¡Haz que los modelos grandes miren diagramas que escribir funciona! Un nuevo estudio de NeurIPS 2023 propone un método de consulta multimodal, la precisión mejora en un 7,8%
La capacidad de los grandes modelos para "leer imágenes" es tan fuerte, ¿por qué sigues buscando las cosas equivocadas?
Por ejemplo, confundir murciélagos que no se parecen a ellos con raquetas, o no reconocer peces raros en algunos conjuntos de datos...
Esto se debe a que cuando dejamos que un modelo grande "encuentre algo", a menudo ingresamos texto.
Si la descripción es ambigua o demasiado parcial, como "murciélago" (¿murciélago o golpe?). O "Cyprinodon diabolis", y la IA se confundirá.
Esto lleva al uso de modelos grandes para realizar ** detección de objetos **, especialmente tareas de detección de objetos de mundo abierto (escena desconocida), el efecto a menudo no es tan bueno como se esperaba.
Ahora, un artículo incluido en NeurIPS 2023 finalmente ha resuelto este problema.
En este artículo se propone un método de detección de objetos MQ-Det basado en la consulta multimodal, que solo necesita añadir un ejemplo de imagen a la entrada, lo que puede mejorar en gran medida la precisión de la búsqueda de cosas en modelos grandes.
En el conjunto de datos de detección de referencia LVIS, MQ-Det mejora la precisión de GLIP de los modelos grandes de detección convencionales en aproximadamente un 7,8 % de media, y mejora la precisión de 13 tareas posteriores de referencia de muestras pequeñas en un promedio del 6,3 %.
¿Cómo se hace esto exactamente? Echemos un vistazo.
Lo siguiente es una reproducción del autor del artículo, el bloguero Zhihu @Qinyuanxia:
Tabla de contenido
MQ-Det: Modelo grande de detección de objetos de mundo abierto para consultas multimodales
1.1 De la consulta de texto a la consulta multimodal
1.2 Arquitectura de modelo de consulta multimodal plug-and-play MQ-Det
1.3 Estrategia de entrenamiento eficiente MQ-Det
1.4 Resultados experimentales: Evaluación sin ajuste fino
*1.5 Resultados experimentales: Evaluación de pocos disparos
1.6 Consulta multimodal de la perspectiva de detección de objetos
MQ-DET: Modelo grande de detección de objetos de mundo abierto para consultas multimodales**
Detección multimodal de objetos consultados en la naturaleza
Enlace de papel:
Dirección del código:**
### 1.1 De la consulta de texto a la consulta multimodal
Una imagen vale más que mil palabras: Con el auge del preentrenamiento gráfico, con la ayuda de la semántica abierta del texto, la detección de objetos ha entrado gradualmente en la etapa de percepción del mundo abierto. Por este motivo, muchos modelos de detección de gran tamaño siguen el patrón de consulta de texto, es decir, el uso de descripciones de texto categóricas para consultar posibles destinos en imágenes de destino. Sin embargo, este enfoque a menudo se enfrenta al problema de ser "amplio pero no refinado".
Por ejemplo, (1) la detección de objetos de grano fino (alevines) en la Figura 1 es a menudo difícil de describir las diversas especies de grano fino con un texto limitado, y (2) la ambigüedad de la categoría ("murciélago" puede referirse tanto a un murciélago como a una raqueta).
Sin embargo, los problemas anteriores se pueden resolver con ejemplos de imágenes, que proporcionan pistas de características más ricas para el objeto de destino que el texto, pero al mismo tiempo el texto tiene una fuerte generalización.
Por lo tanto, cómo combinar orgánicamente los dos métodos de consulta se ha convertido en una idea natural.
Dificultades para obtener capacidades de consulta multimodal: Hay tres desafíos en la forma de obtener un modelo de este tipo con consultas multimodales: (1) el ajuste fino directo con ejemplos de imágenes limitados puede conducir fácilmente a un olvido catastrófico; (2) El entrenamiento de un modelo de detección grande desde cero tendrá una buena generalización, pero un gran consumo, por ejemplo, el entrenamiento de una sola tarjeta GLIP requiere 480 días de entrenamiento con un volumen de 30 millones de datos.
Detección de objetos de consulta multimodal: Con base en las consideraciones anteriores, el autor propone una estrategia de diseño y entrenamiento de modelos simple y efectiva: MQ-Det.
MQ-Det inserta un pequeño número de módulos de percepción cerrada (GCP) para recibir la entrada de ejemplos visuales sobre la base del modelo grande de detección de consultas de texto congelado existente, y diseña una estrategia de entrenamiento de predicción de lenguaje de máscara de condición visual para obtener de manera eficiente un detector para consultas multimodales de alto rendimiento.
1.2 Arquitectura del modelo de consulta multimodal plug-and-play MQ-Det
** **####### △Figura 1 Diagrama de arquitectura del método MQ-Det
Módulo de percepción cerrada
Como se muestra en la Figura 1, el autor inserta un módulo de reconocimiento de compuerta (GCP) capa por capa en el lado del codificador de texto del modelo grande de detección de consultas de texto congelado existente, y el modo de trabajo de GCP se puede representar sucintamente mediante la siguiente fórmula:
Para la i-ésima categoría, introduzca el ejemplo visual Vi, que primero cruza la atención (X-MHA) con la imagen objetivo I
para ampliar sus capacidades de representación, y luego cada categoría texto ti y el ejemplo visual de la categoría correspondiente
Llevar a cabo la atención cruzada obtiene
, después de lo cual el texto original ti y el aumento visual del texto se ven reforzados por una puerta de módulo de compuerta
Fusión para obtener la salida de la capa actual
。 Este sencillo diseño sigue tres principios: (1) escalabilidad de categorías; (2) completitud semántica; (3) Antiamnesia, se puede encontrar una discusión específica en el texto original.
1.3 Estrategia de entrenamiento eficiente de MQ-det
Entrenamiento de modulación basado en detector de consultas de lenguaje congelado
Dado que el modelo grande de detección previa al entrenamiento actual de consulta de texto en sí mismo tiene una buena generalización, los autores creen que solo es necesario realizar ligeros ajustes con detalles visuales sobre la base de las características del texto original.
En el artículo, también hay una demostración experimental específica de que es fácil provocar un olvido catastrófico después de abrir los parámetros del modelo original preentrenado y ajustarlo, pero perder la capacidad de detección de mundo abierto.
Por lo tanto, MQ-Det puede insertar de manera eficiente información visual en el detector de consultas de texto existentes sobre la base del detector preentrenado de consultas de texto congelado y solo modular el módulo GCP insertado por entrenamiento.
En el artículo, los autores aplican el diseño estructural y las técnicas de entrenamiento de MQ-Det a los modelos actuales de SOTA GLIP y GroundingDINO respectivamente para verificar la versatilidad del método.
Enmascarar la estrategia de entrenamiento de predicción del lenguaje con condición visual
Los autores también proponen una estrategia de entrenamiento predictivo de lenguaje de enmascaramiento visualmente condicionado para resolver el problema de la pereza de aprendizaje causada por la congelación de modelos preentrenados.
La llamada pereza de aprendizaje significa que el detector tiende a mantener las características de la consulta de texto original durante el proceso de entrenamiento, ignorando así las características de consulta visual recién agregadas.
Para ello, MQ-Det se utiliza de forma aleatoria durante el entrenamiento[MASK] token reemplaza al token de texto, lo que obliga al modelo a aprender del lado de la característica de consulta visual, a saber:
Aunque esta estrategia es simple, es muy efectiva y, a partir de los resultados experimentales, esta estrategia ha traído una mejora significativa del rendimiento.
1.4 Resultados experimentales: Evaluación sin ajustes
Sin ajustes: MQ-Det propone una estrategia de evaluación más práctica: sin ajustes, en comparación con la evaluación tradicional de disparo cero que utiliza solo texto de categoría. Se define como la detección de objetos mediante texto de categoría, ejemplos de imágenes o una combinación de ambos sin ningún ajuste fino posterior.
En la configuración sin ajustes, MQ-Det selecciona 5 ejemplos visuales para cada categoría y combina el texto de la categoría para la detección de objetos, mientras que otros modelos existentes no admiten consultas visuales y solo pueden usar descripciones de texto sin formato para la detección de objetos. La siguiente tabla muestra los resultados de LVIS MiniVal y LVIS v1.0. Se puede encontrar que la introducción de la consulta multimodal ha mejorado en gran medida la capacidad de detección de objetos de mundo abierto.
** **###### △Tabla 1 Rendimiento sin ajuste fino de cada modelo de detección en el conjunto de datos de referencia LVIS
Como se puede ver en la Tabla 1, MQ-GLIP-L ha mejorado la PA en más de un 7% sobre la base de GLIP-L, ¡y el efecto es muy significativo!
1.5 Resultados experimentales: Evaluación de pocos disparos
** **####### △Tabla 2 Rendimiento de cada modelo en ODinW-35 y 13 subconjuntos de ODinW-13 en 35 tareas de detección
Además, los autores realizaron experimentos exhaustivos en ODinW-35, una tarea de detección 35 aguas abajo. Como se puede ver en la Tabla 2, MQ-Det no solo tiene un fuerte rendimiento sin ajustes, sino que también tiene buenas capacidades de detección de muestras pequeñas, lo que confirma aún más el potencial de las consultas multimodales. La Figura 2 también muestra la mejora significativa de MQ-Det a GLIP.
** **###### △Figura 2 Comparación de la eficiencia de la utilización de datos; Eje horizontal: el número de muestras de entrenamiento, eje vertical: AP promedio en OdinW-13
1.6 Perspectivas para la detección de objetos de consulta multimodal
Como campo de investigación basado en aplicaciones prácticas, la detección de objetos presta gran atención al aterrizaje de algoritmos.
Aunque el modelo anterior de detección de objetos de consulta de texto sin formato muestra una buena generalización, es difícil cubrir información detallada en el chino de detección de mundo abierto real, y la rica granularidad de la información en la imagen completa perfectamente este vínculo.
Hasta ahora, podemos encontrar que el texto es genérico pero no preciso, y la imagen es precisa pero no general, y si podemos combinar efectivamente los dos, es decir, la consulta multimodal, promoverá que la detección de objetos de mundo abierto avance más.
MQ-Det ha dado el primer paso en la consulta multimodal, y su mejora significativa en el rendimiento también muestra el gran potencial de la detección de objetivos de consulta multimodal.
Al mismo tiempo, la introducción de descripciones de texto y ejemplos visuales proporciona a los usuarios más opciones, lo que hace que la detección de objetos sea más flexible y fácil de usar.
Enlace original:
Ver originales
Esta página puede contener contenido de terceros, que se proporciona únicamente con fines informativos (sin garantías ni declaraciones) y no debe considerarse como un respaldo por parte de Gate a las opiniones expresadas ni como asesoramiento financiero o profesional. Consulte el Descargo de responsabilidad para obtener más detalles.
¡Haz que los modelos grandes miren diagramas que escribir funciona! Un nuevo estudio de NeurIPS 2023 propone un método de consulta multimodal, la precisión mejora en un 7,8%
Fuente original: Qubits
La capacidad de los grandes modelos para "leer imágenes" es tan fuerte, ¿por qué sigues buscando las cosas equivocadas?
Por ejemplo, confundir murciélagos que no se parecen a ellos con raquetas, o no reconocer peces raros en algunos conjuntos de datos...
Si la descripción es ambigua o demasiado parcial, como "murciélago" (¿murciélago o golpe?). O "Cyprinodon diabolis", y la IA se confundirá.
Esto lleva al uso de modelos grandes para realizar ** detección de objetos **, especialmente tareas de detección de objetos de mundo abierto (escena desconocida), el efecto a menudo no es tan bueno como se esperaba.
Ahora, un artículo incluido en NeurIPS 2023 finalmente ha resuelto este problema.
En el conjunto de datos de detección de referencia LVIS, MQ-Det mejora la precisión de GLIP de los modelos grandes de detección convencionales en aproximadamente un 7,8 % de media, y mejora la precisión de 13 tareas posteriores de referencia de muestras pequeñas en un promedio del 6,3 %.
¿Cómo se hace esto exactamente? Echemos un vistazo.
Lo siguiente es una reproducción del autor del artículo, el bloguero Zhihu @Qinyuanxia:
Tabla de contenido
MQ-DET: Modelo grande de detección de objetos de mundo abierto para consultas multimodales**
Detección multimodal de objetos consultados en la naturaleza
Enlace de papel:
Dirección del código:**
Una imagen vale más que mil palabras: Con el auge del preentrenamiento gráfico, con la ayuda de la semántica abierta del texto, la detección de objetos ha entrado gradualmente en la etapa de percepción del mundo abierto. Por este motivo, muchos modelos de detección de gran tamaño siguen el patrón de consulta de texto, es decir, el uso de descripciones de texto categóricas para consultar posibles destinos en imágenes de destino. Sin embargo, este enfoque a menudo se enfrenta al problema de ser "amplio pero no refinado".
Por ejemplo, (1) la detección de objetos de grano fino (alevines) en la Figura 1 es a menudo difícil de describir las diversas especies de grano fino con un texto limitado, y (2) la ambigüedad de la categoría ("murciélago" puede referirse tanto a un murciélago como a una raqueta).
Sin embargo, los problemas anteriores se pueden resolver con ejemplos de imágenes, que proporcionan pistas de características más ricas para el objeto de destino que el texto, pero al mismo tiempo el texto tiene una fuerte generalización.
Por lo tanto, cómo combinar orgánicamente los dos métodos de consulta se ha convertido en una idea natural.
Dificultades para obtener capacidades de consulta multimodal: Hay tres desafíos en la forma de obtener un modelo de este tipo con consultas multimodales: (1) el ajuste fino directo con ejemplos de imágenes limitados puede conducir fácilmente a un olvido catastrófico; (2) El entrenamiento de un modelo de detección grande desde cero tendrá una buena generalización, pero un gran consumo, por ejemplo, el entrenamiento de una sola tarjeta GLIP requiere 480 días de entrenamiento con un volumen de 30 millones de datos.
Detección de objetos de consulta multimodal: Con base en las consideraciones anteriores, el autor propone una estrategia de diseño y entrenamiento de modelos simple y efectiva: MQ-Det.
MQ-Det inserta un pequeño número de módulos de percepción cerrada (GCP) para recibir la entrada de ejemplos visuales sobre la base del modelo grande de detección de consultas de texto congelado existente, y diseña una estrategia de entrenamiento de predicción de lenguaje de máscara de condición visual para obtener de manera eficiente un detector para consultas multimodales de alto rendimiento.
1.2 Arquitectura del modelo de consulta multimodal plug-and-play MQ-Det
** **####### △Figura 1 Diagrama de arquitectura del método MQ-Det
**####### △Figura 1 Diagrama de arquitectura del método MQ-Det
Módulo de percepción cerrada
Como se muestra en la Figura 1, el autor inserta un módulo de reconocimiento de compuerta (GCP) capa por capa en el lado del codificador de texto del modelo grande de detección de consultas de texto congelado existente, y el modo de trabajo de GCP se puede representar sucintamente mediante la siguiente fórmula:
1.3 Estrategia de entrenamiento eficiente de MQ-det
Entrenamiento de modulación basado en detector de consultas de lenguaje congelado
Dado que el modelo grande de detección previa al entrenamiento actual de consulta de texto en sí mismo tiene una buena generalización, los autores creen que solo es necesario realizar ligeros ajustes con detalles visuales sobre la base de las características del texto original.
En el artículo, también hay una demostración experimental específica de que es fácil provocar un olvido catastrófico después de abrir los parámetros del modelo original preentrenado y ajustarlo, pero perder la capacidad de detección de mundo abierto.
Por lo tanto, MQ-Det puede insertar de manera eficiente información visual en el detector de consultas de texto existentes sobre la base del detector preentrenado de consultas de texto congelado y solo modular el módulo GCP insertado por entrenamiento.
En el artículo, los autores aplican el diseño estructural y las técnicas de entrenamiento de MQ-Det a los modelos actuales de SOTA GLIP y GroundingDINO respectivamente para verificar la versatilidad del método.
Enmascarar la estrategia de entrenamiento de predicción del lenguaje con condición visual
Los autores también proponen una estrategia de entrenamiento predictivo de lenguaje de enmascaramiento visualmente condicionado para resolver el problema de la pereza de aprendizaje causada por la congelación de modelos preentrenados.
La llamada pereza de aprendizaje significa que el detector tiende a mantener las características de la consulta de texto original durante el proceso de entrenamiento, ignorando así las características de consulta visual recién agregadas.
Para ello, MQ-Det se utiliza de forma aleatoria durante el entrenamiento[MASK] token reemplaza al token de texto, lo que obliga al modelo a aprender del lado de la característica de consulta visual, a saber:
1.4 Resultados experimentales: Evaluación sin ajustes
Sin ajustes: MQ-Det propone una estrategia de evaluación más práctica: sin ajustes, en comparación con la evaluación tradicional de disparo cero que utiliza solo texto de categoría. Se define como la detección de objetos mediante texto de categoría, ejemplos de imágenes o una combinación de ambos sin ningún ajuste fino posterior.
En la configuración sin ajustes, MQ-Det selecciona 5 ejemplos visuales para cada categoría y combina el texto de la categoría para la detección de objetos, mientras que otros modelos existentes no admiten consultas visuales y solo pueden usar descripciones de texto sin formato para la detección de objetos. La siguiente tabla muestra los resultados de LVIS MiniVal y LVIS v1.0. Se puede encontrar que la introducción de la consulta multimodal ha mejorado en gran medida la capacidad de detección de objetos de mundo abierto.
**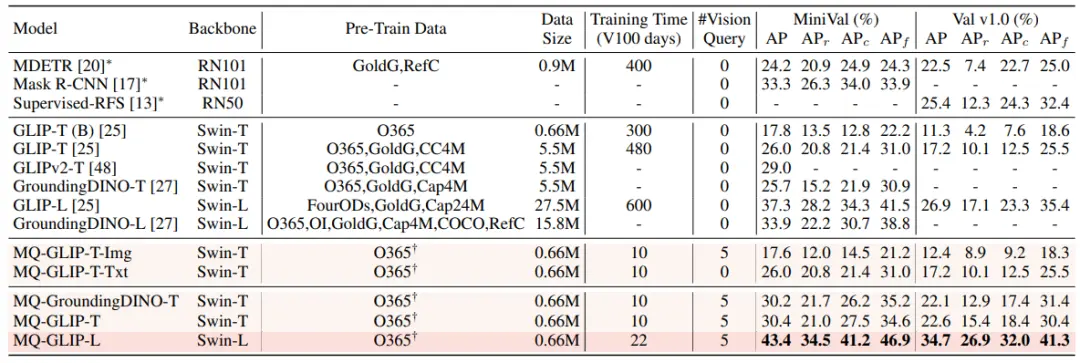 **###### △Tabla 1 Rendimiento sin ajuste fino de cada modelo de detección en el conjunto de datos de referencia LVIS
**###### △Tabla 1 Rendimiento sin ajuste fino de cada modelo de detección en el conjunto de datos de referencia LVIS
Como se puede ver en la Tabla 1, MQ-GLIP-L ha mejorado la PA en más de un 7% sobre la base de GLIP-L, ¡y el efecto es muy significativo!
1.5 Resultados experimentales: Evaluación de pocos disparos
**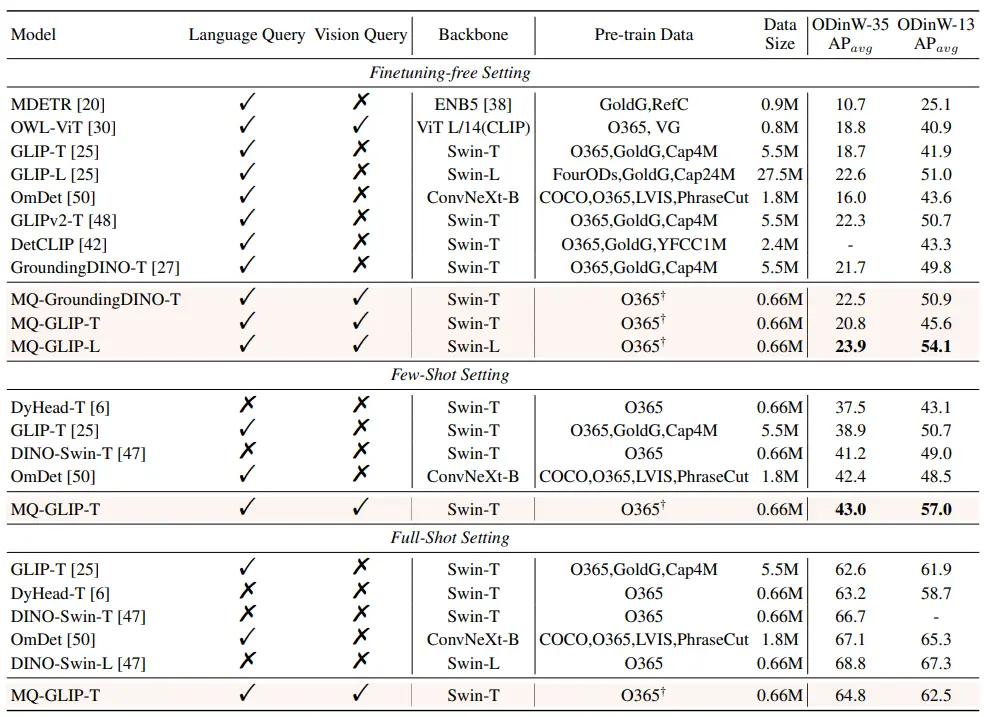 **####### △Tabla 2 Rendimiento de cada modelo en ODinW-35 y 13 subconjuntos de ODinW-13 en 35 tareas de detección
**####### △Tabla 2 Rendimiento de cada modelo en ODinW-35 y 13 subconjuntos de ODinW-13 en 35 tareas de detección
Además, los autores realizaron experimentos exhaustivos en ODinW-35, una tarea de detección 35 aguas abajo. Como se puede ver en la Tabla 2, MQ-Det no solo tiene un fuerte rendimiento sin ajustes, sino que también tiene buenas capacidades de detección de muestras pequeñas, lo que confirma aún más el potencial de las consultas multimodales. La Figura 2 también muestra la mejora significativa de MQ-Det a GLIP.
**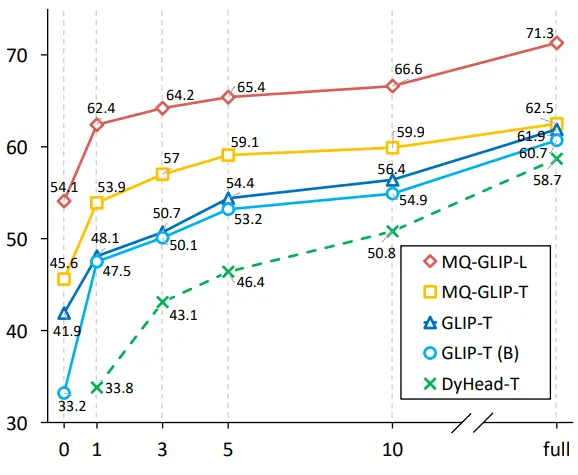 **###### △Figura 2 Comparación de la eficiencia de la utilización de datos; Eje horizontal: el número de muestras de entrenamiento, eje vertical: AP promedio en OdinW-13
**###### △Figura 2 Comparación de la eficiencia de la utilización de datos; Eje horizontal: el número de muestras de entrenamiento, eje vertical: AP promedio en OdinW-13
1.6 Perspectivas para la detección de objetos de consulta multimodal
Como campo de investigación basado en aplicaciones prácticas, la detección de objetos presta gran atención al aterrizaje de algoritmos.
Aunque el modelo anterior de detección de objetos de consulta de texto sin formato muestra una buena generalización, es difícil cubrir información detallada en el chino de detección de mundo abierto real, y la rica granularidad de la información en la imagen completa perfectamente este vínculo.
Hasta ahora, podemos encontrar que el texto es genérico pero no preciso, y la imagen es precisa pero no general, y si podemos combinar efectivamente los dos, es decir, la consulta multimodal, promoverá que la detección de objetos de mundo abierto avance más.
MQ-Det ha dado el primer paso en la consulta multimodal, y su mejora significativa en el rendimiento también muestra el gran potencial de la detección de objetivos de consulta multimodal.
Al mismo tiempo, la introducción de descripciones de texto y ejemplos visuales proporciona a los usuarios más opciones, lo que hace que la detección de objetos sea más flexible y fácil de usar.
Enlace original: