¡El mejor modelo 7B vuelve a cambiar de manos! Derrota a 70 mil millones de LLaMA2 y las computadoras de Apple podrán ejecutarse | código abierto y libre
¡El modelo de 7 mil millones de parámetros que tardó 500 dólares en "sintonizarse" derrotó al Llama 2 de 70 mil millones de parámetros!
Y el cuaderno puede ejecutarse fácilmente, y el efecto es comparable al de ChatGPT.
Importante: Gratis, sin dinero.
El modelo de código abierto Zephyr-7B creado por el equipo de HuggingFace H4, loco por los tiburones.
Su modelo subyacente es un modelo grande de código abierto Mistral-7B, que explotó hace algún tiempo y fue construido por Mistral AI, que se conoce como "European OpenAI".
Ya sabes, menos de 2 semanas después del lanzamiento del Mistral-7B, han aparecido varias versiones ajustadas una tras otra, y hay mucho estilo de "alpaca" que apareció rápidamente cuando se lanzó Llama por primera vez.
La clave de la capacidad de Zephyr para destacar entre las variantes fue que el equipo afinó el modelo en un conjunto de datos público utilizando la optimización de preferencias directas (DPO) sobre Mistral.
El equipo también descubrió que la eliminación de la alineación incorporada del conjunto de datos podría mejorar aún más el rendimiento de MT Bench. El Zephyr-7B-alpha original tenía una puntuación media de 7,09 en MT-Bench, superando al Llama2-70B-Chat.
** **###### △MT-Bench es una prueba de referencia para evaluar la capacidad del modelo para manejar múltiples rondas de diálogo, y el conjunto de preguntas cubre 8 categorías, como escritura, juego de roles y extracción.
¡El punto es que luego pasó a actualizarse!
El equipo de H4 lanzó la segunda generación de Zephyr-7B-beta. Agregaron que exploraron la idea de extraer la alineación de GPT-4, Claude 2 y luego inyectarla en modelos pequeños, desarrollando un método para usar la optimización de preferencia directa por destilación (dDPO) para modelos pequeños.
En la segunda generación de Zephyr, la puntuación media de MT-Bench aumentó a 7,34.
En Alpaca, Zephyr tiene una tasa de victorias del 90,6%, que es mejor que ChatGPT (3,5):
Los internautas que se apresuraron a Zephyr elogiaron unánimemente, y el equipo de lmsys también mostró la puntuación Elo de Zephyr-7b-beta, que se ha disparado muy alto 🔥:
La tabla de clasificación interna de la Arena ha superado los 13 mil millones de modelos.
Algunas personas incluso dijeron:
Ver que el enfoque de DPO funciona bien en el campo es probablemente lo más emocionante del desarrollo de grandes modelos de lenguaje este año.
Más internautas han comenzado a probar el efecto de Zephyr, y los resultados son sorprendentemente buenos.
La palabra Mistral significa viento seco, frío y fuerte en francés, mientras que Zephyr significa viento suave y agradable del oeste.
No hay duda de que hay un zoológico al otro lado de Llama, y no hay duda de que hay una oficina meteorológica en este lado.
El mejor modelo 7B vuelve a cambiar de manos
Comencemos con los requisitos de la computadora para ejecutar Zephyr. ¡Los internautas dijeron que "los pantalones tailandeses son picantes" después de la prueba! , el portátil (Apple M1 Pro) es suficiente, "el resultado es muy bueno".
En términos de efectividad, el equipo de Llama Index (anteriormente conocido como GPT Index) también lo probó.
Resulta que Zephyr es actualmente el único modelo 7B de código abierto que funciona bien en tareas RAG/agentic de alto nivel.
Los datos también muestran que el efecto de la tarea avanzada RAG de Zephyr puede competir con GPT-3.5 y Claude 2.
Agregaron que Zephyr no solo funciona bien en RAG, sino también en el enrutamiento, la planificación de consultas, la recuperación de instrucciones SQL complejas y la extracción de datos estructurados.
Los funcionarios también dieron los resultados de las pruebas, y en MT-Bench, Zephyr-7B-beta tiene un gran rendimiento en comparación con modelos más grandes como Llama2-Chat-70B.
Pero en tareas más complejas, como la codificación y las matemáticas, Zephyr-7B-beta se queda atrás de los modelos patentados y requiere más investigación para cerrar la brecha.
Abandonar el aprendizaje por refuerzo
Si bien todos están probando los efectos de Zephyr, los desarrolladores dicen que lo más interesante no son las métricas, sino la forma en que se entrena el modelo.
A continuación se resumen los aspectos más destacados:
Ajuste el mejor modelo preentrenado pequeño y de código abierto: Mistral 7B
Uso de conjuntos de datos de preferencias a gran escala: UltraFeedback
Utilice la optimización directa de preferencias (DPO) en lugar del aprendizaje por refuerzo
Inesperadamente, el sobreajuste del conjunto de datos de preferencias produce mejores resultados
A grandes rasgos, como se mencionó al principio, la razón principal por la que Zephyr es capaz de superar al 70B Llama 2 se debe al uso de un método especial de ajuste fino.
A diferencia del enfoque tradicional de aprendizaje por refuerzo PPO, el equipo de investigación utilizó una colaboración reciente entre la Universidad de Stanford y CZ Biohub para proponer un enfoque DPO.
Según los investigadores:
DPO es mucho más estable que PPO.
En términos simples, DPO se puede explicar de la siguiente manera:
Con el fin de hacer que el resultado del modelo esté más en línea con las preferencias humanas, el enfoque tradicional ha sido ajustar el modelo objetivo con un modelo de recompensa. Si el resultado es bueno, será recompensado, y si el resultado es malo, no será recompensado.
El enfoque DPO, por otro lado, omite la función de recompensa de modelado y es equivalente a optimizar el modelo directamente en los datos de preferencias.
En general, DPO resuelve el problema de la difícil y costosa formación de aprendizaje por refuerzo debido a la retroalimentación humana.
En términos específicos del entrenamiento de Zephyr, el equipo de investigación afinó inicialmente Zephyr-7B-alpha en una variante optimizada del conjunto de datos UltraChat, que contiene 1,6 millones de conversaciones generadas por ChatGPT (unas 200.000 restantes).
(La razón de la racionalización fue que el equipo descubrió que Zephyr a veces se entubaba incorrectamente, como "Hola. ¿Cómo estás?"; A veces, la respuesta comienza con "No tengo una X personal". )
Más tarde, alinearon aún más el modelo con el conjunto de datos openbmb/UltraFeedback disponible públicamente utilizando el método DPO Trainer de TRL.
El conjunto de datos contiene 64.000 pares de respuesta rápida de varios modelos. Cada respuesta se clasifica mediante GPT-4 en función de criterios como la utilidad y se le asigna una puntuación de la que se deriva una preferencia de IA.
Un hallazgo interesante es que cuando se utiliza el método DPO, el efecto es en realidad mejor después del sobreajuste a medida que aumenta el tiempo de entrenamiento. Los investigadores creen que esto es similar al sobreajuste en SFT.
Vale la pena mencionar que el equipo de investigación también introdujo que ajustar el modelo con este método cuesta solo $ 500, lo que equivale a 8 horas de funcionamiento en 16 A100.
Al actualizar Zephyr a la versión beta, el equipo pasó a explicar su enfoque.
Pensaron en el ajuste fino supervisado por destilación (dSFT) utilizado en modelos grandes, pero con este enfoque el modelo estaba desalineado y no producía resultados que coincidieran con la intención del usuario.
Por lo tanto, el equipo intentó utilizar los datos de preferencias de AI Feedback (AIF) para clasificar los resultados con un "modelo maestro" para formar un conjunto de datos y, a continuación, aplicar la optimización de preferencias directas por destilación (dDPO) para entrenar un modelo que se alineara con la intención del usuario sin ningún muestreo adicional durante el ajuste.
Los investigadores también probaron el efecto cuando no se utilizó SFT, y los resultados dieron como resultado una reducción significativa en el rendimiento, lo que indica que el paso dSFT es crítico.
En la actualidad, además de que el modelo ha sido de código abierto y comercial, también hay una Demo para probar, por lo que podemos empezar y experimentarlo de forma sencilla.
Experiencia de demostración
En primer lugar, tuve que salir de la pregunta de "discapacitado mental" para hacer un examen.
Sobre la pregunta "Mamá y papá no me lleven cuando se casen", la respuesta general de Zephyr es más precisa.
ChatGPT no puede superar esta pregunta.
En la prueba, también descubrimos que Zephyr también conoce eventos recientes como el lanzamiento de GPT-4 por parte de OpenAI:
En realidad, esto está relacionado con su modelo subyacente, aunque el funcionario de Mistral no especificó la fecha límite para los datos de entrenamiento.
Pero algunos internautas lo han probado antes, y también lo sabe en marzo de este año.
Por el contrario, los datos previos al entrenamiento de Llama 2 son a partir de septiembre de 2022, y solo algunos datos ajustados son hasta junio de 2023.
Además, Zephyr es muy receptivo, por lo que puedes escribir código e inventar historias. :
Vale la pena mencionar que Zephyr es mejor para responder preguntas en inglés, y también tiene un problema común con el modelo de "alucinación".
Los investigadores también mencionaron alucinaciones, y se marcó una pequeña línea de texto debajo del cuadro de entrada que indica que el contenido generado por el modelo puede ser inexacto o incorrecto.
La cuestión es que Zephyr no utiliza métodos como el aprendizaje por refuerzo con retroalimentación humana para alinearse con las preferencias humanas, ni utiliza el filtrado de respuestas de ChatGPT.
Elija siempre uno de los peces emmm y las patas de oso.
Zephyr fue capaz de hacer esto con solo 70B parámetros, lo que sorprendió a Andriy Burkov, autor de "El libro de aprendizaje automático de 100 páginas", e incluso dijo:
Zephyr-7B derrota a Llama 2-70B con un modelo base de Mistral-7B con una ventana de contexto de 8k tokens, que teóricamente tiene un rango de atención de hasta 128K tokens.
¿Y si el Zephyr fuera un modelo 70B? ¿Superará a GPT-4? Parece probable.
Si estás interesado en Zephyr-7B, puedes probarlo en huggingface.
Enlaces de papel:
Enlaces de referencia:
[1]
[2]
[3]
[4]
[5]
Ver originales
Esta página puede contener contenido de terceros, que se proporciona únicamente con fines informativos (sin garantías ni declaraciones) y no debe considerarse como un respaldo por parte de Gate a las opiniones expresadas ni como asesoramiento financiero o profesional. Consulte el Descargo de responsabilidad para obtener más detalles.
¡El mejor modelo 7B vuelve a cambiar de manos! Derrota a 70 mil millones de LLaMA2 y las computadoras de Apple podrán ejecutarse | código abierto y libre
Fuente original: qubits
¡El modelo de 7 mil millones de parámetros que tardó 500 dólares en "sintonizarse" derrotó al Llama 2 de 70 mil millones de parámetros!
Y el cuaderno puede ejecutarse fácilmente, y el efecto es comparable al de ChatGPT.
Importante: Gratis, sin dinero.
El modelo de código abierto Zephyr-7B creado por el equipo de HuggingFace H4, loco por los tiburones.
La clave de la capacidad de Zephyr para destacar entre las variantes fue que el equipo afinó el modelo en un conjunto de datos público utilizando la optimización de preferencias directas (DPO) sobre Mistral.
El equipo también descubrió que la eliminación de la alineación incorporada del conjunto de datos podría mejorar aún más el rendimiento de MT Bench. El Zephyr-7B-alpha original tenía una puntuación media de 7,09 en MT-Bench, superando al Llama2-70B-Chat.
**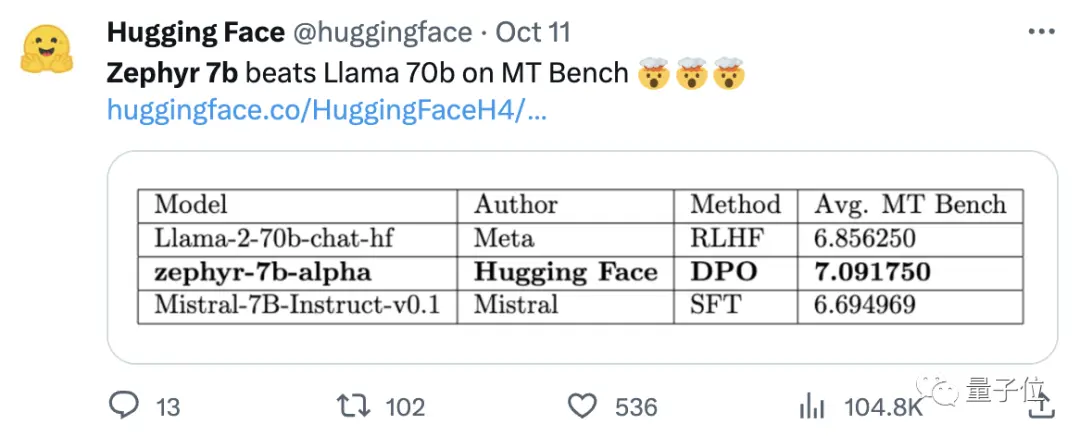 **###### △MT-Bench es una prueba de referencia para evaluar la capacidad del modelo para manejar múltiples rondas de diálogo, y el conjunto de preguntas cubre 8 categorías, como escritura, juego de roles y extracción.
**###### △MT-Bench es una prueba de referencia para evaluar la capacidad del modelo para manejar múltiples rondas de diálogo, y el conjunto de preguntas cubre 8 categorías, como escritura, juego de roles y extracción.
¡El punto es que luego pasó a actualizarse!
El equipo de H4 lanzó la segunda generación de Zephyr-7B-beta. Agregaron que exploraron la idea de extraer la alineación de GPT-4, Claude 2 y luego inyectarla en modelos pequeños, desarrollando un método para usar la optimización de preferencia directa por destilación (dDPO) para modelos pequeños.
En la segunda generación de Zephyr, la puntuación media de MT-Bench aumentó a 7,34.
La palabra Mistral significa viento seco, frío y fuerte en francés, mientras que Zephyr significa viento suave y agradable del oeste.
No hay duda de que hay un zoológico al otro lado de Llama, y no hay duda de que hay una oficina meteorológica en este lado.
El mejor modelo 7B vuelve a cambiar de manos
Comencemos con los requisitos de la computadora para ejecutar Zephyr. ¡Los internautas dijeron que "los pantalones tailandeses son picantes" después de la prueba! , el portátil (Apple M1 Pro) es suficiente, "el resultado es muy bueno".
Los datos también muestran que el efecto de la tarea avanzada RAG de Zephyr puede competir con GPT-3.5 y Claude 2.
Agregaron que Zephyr no solo funciona bien en RAG, sino también en el enrutamiento, la planificación de consultas, la recuperación de instrucciones SQL complejas y la extracción de datos estructurados.
Abandonar el aprendizaje por refuerzo
Si bien todos están probando los efectos de Zephyr, los desarrolladores dicen que lo más interesante no son las métricas, sino la forma en que se entrena el modelo.
A continuación se resumen los aspectos más destacados:
A grandes rasgos, como se mencionó al principio, la razón principal por la que Zephyr es capaz de superar al 70B Llama 2 se debe al uso de un método especial de ajuste fino.
A diferencia del enfoque tradicional de aprendizaje por refuerzo PPO, el equipo de investigación utilizó una colaboración reciente entre la Universidad de Stanford y CZ Biohub para proponer un enfoque DPO.
En términos simples, DPO se puede explicar de la siguiente manera:
Con el fin de hacer que el resultado del modelo esté más en línea con las preferencias humanas, el enfoque tradicional ha sido ajustar el modelo objetivo con un modelo de recompensa. Si el resultado es bueno, será recompensado, y si el resultado es malo, no será recompensado.
El enfoque DPO, por otro lado, omite la función de recompensa de modelado y es equivalente a optimizar el modelo directamente en los datos de preferencias.
En general, DPO resuelve el problema de la difícil y costosa formación de aprendizaje por refuerzo debido a la retroalimentación humana.
En términos específicos del entrenamiento de Zephyr, el equipo de investigación afinó inicialmente Zephyr-7B-alpha en una variante optimizada del conjunto de datos UltraChat, que contiene 1,6 millones de conversaciones generadas por ChatGPT (unas 200.000 restantes).
(La razón de la racionalización fue que el equipo descubrió que Zephyr a veces se entubaba incorrectamente, como "Hola. ¿Cómo estás?"; A veces, la respuesta comienza con "No tengo una X personal". )
Más tarde, alinearon aún más el modelo con el conjunto de datos openbmb/UltraFeedback disponible públicamente utilizando el método DPO Trainer de TRL.
El conjunto de datos contiene 64.000 pares de respuesta rápida de varios modelos. Cada respuesta se clasifica mediante GPT-4 en función de criterios como la utilidad y se le asigna una puntuación de la que se deriva una preferencia de IA.
Un hallazgo interesante es que cuando se utiliza el método DPO, el efecto es en realidad mejor después del sobreajuste a medida que aumenta el tiempo de entrenamiento. Los investigadores creen que esto es similar al sobreajuste en SFT.
Pensaron en el ajuste fino supervisado por destilación (dSFT) utilizado en modelos grandes, pero con este enfoque el modelo estaba desalineado y no producía resultados que coincidieran con la intención del usuario.
Los investigadores también probaron el efecto cuando no se utilizó SFT, y los resultados dieron como resultado una reducción significativa en el rendimiento, lo que indica que el paso dSFT es crítico.
Experiencia de demostración
En primer lugar, tuve que salir de la pregunta de "discapacitado mental" para hacer un examen.
Sobre la pregunta "Mamá y papá no me lleven cuando se casen", la respuesta general de Zephyr es más precisa.
Pero algunos internautas lo han probado antes, y también lo sabe en marzo de este año.
Además, Zephyr es muy receptivo, por lo que puedes escribir código e inventar historias. :
Los investigadores también mencionaron alucinaciones, y se marcó una pequeña línea de texto debajo del cuadro de entrada que indica que el contenido generado por el modelo puede ser inexacto o incorrecto.
Elija siempre uno de los peces emmm y las patas de oso.
Zephyr fue capaz de hacer esto con solo 70B parámetros, lo que sorprendió a Andriy Burkov, autor de "El libro de aprendizaje automático de 100 páginas", e incluso dijo:
Enlaces de papel:
Enlaces de referencia:
[1]
[2]
[3]
[4]
[5]