¡Yao Qizhi tomó la iniciativa al proponer un marco de "pensamiento" modelo grande! La precisión del razonamiento lógico es del 98% y la forma de pensar se parece más a la de los humanos.
¡El primer artículo sobre Modelo de lenguaje grande dirigido por el ganador del premio Turing, Yao Qizhi, ya está aquí!
Tan pronto como comencé, apunté a la dirección de "hacer que los modelos grandes piensen como personas"——
Los modelos grandes no solo necesitan razonar paso a paso, sino que también deben aprender a "paso a paso" y recordar todos los procesos correctos en el proceso de razonamiento.
Específicamente, este nuevo artículo propone un nuevo método llamado razonamiento acumulativo, que mejora significativamente la capacidad de los modelos grandes para realizar razonamientos complejos.
Debe saber que los modelos grandes se basan en cadenas de pensamiento, etc., y pueden usarse para razonar problemas, pero cuando se enfrenta a problemas que requieren "varios giros", aún es fácil cometer errores.
Es sobre esta base que el razonamiento acumulativo añade un "verificador" para juzgar el bien y el mal en tiempo real. El marco de pensamiento de este modelo también ha cambiado de cadena y árbol a un "gráfico acíclico dirigido" más complejo.
De esta manera, el modelo grande no sólo tiene ideas más claras para resolver problemas, sino que también desarrolla la habilidad de "jugar a las cartas":
En problemas matemáticos como álgebra y teoría geométrica de números, la precisión relativa de los modelos grandes aumentó en un 42 %; al jugar 24 puntos, la tasa de éxito se disparó al 98 %.
Según el Instituto de Información Cruzada de la Universidad de Tsinghua, el coautor Zhang Yifan explicó el punto de partida de este artículo:
Kahneman cree que el procesamiento cognitivo humano incluye dos sistemas: el "Sistema 1" es rápido, instintivo y emocional, y el "Sistema 2" es lento, reflexivo y lógico.
Actualmente, el rendimiento de los modelos de lenguaje grandes está más cerca del "Sistema 1", lo que puede explicar por qué no es bueno para abordar tareas complejas.
El razonamiento acumulativo diseñado desde esta perspectiva es mejor que Cadena de Pensamiento (CoT) y Árbol de Pensamiento (ToT).
Entonces, ¿cómo es realmente este nuevo enfoque? Echemos un vistazo juntos.
Rompe la cadena de pensamiento y los "cuellos de botella" de los árboles
El núcleo del razonamiento acumulativo radica en mejorar la "forma" del proceso de pensamiento de modelos grandes.
Específicamente, este método utiliza 3 modelos de lenguaje grandes:
Proponente: Proponer constantemente nuevas proposiciones, es decir, sugerir cuál es el siguiente paso en función del contexto de pensamiento actual.
Verificador: Verifica la exactitud de la proposición del proponente y la agrega al contexto de pensamiento si es correcta.
Reportero: Determina si se ha obtenido la solución final y si se debe finalizar el proceso de razonamiento.
Durante el proceso de razonamiento, el "proponente" primero da una propuesta, el "verificador" es responsable de la evaluación y el "reportero" decide si finaliza la respuesta y finaliza el proceso de pensamiento.
** ****△**Ejemplo de razonamiento CR
Es un poco como los tres tipos de roles en un proyecto de equipo: los miembros del equipo intercambian ideas primero, el instructor "comprueba" qué idea es factible y el líder del equipo decide cuándo completar el proyecto.
**Entonces, ¿cómo cambia exactamente este enfoque la “forma” del pensamiento de los grandes modelos? **
Para entender esto, tenemos que comenzar con la "Cadena de Pensamiento, CoT" (Cadena de Pensamiento, CoT), el "creador" de los métodos de mejora del pensamiento de modelos grandes.
Este método fue propuesto por el científico de OpenAI Jason Wei y otros en enero de 2022. El núcleo es agregar un texto de "razonamiento paso a paso" a la entrada del conjunto de datos para estimular la capacidad de pensamiento del modelo grande.
** ****△**Seleccionado del conjunto de datos GSM8K
Basado en el principio de la cadena de pensamiento, Google también siguió rápidamente una "versión PLUS de la cadena de pensamiento", a saber, CoT-SC, que lleva a cabo principalmente múltiples procesos de cadena de pensamiento y realiza una votación mayoritaria sobre las respuestas para seleccionar la mejor. La mejor respuesta puede mejorar aún más la precisión del razonamiento.
Pero tanto Thinking Chain como CoT-SC ignoran un problema: hay más de una solución a la pregunta, especialmente cuando los humanos resuelven el problema.
Por ello, posteriormente apareció una nueva investigación llamada Árbol del Pensamiento (ToT).
Se trata de un esquema de búsqueda en forma de árbol que permite al modelo probar una variedad de ideas de razonamiento diferentes, autoevaluarse, elegir el siguiente curso de acción y retroceder si es necesario.
Del método se puede ver que el árbol de pensamiento va más allá de la cadena de pensamiento, lo que hace que el pensamiento de modelos grandes sea "más activo".
Es por eso que cuando se juegan 24 puntos, la tasa de éxito de GPT-4 de la bonificación de la Cadena de Pensamiento es solo del 4%**, pero la tasa de éxito del Árbol de Pensamiento se eleva al 74%.
PERO, independientemente de la cadena de pensamiento, CoT-SC o árbol de pensamiento, tiene una limitación común:
Ninguno de ellos estableció un lugar de almacenamiento para los resultados intermedios del proceso de pensamiento.
Después de todo, no todos los procesos de pensamiento se pueden convertir en cadenas o árboles: la forma en que los humanos piensan sobre las cosas suele ser más complicada.
Este nuevo marco de razonamiento acumulativo supera este punto del diseño——
El proceso de pensamiento general de un modelo grande no es necesariamente una cadena o un árbol, ¡también puede ser un ** Gráfico acíclico dirigido (DAG) **! (Bueno, huele a sinapsis)
** ****△**Los bordes en el gráfico tienen direcciones y no hay caminos circulares; cada borde dirigido es un paso de derivación
Esto significa que puede almacenar todos los resultados de inferencia históricamente correctos en la memoria para su exploración en la rama de búsqueda actual. (Por el contrario, un árbol pensante no almacena información de otras ramas)
Pero el razonamiento acumulativo también se puede cambiar sin problemas con la cadena de pensamiento: siempre que se elimine el "verificador", es un modelo de cadena de pensamiento estándar.
El razonamiento acumulativo diseñado en base a este método ha logrado buenos resultados en varios métodos.
Bueno para hacer matemáticas y razonamiento lógico
Los investigadores eligieron el wiki FOLIO y AutoTNLI, el juego de 24 puntos y los conjuntos de datos MATH para "probar" el razonamiento acumulativo.
El proponente, el verificador y el informante utilizan el mismo modelo de lenguaje amplio en cada experimento, con diferentes configuraciones para sus roles.
Los modelos básicos utilizados aquí para los experimentos incluyen GPT-3.5-turbo, GPT-4, LLaMA-13B y LLaMA-65B.
Vale la pena mencionar que, idealmente, el modelo debería entrenarse previamente especialmente utilizando datos de tareas de derivación relevantes, y el "verificador" también debería agregar un probador matemático formal, un módulo de resolución de lógica proposicional, etc.
1. Capacidad de razonamiento lógico
FOLIO es un conjunto de datos de razonamiento lógico de primer orden y las etiquetas de las preguntas pueden ser "verdadero", "Falso" y "Desconocido"; AutoTNLI es un conjunto de datos de razonamiento lógico de orden superior.
En el conjunto de datos de FOLIO wiki, en comparación con los métodos de resultados de salida directa (Direct), cadena de pensamiento (CoT) y cadena de pensamiento avanzada (CoT-SC), el rendimiento del razonamiento acumulativo (CR) es siempre el mejor.
Después de eliminar instancias problemáticas (como respuestas incorrectas) del conjunto de datos, la precisión de la inferencia de GPT-4 utilizando el método CR alcanzó el 98,04 %, con una tasa de error mínima del 1,96 %.
Veamos el rendimiento en el conjunto de datos de AutoTNLI:
En comparación con el método CoT, CR mejoró significativamente el rendimiento de LLaMA-13B y LLaMA-65B.
En el modelo LLaMA-65B, la mejora de CR respecto a CoT alcanzó el 9,3%.
### ** 2. Posibilidad de jugar juegos de 24 puntos **
El artículo de ToT original utilizó un juego de 24 puntos, por lo que los investigadores utilizaron este conjunto de datos para comparar CR y ToT.
ToT utiliza un árbol de búsqueda de ancho y profundidad fijos, y CR permite que modelos grandes determinen la profundidad de búsqueda de forma autónoma.
Los investigadores encontraron en experimentos que en el contexto de 24 puntos, el algoritmo CR y el algoritmo ToT son muy similares. La diferencia es que el algoritmo en CR genera como máximo un nuevo estado por iteración, mientras que ToT genera muchos estados candidatos en cada iteración y filtra y retiene una parte del estado.
En términos sencillos, ToT no tiene el "verificador" mencionado anteriormente como CR y no puede juzgar si los estados (a, b, c) son correctos o incorrectos, por lo que ToT explorará más estados inválidos que CR.
Al final, la precisión del método CR puede incluso alcanzar el 98% (ToT es 74%), y el número promedio de estados accedidos es mucho menor que ToT.
En otras palabras, CR no solo tiene una mayor tasa de precisión de búsqueda, sino que también tiene una mayor eficiencia de búsqueda.
### 3. Habilidad matemática
El conjunto de datos MATH contiene una gran cantidad de preguntas de razonamiento matemático, que incluyen álgebra, geometría, teoría de números, etc. La dificultad de las preguntas se divide en cinco niveles.
Usando el método CR, el modelo puede descomponer la pregunta en subpreguntas que se pueden completar paso a paso y hacer y responder preguntas hasta que se genere la respuesta.
Los resultados experimentales muestran que bajo dos entornos experimentales diferentes, la tasa de precisión de CR excede los métodos existentes actualmente, con una tasa de precisión general de hasta el 58% y una mejora de precisión relativa del 42% en el problema de Nivel 5. bajo el modelo GPT-4.
Investigación dirigida por Yao Qizhi y Yuan Yang de la Universidad de Tsinghua
Este artículo proviene del grupo de investigación AI for Math dirigido por Yao Qizhi y Yuan Yang del Instituto Tsinghua de Información Interdisciplinaria.
Los coautores del artículo son Zhang Yifan y Yang Jingqin, estudiantes de doctorado de 2021 en el Instituto de Información Interdisciplinaria;
El instructor y coautor correspondiente son el profesor asistente Yuan Yang y el académico Yao Qizhi.
Zhang Yifan
Zhang Yifan se graduó de la Facultad Yuanpei de la Universidad de Pekín en 2021. Actualmente estudia con el profesor asistente Yuan Yang. Sus principales direcciones de investigación son la teoría y los algoritmos de modelos básicos (modelos de lenguaje grande), el aprendizaje autosupervisado y la inteligencia artificial confiable.
Yang Jingqin
Yang Jingqin recibió su licenciatura en el Instituto de Información Cruzada de la Universidad de Tsinghua en 2021 y actualmente está estudiando para obtener su doctorado con el profesor asistente Yuan Yang. Las principales direcciones de investigación incluyen grandes modelos de lenguaje, aprendizaje autosupervisado, atención médica inteligente, etc.
Yuan Yang
Yuan Yang es profesor asistente en la Escuela de Información Interdisciplinaria de la Universidad de Tsinghua. Graduado del Departamento de Ciencias de la Computación de la Universidad de Pekín en 2012; recibió un doctorado en Ciencias de la Computación de la Universidad de Cornell en Estados Unidos en 2018; de 2018 a 2019 trabajó como becario postdoctoral en la Escuela de Ciencias de Big Data del Instituto de Massachusetts. de tecnología.
Sus principales direcciones de investigación son la atención médica inteligente, la teoría básica de la IA, la teoría de categorías aplicada, etc.
Yao Qizhi
Yao Qizhi es académico de la Academia de Ciencias de China y decano del Instituto de Información Interdisciplinaria de la Universidad de Tsinghua. También es el primer académico asiático en ganar el Premio Turing desde su creación, y el único informático chino en ganar este honor. hasta ahora.
El profesor Yao Qizhi renunció a Princeton como profesor titular en 2004 y regresó a Tsinghua para enseñar; en 2005, fundó la "Clase Yao", una clase experimental de ciencias de la computación para estudiantes universitarios de Tsinghua; en 2011, fundó el "Centro de Información Cuántica de Tsinghua". " y el "Instituto de Investigación de Información Interdisciplinaria"; en 2019 En 2008, fundó una clase de inteligencia artificial para estudiantes universitarios de Tsinghua, conocida como "Clase Inteligente".
Hoy en día, el Instituto de Información Interdisciplinaria de la Universidad de Tsinghua dirigido por él es famoso desde hace mucho tiempo. Yao Class y Zhiban están afiliados al Instituto de Información Interdisciplinaria.
Los intereses de investigación del profesor Yao Qizhi incluyen algoritmos, criptografía, computación cuántica, etc. Es un pionero y una autoridad internacional en este campo. Recientemente, apareció en la Conferencia Mundial de Inteligencia Artificial de 2023. El Instituto de Investigación Qizhi de Shanghai que dirige está estudiando actualmente la "inteligencia artificial general incorporada".
Enlace del artículo:
Ver originales
Esta página puede contener contenido de terceros, que se proporciona únicamente con fines informativos (sin garantías ni declaraciones) y no debe considerarse como un respaldo por parte de Gate a las opiniones expresadas ni como asesoramiento financiero o profesional. Consulte el Descargo de responsabilidad para obtener más detalles.
¡Yao Qizhi tomó la iniciativa al proponer un marco de "pensamiento" modelo grande! La precisión del razonamiento lógico es del 98% y la forma de pensar se parece más a la de los humanos.
Fuente: Qubits
¡El primer artículo sobre Modelo de lenguaje grande dirigido por el ganador del premio Turing, Yao Qizhi, ya está aquí!
Tan pronto como comencé, apunté a la dirección de "hacer que los modelos grandes piensen como personas"——
Los modelos grandes no solo necesitan razonar paso a paso, sino que también deben aprender a "paso a paso" y recordar todos los procesos correctos en el proceso de razonamiento.
Específicamente, este nuevo artículo propone un nuevo método llamado razonamiento acumulativo, que mejora significativamente la capacidad de los modelos grandes para realizar razonamientos complejos.
Es sobre esta base que el razonamiento acumulativo añade un "verificador" para juzgar el bien y el mal en tiempo real. El marco de pensamiento de este modelo también ha cambiado de cadena y árbol a un "gráfico acíclico dirigido" más complejo.
De esta manera, el modelo grande no sólo tiene ideas más claras para resolver problemas, sino que también desarrolla la habilidad de "jugar a las cartas":
En problemas matemáticos como álgebra y teoría geométrica de números, la precisión relativa de los modelos grandes aumentó en un 42 %; al jugar 24 puntos, la tasa de éxito se disparó al 98 %.
El razonamiento acumulativo diseñado desde esta perspectiva es mejor que Cadena de Pensamiento (CoT) y Árbol de Pensamiento (ToT).
Entonces, ¿cómo es realmente este nuevo enfoque? Echemos un vistazo juntos.
Rompe la cadena de pensamiento y los "cuellos de botella" de los árboles
El núcleo del razonamiento acumulativo radica en mejorar la "forma" del proceso de pensamiento de modelos grandes.
Específicamente, este método utiliza 3 modelos de lenguaje grandes:
Durante el proceso de razonamiento, el "proponente" primero da una propuesta, el "verificador" es responsable de la evaluación y el "reportero" decide si finaliza la respuesta y finaliza el proceso de pensamiento.
**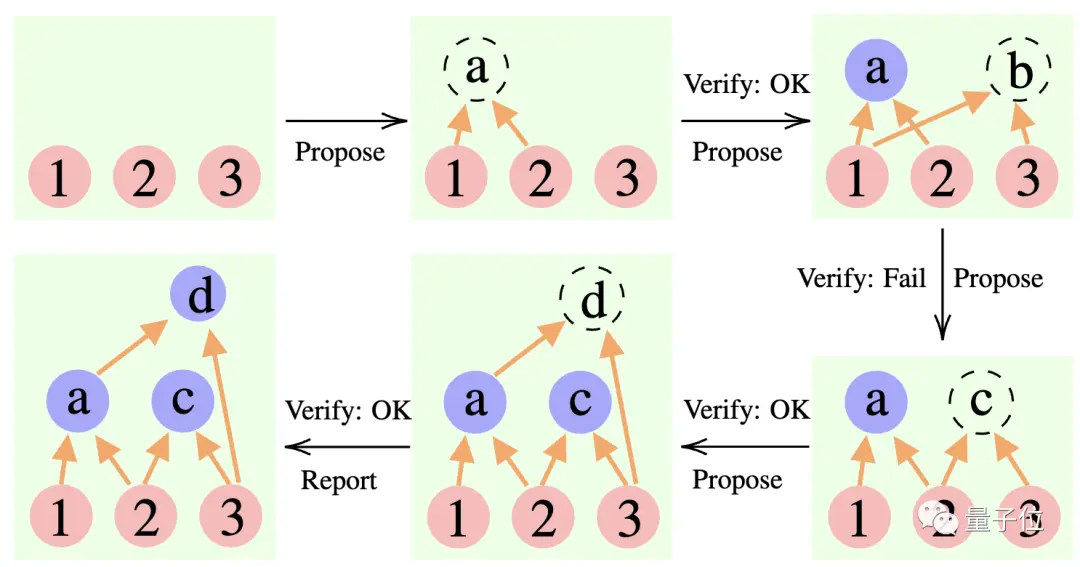 ****△**Ejemplo de razonamiento CR
****△**Ejemplo de razonamiento CR
Es un poco como los tres tipos de roles en un proyecto de equipo: los miembros del equipo intercambian ideas primero, el instructor "comprueba" qué idea es factible y el líder del equipo decide cuándo completar el proyecto.
Para entender esto, tenemos que comenzar con la "Cadena de Pensamiento, CoT" (Cadena de Pensamiento, CoT), el "creador" de los métodos de mejora del pensamiento de modelos grandes.
Este método fue propuesto por el científico de OpenAI Jason Wei y otros en enero de 2022. El núcleo es agregar un texto de "razonamiento paso a paso" a la entrada del conjunto de datos para estimular la capacidad de pensamiento del modelo grande.
**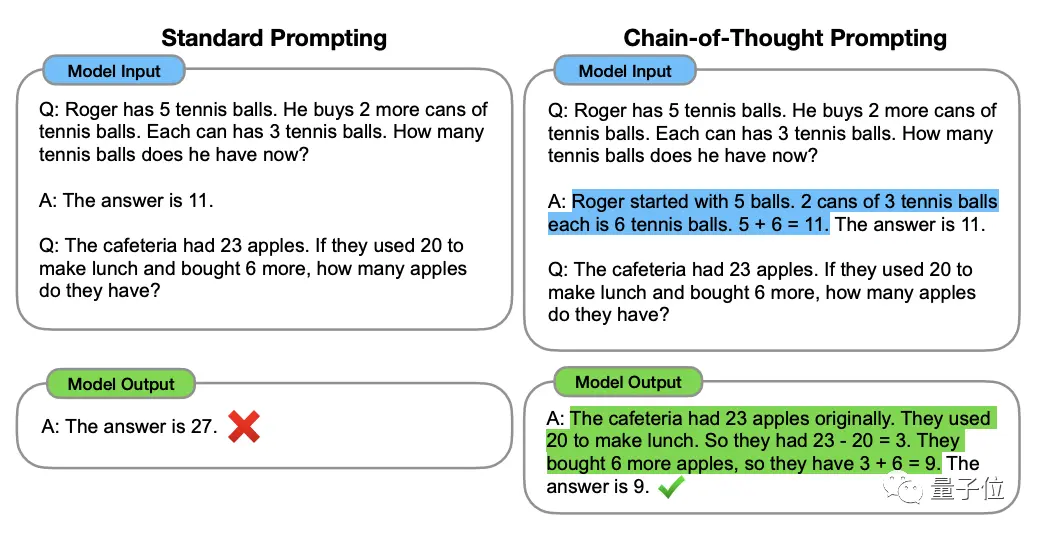 ****△**Seleccionado del conjunto de datos GSM8K
****△**Seleccionado del conjunto de datos GSM8K
Basado en el principio de la cadena de pensamiento, Google también siguió rápidamente una "versión PLUS de la cadena de pensamiento", a saber, CoT-SC, que lleva a cabo principalmente múltiples procesos de cadena de pensamiento y realiza una votación mayoritaria sobre las respuestas para seleccionar la mejor. La mejor respuesta puede mejorar aún más la precisión del razonamiento.
Pero tanto Thinking Chain como CoT-SC ignoran un problema: hay más de una solución a la pregunta, especialmente cuando los humanos resuelven el problema.
Por ello, posteriormente apareció una nueva investigación llamada Árbol del Pensamiento (ToT).
Se trata de un esquema de búsqueda en forma de árbol que permite al modelo probar una variedad de ideas de razonamiento diferentes, autoevaluarse, elegir el siguiente curso de acción y retroceder si es necesario.
Es por eso que cuando se juegan 24 puntos, la tasa de éxito de GPT-4 de la bonificación de la Cadena de Pensamiento es solo del 4%**, pero la tasa de éxito del Árbol de Pensamiento se eleva al 74%.
PERO, independientemente de la cadena de pensamiento, CoT-SC o árbol de pensamiento, tiene una limitación común:
Después de todo, no todos los procesos de pensamiento se pueden convertir en cadenas o árboles: la forma en que los humanos piensan sobre las cosas suele ser más complicada.
Este nuevo marco de razonamiento acumulativo supera este punto del diseño——
El proceso de pensamiento general de un modelo grande no es necesariamente una cadena o un árbol, ¡también puede ser un ** Gráfico acíclico dirigido (DAG) **! (Bueno, huele a sinapsis)
**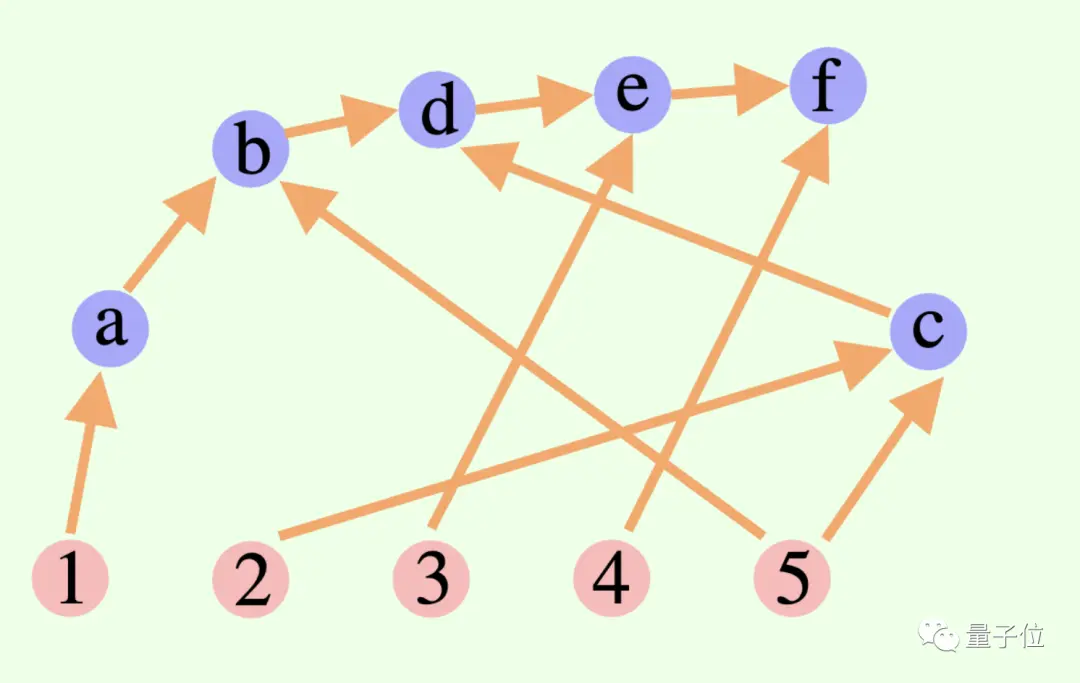 ****△**Los bordes en el gráfico tienen direcciones y no hay caminos circulares; cada borde dirigido es un paso de derivación
****△**Los bordes en el gráfico tienen direcciones y no hay caminos circulares; cada borde dirigido es un paso de derivación
Esto significa que puede almacenar todos los resultados de inferencia históricamente correctos en la memoria para su exploración en la rama de búsqueda actual. (Por el contrario, un árbol pensante no almacena información de otras ramas)
Pero el razonamiento acumulativo también se puede cambiar sin problemas con la cadena de pensamiento: siempre que se elimine el "verificador", es un modelo de cadena de pensamiento estándar.
El razonamiento acumulativo diseñado en base a este método ha logrado buenos resultados en varios métodos.
Bueno para hacer matemáticas y razonamiento lógico
Los investigadores eligieron el wiki FOLIO y AutoTNLI, el juego de 24 puntos y los conjuntos de datos MATH para "probar" el razonamiento acumulativo.
El proponente, el verificador y el informante utilizan el mismo modelo de lenguaje amplio en cada experimento, con diferentes configuraciones para sus roles.
Los modelos básicos utilizados aquí para los experimentos incluyen GPT-3.5-turbo, GPT-4, LLaMA-13B y LLaMA-65B.
Vale la pena mencionar que, idealmente, el modelo debería entrenarse previamente especialmente utilizando datos de tareas de derivación relevantes, y el "verificador" también debería agregar un probador matemático formal, un módulo de resolución de lógica proposicional, etc.
1. Capacidad de razonamiento lógico
FOLIO es un conjunto de datos de razonamiento lógico de primer orden y las etiquetas de las preguntas pueden ser "verdadero", "Falso" y "Desconocido"; AutoTNLI es un conjunto de datos de razonamiento lógico de orden superior.
En el conjunto de datos de FOLIO wiki, en comparación con los métodos de resultados de salida directa (Direct), cadena de pensamiento (CoT) y cadena de pensamiento avanzada (CoT-SC), el rendimiento del razonamiento acumulativo (CR) es siempre el mejor.
Después de eliminar instancias problemáticas (como respuestas incorrectas) del conjunto de datos, la precisión de la inferencia de GPT-4 utilizando el método CR alcanzó el 98,04 %, con una tasa de error mínima del 1,96 %.
En comparación con el método CoT, CR mejoró significativamente el rendimiento de LLaMA-13B y LLaMA-65B.
En el modelo LLaMA-65B, la mejora de CR respecto a CoT alcanzó el 9,3%.
El artículo de ToT original utilizó un juego de 24 puntos, por lo que los investigadores utilizaron este conjunto de datos para comparar CR y ToT.
ToT utiliza un árbol de búsqueda de ancho y profundidad fijos, y CR permite que modelos grandes determinen la profundidad de búsqueda de forma autónoma.
Los investigadores encontraron en experimentos que en el contexto de 24 puntos, el algoritmo CR y el algoritmo ToT son muy similares. La diferencia es que el algoritmo en CR genera como máximo un nuevo estado por iteración, mientras que ToT genera muchos estados candidatos en cada iteración y filtra y retiene una parte del estado.
En términos sencillos, ToT no tiene el "verificador" mencionado anteriormente como CR y no puede juzgar si los estados (a, b, c) son correctos o incorrectos, por lo que ToT explorará más estados inválidos que CR.
En otras palabras, CR no solo tiene una mayor tasa de precisión de búsqueda, sino que también tiene una mayor eficiencia de búsqueda.
El conjunto de datos MATH contiene una gran cantidad de preguntas de razonamiento matemático, que incluyen álgebra, geometría, teoría de números, etc. La dificultad de las preguntas se divide en cinco niveles.
Usando el método CR, el modelo puede descomponer la pregunta en subpreguntas que se pueden completar paso a paso y hacer y responder preguntas hasta que se genere la respuesta.
Los resultados experimentales muestran que bajo dos entornos experimentales diferentes, la tasa de precisión de CR excede los métodos existentes actualmente, con una tasa de precisión general de hasta el 58% y una mejora de precisión relativa del 42% en el problema de Nivel 5. bajo el modelo GPT-4.
Investigación dirigida por Yao Qizhi y Yuan Yang de la Universidad de Tsinghua
Este artículo proviene del grupo de investigación AI for Math dirigido por Yao Qizhi y Yuan Yang del Instituto Tsinghua de Información Interdisciplinaria.
Los coautores del artículo son Zhang Yifan y Yang Jingqin, estudiantes de doctorado de 2021 en el Instituto de Información Interdisciplinaria;
El instructor y coautor correspondiente son el profesor asistente Yuan Yang y el académico Yao Qizhi.
Zhang Yifan
Zhang Yifan se graduó de la Facultad Yuanpei de la Universidad de Pekín en 2021. Actualmente estudia con el profesor asistente Yuan Yang. Sus principales direcciones de investigación son la teoría y los algoritmos de modelos básicos (modelos de lenguaje grande), el aprendizaje autosupervisado y la inteligencia artificial confiable.
Yang Jingqin
Yang Jingqin recibió su licenciatura en el Instituto de Información Cruzada de la Universidad de Tsinghua en 2021 y actualmente está estudiando para obtener su doctorado con el profesor asistente Yuan Yang. Las principales direcciones de investigación incluyen grandes modelos de lenguaje, aprendizaje autosupervisado, atención médica inteligente, etc.
Yuan Yang
Sus principales direcciones de investigación son la atención médica inteligente, la teoría básica de la IA, la teoría de categorías aplicada, etc.
Yao Qizhi
El profesor Yao Qizhi renunció a Princeton como profesor titular en 2004 y regresó a Tsinghua para enseñar; en 2005, fundó la "Clase Yao", una clase experimental de ciencias de la computación para estudiantes universitarios de Tsinghua; en 2011, fundó el "Centro de Información Cuántica de Tsinghua". " y el "Instituto de Investigación de Información Interdisciplinaria"; en 2019 En 2008, fundó una clase de inteligencia artificial para estudiantes universitarios de Tsinghua, conocida como "Clase Inteligente".
Hoy en día, el Instituto de Información Interdisciplinaria de la Universidad de Tsinghua dirigido por él es famoso desde hace mucho tiempo. Yao Class y Zhiban están afiliados al Instituto de Información Interdisciplinaria.
Los intereses de investigación del profesor Yao Qizhi incluyen algoritmos, criptografía, computación cuántica, etc. Es un pionero y una autoridad internacional en este campo. Recientemente, apareció en la Conferencia Mundial de Inteligencia Artificial de 2023. El Instituto de Investigación Qizhi de Shanghai que dirige está estudiando actualmente la "inteligencia artificial general incorporada".
Enlace del artículo: