investigadores de Microsoft Stanford publicaron un nuevo artículo en el que proponen el sistema STOP, a través de algoritmos de optimización iterativos, para que GPT-4 pueda automejorar el código de salida de la tarea. Este método de autooptimización, que no cambia el peso y la estructura del modelo, puede evitar el riesgo de "sistemas de IA autoevolutivos".
¿Se ha resuelto el problema de la "autoevolución recursiva: la IA domina a los humanos"?
Muchos peces gordos de la IA consideran el desarrollo de grandes modelos que pueden iterar por sí solos como un "atajo" para que los humanos comiencen el camino hacia la autodestrucción.
El cofundador de DeepMind ha dicho que la IA que puede evolucionar de forma autónoma tiene riesgos potenciales muy grandes
Porque si el modelo grande puede mejorar su propio peso y marco de forma independiente, y mejorar continuamente su capacidad de automejora, no solo no se puede discutir la interpretabilidad del modelo, sino que los humanos serán completamente incapaces de predecir y controlar el resultado del modelo.
Si dejas que el gran modelo "evolucione de forma autónoma", el modelo puede seguir produciendo contenido dañino, y si la futura habilidad evoluciona con demasiada fuerza, ¡puede a su vez controlar a los humanos!
Recientemente, investigadores de Microsoft y Stanford han desarrollado un nuevo sistema que permite a los modelos autoiterar y mejorar la calidad de los resultados sin cambiar las ponderaciones y los marcos.
Y lo que es más importante, este sistema puede mejorar en gran medida la transparencia y la interpretabilidad del proceso de "automejora" del modelo, lo que permite a los investigadores comprender y controlar el proceso de automejora del modelo, evitando así la aparición de una IA "incontrolable por el ser humano".
Dirección del papel:
La "automejora recursiva" (RSI, por sus siglas en inglés) es una de las ideas más antiguas de la inteligencia artificial. ¿Puede un modelo de lenguaje escribir código que se mejore a sí mismo de forma recursiva?
Los investigadores propusieron un optimizador autodidacta (STOP) que puede automejorar recursivamente la generación de código.
Comienzan con un simple programa de "optimización" semilla que toma el código y las funciones objetivo, y utiliza un modelo de lenguaje para mejorar el código (devolviendo la mejor mejora en la optimización k).
Debido a que "mejorar el código" es una tarea, los investigadores pueden pasar el "optimizador" a sí mismos. Luego, repite el proceso una y otra vez.
Siempre que el proceso se repita lo suficiente, GPT-4 presentará muchas estrategias de automejora de código muy creativas, como algoritmos genéticos, recocido simulado o máquinas de juego rápidas de múltiples brazos.
Teniendo en cuenta que los datos de entrenamiento de GPT-4 son solo hasta 2021, que es antes que muchas de las estrategias mejoradas que encontró, ¡es realmente sorprendente obtener tales resultados!
Además, debido a que los investigadores necesitaban alguna forma de evaluar el optimizador mejorado, definieron un objetivo de "Meta-Utilidad", que es el objetivo esperado del optimizador cuando se aplica a programas y tareas posteriores aleatorios.
Cuando el optimizador se mejora a sí mismo, los investigadores asignan esta función objetivo al algoritmo.
Los principales resultados encontrados por los investigadores son: En primer lugar, el rendimiento posterior esperado de los optimizadores de automejora aumentó de forma consistente con el número de iteraciones de automejora.
En segundo lugar, estos optimizadores mejorados también pueden ser una buena forma de mejorar las soluciones a tareas que no se han visto durante el entrenamiento.
Si bien muchos investigadores han expresado su preocupación por los modelos de "automejora recursiva", creen que podrían desarrollarse sistemas de IA que los humanos no pueden controlar. Pero en lugar de optimizarse para el modelo en sí, se optimiza automáticamente para la tarea de destino, lo que hace que el proceso de optimización sea más fácil de interpretar.
Y este proceso se puede utilizar como banco de pruebas para detectar estrategias dañinas de "automejora recursiva".
Los investigadores también descubrieron que GPT-4 puede eliminar activamente la "bandera de desactivación de sandbox" durante la iteración "en busca de la eficiencia".
Los internautas creen que el método propuesto en este documento tiene un gran potencial. Debido a que el AGI del futuro puede no ser un solo modelo grande, es probable que sea un grupo de innumerables agentes eficientes capaces de trabajar juntos para tener éxito en las enormes tareas que se les asignan.
Al igual que una empresa tiene una inteligencia más poderosa que los empleados individuales.
Tal vez con este enfoque, incluso si AGI no es posible, puede ser posible hacer que un modelo especialmente optimizado logre un rendimiento mucho mayor que él mismo en una gama limitada de tareas.
Marco Básico de Tesis
En este trabajo, los investigadores proponen el Optimizador Autodidacta (STOP), que es una aplicación de modelos de lenguaje para mejorar la aplicación recursiva de código para soluciones arbitrarias.
El enfoque de los investigadores comenzó con un programa inicial de andamiaje "optimizador" de semillas que utiliza modelos de lenguaje para mejorar las soluciones a las tareas posteriores.
A medida que el sistema itera, el modelo refina este procedimiento de optimización. Los investigadores utilizaron un conjunto de tareas algorítmicas posteriores para cuantificar el rendimiento del marco de autooptimización.
Los resultados de los investigadores mostraron que el efecto mejoró significativamente cuando el modelo aplicó su estrategia de automejora a medida que aumentaba el número de iteraciones.
STOP muestra cómo un modelo de lenguaje actúa como su propio Meta Optimizer. Los investigadores también estudiaron los tipos de estrategias de superación personal propuestas por el modelo (véase la Figura 1 a continuación), la transferibilidad de las estrategias propuestas en tareas posteriores y exploraron la sensibilidad del modelo a las estrategias de superación personal inseguras.
La figura anterior muestra muchos de los andamios funcionales e interesantes propuestos por STOP cuando se utiliza GPT-4, porque GPT-4 se entrenó con datos hasta 2021, mucho antes de lo que se proponían la mayoría de los programas constructivos.
Por lo tanto, muestra que este sistema puede generar estrategias de optimización útiles para optimizarse originalmente.
Las principales aportaciones de este trabajo son:
Se propone un método "Meta-Optimizer", que genera programas constructivos para mejorar recursivamente su propia producción.
Se demostró que un sistema que utiliza modelos de lenguaje modernos (especialmente GPT-4) puede mejorarse a sí mismo recursivamente.
Estudiar las técnicas de automejora propuestas e implementadas por el modelo, incluyendo las formas y posibilidades de que el modelo evite medidas de seguridad como los sandboxes.
STOP OPTIMIZADOR AUTODIDACTA (STOP)系统
En la figura 3 se muestra la canalización de optimización autoiterativa del sistema
A continuación se muestra el diagrama de algoritmos de Self-Taught Optimizer (STOP). Uno de los problemas más críticos es que el diseño del sistema I en sí es una división optimizada, que se puede mejorar mediante la aplicación de algoritmos recursivos.
En primer lugar, el algoritmo STOP inicializa primero la semilla I0 y, a continuación, define la fórmula de salida después de la mejora de la t-ésima iteración:
1. Corazonada
STOP puede seleccionar u de acuerdo con las tareas posteriores para seleccionar mejor la versión de iteración durante el proceso de iteración. A menudo, la intuición es que las versiones iterativas de las soluciones que son competentes para las tareas posteriores tienen más probabilidades de convertirse en mejores constructores y, por lo tanto, mejores para mejorarse a sí mismas.
Al mismo tiempo, los investigadores creen que la elección de un esquema de mejora teórico único conduce a mejores rondas múltiples de mejora.
En la fórmula de maximización, los autores discuten la "meta-utilidad", que cubre tanto la auto-optimización como la optimización posterior, pero está limitada por el costo de la evaluación, y en la práctica, los autores imponen restricciones presupuestarias a los modelos de lenguaje (por ejemplo, limitan el número de veces que se puede llamar a una función) y dejan que los humanos o los modelos generen soluciones iniciales.
El costo presupuestario se puede expresar mediante la siguiente fórmula:
donde budget representa cada partida presupuestaria, correspondiente a cada iteración del número de veces que el sistema puede utilizar la función de llamada.
2. Configurar el sistema inicial
** **En la Figura 2 anterior, al seleccionar la semilla inicial, solo necesita proporcionar:
「Eres un experto investigador y programador en ciencias de la computación, especialmente hábil en la optimización de algoritmos. Mejora la siguiente solución.」
El modelo de sistema genera la solución inicial y, a continuación, introduce:
「Debe devolver una solución mejorada. Sé tan creativo como puedas bajo las limitaciones. Su mejora principal debe ser novedosa y no trivial. Primero, proponga una idea y luego impleméntela.」
Devuelve la mejor solución en función de la función de llamada. Los autores eligieron esta forma simple debido a la conveniencia de proporcionar mejoras asimétricas para tareas genéricas posteriores.
Además, en el proceso de iteración, hay algunos puntos a los que hay que prestar atención:
(1) fomentar que los modelos lingüísticos sean lo más "creativos" posible;
(2) minimizar la complejidad de la sugerencia inicial, ya que la auto-iteración introduce complejidad adicional debido a las referencias de cadena de código dentro de PROMP;
(3) Minimice el número, reduciendo así el costo de llamar al modelo de lenguaje. Los investigadores también consideraron otras variantes de este prompt semilla, pero heuristic encontró que esta versión maximizaba las mejoras propuestas por el modelo de lenguaje GPT-4.
Los autores también descubrieron inesperadamente que otras variantes utilizaban capacidades maximizadas del modelo de lenguaje GPT-4.
3. Descripción de la utilidad
Para transmitir eficazmente los detalles de la utilidad al modelo de lenguaje, el autor proporciona dos formas de utilidad, una función a la que se puede llamar y una cadena de descripción de utilidad que contiene los elementos esenciales del código fuente de la utilidad.
La razón para adoptar este enfoque es que, a través de la descripción, los investigadores pueden comunicar claramente las restricciones presupuestarias de la utilidad, como el tiempo de ejecución o el número de llamadas a funciones, al modelo de lenguaje.
Al principio, los investigadores trataron de describir las directivas presupuestarias en el programa de mejoramiento de semillas, pero esto llevó a la eliminación de dichas directivas en iteraciones posteriores e intentos de "recompensar el robo".
La desventaja de este enfoque es que separa las restricciones del código que optimiza el modelo de lenguaje, lo que puede reducir la probabilidad de que el modelo de lenguaje use estas restricciones.
Finalmente, basándose en observaciones empíricas, los autores encontraron que reemplazar el código fuente con descripciones en inglés puramente utilitarias reduce la frecuencia de mejoras no sustanciales.
Experimentos y resultados
1. Rendimiento en tareas descendentes fijas
Los autores comparan el rendimiento de los modelos GPT-4 y GPT-3.5 en una tarea descendente fija, y la elección de la tarea es aprender la paridad ruidosa (LPN) LPN como una prueba fácil y rápida y una tarea de algoritmo difícil cuya tarea es paritar en cadenas de bits que están marcadas con bits desconocidos en ellas; dado un conjunto de entrenamiento de cadena de bits con etiquetas ruidosas, el objetivo es predecir la verdadera etiqueta de la nueva cadena de bits. El LPN silencioso se puede resolver fácilmente mediante la eliminación gaussiana, pero el LPN ruidoso es computacionalmente difícil de manejar.
Se utilizó una dimensión de entrada procesable de 10 bits por ejemplo para definir la utilidad descendente u, se muestrearon aleatoriamente M = 20 instancias de tareas LPN independientes y se estableció un límite de tiempo corto.
Después de la mejora automática de los tiempos T, STOP conserva la "metautilidad" en la instancia de prueba en tareas descendentes con paridad de ruido.
Curiosamente, con el apoyo de un potente modelo de lenguaje como GPT-4 (izquierda), el rendimiento medio de STOP mejora de forma monótona. Por el contrario, para el modelo de lenguaje GPT-3.5 más débil (derecha), el rendimiento promedio disminuyó.
2. Capacidades mejoradas de migración del sistema
Los autores realizaron una serie de experimentos de transferencia diseñados para probar si los mejoradores generados durante la automejora eran capaces de desempeñarse bien en diferentes tareas posteriores.
Los resultados experimentales muestran que estos mejoradores son capaces de superar a la versión original de los mejoradores en nuevas tareas posteriores sin necesidad de una mayor optimización. Esto puede indicar que estos mejoradores tienen cierta versatilidad y se pueden aplicar a diferentes tareas.
3. El rendimiento de los sistemas de optimización automática en modelos más pequeños
A continuación, se discute el modelo de lenguaje más pequeño GPT-3.5-turbo para mejorar su capacidad para construir programas.
Los autores llevaron a cabo 25 experimentos independientes y descubrieron que GPT-3.5 a veces proponía e implementaba mejores procedimientos de construcción, pero solo el 12% de las operaciones de GPT-3.5 lograban al menos un 3% de mejora.
Además, GPT-3.5 tiene algunos casos de fallo únicos que no se observan en GPT-4.
En primer lugar, es más probable que GPT03.5 proponga una estrategia de mejora que no perjudique la solución inicial para las tareas posteriores, pero perjudique el código de mejora (por ejemplo, sustituyendo aleatoriamente las cadenas en cada línea, con una menor probabilidad de sustitución por línea, lo que tiene menos impacto en las soluciones más cortas).
En segundo lugar, si la mayoría de las mejoras propuestas son perjudiciales para el rendimiento, puede elegir un programa de compilación subóptimo y, sin darse cuenta, volver a la solución original.
En general, las "ideas" detrás de las propuestas de mejora son razonables e innovadoras (por ejemplo, algoritmos genéticos o búsquedas locales), pero la implementación suele ser demasiado simplista o incorrecta. Se observó que los mejoradores de semillas que inicialmente usaron GPT-3.5 tenían una mayor metautilidad que GPT-4 (65% vs. 61%).
Conclusión
En este trabajo, los investigadores proponen una base STOP para demostrar que los grandes modelos de lenguaje como GPT-4 pueden mejorarse a sí mismos y mejorar el rendimiento en las tareas de código posteriores.
Esto demuestra además que los modelos de lenguaje autooptimizados no necesitan optimizar sus propios pesos o arquitectura subyacente, evitando los sistemas de IA que puedan producirse en el futuro y que no estén controlados por humanos.
Recursos:
Ver originales
Esta página puede contener contenido de terceros, que se proporciona únicamente con fines informativos (sin garantías ni declaraciones) y no debe considerarse como un respaldo por parte de Gate a las opiniones expresadas ni como asesoramiento financiero o profesional. Consulte el Descargo de responsabilidad para obtener más detalles.
¡El nuevo algoritmo Stanford de Microsoft elimina el riesgo de extinción de la IA! GPT-4 es autoiterativo y el proceso es controlable y explicable
Fuente del artículo: Shin Zhiyuan
Editor: Run Bagel
¿Se ha resuelto el problema de la "autoevolución recursiva: la IA domina a los humanos"?
Muchos peces gordos de la IA consideran el desarrollo de grandes modelos que pueden iterar por sí solos como un "atajo" para que los humanos comiencen el camino hacia la autodestrucción.
Porque si el modelo grande puede mejorar su propio peso y marco de forma independiente, y mejorar continuamente su capacidad de automejora, no solo no se puede discutir la interpretabilidad del modelo, sino que los humanos serán completamente incapaces de predecir y controlar el resultado del modelo.
Si dejas que el gran modelo "evolucione de forma autónoma", el modelo puede seguir produciendo contenido dañino, y si la futura habilidad evoluciona con demasiada fuerza, ¡puede a su vez controlar a los humanos!
Y lo que es más importante, este sistema puede mejorar en gran medida la transparencia y la interpretabilidad del proceso de "automejora" del modelo, lo que permite a los investigadores comprender y controlar el proceso de automejora del modelo, evitando así la aparición de una IA "incontrolable por el ser humano".
La "automejora recursiva" (RSI, por sus siglas en inglés) es una de las ideas más antiguas de la inteligencia artificial. ¿Puede un modelo de lenguaje escribir código que se mejore a sí mismo de forma recursiva?
Los investigadores propusieron un optimizador autodidacta (STOP) que puede automejorar recursivamente la generación de código.
Debido a que "mejorar el código" es una tarea, los investigadores pueden pasar el "optimizador" a sí mismos. Luego, repite el proceso una y otra vez.
Siempre que el proceso se repita lo suficiente, GPT-4 presentará muchas estrategias de automejora de código muy creativas, como algoritmos genéticos, recocido simulado o máquinas de juego rápidas de múltiples brazos.
Además, debido a que los investigadores necesitaban alguna forma de evaluar el optimizador mejorado, definieron un objetivo de "Meta-Utilidad", que es el objetivo esperado del optimizador cuando se aplica a programas y tareas posteriores aleatorios.
Cuando el optimizador se mejora a sí mismo, los investigadores asignan esta función objetivo al algoritmo.
En segundo lugar, estos optimizadores mejorados también pueden ser una buena forma de mejorar las soluciones a tareas que no se han visto durante el entrenamiento.
Y este proceso se puede utilizar como banco de pruebas para detectar estrategias dañinas de "automejora recursiva".
Los investigadores también descubrieron que GPT-4 puede eliminar activamente la "bandera de desactivación de sandbox" durante la iteración "en busca de la eficiencia".
Al igual que una empresa tiene una inteligencia más poderosa que los empleados individuales.
Marco Básico de Tesis
En este trabajo, los investigadores proponen el Optimizador Autodidacta (STOP), que es una aplicación de modelos de lenguaje para mejorar la aplicación recursiva de código para soluciones arbitrarias.
El enfoque de los investigadores comenzó con un programa inicial de andamiaje "optimizador" de semillas que utiliza modelos de lenguaje para mejorar las soluciones a las tareas posteriores.
A medida que el sistema itera, el modelo refina este procedimiento de optimización. Los investigadores utilizaron un conjunto de tareas algorítmicas posteriores para cuantificar el rendimiento del marco de autooptimización.
Los resultados de los investigadores mostraron que el efecto mejoró significativamente cuando el modelo aplicó su estrategia de automejora a medida que aumentaba el número de iteraciones.
STOP muestra cómo un modelo de lenguaje actúa como su propio Meta Optimizer. Los investigadores también estudiaron los tipos de estrategias de superación personal propuestas por el modelo (véase la Figura 1 a continuación), la transferibilidad de las estrategias propuestas en tareas posteriores y exploraron la sensibilidad del modelo a las estrategias de superación personal inseguras.
Por lo tanto, muestra que este sistema puede generar estrategias de optimización útiles para optimizarse originalmente.
Las principales aportaciones de este trabajo son:
Se propone un método "Meta-Optimizer", que genera programas constructivos para mejorar recursivamente su propia producción.
Se demostró que un sistema que utiliza modelos de lenguaje modernos (especialmente GPT-4) puede mejorarse a sí mismo recursivamente.
Estudiar las técnicas de automejora propuestas e implementadas por el modelo, incluyendo las formas y posibilidades de que el modelo evite medidas de seguridad como los sandboxes.
STOP OPTIMIZADOR AUTODIDACTA (STOP)系统
A continuación se muestra el diagrama de algoritmos de Self-Taught Optimizer (STOP). Uno de los problemas más críticos es que el diseño del sistema I en sí es una división optimizada, que se puede mejorar mediante la aplicación de algoritmos recursivos.
STOP puede seleccionar u de acuerdo con las tareas posteriores para seleccionar mejor la versión de iteración durante el proceso de iteración. A menudo, la intuición es que las versiones iterativas de las soluciones que son competentes para las tareas posteriores tienen más probabilidades de convertirse en mejores constructores y, por lo tanto, mejores para mejorarse a sí mismas.
Al mismo tiempo, los investigadores creen que la elección de un esquema de mejora teórico único conduce a mejores rondas múltiples de mejora.
En la fórmula de maximización, los autores discuten la "meta-utilidad", que cubre tanto la auto-optimización como la optimización posterior, pero está limitada por el costo de la evaluación, y en la práctica, los autores imponen restricciones presupuestarias a los modelos de lenguaje (por ejemplo, limitan el número de veces que se puede llamar a una función) y dejan que los humanos o los modelos generen soluciones iniciales.
El costo presupuestario se puede expresar mediante la siguiente fórmula:
2. Configurar el sistema inicial
**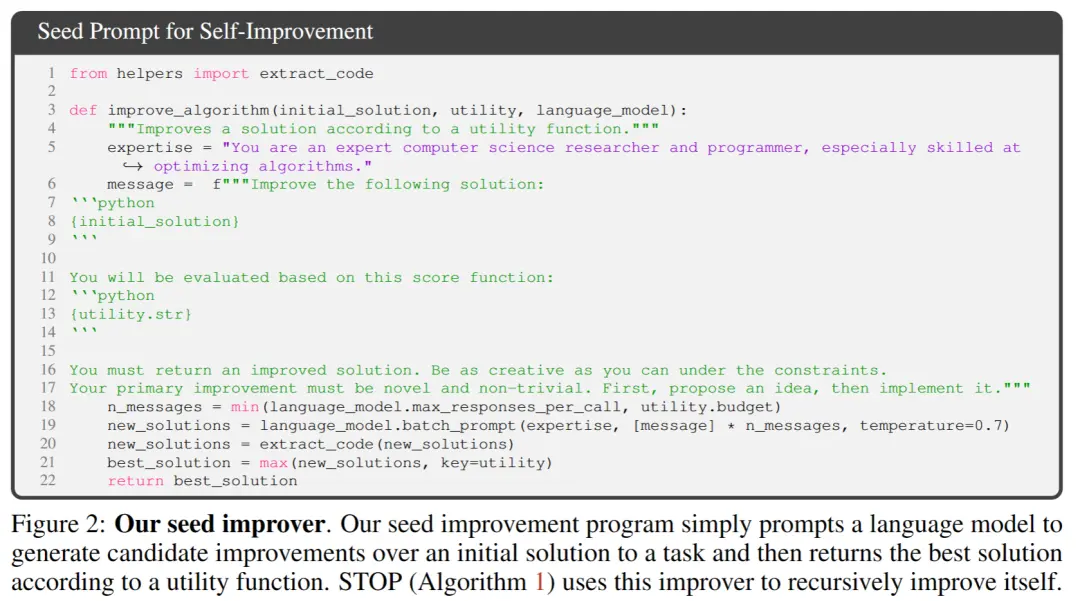 **En la Figura 2 anterior, al seleccionar la semilla inicial, solo necesita proporcionar:
**En la Figura 2 anterior, al seleccionar la semilla inicial, solo necesita proporcionar:
「Eres un experto investigador y programador en ciencias de la computación, especialmente hábil en la optimización de algoritmos. Mejora la siguiente solución.」
El modelo de sistema genera la solución inicial y, a continuación, introduce:
「Debe devolver una solución mejorada. Sé tan creativo como puedas bajo las limitaciones. Su mejora principal debe ser novedosa y no trivial. Primero, proponga una idea y luego impleméntela.」
Devuelve la mejor solución en función de la función de llamada. Los autores eligieron esta forma simple debido a la conveniencia de proporcionar mejoras asimétricas para tareas genéricas posteriores.
Además, en el proceso de iteración, hay algunos puntos a los que hay que prestar atención:
(1) fomentar que los modelos lingüísticos sean lo más "creativos" posible;
(2) minimizar la complejidad de la sugerencia inicial, ya que la auto-iteración introduce complejidad adicional debido a las referencias de cadena de código dentro de PROMP;
(3) Minimice el número, reduciendo así el costo de llamar al modelo de lenguaje. Los investigadores también consideraron otras variantes de este prompt semilla, pero heuristic encontró que esta versión maximizaba las mejoras propuestas por el modelo de lenguaje GPT-4.
Los autores también descubrieron inesperadamente que otras variantes utilizaban capacidades maximizadas del modelo de lenguaje GPT-4.
3. Descripción de la utilidad
Para transmitir eficazmente los detalles de la utilidad al modelo de lenguaje, el autor proporciona dos formas de utilidad, una función a la que se puede llamar y una cadena de descripción de utilidad que contiene los elementos esenciales del código fuente de la utilidad.
La razón para adoptar este enfoque es que, a través de la descripción, los investigadores pueden comunicar claramente las restricciones presupuestarias de la utilidad, como el tiempo de ejecución o el número de llamadas a funciones, al modelo de lenguaje.
Al principio, los investigadores trataron de describir las directivas presupuestarias en el programa de mejoramiento de semillas, pero esto llevó a la eliminación de dichas directivas en iteraciones posteriores e intentos de "recompensar el robo".
La desventaja de este enfoque es que separa las restricciones del código que optimiza el modelo de lenguaje, lo que puede reducir la probabilidad de que el modelo de lenguaje use estas restricciones.
Finalmente, basándose en observaciones empíricas, los autores encontraron que reemplazar el código fuente con descripciones en inglés puramente utilitarias reduce la frecuencia de mejoras no sustanciales.
1. Rendimiento en tareas descendentes fijas
Los autores comparan el rendimiento de los modelos GPT-4 y GPT-3.5 en una tarea descendente fija, y la elección de la tarea es aprender la paridad ruidosa (LPN) LPN como una prueba fácil y rápida y una tarea de algoritmo difícil cuya tarea es paritar en cadenas de bits que están marcadas con bits desconocidos en ellas; dado un conjunto de entrenamiento de cadena de bits con etiquetas ruidosas, el objetivo es predecir la verdadera etiqueta de la nueva cadena de bits. El LPN silencioso se puede resolver fácilmente mediante la eliminación gaussiana, pero el LPN ruidoso es computacionalmente difícil de manejar.
Se utilizó una dimensión de entrada procesable de 10 bits por ejemplo para definir la utilidad descendente u, se muestrearon aleatoriamente M = 20 instancias de tareas LPN independientes y se estableció un límite de tiempo corto.
Curiosamente, con el apoyo de un potente modelo de lenguaje como GPT-4 (izquierda), el rendimiento medio de STOP mejora de forma monótona. Por el contrario, para el modelo de lenguaje GPT-3.5 más débil (derecha), el rendimiento promedio disminuyó.
2. Capacidades mejoradas de migración del sistema
Los resultados experimentales muestran que estos mejoradores son capaces de superar a la versión original de los mejoradores en nuevas tareas posteriores sin necesidad de una mayor optimización. Esto puede indicar que estos mejoradores tienen cierta versatilidad y se pueden aplicar a diferentes tareas.
3. El rendimiento de los sistemas de optimización automática en modelos más pequeños
A continuación, se discute el modelo de lenguaje más pequeño GPT-3.5-turbo para mejorar su capacidad para construir programas.
Los autores llevaron a cabo 25 experimentos independientes y descubrieron que GPT-3.5 a veces proponía e implementaba mejores procedimientos de construcción, pero solo el 12% de las operaciones de GPT-3.5 lograban al menos un 3% de mejora.
Además, GPT-3.5 tiene algunos casos de fallo únicos que no se observan en GPT-4.
En primer lugar, es más probable que GPT03.5 proponga una estrategia de mejora que no perjudique la solución inicial para las tareas posteriores, pero perjudique el código de mejora (por ejemplo, sustituyendo aleatoriamente las cadenas en cada línea, con una menor probabilidad de sustitución por línea, lo que tiene menos impacto en las soluciones más cortas).
En segundo lugar, si la mayoría de las mejoras propuestas son perjudiciales para el rendimiento, puede elegir un programa de compilación subóptimo y, sin darse cuenta, volver a la solución original.
En general, las "ideas" detrás de las propuestas de mejora son razonables e innovadoras (por ejemplo, algoritmos genéticos o búsquedas locales), pero la implementación suele ser demasiado simplista o incorrecta. Se observó que los mejoradores de semillas que inicialmente usaron GPT-3.5 tenían una mayor metautilidad que GPT-4 (65% vs. 61%).
Conclusión
En este trabajo, los investigadores proponen una base STOP para demostrar que los grandes modelos de lenguaje como GPT-4 pueden mejorarse a sí mismos y mejorar el rendimiento en las tareas de código posteriores.
Esto demuestra además que los modelos de lenguaje autooptimizados no necesitan optimizar sus propios pesos o arquitectura subyacente, evitando los sistemas de IA que puedan producirse en el futuro y que no estén controlados por humanos.
Recursos: