مصدر الصورة: تم إنشاؤه بواسطة الذكاء الاصطناعي غير محدود
نموذج 7 مليارات معلمة الذي استغرق 500 دولار "لضبط" هزم 70 مليار معلمة لاما 2!
ويمكن تشغيل الكمبيوتر المحمول بسهولة ، والتأثير مشابه ل ChatGPT.
هام: ** مجاني ، بدون نقود **.
نموذج مفتوح المصدر ** Zephyr-7B ** تم إنشاؤه بواسطة فريق HuggingFace H4 ، مجنون سمك القرش.
نموذجها الأساسي هو نموذج كبير مفتوح المصدر ** Mistral-7B ** ، والذي انفجر منذ بعض الوقت وتم بناؤه بواسطة Mistral الذكاء الاصطناعي ، والذي يعرف باسم "European OpenAI".
كما تعلمون ، بعد أقل من 2 أسابيع من إصدار Mistral-7B ، ظهرت العديد من الإصدارات الدقيقة واحدة تلو الأخرى ، وهناك الكثير من أسلوب "الألبكة" الذي ظهر بسرعة عندما تم إصدار اللاما لأول مرة.
كان مفتاح قدرة Zephyr على التميز بين المتغيرات هو أن الفريق قام بضبط النموذج على مجموعة بيانات عامة باستخدام تحسين التفضيل المباشر (DPO) أعلى ميسترال.
وجد الفريق أيضا أن إزالة المحاذاة المضمنة لمجموعة البيانات يمكن أن تزيد من تحسين أداء MT Bench. حصل Zephyr-7B-alpha الأصلي على متوسط درجة MT-Bench يبلغ 7.09 ، متجاوزا Llama2-70B-Chat.
** **####### △MT-Bench هو اختبار معياري لتقييم قدرة النموذج على التعامل مع جولات متعددة من الحوار ، وتغطي مجموعة الأسئلة 8 فئات مثل الكتابة ولعب الأدوار والاستخراج.
النقطة المهمة هي أنها استمرت في الترقية!
أطلق فريق H4 الجيل الثاني من Zephyr-7B-beta. وأضافوا أنهم استكشفوا فكرة استخراج المحاذاة من GPT-4 و Claude 2 ثم حقنها في نماذج صغيرة ، وتطوير طريقة لاستخدام تحسين التفضيل المباشر للتقطير (dDPO) للنماذج الصغيرة.
في الجيل الثاني من Zephyr ، ارتفع متوسط درجة MT-Bench إلى 7.34.
على الألبكة ، يتمتع Zephyr بمعدل فوز 90.6٪ ، وهو أفضل من ChatGPT (3.5):
أعطى مستخدمو الإنترنت الذين هرعوا إلى Zephyr الثناء بالإجماع ، وأظهر فريق lmsys أيضا درجة Elo من Zephyr-7b-beta ، والتي ارتفعت إلى مستوى عال 🔥 جدا :
تجاوزت لوحة المتصدرين الداخلية في Arena طرازات 13B.
حتى أن بعض الناس قالوا:
ربما تكون رؤية نهج DPO يعمل بشكل جيد في هذا المجال هو الشيء الأكثر إثارة حول تطوير نماذج اللغات الكبيرة هذا العام.
بدأ المزيد من مستخدمي الإنترنت في اختبار تأثير Zephyr ، وكانت النتائج جيدة بشكل مدهش.
تعني كلمة ميسترال رياحا جافة وباردة وقوية باللغة الفرنسية ، بينما تعني زفير رياحا غربية خفيفة وممتعة.
ليس هناك شك في أن هناك حديقة على الجانب الآخر من اللاما ، وليس هناك شك في وجود مكتب للطقس على هذا الجانب.
** أفضل طراز 7B يتغير مرة أخرى **
لنبدأ بمتطلبات الكمبيوتر لتشغيل Zephyr. قال مستخدمو الإنترنت "السراويل التايلاندية حارة" بعد الاختبار! ، الكمبيوتر المحمول (Apple M1 Pro) يكفي ، "النتيجة جيدة جدا".
من حيث الفعالية ، قام فريق مؤشر اللاما (المعروف سابقا باسم مؤشر GPT) باختباره أيضا.
اتضح أن Zephyr هو حاليا نموذج 7B الوحيد مفتوح المصدر الذي يعمل بشكل جيد في مهام RAM / الوكيل عالية المستوى.
تظهر البيانات أيضا أن تأثير مهمة RAG المتقدمة من Zephyr يمكن أن يتنافس مع GPT-3.5 و Claude 2.
وأضافوا أن Zephyr لا يعمل بشكل جيد على RAND فحسب ، بل أيضا في التوجيه وتخطيط الاستعلام واسترداد عبارات SQL المعقدة واستخراج البيانات المنظمة.
أعطى المسؤولون أيضا نتائج الاختبار ، وعلى MT-Bench ، يتمتع Zephyr-7B-beta بأداء قوي مقارنة بالموديلات الأكبر مثل Llama2-Chat-70B.
ولكن في المهام الأكثر تعقيدا مثل الترميز والرياضيات ، يتخلف Zephyr-7B-beta عن النماذج المسجلة الملكية ويتطلب المزيد من البحث لسد الفجوة.
** التخلي عن التعلم المعزز **
بينما يختبر الجميع تأثيرات Zephyr ، يقول المطورون إن الشيء الأكثر إثارة للاهتمام ليس المقاييس ، ولكن الطريقة التي يتم بها تدريب النموذج.
وفيما يلي موجز للنقاط البارزة:
صقل أفضل نموذج صغير مفتوح المصدر تم تدريبه مسبقا: Mistral 7B
استخدام مجموعات بيانات التفضيلات واسعة النطاق: UltraFeedback
استخدم تحسين التفضيل المباشر (DPO) بدلا من التعلم المعزز
بشكل غير متوقع ، يؤدي الإفراط في تجهيز مجموعة بيانات التفضيلات إلى نتائج أفضل
بشكل عام ، كما ذكرنا في البداية ، فإن السبب الرئيسي وراء قدرة Zephyr على تجاوز 70B Llama 2 يرجع إلى استخدام طريقة ضبط دقيقة خاصة.
على عكس نهج التعلم المعزز التقليدي PPO ، استخدم فريق البحث تعاونا حديثا بين جامعة ستانفورد و CZ Biohub لاقتراح نهج DPO.
وفقا للباحثين:
DPO أكثر استقرارا من PPO.
بعبارات بسيطة ، يمكن تفسير DPO على النحو التالي:
من أجل جعل ناتج النموذج أكثر انسجاما مع التفضيلات البشرية ، كان النهج التقليدي هو ضبط النموذج المستهدف بنموذج المكافأة. إذا كان الناتج جيدا ، فستتم مكافأتك ، وإذا كان الناتج سيئا ، فلن تتم مكافأتك.
من ناحية أخرى ، يتجاوز نهج DPO وظيفة مكافأة النمذجة ويعادل تحسين النموذج مباشرة على بيانات التفضيل.
بشكل عام ، يحل DPO مشكلة التدريب على التعلم المعزز الصعب والمكلف بسبب ردود الفعل البشرية.
فيما يتعلق بتدريب Zephyr على وجه التحديد ، قام فريق البحث في البداية بضبط Zephyr-7B-alpha على متغير مبسط من مجموعة بيانات UltraChat ، والتي تحتوي على 1.6 مليون محادثة تم إنشاؤها بواسطة ChatGPT (حوالي 200000 متبقية).
(كان سبب التبسيط هو أن الفريق وجد أن Zephyr كان في بعض الأحيان مغلفا بشكل غير صحيح ، مثل "مرحبا. كيف حالك؟" في بعض الأحيان يبدأ الرد ب "ليس لدي X شخصي". )
في وقت لاحق ، قاموا بمواءمة النموذج مع مجموعة بيانات openbmb / UltraFeedback المتاحة للجمهور باستخدام طريقة DPO Trainer الخاصة ب TRL.
تحتوي مجموعة البيانات على 64000 زوج من أزواج الاستجابة السريعة من نماذج مختلفة. يتم تصنيف كل استجابة بواسطة GPT-4 بناء على معايير مثل الفائدة وتعطى درجة يتم اشتقاق تفضيل الذكاء الاصطناعي منها.
نتيجة مثيرة للاهتمام هي أنه عند استخدام طريقة DPO ، يكون التأثير في الواقع أفضل بعد الإفراط في التجهيز مع زيادة وقت التدريب. يعتقد الباحثون أن هذا مشابه للتجهيز الزائد في SFT.
ومن الجدير بالذكر أن فريق البحث قدم أيضا أن ضبط النموذج بهذه الطريقة يكلف 500 دولار فقط ، أي 8 ساعات من التشغيل على 16 A100s.
عند ترقية Zephyr إلى الإصدار التجريبي ، استمر الفريق في شرح نهجهم.
فكروا في الضبط الدقيق الخاضع للإشراف على التقطير (dSFT) المستخدم في النماذج الكبيرة ، ولكن مع هذا النهج كان النموذج غير محاذ ولم ينتج مخرجات تتوافق مع نية المستخدم.
لذلك حاول الفريق استخدام بيانات التفضيل من الذكاء الاصطناعي Feedback (AIF) لترتيب المخرجات باستخدام "نموذج المعلم" لتشكيل مجموعة بيانات ، ثم تطبيق تحسين التفضيل المباشر للتقطير (dDPO) لتدريب نموذج يتماشى مع نية المستخدم دون أي عينات إضافية أثناء الضبط الدقيق.
اختبر الباحثون أيضا التأثير عندما لم يتم استخدام SFT ، وأسفرت النتائج عن انخفاض كبير في الأداء ، مما يشير إلى أن خطوة dSFT أمر بالغ الأهمية.
في الوقت الحاضر ، بالإضافة إلى أن النموذج كان مفتوح المصدر وتجاريا ، هناك أيضا عرض توضيحي لتجربته ، حتى نتمكن من البدء وتجربته ببساطة.
تجربة تجريبية
بادئ ذي بدء ، اضطررت إلى الخروج من سؤال "المعاقين عقليا" لإجراء اختبار.
فيما يتعلق بالسؤال "أمي وأبي لا يأخذاني عندما يتزوجان" ، فإن إجابة زفير الإجمالية أكثر دقة.
لا يمكن ل ChatGPT التغلب على هذا السؤال.
في الاختبار ، وجدنا أيضا أن Zephyr يعرف أيضا الأحداث الأخيرة مثل إصدار OpenAI ل GPT-4:
يرتبط هذا في الواقع بنموذجها الأساسي ، على الرغم من أن مسؤول ميسترال لم يحدد الموعد النهائي لبيانات التدريب.
لكن بعض مستخدمي الإنترنت اختبروه من قبل ، وهم يعرفون عنه أيضا في مارس من هذا العام.
في المقابل ، فإن بيانات ما قبل التدريب في Llama 2 اعتبارا من سبتمبر 2022 ، وبعض البيانات الدقيقة فقط تصل إلى يونيو 2023.
بالإضافة إلى ذلك ، فإن Zephyr سريع الاستجابة للغاية ، لذا يمكنك كتابة التعليمات البرمجية وتكوين القصص. :
تجدر الإشارة إلى أن Zephyr أفضل في الإجابة على الأسئلة باللغة الإنجليزية ، ولديه أيضا مشكلة شائعة في نموذج "الهلوسة".
ذكر الباحثون أيضا الهلوسة ، وتم وضع علامة على سطر صغير من النص أسفل مربع الإدخال يشير إلى أن المحتوى الناتج عن النموذج قد يكون غير دقيق أو غير صحيح.
النقطة المهمة هي أن Zephyr لا يستخدم طرقا مثل التعلم المعزز مع التعليقات البشرية لتتماشى مع التفضيلات البشرية ، ولا يستخدم تصفية استجابة ChatGPT.
دائما اختيار واحدة من الأسماك emmm والكفوف الدب.
كان Zephyr قادرا على القيام بذلك باستخدام 70B معلمة فقط ، الأمر الذي فاجأ أندريه بوركوف ، مؤلف كتاب "كتاب التعلم الآلي المكون من 100 صفحة" ، بل وقال:
هزم Zephyr-7B اللاما 2-70B بنموذج أساسي من Mistral-7B مع نافذة سياق من 8k tokens ، والتي من الناحية النظرية لديها نطاق انتباه يصل إلى 128K tokens.
ماذا لو كان Zephyr من طراز 70B؟ هل ستتفوق على GPT-4؟ يبدو من المرجح.
إذا كنت مهتما ب Zephyr-7B ، فيمكنك تجربته على Huggingface.
روابط الورق:
الروابط المرجعية:
[1]
[2]
[3]
[4]
[5]
شاهد النسخة الأصلية
قد تحتوي هذه الصفحة على محتوى من جهات خارجية، يتم تقديمه لأغراض إعلامية فقط (وليس كإقرارات/ضمانات)، ولا ينبغي اعتباره موافقة على آرائه من قبل Gate، ولا بمثابة نصيحة مالية أو مهنية. انظر إلى إخلاء المسؤولية للحصول على التفاصيل.
أفضل نموذج 7B يتغير مرة أخرى! اهزم 70 مليار LLaMA2 ، وستتمكن أجهزة كمبيوتر Apple من التشغيل | مفتوح المصدر ومجاني
المصدر الأصلي: الكيوبت
نموذج 7 مليارات معلمة الذي استغرق 500 دولار "لضبط" هزم 70 مليار معلمة لاما 2!
ويمكن تشغيل الكمبيوتر المحمول بسهولة ، والتأثير مشابه ل ChatGPT.
هام: ** مجاني ، بدون نقود **.
نموذج مفتوح المصدر ** Zephyr-7B ** تم إنشاؤه بواسطة فريق HuggingFace H4 ، مجنون سمك القرش.
كان مفتاح قدرة Zephyr على التميز بين المتغيرات هو أن الفريق قام بضبط النموذج على مجموعة بيانات عامة باستخدام تحسين التفضيل المباشر (DPO) أعلى ميسترال.
وجد الفريق أيضا أن إزالة المحاذاة المضمنة لمجموعة البيانات يمكن أن تزيد من تحسين أداء MT Bench. حصل Zephyr-7B-alpha الأصلي على متوسط درجة MT-Bench يبلغ 7.09 ، متجاوزا Llama2-70B-Chat.
**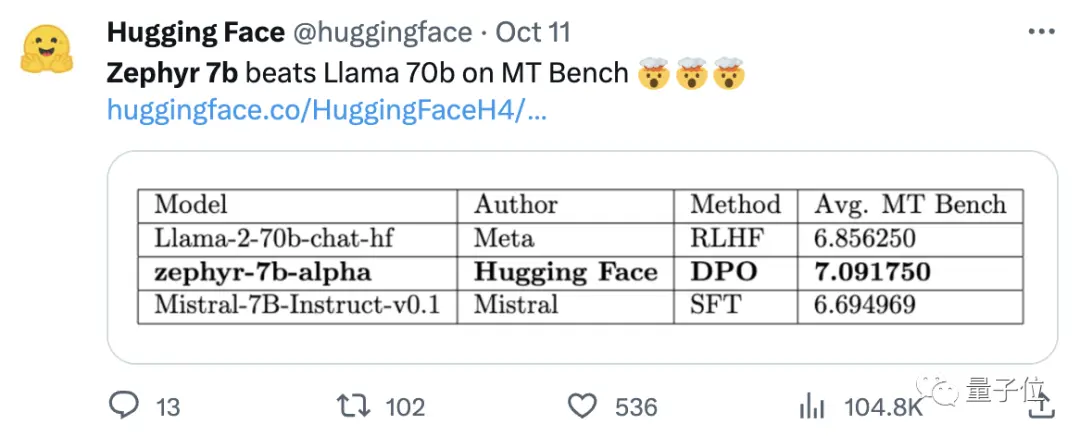 **####### △MT-Bench هو اختبار معياري لتقييم قدرة النموذج على التعامل مع جولات متعددة من الحوار ، وتغطي مجموعة الأسئلة 8 فئات مثل الكتابة ولعب الأدوار والاستخراج.
**####### △MT-Bench هو اختبار معياري لتقييم قدرة النموذج على التعامل مع جولات متعددة من الحوار ، وتغطي مجموعة الأسئلة 8 فئات مثل الكتابة ولعب الأدوار والاستخراج.
النقطة المهمة هي أنها استمرت في الترقية!
أطلق فريق H4 الجيل الثاني من Zephyr-7B-beta. وأضافوا أنهم استكشفوا فكرة استخراج المحاذاة من GPT-4 و Claude 2 ثم حقنها في نماذج صغيرة ، وتطوير طريقة لاستخدام تحسين التفضيل المباشر للتقطير (dDPO) للنماذج الصغيرة.
في الجيل الثاني من Zephyr ، ارتفع متوسط درجة MT-Bench إلى 7.34.
تعني كلمة ميسترال رياحا جافة وباردة وقوية باللغة الفرنسية ، بينما تعني زفير رياحا غربية خفيفة وممتعة.
ليس هناك شك في أن هناك حديقة على الجانب الآخر من اللاما ، وليس هناك شك في وجود مكتب للطقس على هذا الجانب.
** أفضل طراز 7B يتغير مرة أخرى **
لنبدأ بمتطلبات الكمبيوتر لتشغيل Zephyr. قال مستخدمو الإنترنت "السراويل التايلاندية حارة" بعد الاختبار! ، الكمبيوتر المحمول (Apple M1 Pro) يكفي ، "النتيجة جيدة جدا".
تظهر البيانات أيضا أن تأثير مهمة RAG المتقدمة من Zephyr يمكن أن يتنافس مع GPT-3.5 و Claude 2.
وأضافوا أن Zephyr لا يعمل بشكل جيد على RAND فحسب ، بل أيضا في التوجيه وتخطيط الاستعلام واسترداد عبارات SQL المعقدة واستخراج البيانات المنظمة.
** التخلي عن التعلم المعزز **
بينما يختبر الجميع تأثيرات Zephyr ، يقول المطورون إن الشيء الأكثر إثارة للاهتمام ليس المقاييس ، ولكن الطريقة التي يتم بها تدريب النموذج.
وفيما يلي موجز للنقاط البارزة:
بشكل عام ، كما ذكرنا في البداية ، فإن السبب الرئيسي وراء قدرة Zephyr على تجاوز 70B Llama 2 يرجع إلى استخدام طريقة ضبط دقيقة خاصة.
على عكس نهج التعلم المعزز التقليدي PPO ، استخدم فريق البحث تعاونا حديثا بين جامعة ستانفورد و CZ Biohub لاقتراح نهج DPO.
بعبارات بسيطة ، يمكن تفسير DPO على النحو التالي:
من أجل جعل ناتج النموذج أكثر انسجاما مع التفضيلات البشرية ، كان النهج التقليدي هو ضبط النموذج المستهدف بنموذج المكافأة. إذا كان الناتج جيدا ، فستتم مكافأتك ، وإذا كان الناتج سيئا ، فلن تتم مكافأتك.
من ناحية أخرى ، يتجاوز نهج DPO وظيفة مكافأة النمذجة ويعادل تحسين النموذج مباشرة على بيانات التفضيل.
بشكل عام ، يحل DPO مشكلة التدريب على التعلم المعزز الصعب والمكلف بسبب ردود الفعل البشرية.
فيما يتعلق بتدريب Zephyr على وجه التحديد ، قام فريق البحث في البداية بضبط Zephyr-7B-alpha على متغير مبسط من مجموعة بيانات UltraChat ، والتي تحتوي على 1.6 مليون محادثة تم إنشاؤها بواسطة ChatGPT (حوالي 200000 متبقية).
(كان سبب التبسيط هو أن الفريق وجد أن Zephyr كان في بعض الأحيان مغلفا بشكل غير صحيح ، مثل "مرحبا. كيف حالك؟" في بعض الأحيان يبدأ الرد ب "ليس لدي X شخصي". )
في وقت لاحق ، قاموا بمواءمة النموذج مع مجموعة بيانات openbmb / UltraFeedback المتاحة للجمهور باستخدام طريقة DPO Trainer الخاصة ب TRL.
تحتوي مجموعة البيانات على 64000 زوج من أزواج الاستجابة السريعة من نماذج مختلفة. يتم تصنيف كل استجابة بواسطة GPT-4 بناء على معايير مثل الفائدة وتعطى درجة يتم اشتقاق تفضيل الذكاء الاصطناعي منها.
نتيجة مثيرة للاهتمام هي أنه عند استخدام طريقة DPO ، يكون التأثير في الواقع أفضل بعد الإفراط في التجهيز مع زيادة وقت التدريب. يعتقد الباحثون أن هذا مشابه للتجهيز الزائد في SFT.
فكروا في الضبط الدقيق الخاضع للإشراف على التقطير (dSFT) المستخدم في النماذج الكبيرة ، ولكن مع هذا النهج كان النموذج غير محاذ ولم ينتج مخرجات تتوافق مع نية المستخدم.
اختبر الباحثون أيضا التأثير عندما لم يتم استخدام SFT ، وأسفرت النتائج عن انخفاض كبير في الأداء ، مما يشير إلى أن خطوة dSFT أمر بالغ الأهمية.
تجربة تجريبية
بادئ ذي بدء ، اضطررت إلى الخروج من سؤال "المعاقين عقليا" لإجراء اختبار.
فيما يتعلق بالسؤال "أمي وأبي لا يأخذاني عندما يتزوجان" ، فإن إجابة زفير الإجمالية أكثر دقة.
لكن بعض مستخدمي الإنترنت اختبروه من قبل ، وهم يعرفون عنه أيضا في مارس من هذا العام.
بالإضافة إلى ذلك ، فإن Zephyr سريع الاستجابة للغاية ، لذا يمكنك كتابة التعليمات البرمجية وتكوين القصص. :
ذكر الباحثون أيضا الهلوسة ، وتم وضع علامة على سطر صغير من النص أسفل مربع الإدخال يشير إلى أن المحتوى الناتج عن النموذج قد يكون غير دقيق أو غير صحيح.
دائما اختيار واحدة من الأسماك emmm والكفوف الدب.
كان Zephyr قادرا على القيام بذلك باستخدام 70B معلمة فقط ، الأمر الذي فاجأ أندريه بوركوف ، مؤلف كتاب "كتاب التعلم الآلي المكون من 100 صفحة" ، بل وقال:
روابط الورق:
الروابط المرجعية:
[1]
[2]
[3]
[4]
[5]