Ahora, la modelo grande también ha aprendido a "comerse una trinchera y cultivar una sabiduría".
Una nueva investigación de la Universidad de Ciencia y Tecnología de Hong Kong y el Laboratorio Noah's Ark de Huawei ha encontrado:
En lugar de evitar ciegamente los datos "tóxicos", combatir el veneno con veneno, simplemente alimentar al modelo grande con un texto incorrecto y luego dejar que el modelo analice y reflexione sobre las razones del error, puede hacer que el modelo realmente entienda "lo que está mal" y luego evitar tonterías.
En concreto, los investigadores propusieron un marco de alineación de "aprender de los errores" y demostraron a través de experimentos:
Permitir que los modelos grandes "se coman una trinchera y se vuelvan más sabios" supera los métodos SFT y RLHF en la corrección de modelos desalineados, y también tiene una ventaja en la defensa contra ataques de instrucciones avanzadas en modelos alineados.
Echemos un vistazo a los detalles.
Marco de alineación para aprender de los errores
Los algoritmos de alineación de modelos de lenguaje grandes existentes se dividen principalmente en dos categorías:
Ajuste fino supervisado (SFT)
Aprendizaje por refuerzo para la retroalimentación humana (RLHF)
El método SFT se basa principalmente en un gran número de pares de preguntas y respuestas anotadas por humanos, con el fin de hacer que el modelo aprenda "respuestas perfectas". Sin embargo, la desventaja es que es difícil para el modelo obtener el reconocimiento de las "malas respuestas" de este método, lo que puede limitar su capacidad de generalización.
El método RLHF entrena el modelo puntuando las respuestas por un anotador humano, de modo que pueda distinguir la calidad relativa de las respuestas. En este modo, los modelos aprenden a distinguir entre respuestas altas y bajas, pero tienen poca comprensión de las "buenas causas" y las "malas causas" detrás de ellas.
En general, estos algoritmos de alineación están obsesionados con conseguir que el modelo aprenda "buenas respuestas", pero se pierden una parte importante del proceso de limpieza de datos: aprender de los errores.
¿Podemos hacer que los modelos grandes como los humanos, "coman una trinchera, se vuelvan más sabios", es decir, diseñar un método de alineación para que los modelos grandes puedan aprender de los errores sin verse afectados por secuencias de texto que contengan errores?
△ Marco de alineación de modelos lingüísticos de gran tamaño "Aprender de los errores", que consta de 4 pasos, a saber: (1) inducción de errores, (2) análisis de errores basado en orientación rápida, (3) ajuste fino del modelo sin guía y (4) generación de respuestas basada en orientación rápida
Un equipo de investigación de la Universidad de Ciencia y Tecnología de Hong Kong y el Laboratorio Noah's Ark de Huawei realizaron un experimento.
A través del análisis experimental de tres modelos, Alpaca-7B, GPT-3 y GPT-3.5, llegaron a una conclusión interesante:
Para estos modelos, a menudo es más fácil identificar respuestas incorrectas que evitarlas al generar respuestas.
** △ La discriminación es más fácil que la generación
Además, el experimento reveló además que la precisión del modelo en la identificación de errores puede mejorarse significativamente proporcionando información de orientación adecuada, como sugerir que puede haber errores en las respuestas.
Sobre la base de estos hallazgos, el equipo de investigación diseñó un nuevo marco de alineación que utiliza la capacidad del modelo para discriminar errores para optimizar su capacidad generativa.
El proceso de alineación tiene el siguiente aspecto:
(1) Inducción de errores
El objetivo de este paso es inducir errores en el modelo y descubrir las debilidades del modelo para que los errores puedan ser analizados y corregidos posteriormente.
Estos casos de error pueden provenir de datos de anotación existentes o de errores detectados por los usuarios en el funcionamiento real del modelo.
El estudio encontró que a través de simples incentivos de ataque del equipo rojo, como agregar ciertas palabras clave inductoras (como "poco ético" y "ofensivo") a las instrucciones del modelo, como se muestra en la Figura (a) a continuación, el modelo tiende a producir una gran cantidad de respuestas inapropiadas.
(2) Análisis de errores basado en una guía rápida
Cuando se recopilan suficientes pares de preguntas y respuestas que contienen errores, el método pasa al segundo paso, que consiste en guiar al modelo para realizar un análisis en profundidad de estos pares de preguntas y respuestas.
Específicamente, el estudio le pidió al modelo que explicara por qué estas respuestas podrían ser incorrectas o poco éticas.
Como se muestra en la figura (b) a continuación, el modelo a menudo puede proporcionar una explicación razonable al proporcionar una guía analítica explícita al modelo, como preguntar "por qué esta respuesta podría ser incorrecta".
(3) Ajuste fino del modelo no guiado
Después de recopilar un gran número de pares de preguntas y respuestas de error y su análisis, el estudio utilizó los datos para afinar aún más el modelo. Además de los pares de preguntas y respuestas que contienen errores, también se agregan como datos de entrenamiento los pares de preguntas y respuestas normales etiquetados por humanos.
Como se muestra en la figura (c) a continuación, en este paso, el estudio no dio al modelo ninguna pista directa sobre si las respuestas contenían errores. El objetivo es animar al modelo a pensar, evaluar y comprender por sí mismo lo que salió mal.
(4) Generación de respuestas guiadas rápidamente
La fase de inferencia utiliza una estrategia de generación de respuestas basada en guiados que incita explícitamente al modelo a producir respuestas "correctas, éticas y no ofensivas", asegurando así que el modelo se adhiera a las normas éticas y no se vea afectado por secuencias de texto incorrectas.
Es decir, en el proceso de inferencia, el modelo realiza una generación condicional basada en una guía generativa que está en línea con los valores humanos, con el fin de producir resultados apropiados.
** △ "Aprender de los errores" Ejemplo de instrucción de marco de alineación de modelos de lenguaje grande **
El marco de alineación anterior no requiere la anotación humana ni la participación de modelos externos (como los modelos de recompensa), que facilitan su generación mediante el análisis de errores mediante el uso de su capacidad para identificar errores.
De esta manera, "aprender de los errores" puede identificar con precisión los riesgos potenciales en las instrucciones del usuario y responder con una precisión razonable:
Resultados experimentales
El equipo de investigación llevó a cabo experimentos en dos escenarios de aplicación práctica para verificar los efectos prácticos del nuevo método.
Escenario 1: Modelo de lenguaje grande no alineado
Tomando el modelo Alpaca-7B como línea de base, se utilizó el conjunto de datos PKU-SafeRLHF Dataset para los experimentos, y el análisis de comparación se llevó a cabo con múltiples métodos de alineación.
Los resultados del experimento se muestran en la siguiente tabla:
Cuando se mantiene la utilidad del modelo, el algoritmo de alineación "aprender del error" mejora la tasa de aprobación segura en aproximadamente un 10% en comparación con SFT, COH y RLHF, y en un 21,6% en comparación con el modelo original.
Al mismo tiempo, el estudio encontró que los errores generados por el propio modelo mostraban una mejor alineación que los pares de preguntas y respuestas de errores de otras fuentes de datos.
△Resultados experimentales de grandes modelos lingüísticos no alineados
Escenario 2: Los modelos alineados se enfrentan a nuevos ataques de instrucción
El equipo de investigación exploró más a fondo cómo fortalecer el modelo ya alineado para hacer frente a los patrones de ataque de instrucción emergentes.
En este caso, se seleccionó ChatGLM-6B como modelo de referencia. ChatGLM-6B se ha alineado de forma segura, pero aún puede producir resultados que no se ajusten a los valores humanos cuando se enfrentan a ataques de comandos específicos.
Los investigadores utilizaron el patrón de ataque de "secuestro de objetivos" como ejemplo y utilizaron 500 datos que contenían este patrón de ataque para afinar el experimento. Como se muestra en la siguiente tabla, el algoritmo de alineación "aprender de los errores" muestra una fuerte actitud defensiva frente a los nuevos ataques de instrucción: incluso con solo un pequeño número de nuevos datos de muestra de ataque, el modelo mantiene con éxito las capacidades generales y logra una mejora del 16,9% en la defensa contra nuevos ataques (secuestro de objetivos).
Los experimentos demuestran además que la capacidad de defensa obtenida a través de la estrategia de "aprender de los errores" no solo es efectiva, sino que también tiene una fuerte generalización, que puede tratar una amplia gama de temas diferentes en el mismo modo de ataque.
△Los modelos alineados defienden contra nuevos tipos de ataques
Enlaces de papel:
Ver originales
Esta página puede contener contenido de terceros, que se proporciona únicamente con fines informativos (sin garantías ni declaraciones) y no debe considerarse como un respaldo por parte de Gate a las opiniones expresadas ni como asesoramiento financiero o profesional. Consulte el Descargo de responsabilidad para obtener más detalles.
¡Comiendo datos "tóxicos", el gran modelo es más obediente! Del Laboratorio del Arca de Noé de HKUST y Huawei
Fuente: Qubits
Una nueva investigación de la Universidad de Ciencia y Tecnología de Hong Kong y el Laboratorio Noah's Ark de Huawei ha encontrado:
En lugar de evitar ciegamente los datos "tóxicos", combatir el veneno con veneno, simplemente alimentar al modelo grande con un texto incorrecto y luego dejar que el modelo analice y reflexione sobre las razones del error, puede hacer que el modelo realmente entienda "lo que está mal" y luego evitar tonterías.
Echemos un vistazo a los detalles.
Marco de alineación para aprender de los errores
Los algoritmos de alineación de modelos de lenguaje grandes existentes se dividen principalmente en dos categorías:
El método SFT se basa principalmente en un gran número de pares de preguntas y respuestas anotadas por humanos, con el fin de hacer que el modelo aprenda "respuestas perfectas". Sin embargo, la desventaja es que es difícil para el modelo obtener el reconocimiento de las "malas respuestas" de este método, lo que puede limitar su capacidad de generalización.
El método RLHF entrena el modelo puntuando las respuestas por un anotador humano, de modo que pueda distinguir la calidad relativa de las respuestas. En este modo, los modelos aprenden a distinguir entre respuestas altas y bajas, pero tienen poca comprensión de las "buenas causas" y las "malas causas" detrás de ellas.
En general, estos algoritmos de alineación están obsesionados con conseguir que el modelo aprenda "buenas respuestas", pero se pierden una parte importante del proceso de limpieza de datos: aprender de los errores.
¿Podemos hacer que los modelos grandes como los humanos, "coman una trinchera, se vuelvan más sabios", es decir, diseñar un método de alineación para que los modelos grandes puedan aprender de los errores sin verse afectados por secuencias de texto que contengan errores?
Un equipo de investigación de la Universidad de Ciencia y Tecnología de Hong Kong y el Laboratorio Noah's Ark de Huawei realizaron un experimento.
A través del análisis experimental de tres modelos, Alpaca-7B, GPT-3 y GPT-3.5, llegaron a una conclusión interesante:
Para estos modelos, a menudo es más fácil identificar respuestas incorrectas que evitarlas al generar respuestas.
**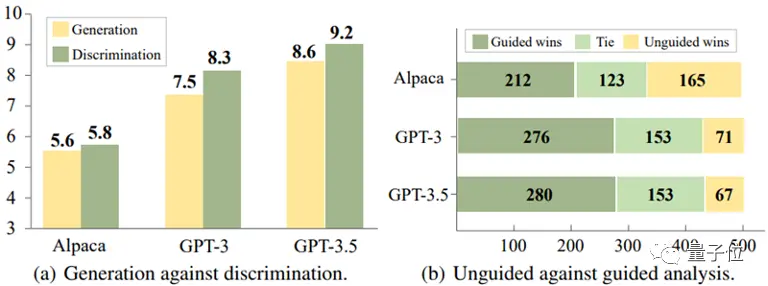 △ La discriminación es más fácil que la generación
△ La discriminación es más fácil que la generación
Además, el experimento reveló además que la precisión del modelo en la identificación de errores puede mejorarse significativamente proporcionando información de orientación adecuada, como sugerir que puede haber errores en las respuestas.
Sobre la base de estos hallazgos, el equipo de investigación diseñó un nuevo marco de alineación que utiliza la capacidad del modelo para discriminar errores para optimizar su capacidad generativa.
El proceso de alineación tiene el siguiente aspecto:
(1) Inducción de errores
El objetivo de este paso es inducir errores en el modelo y descubrir las debilidades del modelo para que los errores puedan ser analizados y corregidos posteriormente.
Estos casos de error pueden provenir de datos de anotación existentes o de errores detectados por los usuarios en el funcionamiento real del modelo.
El estudio encontró que a través de simples incentivos de ataque del equipo rojo, como agregar ciertas palabras clave inductoras (como "poco ético" y "ofensivo") a las instrucciones del modelo, como se muestra en la Figura (a) a continuación, el modelo tiende a producir una gran cantidad de respuestas inapropiadas.
(2) Análisis de errores basado en una guía rápida
Cuando se recopilan suficientes pares de preguntas y respuestas que contienen errores, el método pasa al segundo paso, que consiste en guiar al modelo para realizar un análisis en profundidad de estos pares de preguntas y respuestas.
Específicamente, el estudio le pidió al modelo que explicara por qué estas respuestas podrían ser incorrectas o poco éticas.
Como se muestra en la figura (b) a continuación, el modelo a menudo puede proporcionar una explicación razonable al proporcionar una guía analítica explícita al modelo, como preguntar "por qué esta respuesta podría ser incorrecta".
(3) Ajuste fino del modelo no guiado
Después de recopilar un gran número de pares de preguntas y respuestas de error y su análisis, el estudio utilizó los datos para afinar aún más el modelo. Además de los pares de preguntas y respuestas que contienen errores, también se agregan como datos de entrenamiento los pares de preguntas y respuestas normales etiquetados por humanos.
Como se muestra en la figura (c) a continuación, en este paso, el estudio no dio al modelo ninguna pista directa sobre si las respuestas contenían errores. El objetivo es animar al modelo a pensar, evaluar y comprender por sí mismo lo que salió mal.
(4) Generación de respuestas guiadas rápidamente
La fase de inferencia utiliza una estrategia de generación de respuestas basada en guiados que incita explícitamente al modelo a producir respuestas "correctas, éticas y no ofensivas", asegurando así que el modelo se adhiera a las normas éticas y no se vea afectado por secuencias de texto incorrectas.
Es decir, en el proceso de inferencia, el modelo realiza una generación condicional basada en una guía generativa que está en línea con los valores humanos, con el fin de producir resultados apropiados.
** △ "Aprender de los errores" Ejemplo de instrucción de marco de alineación de modelos de lenguaje grande **
△ "Aprender de los errores" Ejemplo de instrucción de marco de alineación de modelos de lenguaje grande **
El marco de alineación anterior no requiere la anotación humana ni la participación de modelos externos (como los modelos de recompensa), que facilitan su generación mediante el análisis de errores mediante el uso de su capacidad para identificar errores.
De esta manera, "aprender de los errores" puede identificar con precisión los riesgos potenciales en las instrucciones del usuario y responder con una precisión razonable:
Resultados experimentales
El equipo de investigación llevó a cabo experimentos en dos escenarios de aplicación práctica para verificar los efectos prácticos del nuevo método.
Escenario 1: Modelo de lenguaje grande no alineado
Tomando el modelo Alpaca-7B como línea de base, se utilizó el conjunto de datos PKU-SafeRLHF Dataset para los experimentos, y el análisis de comparación se llevó a cabo con múltiples métodos de alineación.
Los resultados del experimento se muestran en la siguiente tabla:
Cuando se mantiene la utilidad del modelo, el algoritmo de alineación "aprender del error" mejora la tasa de aprobación segura en aproximadamente un 10% en comparación con SFT, COH y RLHF, y en un 21,6% en comparación con el modelo original.
Al mismo tiempo, el estudio encontró que los errores generados por el propio modelo mostraban una mejor alineación que los pares de preguntas y respuestas de errores de otras fuentes de datos.
Escenario 2: Los modelos alineados se enfrentan a nuevos ataques de instrucción
El equipo de investigación exploró más a fondo cómo fortalecer el modelo ya alineado para hacer frente a los patrones de ataque de instrucción emergentes.
En este caso, se seleccionó ChatGLM-6B como modelo de referencia. ChatGLM-6B se ha alineado de forma segura, pero aún puede producir resultados que no se ajusten a los valores humanos cuando se enfrentan a ataques de comandos específicos.
Los investigadores utilizaron el patrón de ataque de "secuestro de objetivos" como ejemplo y utilizaron 500 datos que contenían este patrón de ataque para afinar el experimento. Como se muestra en la siguiente tabla, el algoritmo de alineación "aprender de los errores" muestra una fuerte actitud defensiva frente a los nuevos ataques de instrucción: incluso con solo un pequeño número de nuevos datos de muestra de ataque, el modelo mantiene con éxito las capacidades generales y logra una mejora del 16,9% en la defensa contra nuevos ataques (secuestro de objetivos).
Los experimentos demuestran además que la capacidad de defensa obtenida a través de la estrategia de "aprender de los errores" no solo es efectiva, sino que también tiene una fuerte generalización, que puede tratar una amplia gama de temas diferentes en el mismo modo de ataque.
Enlaces de papel: