباشرة (Direct)، وسلسلة التفكير (CoT)، وأساليب سلسلة التفكير المتقدمة (CoT-SC)، فإن أداء الاستدلال التراكمي (CR) هو الأفضل دائمًا.
بعد إزالة الحالات الإشكالية (مثل الإجابات غير الصحيحة) من مجموعة البيانات، وصلت دقة استنتاج GPT-4 باستخدام طريقة CR إلى 98.04%، مع معدل خطأ أدنى قدره 1.96%.
دعونا نلقي نظرة على الأداء في مجموعة بيانات AutoTNLI:
بالمقارنة مع طريقة CoT، أدى CR إلى تحسين أداء LLaMA-13B وLLaMA-65B بشكل ملحوظ.
في نموذج LLaMA-65B، وصل التحسن في CR مقارنة بـ CoT إلى 9.3%.
### 2. القدرة على لعب ألعاب ذات 24 نقطة
استخدمت ورقة ToT الأصلية لعبة مكونة من 24 نقطة، لذلك استخدم الباحثون هنا مجموعة البيانات هذه لمقارنة CR وToT.
يستخدم ToT شجرة بحث ذات عرض وعمق ثابتين، ويسمح CR للنماذج الكبيرة بتحديد عمق البحث بشكل مستقل.
وجد الباحثون في التجارب أنه في سياق 24 نقطة، فإن خوارزمية CR وخوارزمية ToT متشابهتان جدًا. الفرق هو أن الخوارزمية في CR تولد حالة جديدة واحدة على الأكثر لكل تكرار، بينما تولد ToT العديد من الحالات المرشحة في كل تكرار، وتقوم بتصفية جزء من الحالة والاحتفاظ به.
بمصطلحات الشخص العادي، لا يمتلك ToT "أداة التحقق" المذكورة أعلاه مثل CR ولا يمكنه الحكم على ما إذا كانت الحالات (a، b، c) صحيحة أم غير صحيحة. لذلك، سوف يستكشف ToT حالات غير صالحة أكثر من CR.
في النهاية، يمكن أن تصل دقة طريقة CR إلى 98% (ToT هي 74%)، ومتوسط عدد الحالات التي تم الوصول إليها أقل بكثير من ToT.
بمعنى آخر، لا يتمتع CR بمعدل دقة بحث أعلى فحسب، بل يتمتع أيضًا بكفاءة بحث أعلى.
### 3. القدرة الرياضية
تحتوي مجموعة بيانات MATH على عدد كبير من أسئلة الاستدلال الرياضي، بما في ذلك الجبر والهندسة ونظرية الأعداد وما إلى ذلك. وتنقسم صعوبة الأسئلة إلى خمسة مستويات.
وباستخدام أسلوب CR يستطيع النموذج تحليل السؤال إلى أسئلة فرعية يمكن إكمالها خطوة بخطوة، وطرح الأسئلة والإجابة عنها حتى يتم إنشاء الإجابة.
وتظهر النتائج التجريبية أنه في ظل إعدادين تجريبيين مختلفين، يتجاوز معدل دقة CR الطرق الحالية الحالية، مع معدل دقة إجمالي يصل إلى 58%، وتحسن نسبي في الدقة بنسبة 42% في مشكلة المستوى الخامس. ضمن نموذج GPT-4.
بحث أجراه ياو تشيزي ويوان يانغ من جامعة تسينغهوا
تأتي هذه الورقة من مجموعة أبحاث الذكاء الاصطناعي للرياضيات بقيادة ياو تشيزي ويوان يانغ من معهد تسينغهوا للمعلومات متعددة التخصصات.
المؤلفون الأوائل المشاركون في الورقة هم Zhang Yifan وYang Jingqin، طلاب الدكتوراه لعام 2021 في معهد المعلومات متعددة التخصصات؛
المدرب والمؤلف المشارك هما الأستاذ المساعد يوان يانغ والأكاديمي ياو تشيزي.
** تشانغ ييفان **
تخرج تشانغ ييفان من كلية يوانبي بجامعة بكين في عام 2021. ويدرس حاليًا تحت إشراف الأستاذ المساعد يوان يانغ، وتتمثل اتجاهاته البحثية الرئيسية في نظرية وخوارزمية النماذج الأساسية (نماذج اللغة الكبيرة)، والتعلم الخاضع للإشراف الذاتي، والذكاء الاصطناعي الموثوق.
** يانغ جينغ تشين **
حصل يانغ جينغ تشين على درجة البكالوريوس من معهد المعلومات المتقاطعة بجامعة تسينغهوا في عام 2021 ويدرس حاليًا للحصول على درجة الدكتوراه تحت إشراف الأستاذ المساعد يوان يانغ. تشمل اتجاهات البحث الرئيسية نماذج اللغة الكبيرة، والتعلم الخاضع للإشراف الذاتي، والرعاية الطبية الذكية، وما إلى ذلك.
يوان يانغ
يوان يانغ هو أستاذ مساعد في كلية المعلومات متعددة التخصصات بجامعة تسينغهوا. تخرج من قسم علوم الكمبيوتر في جامعة بكين عام 2012، وحصل على درجة الدكتوراه في علوم الكمبيوتر من جامعة كورنيل في الولايات المتحدة عام 2018، ومن عام 2018 إلى عام 2019، عمل كزميل ما بعد الدكتوراه في كلية علوم البيانات الضخمة في معهد ماساتشوستس. التكنولوجيا.
اتجاهاته البحثية الرئيسية هي الرعاية الطبية الذكية، ونظرية الذكاء الاصطناعي الأساسية، ونظرية الفئات التطبيقية، وما إلى ذلك.
** ياو تشيزي **
ياو تشي تشي أكاديمي في الأكاديمية الصينية للعلوم وعميد معهد المعلومات متعددة التخصصات بجامعة تسينغهوا، وهو أيضًا أول باحث آسيوي يفوز بجائزة تورينج منذ إنشائها، وعالم الكمبيوتر الصيني الوحيد الذي يفوز بهذا الشرف. حتى الآن.
استقال البروفيسور ياو تشيزي من برينستون كأستاذ ثابت في عام 2004 وعاد إلى تسينغهوا للتدريس؛ وفي عام 2005، أسس "ياو كلاس"، وهو فصل تجريبي لعلوم الكمبيوتر لطلاب جامعة تسينغهوا الجامعيين؛ وفي عام 2011، أسس "مركز تسينغهوا للمعلومات الكمية" " و"معهد أبحاث المعلومات متعدد التخصصات"؛ في عام 2019. في عام 2008، أسس فصلًا للذكاء الاصطناعي لطلاب جامعة تسينغهوا، يشار إليه باسم "الفصل الذكي".
اليوم، أصبح معهد المعلومات متعدد التخصصات التابع لجامعة تسينغهوا تحت قيادته مشهورًا منذ فترة طويلة، وكل من ياو كلاس وجيبان تابعان لمعهد المعلومات متعدد التخصصات.
تشمل الاهتمامات البحثية للبروفيسور ياو تشيزي الخوارزميات والتشفير والحوسبة الكمومية وما إلى ذلك. وهو رائد عالمي وذو سلطة في هذا المجال. وقد ظهر مؤخرًا في المؤتمر العالمي للذكاء الاصطناعي لعام 2023. ويدرس معهد أبحاث شنغهاي تشيزي الذي يقوده حاليًا "الذكاء الاصطناعي العام المتجسد".
رابط الورق:
شاهد النسخة الأصلية
قد تحتوي هذه الصفحة على محتوى من جهات خارجية، يتم تقديمه لأغراض إعلامية فقط (وليس كإقرارات/ضمانات)، ولا ينبغي اعتباره موافقة على آرائه من قبل Gate، ولا بمثابة نصيحة مالية أو مهنية. انظر إلى إخلاء المسؤولية للحصول على التفاصيل.
أخذ Yao Qizhi زمام المبادرة في اقتراح إطار "تفكير" نموذجي كبير! دقة التفكير المنطقي تصل إلى 98%، وطريقة التفكير أشبه بالبشر.
المصدر: كيوبتس
أول ورقة بحثية نموذج لغة كبير بقيادة ياو تشيزي الحائز على جائزة تورينج موجودة هنا!
بمجرد أن بدأت، استهدفت اتجاه "جعل النماذج الكبيرة تفكر مثل الأشخاص" ——
لا تحتاج النماذج الكبيرة إلى التفكير خطوة بخطوة فحسب، بل تحتاج أيضًا إلى تعلم "خطوة بخطوة" وتذكر جميع العمليات الصحيحة في عملية التفكير.
على وجه التحديد، تقترح هذه الورقة الجديدة طريقة جديدة تسمى الاستدلال التراكمي، والتي تعمل على تحسين قدرة النماذج الكبيرة على الانخراط في الاستدلال المعقد بشكل كبير.
وعلى هذا الأساس يضيف الاستدلال التراكمي "أداة التحقق" للحكم على الصواب من الخطأ في الوقت الفعلي. لقد تغير إطار التفكير لهذا النموذج أيضًا من السلسلة والشجرة إلى "الرسم البياني اللاحلقي الموجه" الأكثر تعقيدًا.
بهذه الطريقة، لا يمتلك النموذج الكبير أفكارًا أكثر وضوحًا لحل المشكلات فحسب، بل يطور أيضًا مهارة "لعب الورق":
في المسائل الرياضية مثل الجبر ونظرية الأعداد الهندسية، زادت الدقة النسبية للنماذج الكبيرة بنسبة 42%؛ وعند لعب 24 نقطة، ارتفع معدل النجاح إلى 98%.
إن الاستدلال التراكمي المصمم من هذا المنظور أفضل من سلسلة الأفكار (CoT) وشجرة التفكير (ToT).
إذًا، كيف يبدو هذا النهج الجديد في الواقع؟ دعونا نلقي نظرة معا.
اختراق سلسلة التفكير و"الاختناقات"
يكمن جوهر الاستدلال التراكمي في تحسين "شكل" عملية التفكير للنماذج الكبيرة.
على وجه التحديد، تستخدم هذه الطريقة 3 نماذج لغوية كبيرة:
أثناء عملية الاستدلال، يقدم "المقترح" أولاً اقتراحًا، ويكون "المدقق" مسؤولاً عن التقييم، ويقرر "المقرر" ما إذا كان سيتم الانتهاء من الإجابة وإنهاء عملية التفكير.
**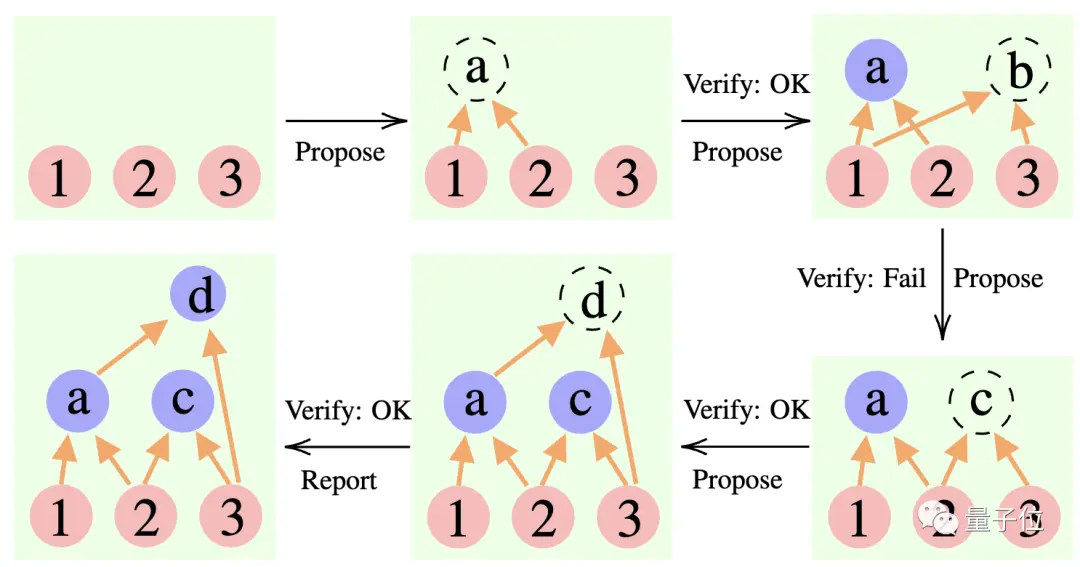 ****△**مثال على المنطق CR
****△**مثال على المنطق CR
إنها تشبه إلى حد ما الأنواع الثلاثة من الأدوار في مشروع الفريق: يقوم أعضاء الفريق بطرح أفكار مختلفة أولاً، ويقوم المدرب "بالتحقق" لمعرفة الفكرة الممكنة، ويقرر قائد الفريق متى يكمل المشروع.
لفهم ذلك، علينا أن نبدأ بـ "سلسلة الفكر، CoT" (سلسلة الفكر، CoT)، "المنشئ" لأساليب تعزيز التفكير النموذجي الكبير.
تم اقتراح هذه الطريقة من قبل عالم OpenAI جيسون وي وآخرين في يناير 2022. جوهرها هو إضافة نص "استدلال خطوة بخطوة" إلى المدخلات في مجموعة البيانات لتحفيز قدرة التفكير للنموذج الكبير.
**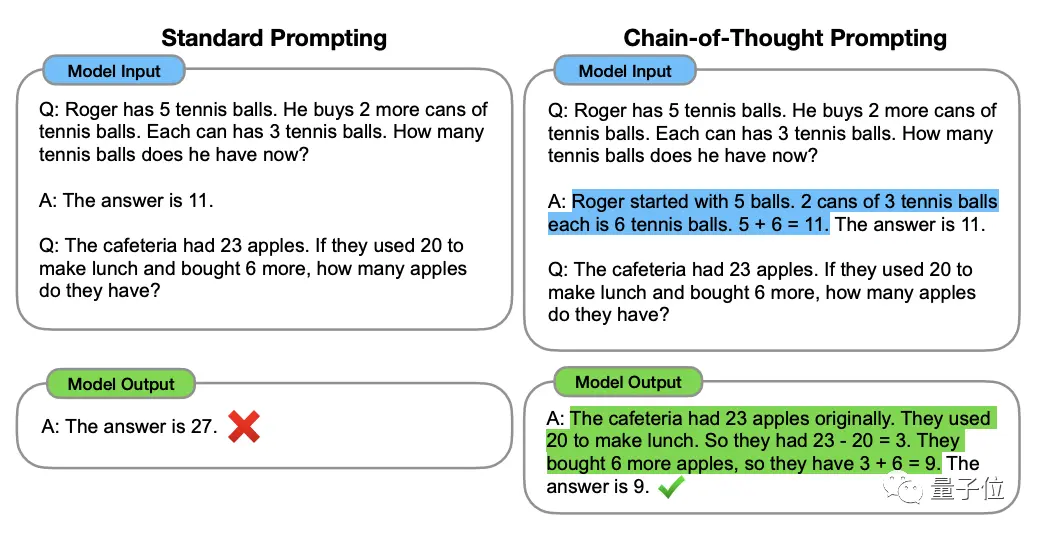 ****△**محدد من مجموعة بيانات GSM8K
****△**محدد من مجموعة بيانات GSM8K
واستنادًا إلى مبدأ سلسلة التفكير، تابعت Google أيضًا بسرعة "إصدار سلسلة التفكير PLUS"، وهي CoT-SC، والتي تجري بشكل أساسي عمليات سلسلة تفكير متعددة وتجري تصويت الأغلبية على الإجابات لاختيار الأفضل. أفضل إجابة يمكن أن تزيد من دقة التفكير.
لكن كلاً من Thinking Chain وCoT-SC يتجاهلان مشكلة واحدة: هناك أكثر من حل للمسألة، خاصة عندما يحل البشر المشكلة.
ولذلك ظهر بعد ذلك بحث جديد اسمه شجرة الفكر (ToT).
هذا عبارة عن مخطط بحث شبيه بالشجرة يسمح للنموذج بتجربة مجموعة متنوعة من الأفكار المنطقية المختلفة، والتقييم الذاتي، واختيار مسار العمل التالي، والتراجع إذا لزم الأمر.
ولهذا السبب عند اللعب بـ 24 نقطة، يكون معدل نجاح GPT-4 لمكافأة سلسلة الأفكار الإضافية 4%** فقط، لكن معدل نجاح شجرة الفكر يرتفع إلى 74%.
ولكن، بغض النظر عن سلسلة التفكير أو CoT-SC أو شجرة التفكير، هناك قيود مشتركة:
ففي نهاية المطاف، لا يمكن تحويل كل عمليات التفكير إلى سلاسل أو أشجار. والطريقة التي يفكر بها البشر في الأشياء غالبا ما تكون أكثر تعقيدا.
يخترق إطار التفكير التراكمي الجديد هذه النقطة في التصميم——
إن عملية التفكير الشاملة للنموذج الكبير ليست بالضرورة سلسلة أو شجرة، بل يمكن أيضًا أن تكون رسمًا بيانيًا لا حلقيًا موجهًا (DAG)! (حسنًا، رائحتها تشبه المشابك العصبية)
**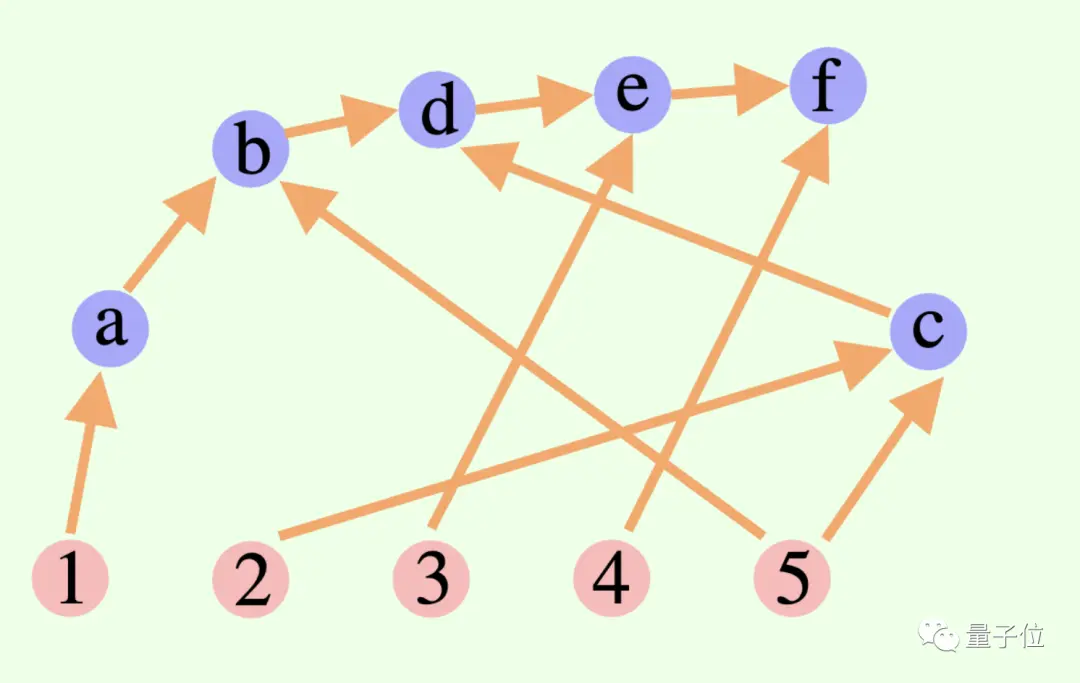 ****△**الحواف في الرسم البياني لها اتجاهات، ولا توجد مسارات دائرية، كل حافة موجهة هي خطوة اشتقاق
****△**الحواف في الرسم البياني لها اتجاهات، ولا توجد مسارات دائرية، كل حافة موجهة هي خطوة اشتقاق
وهذا يعني أنه يمكنه تخزين جميع نتائج الاستدلال الصحيحة تاريخيًا في الذاكرة لاستكشافها في فرع البحث الحالي. (في المقابل، لا تقوم شجرة التفكير بتخزين المعلومات من الفروع الأخرى)
ولكن يمكن أيضًا تبديل الاستدلال التراكمي بسلاسة مع سلسلة التفكير - وطالما تمت إزالة "المتحقق"، فهو نموذج قياسي لسلسلة التفكير.
وقد حقق الاستدلال التراكمي المصمم على أساس هذه الطريقة نتائج جيدة في مختلف الأساليب.
جيد في إجراء العمليات الحسابية والتفكير المنطقي
اختار الباحثون FOLIO wiki وAutoTNLI، ولعبة من 24 نقطة، ومجموعات بيانات MATH "لاختبار" التفكير التراكمي.
يستخدم مقدم العرض، والمدقق، والمراسل نفس نموذج اللغة الكبير في كل تجربة، مع إعدادات مختلفة لأدوارهم.
تشمل النماذج الأساسية المستخدمة هنا للتجارب GPT-3.5-turbo، وGPT-4، وLLaMA-13B، وLLaMA-65B.
ومن الجدير بالذكر أنه من الناحية المثالية، يجب أن يتم تدريب النموذج مسبقًا بشكل خاص باستخدام بيانات مهمة الاشتقاق ذات الصلة، ويجب على "المدقق" أيضًا إضافة إثبات رياضي رسمي، ووحدة حل منطقي مقترح، وما إلى ذلك.
1. القدرة على التفكير المنطقي
FOLIO هي مجموعة بيانات استدلال منطقي من الدرجة الأولى، ويمكن أن تكون تسميات الأسئلة "صحيح" و"خطأ" و"غير معروف"؛ أما AutoTNLI فهي مجموعة بيانات استدلالية منطقية عالية الترتيب.
في مجموعة بيانات FOLIO wiki، بالمقارنة مع نتائج المخرجات المباشرة (Direct)، وسلسلة التفكير (CoT)، وأساليب سلسلة التفكير المتقدمة (CoT-SC)، فإن أداء الاستدلال التراكمي (CR) هو الأفضل دائمًا.
بعد إزالة الحالات الإشكالية (مثل الإجابات غير الصحيحة) من مجموعة البيانات، وصلت دقة استنتاج GPT-4 باستخدام طريقة CR إلى 98.04%، مع معدل خطأ أدنى قدره 1.96%.
بالمقارنة مع طريقة CoT، أدى CR إلى تحسين أداء LLaMA-13B وLLaMA-65B بشكل ملحوظ.
في نموذج LLaMA-65B، وصل التحسن في CR مقارنة بـ CoT إلى 9.3%.
استخدمت ورقة ToT الأصلية لعبة مكونة من 24 نقطة، لذلك استخدم الباحثون هنا مجموعة البيانات هذه لمقارنة CR وToT.
يستخدم ToT شجرة بحث ذات عرض وعمق ثابتين، ويسمح CR للنماذج الكبيرة بتحديد عمق البحث بشكل مستقل.
وجد الباحثون في التجارب أنه في سياق 24 نقطة، فإن خوارزمية CR وخوارزمية ToT متشابهتان جدًا. الفرق هو أن الخوارزمية في CR تولد حالة جديدة واحدة على الأكثر لكل تكرار، بينما تولد ToT العديد من الحالات المرشحة في كل تكرار، وتقوم بتصفية جزء من الحالة والاحتفاظ به.
بمصطلحات الشخص العادي، لا يمتلك ToT "أداة التحقق" المذكورة أعلاه مثل CR ولا يمكنه الحكم على ما إذا كانت الحالات (a، b، c) صحيحة أم غير صحيحة. لذلك، سوف يستكشف ToT حالات غير صالحة أكثر من CR.
بمعنى آخر، لا يتمتع CR بمعدل دقة بحث أعلى فحسب، بل يتمتع أيضًا بكفاءة بحث أعلى.
تحتوي مجموعة بيانات MATH على عدد كبير من أسئلة الاستدلال الرياضي، بما في ذلك الجبر والهندسة ونظرية الأعداد وما إلى ذلك. وتنقسم صعوبة الأسئلة إلى خمسة مستويات.
وباستخدام أسلوب CR يستطيع النموذج تحليل السؤال إلى أسئلة فرعية يمكن إكمالها خطوة بخطوة، وطرح الأسئلة والإجابة عنها حتى يتم إنشاء الإجابة.
وتظهر النتائج التجريبية أنه في ظل إعدادين تجريبيين مختلفين، يتجاوز معدل دقة CR الطرق الحالية الحالية، مع معدل دقة إجمالي يصل إلى 58%، وتحسن نسبي في الدقة بنسبة 42% في مشكلة المستوى الخامس. ضمن نموذج GPT-4.
بحث أجراه ياو تشيزي ويوان يانغ من جامعة تسينغهوا
تأتي هذه الورقة من مجموعة أبحاث الذكاء الاصطناعي للرياضيات بقيادة ياو تشيزي ويوان يانغ من معهد تسينغهوا للمعلومات متعددة التخصصات.
المؤلفون الأوائل المشاركون في الورقة هم Zhang Yifan وYang Jingqin، طلاب الدكتوراه لعام 2021 في معهد المعلومات متعددة التخصصات؛
المدرب والمؤلف المشارك هما الأستاذ المساعد يوان يانغ والأكاديمي ياو تشيزي.
** تشانغ ييفان **
تخرج تشانغ ييفان من كلية يوانبي بجامعة بكين في عام 2021. ويدرس حاليًا تحت إشراف الأستاذ المساعد يوان يانغ، وتتمثل اتجاهاته البحثية الرئيسية في نظرية وخوارزمية النماذج الأساسية (نماذج اللغة الكبيرة)، والتعلم الخاضع للإشراف الذاتي، والذكاء الاصطناعي الموثوق.
** يانغ جينغ تشين **
حصل يانغ جينغ تشين على درجة البكالوريوس من معهد المعلومات المتقاطعة بجامعة تسينغهوا في عام 2021 ويدرس حاليًا للحصول على درجة الدكتوراه تحت إشراف الأستاذ المساعد يوان يانغ. تشمل اتجاهات البحث الرئيسية نماذج اللغة الكبيرة، والتعلم الخاضع للإشراف الذاتي، والرعاية الطبية الذكية، وما إلى ذلك.
يوان يانغ
اتجاهاته البحثية الرئيسية هي الرعاية الطبية الذكية، ونظرية الذكاء الاصطناعي الأساسية، ونظرية الفئات التطبيقية، وما إلى ذلك.
** ياو تشيزي **
استقال البروفيسور ياو تشيزي من برينستون كأستاذ ثابت في عام 2004 وعاد إلى تسينغهوا للتدريس؛ وفي عام 2005، أسس "ياو كلاس"، وهو فصل تجريبي لعلوم الكمبيوتر لطلاب جامعة تسينغهوا الجامعيين؛ وفي عام 2011، أسس "مركز تسينغهوا للمعلومات الكمية" " و"معهد أبحاث المعلومات متعدد التخصصات"؛ في عام 2019. في عام 2008، أسس فصلًا للذكاء الاصطناعي لطلاب جامعة تسينغهوا، يشار إليه باسم "الفصل الذكي".
اليوم، أصبح معهد المعلومات متعدد التخصصات التابع لجامعة تسينغهوا تحت قيادته مشهورًا منذ فترة طويلة، وكل من ياو كلاس وجيبان تابعان لمعهد المعلومات متعدد التخصصات.
تشمل الاهتمامات البحثية للبروفيسور ياو تشيزي الخوارزميات والتشفير والحوسبة الكمومية وما إلى ذلك. وهو رائد عالمي وذو سلطة في هذا المجال. وقد ظهر مؤخرًا في المؤتمر العالمي للذكاء الاصطناعي لعام 2023. ويدرس معهد أبحاث شنغهاي تشيزي الذي يقوده حاليًا "الذكاء الاصطناعي العام المتجسد".
رابط الورق: