Yao Qizhi a pris les devants en proposant un cadre de « réflexion » à grande échelle ! La précision du raisonnement logique est de 98 % et la façon de penser ressemble davantage à celle des humains.
Le premier article Large Language Model dirigé par Yao Qizhi, lauréat du prix Turing, est là !
Dès que j'ai commencé, mon objectif était de "faire en sorte que les grands modèles pensent comme les gens"——
Non seulement les grands modèles doivent raisonner étape par étape, mais ils doivent également apprendre à « étape par étape » et se souvenir de tous les processus corrects du processus de raisonnement.
Plus précisément, ce nouvel article propose une nouvelle méthode appelée raisonnement cumulatif, qui améliore considérablement la capacité des grands modèles à s'engager dans un raisonnement complexe.
Il faut savoir que les grands modèles sont basés sur des chaînes de réflexion, etc., et peuvent être utilisés pour raisonner sur des problèmes, mais face à des problèmes qui nécessitent « plusieurs tours », il est encore facile de commettre des erreurs.
C’est sur cette base que le raisonnement cumulatif ajoute un « vérificateur » pour juger du bien du mal en temps réel. Le cadre de réflexion de ce modèle est également passé d'une chaîne et d'un arbre à un « graphe acyclique orienté » plus complexe.
De cette façon, le grand modèle a non seulement des idées plus claires pour résoudre les problèmes, mais développe également une compétence de « cartes à jouer » :
Sur des problèmes mathématiques tels que l'algèbre et la théorie géométrique des nombres, la précision relative des grands modèles a augmenté de 42 % ; en jouant à 24 points, le taux de réussite a grimpé à 98 %.
Selon l'Institut d'information croisée de l'Université Tsinghua, le co-premier auteur Zhang Yifan a expliqué le point de départ de cet article :
Kahneman estime que le traitement cognitif humain comprend deux systèmes : le « Système 1 » est rapide, instinctif et émotionnel, et le « Système 2 » est lent, réfléchi et logique.
À l'heure actuelle, les performances des grands modèles de langage sont plus proches du « Système 1 », ce qui peut expliquer pourquoi ils ne sont pas efficaces pour gérer des tâches complexes.
Le raisonnement cumulatif conçu dans cette perspective est meilleur que Chain of Thought (CoT) et Thinking Tree (ToT).
Alors, à quoi ressemble concrètement cette nouvelle approche ? Jetons un coup d'oeil ensemble.
Percée de la chaîne de réflexion et des "goulots d'étranglement" des arbres
Le cœur du raisonnement cumulatif réside dans l’amélioration de la « forme » du processus de réflexion des grands modèles.
Plus précisément, cette méthode utilise 3 grands modèles de langage :
Proposant : proposer constamment de nouvelles propositions, c'est-à-dire suggérer quelle est la prochaine étape en fonction du contexte de réflexion actuel.
Vérificateur : vérifie l'exactitude de la proposition du proposant et l'ajoute au contexte de réflexion si elle est correcte.
Reporter : Détermine si la solution finale a été obtenue et s'il faut mettre fin au processus de raisonnement.
Au cours du processus de raisonnement, le « proposant » fait d'abord une proposition, le « vérificateur » est responsable de l'évaluation et le « rapporteur » décide s'il doit finaliser la réponse et mettre fin au processus de réflexion.
** ****△**Exemple de raisonnement CR
C'est un peu comme les trois types de rôles dans un projet d'équipe : les membres de l'équipe réfléchissent d'abord à diverses idées, l'instructeur « vérifie » quelle idée est réalisable et le chef d'équipe décide quand terminer le projet.
**Alors, comment cette approche change-t-elle exactement la « forme » de la pensée des grands modèles ? **
Pour comprendre cela, il faut commencer par la « Chain of Thought, CoT » (Chain of Thought, CoT), « l'initiateur » des méthodes d'amélioration de la pensée des grands modèles.
Cette méthode a été proposée par le scientifique d'OpenAI Jason Wei et d'autres en janvier 2022. L'essentiel est d'ajouter un texte de « raisonnement étape par étape » à l'entrée de l'ensemble de données pour stimuler la capacité de réflexion du grand modèle.
** ****△**Sélectionné dans l'ensemble de données GSM8K
Basé sur le principe de la chaîne de pensée, Google a également rapidement mis au point une "version Thinking Chain PLUS", à savoir CoT-SC, qui mène principalement plusieurs processus de chaîne de pensée et procède à un vote majoritaire sur les réponses pour sélectionner la meilleure. La meilleure réponse peut encore améliorer la précision du raisonnement.
Mais Thinking Chain et CoT-SC ignorent un problème : il existe plusieurs solutions à la question, surtout lorsque les humains résolvent le problème.
Par conséquent, une nouvelle recherche appelée Tree of Thought (ToT) est apparue par la suite.
Il s'agit d'un système de recherche arborescent qui permet au modèle d'essayer une variété d'idées de raisonnement différentes, de s'auto-évaluer, de choisir la prochaine ligne de conduite et de revenir en arrière si nécessaire.
La méthode montre que l'arbre de pensée va plus loin que la chaîne de pensée, ce qui rend la pensée sur les grands modèles « plus active ».
C'est pourquoi en jouant 24 points, le taux de réussite GPT-4 du bonus Chaîne de Pensée n'est que de 4%**, mais le taux de réussite de l'Arbre de Pensée s'élève à 74%.
MAIS, quelle que soit la chaîne de pensée, le CoT-SC ou l'arbre de pensée, il y a une limitation commune :
Aucun d'entre eux n'a mis en place un lieu de stockage pour les résultats intermédiaires du processus de réflexion.
Après tout, tous les processus de pensée ne peuvent pas être transformés en chaînes ou en arbres : la façon dont les humains perçoivent les choses est souvent plus complexe.
Ce nouveau cadre de raisonnement cumulatif franchit ce point de la conception——
Le processus de réflexion global d'un grand modèle n'est pas nécessairement une chaîne ou un arbre, il peut aussi s'agir d'un Graphique Acyclique Dirigé (DAG) ! (Eh bien, ça sent les synapses)
** ****△**Les arêtes du graphique ont des directions et il n'y a pas de chemins circulaires ; chaque arête dirigée est une étape de dérivation
Cela signifie qu'il peut stocker en mémoire tous les résultats d'inférence historiquement corrects pour les explorer dans la branche de recherche actuelle. (En revanche, un arbre pensant ne stocke pas les informations provenant d’autres branches)
Mais le raisonnement cumulatif peut également être commuté de manière transparente avec la chaîne de réflexion - tant que le « vérificateur » est supprimé, il s'agit d'un modèle de chaîne de réflexion standard.
Le raisonnement cumulatif conçu sur la base de cette méthode a obtenu de bons résultats dans diverses méthodes.
Bon en mathématiques et en raisonnement logique
Les chercheurs ont choisi le wiki FOLIO et AutoTNLI, le jeu en 24 points et les ensembles de données MATH pour « tester » le raisonnement cumulatif.
Le proposant, le vérificateur et le rapporteur utilisent le même grand modèle de langage dans chaque expérience, avec des paramètres différents pour leurs rôles.
Les modèles de base utilisés ici pour les expériences incluent GPT-3.5-turbo, GPT-4, LLaMA-13B et LLaMA-65B.
Il convient de mentionner qu'idéalement, le modèle devrait être spécifiquement pré-entraîné à l'aide des données de tâche de dérivation pertinentes, et le « vérificateur » devrait également ajouter un prouveur mathématique formel, un module de résolution logique propositionnelle, etc.
1. Capacité de raisonnement logique
FOLIO est un ensemble de données de raisonnement logique de premier ordre, et les étiquettes des questions peuvent être « vrai », « Faux » et « Inconnu » ; AutoTNLI est un ensemble de données de raisonnement logique de ordre supérieur.
Sur l'ensemble de données du wiki FOLIO, par rapport aux méthodes de résultats de sortie directe (Direct), de chaîne de pensée (CoT) et de chaîne de pensée avancée (CoT-SC), les performances du raisonnement cumulatif (CR) sont toujours les meilleures.
Après avoir supprimé les instances problématiques (telles que les réponses incorrectes) de l'ensemble de données, la précision de l'inférence GPT-4 à l'aide de la méthode CR a atteint 98,04 %, avec un taux d'erreur minimum de 1,96 %.
Regardons les performances sur l'ensemble de données AutoTNLI :
Par rapport à la méthode CoT, CR a considérablement amélioré les performances de LLaMA-13B et LLaMA-65B.
Sur le modèle LLaMA-65B, l'amélioration du CR par rapport au CoT atteint 9,3 %.
### 2. Possibilité de jouer à des jeux à 24 points
L'article ToT original utilisait un jeu en 24 points, les chercheurs ont donc utilisé cet ensemble de données pour comparer CR et ToT.
ToT utilise un arbre de recherche à largeur et profondeur fixes, et CR permet aux grands modèles de déterminer la profondeur de recherche de manière autonome.
Les chercheurs ont découvert lors d’expériences que dans le contexte de 24 points, l’algorithme CR et l’algorithme ToT sont très similaires. La différence est que l'algorithme de CR génère au plus un nouvel état par itération, tandis que ToT génère de nombreux états candidats à chaque itération, et filtre et conserve une partie de l'état.
En termes simples, ToT n'a pas le "vérificateur" mentionné ci-dessus comme CR et ne peut pas juger si les états (a, b, c) sont corrects ou incorrects. Par conséquent, ToT explorera plus d'états invalides que CR.
Au final, la précision de la méthode CR peut même atteindre 98 % (ToT est de 74 %), et le nombre moyen d'états consultés est bien inférieur à ToT.
En d’autres termes, CR a non seulement un taux de précision de recherche plus élevé, mais également une efficacité de recherche plus élevée.
### 3. Capacité mathématique
L'ensemble de données MATH contient un grand nombre de questions de raisonnement mathématique, notamment l'algèbre, la géométrie, la théorie des nombres, etc. La difficulté des questions est divisée en cinq niveaux.
En utilisant la méthode CR, le modèle peut décomposer la question en sous-questions qui peuvent être complétées étape par étape, et poser des questions et y répondre jusqu'à ce que la réponse soit générée.
Les résultats expérimentaux montrent que dans deux contextes expérimentaux différents, le taux de précision de la CR dépasse les méthodes existantes actuelles, avec un taux de précision global allant jusqu'à 58 % et une amélioration de la précision relative de 42 % dans le problème de niveau 5. Téléchargement du nouveau SOTA sous le modèle GPT-4.
Recherche dirigée par Yao Qizhi et Yuan Yang de l'Université Tsinghua
Cet article provient du groupe de recherche AI for Math dirigé par Yao Qizhi et Yuan Yang de l'Institut d'information interdisciplinaire Tsinghua.
Les co-premiers auteurs de l'article sont Zhang Yifan et Yang Jingqin, doctorants 2021 à l'Institut d'information interdisciplinaire ;
L'instructeur et l'auteur co-correspondant sont le professeur adjoint Yuan Yang et l'académicien Yao Qizhi.
Zhang Yifan
Zhang Yifan est diplômé du Collège Yuanpei de l'Université de Pékin en 2021. Il étudie actuellement sous la direction du professeur adjoint Yuan Yang. Ses principaux domaines de recherche sont la théorie et l'algorithme des modèles de base (grands modèles de langage), l'apprentissage auto-supervisé et l'intelligence artificielle fiable.
Yang Jingqin
Yang Jingqin a obtenu sa licence à l'Institut d'information croisée de l'Université Tsinghua en 2021 et étudie actuellement pour son doctorat auprès du professeur adjoint Yuan Yang. Les principales orientations de recherche incluent les grands modèles de langage, l’apprentissage auto-supervisé, les soins médicaux intelligents, etc.
Yuan Yang
Yuan Yang est professeur adjoint à l'École d'information interdisciplinaire de l'Université Tsinghua. Diplômé du Département d'informatique de l'Université de Pékin en 2012 ; titulaire d'un doctorat en informatique de l'Université Cornell aux États-Unis en 2018 ; de 2018 à 2019, il a travaillé comme chercheur postdoctoral à la School of Big Data Science du Massachusetts Institute de la Technologie.
Ses principaux domaines de recherche sont les soins médicaux intelligents, la théorie fondamentale de l'IA, la théorie appliquée des catégories, etc.
Yao Qizhi
Yao Qizhi est académicien de l'Académie chinoise des sciences et doyen de l'Institut d'information interdisciplinaire de l'Université Tsinghua. Il est également le premier universitaire asiatique à remporter le prix Turing depuis sa création, et le seul informaticien chinois à remporter cet honneur. jusqu'à présent.
Le professeur Yao Qizhi a démissionné de Princeton en tant que professeur titulaire en 2004 et est retourné à Tsinghua pour enseigner ; en 2005, il a fondé la « Classe Yao », une classe expérimentale d'informatique pour les étudiants de premier cycle de Tsinghua ; en 2011, il a fondé le « Centre d'information quantique de Tsinghua ». " et l'« Institut interdisciplinaire de recherche sur l'information » ; en 2019. En 2008, il a fondé un cours d'intelligence artificielle pour les étudiants de premier cycle de Tsinghua, appelé « Smart Class ».
Aujourd'hui, l'Institut d'information interdisciplinaire de l'Université Tsinghua qu'il dirige est célèbre depuis longtemps. Yao Class et Zhiban sont tous deux affiliés à l'Institut d'information interdisciplinaire.
Les intérêts de recherche du professeur Yao Qizhi incluent les algorithmes, la cryptographie, l’informatique quantique, etc. Il est un pionnier international et une autorité dans ce domaine. Récemment, il est apparu à la Conférence mondiale sur l'intelligence artificielle de 2023. L'Institut de recherche Qizhi de Shanghai qu'il dirige étudie actuellement « l'intelligence artificielle générale incarnée ».
Lien papier :
Voir l'original
Cette page peut inclure du contenu de tiers fourni à des fins d'information uniquement. Gate ne garantit ni l'exactitude ni la validité de ces contenus, n’endosse pas les opinions exprimées, et ne fournit aucun conseil financier ou professionnel à travers ces informations. Voir la section Avertissement pour plus de détails.
Yao Qizhi a pris les devants en proposant un cadre de « réflexion » à grande échelle ! La précision du raisonnement logique est de 98 % et la façon de penser ressemble davantage à celle des humains.
Source : Qubits
Le premier article Large Language Model dirigé par Yao Qizhi, lauréat du prix Turing, est là !
Dès que j'ai commencé, mon objectif était de "faire en sorte que les grands modèles pensent comme les gens"——
Non seulement les grands modèles doivent raisonner étape par étape, mais ils doivent également apprendre à « étape par étape » et se souvenir de tous les processus corrects du processus de raisonnement.
Plus précisément, ce nouvel article propose une nouvelle méthode appelée raisonnement cumulatif, qui améliore considérablement la capacité des grands modèles à s'engager dans un raisonnement complexe.
C’est sur cette base que le raisonnement cumulatif ajoute un « vérificateur » pour juger du bien du mal en temps réel. Le cadre de réflexion de ce modèle est également passé d'une chaîne et d'un arbre à un « graphe acyclique orienté » plus complexe.
De cette façon, le grand modèle a non seulement des idées plus claires pour résoudre les problèmes, mais développe également une compétence de « cartes à jouer » :
Sur des problèmes mathématiques tels que l'algèbre et la théorie géométrique des nombres, la précision relative des grands modèles a augmenté de 42 % ; en jouant à 24 points, le taux de réussite a grimpé à 98 %.
Le raisonnement cumulatif conçu dans cette perspective est meilleur que Chain of Thought (CoT) et Thinking Tree (ToT).
Alors, à quoi ressemble concrètement cette nouvelle approche ? Jetons un coup d'oeil ensemble.
Percée de la chaîne de réflexion et des "goulots d'étranglement" des arbres
Le cœur du raisonnement cumulatif réside dans l’amélioration de la « forme » du processus de réflexion des grands modèles.
Plus précisément, cette méthode utilise 3 grands modèles de langage :
Au cours du processus de raisonnement, le « proposant » fait d'abord une proposition, le « vérificateur » est responsable de l'évaluation et le « rapporteur » décide s'il doit finaliser la réponse et mettre fin au processus de réflexion.
**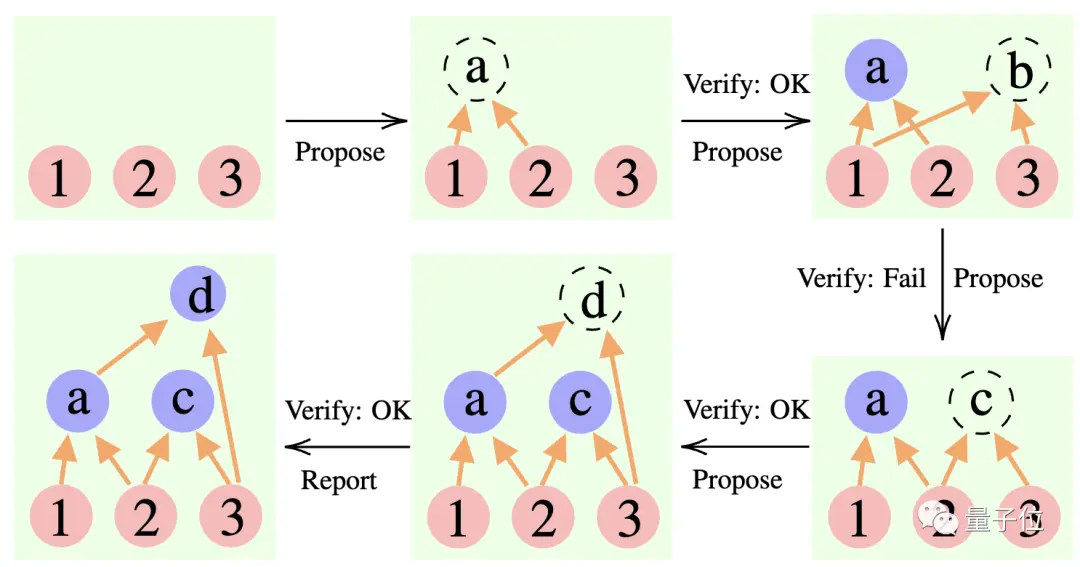 ****△**Exemple de raisonnement CR
****△**Exemple de raisonnement CR
C'est un peu comme les trois types de rôles dans un projet d'équipe : les membres de l'équipe réfléchissent d'abord à diverses idées, l'instructeur « vérifie » quelle idée est réalisable et le chef d'équipe décide quand terminer le projet.
Pour comprendre cela, il faut commencer par la « Chain of Thought, CoT » (Chain of Thought, CoT), « l'initiateur » des méthodes d'amélioration de la pensée des grands modèles.
Cette méthode a été proposée par le scientifique d'OpenAI Jason Wei et d'autres en janvier 2022. L'essentiel est d'ajouter un texte de « raisonnement étape par étape » à l'entrée de l'ensemble de données pour stimuler la capacité de réflexion du grand modèle.
**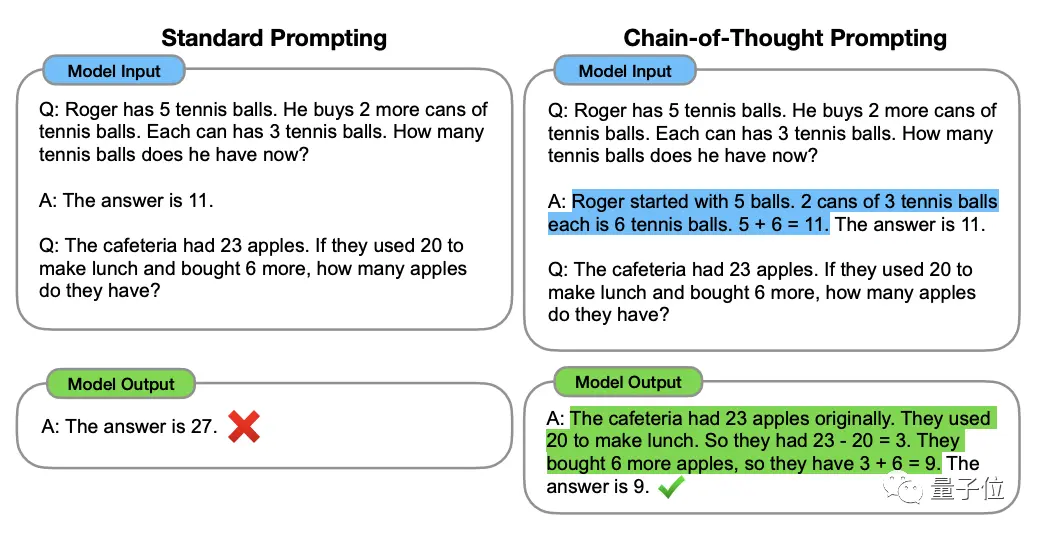 ****△**Sélectionné dans l'ensemble de données GSM8K
****△**Sélectionné dans l'ensemble de données GSM8K
Basé sur le principe de la chaîne de pensée, Google a également rapidement mis au point une "version Thinking Chain PLUS", à savoir CoT-SC, qui mène principalement plusieurs processus de chaîne de pensée et procède à un vote majoritaire sur les réponses pour sélectionner la meilleure. La meilleure réponse peut encore améliorer la précision du raisonnement.
Mais Thinking Chain et CoT-SC ignorent un problème : il existe plusieurs solutions à la question, surtout lorsque les humains résolvent le problème.
Par conséquent, une nouvelle recherche appelée Tree of Thought (ToT) est apparue par la suite.
Il s'agit d'un système de recherche arborescent qui permet au modèle d'essayer une variété d'idées de raisonnement différentes, de s'auto-évaluer, de choisir la prochaine ligne de conduite et de revenir en arrière si nécessaire.
C'est pourquoi en jouant 24 points, le taux de réussite GPT-4 du bonus Chaîne de Pensée n'est que de 4%**, mais le taux de réussite de l'Arbre de Pensée s'élève à 74%.
MAIS, quelle que soit la chaîne de pensée, le CoT-SC ou l'arbre de pensée, il y a une limitation commune :
Après tout, tous les processus de pensée ne peuvent pas être transformés en chaînes ou en arbres : la façon dont les humains perçoivent les choses est souvent plus complexe.
Ce nouveau cadre de raisonnement cumulatif franchit ce point de la conception——
Le processus de réflexion global d'un grand modèle n'est pas nécessairement une chaîne ou un arbre, il peut aussi s'agir d'un Graphique Acyclique Dirigé (DAG) ! (Eh bien, ça sent les synapses)
**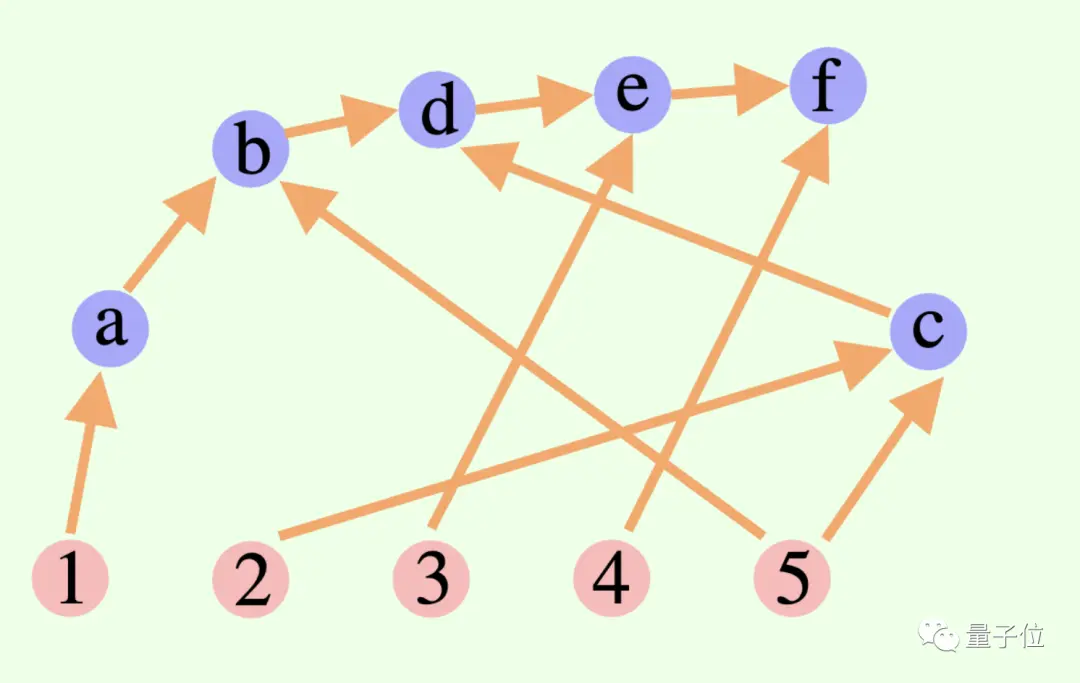 ****△**Les arêtes du graphique ont des directions et il n'y a pas de chemins circulaires ; chaque arête dirigée est une étape de dérivation
****△**Les arêtes du graphique ont des directions et il n'y a pas de chemins circulaires ; chaque arête dirigée est une étape de dérivation
Cela signifie qu'il peut stocker en mémoire tous les résultats d'inférence historiquement corrects pour les explorer dans la branche de recherche actuelle. (En revanche, un arbre pensant ne stocke pas les informations provenant d’autres branches)
Mais le raisonnement cumulatif peut également être commuté de manière transparente avec la chaîne de réflexion - tant que le « vérificateur » est supprimé, il s'agit d'un modèle de chaîne de réflexion standard.
Le raisonnement cumulatif conçu sur la base de cette méthode a obtenu de bons résultats dans diverses méthodes.
Bon en mathématiques et en raisonnement logique
Les chercheurs ont choisi le wiki FOLIO et AutoTNLI, le jeu en 24 points et les ensembles de données MATH pour « tester » le raisonnement cumulatif.
Le proposant, le vérificateur et le rapporteur utilisent le même grand modèle de langage dans chaque expérience, avec des paramètres différents pour leurs rôles.
Les modèles de base utilisés ici pour les expériences incluent GPT-3.5-turbo, GPT-4, LLaMA-13B et LLaMA-65B.
Il convient de mentionner qu'idéalement, le modèle devrait être spécifiquement pré-entraîné à l'aide des données de tâche de dérivation pertinentes, et le « vérificateur » devrait également ajouter un prouveur mathématique formel, un module de résolution logique propositionnelle, etc.
1. Capacité de raisonnement logique
FOLIO est un ensemble de données de raisonnement logique de premier ordre, et les étiquettes des questions peuvent être « vrai », « Faux » et « Inconnu » ; AutoTNLI est un ensemble de données de raisonnement logique de ordre supérieur.
Sur l'ensemble de données du wiki FOLIO, par rapport aux méthodes de résultats de sortie directe (Direct), de chaîne de pensée (CoT) et de chaîne de pensée avancée (CoT-SC), les performances du raisonnement cumulatif (CR) sont toujours les meilleures.
Après avoir supprimé les instances problématiques (telles que les réponses incorrectes) de l'ensemble de données, la précision de l'inférence GPT-4 à l'aide de la méthode CR a atteint 98,04 %, avec un taux d'erreur minimum de 1,96 %.
Par rapport à la méthode CoT, CR a considérablement amélioré les performances de LLaMA-13B et LLaMA-65B.
Sur le modèle LLaMA-65B, l'amélioration du CR par rapport au CoT atteint 9,3 %.
L'article ToT original utilisait un jeu en 24 points, les chercheurs ont donc utilisé cet ensemble de données pour comparer CR et ToT.
ToT utilise un arbre de recherche à largeur et profondeur fixes, et CR permet aux grands modèles de déterminer la profondeur de recherche de manière autonome.
Les chercheurs ont découvert lors d’expériences que dans le contexte de 24 points, l’algorithme CR et l’algorithme ToT sont très similaires. La différence est que l'algorithme de CR génère au plus un nouvel état par itération, tandis que ToT génère de nombreux états candidats à chaque itération, et filtre et conserve une partie de l'état.
En termes simples, ToT n'a pas le "vérificateur" mentionné ci-dessus comme CR et ne peut pas juger si les états (a, b, c) sont corrects ou incorrects. Par conséquent, ToT explorera plus d'états invalides que CR.
En d’autres termes, CR a non seulement un taux de précision de recherche plus élevé, mais également une efficacité de recherche plus élevée.
L'ensemble de données MATH contient un grand nombre de questions de raisonnement mathématique, notamment l'algèbre, la géométrie, la théorie des nombres, etc. La difficulté des questions est divisée en cinq niveaux.
En utilisant la méthode CR, le modèle peut décomposer la question en sous-questions qui peuvent être complétées étape par étape, et poser des questions et y répondre jusqu'à ce que la réponse soit générée.
Les résultats expérimentaux montrent que dans deux contextes expérimentaux différents, le taux de précision de la CR dépasse les méthodes existantes actuelles, avec un taux de précision global allant jusqu'à 58 % et une amélioration de la précision relative de 42 % dans le problème de niveau 5. Téléchargement du nouveau SOTA sous le modèle GPT-4.
Recherche dirigée par Yao Qizhi et Yuan Yang de l'Université Tsinghua
Cet article provient du groupe de recherche AI for Math dirigé par Yao Qizhi et Yuan Yang de l'Institut d'information interdisciplinaire Tsinghua.
Les co-premiers auteurs de l'article sont Zhang Yifan et Yang Jingqin, doctorants 2021 à l'Institut d'information interdisciplinaire ;
L'instructeur et l'auteur co-correspondant sont le professeur adjoint Yuan Yang et l'académicien Yao Qizhi.
Zhang Yifan
Zhang Yifan est diplômé du Collège Yuanpei de l'Université de Pékin en 2021. Il étudie actuellement sous la direction du professeur adjoint Yuan Yang. Ses principaux domaines de recherche sont la théorie et l'algorithme des modèles de base (grands modèles de langage), l'apprentissage auto-supervisé et l'intelligence artificielle fiable.
Yang Jingqin
Yang Jingqin a obtenu sa licence à l'Institut d'information croisée de l'Université Tsinghua en 2021 et étudie actuellement pour son doctorat auprès du professeur adjoint Yuan Yang. Les principales orientations de recherche incluent les grands modèles de langage, l’apprentissage auto-supervisé, les soins médicaux intelligents, etc.
Yuan Yang
Ses principaux domaines de recherche sont les soins médicaux intelligents, la théorie fondamentale de l'IA, la théorie appliquée des catégories, etc.
Yao Qizhi
Le professeur Yao Qizhi a démissionné de Princeton en tant que professeur titulaire en 2004 et est retourné à Tsinghua pour enseigner ; en 2005, il a fondé la « Classe Yao », une classe expérimentale d'informatique pour les étudiants de premier cycle de Tsinghua ; en 2011, il a fondé le « Centre d'information quantique de Tsinghua ». " et l'« Institut interdisciplinaire de recherche sur l'information » ; en 2019. En 2008, il a fondé un cours d'intelligence artificielle pour les étudiants de premier cycle de Tsinghua, appelé « Smart Class ».
Aujourd'hui, l'Institut d'information interdisciplinaire de l'Université Tsinghua qu'il dirige est célèbre depuis longtemps. Yao Class et Zhiban sont tous deux affiliés à l'Institut d'information interdisciplinaire.
Les intérêts de recherche du professeur Yao Qizhi incluent les algorithmes, la cryptographie, l’informatique quantique, etc. Il est un pionnier international et une autorité dans ce domaine. Récemment, il est apparu à la Conférence mondiale sur l'intelligence artificielle de 2023. L'Institut de recherche Qizhi de Shanghai qu'il dirige étudie actuellement « l'intelligence artificielle générale incarnée ».
Lien papier :