Le nouvel algorithme de Stanford de Microsoft élimine le risque d’extinction de l’IA ! GPT-4 est auto-itératif, et le processus est contrôlable et explicable
Microsoft Des chercheurs de Stanford ont publié un nouvel article proposant le système STOP, par le biais d’algorithmes d’optimisation itératifs, afin que GPT-4 puisse s’auto-améliorer le code de sortie de la tâche. Cette méthode d’auto-optimisation, qui ne modifie pas le poids et la structure du modèle, permet d’éviter le risque de « systèmes d’IA auto-évolutifs ».
Le problème de « l’auto-évolution récursive de l’IA domine les humains » a été résolu ?!
De nombreux gros bonnets de l’IA considèrent le développement de grands modèles capables d’itérer par eux-mêmes comme un « raccourci » permettant aux humains de commencer la voie de l’autodestruction.
Le cofondateur de DeepMind a déclaré que l’IA qui peut évoluer de manière autonome présente des risques potentiels très énormes
Parce que si le grand modèle peut améliorer son propre poids et son propre cadre indépendamment, et améliorer continuellement sa capacité d’auto-amélioration, non seulement l’interprétabilité du modèle ne peut pas être discutée, mais les humains seront également complètement incapables de prédire et de contrôler la sortie du modèle.
Si vous laissez le grand modèle « évoluer de manière autonome », le modèle peut continuer à produire du contenu préjudiciable, et si la capacité future évolue trop fortement, elle peut à son tour contrôler les humains !
Récemment, des chercheurs de Microsoft et de Stanford ont mis au point un nouveau système qui permet aux modèles de s’auto-itérer et d’améliorer la qualité de sortie sans modifier les poids et les frameworks.
Plus important encore, ce système peut grandement améliorer la transparence et l’interprétabilité du processus d'« auto-amélioration » du modèle, permettant aux chercheurs de comprendre et de contrôler le processus d’auto-amélioration du modèle, empêchant ainsi l’émergence d’une IA « incontrôlable par l’homme ».
Adresse papier :
L’auto-amélioration récursive (RSI) est l’une des idées les plus anciennes de l’intelligence artificielle. Un modèle de langage peut-il écrire du code qui s’améliore récursivement ?
Les chercheurs ont proposé un optimiseur autodidacte (STOP) capable d’auto-améliorer récursivement la génération de code.
Ils commencent avec un simple programme d’optimisation de la graine qui prend du code et des fonctions objectives, et utilise un modèle de langage pour améliorer le code (renvoyant la meilleure amélioration dans l’optimisation k).
Parce que « l’amélioration du code » est une tâche, les chercheurs peuvent se passer l'« optimiseur » à eux-mêmes ! Ensuite, répétez le processus encore et encore.
Tant que le processus est suffisamment répété, GPT-4 proposera de nombreuses stratégies d’auto-amélioration du code très créatives, telles que des algorithmes génétiques, un recuit simulé ou des machines à sous à plusieurs bras.
Étant donné que les données d’entraînement de GPT-4 ne sont que jusqu’en 2021, ce qui est plus tôt que la plupart des stratégies améliorées qu’il a trouvées, il est en effet surprenant d’obtenir de tels résultats !
De plus, parce que les chercheurs avaient besoin d’un moyen d’évaluer l’optimiseur amélioré, ils ont défini un objectif de « méta-utilité », qui est l’objectif attendu de l’optimiseur lorsqu’il est appliqué à des programmes et des tâches aléatoires en aval.
Lorsque l’optimiseur s’améliore, les chercheurs attribuent cette fonction objective à l’algorithme.
Les principaux résultats trouvés par les chercheurs : Premièrement, les performances attendues en aval des optimiseurs d’auto-amélioration ont augmenté de manière cohérente avec le nombre d’itérations d’auto-amélioration.
Deuxièmement, ces optimiseurs améliorés peuvent également être un bon moyen d’améliorer les solutions aux tâches qui n’ont pas été vues pendant la formation.
Bien que de nombreux chercheurs aient exprimé des inquiétudes quant aux modèles d'« auto-amélioration récursive », ils pensent que des systèmes d’IA que les humains ne peuvent pas contrôler pourraient se développer. Mais au lieu d’être optimisé pour le modèle lui-même, il est automatiquement optimisé pour la tâche cible, ce qui facilite l’interprétation du processus d’optimisation.
Et ce processus peut être utilisé comme banc d’essai pour détecter les stratégies nocives d'« auto-amélioration récursive ».
Les chercheurs ont également constaté que GPT-4 peut activement supprimer le « drapeau de désactivation du bac à sable » pendant l’itération « dans un souci d’efficacité ».
Les internautes estiment que la méthode proposée dans cet article a un grand potentiel. Parce que l’IAG du futur n’est peut-être pas un seul grand modèle, il est probable qu’il s’agisse d’un groupe d’innombrables agents efficaces capables de travailler ensemble pour réussir dans les tâches énormes qui leur sont assignées.
Tout comme une entreprise a une intelligence plus puissante que les employés individuels.
Peut-être qu’avec cette approche, même si l’AGI n’est pas possible, il peut être possible de faire en sorte qu’un modèle spécialement optimisé atteigne des performances beaucoup plus élevées que lui-même sur une gamme limitée de tâches.
Cadre de base de la thèse
Dans ce travail, les chercheurs proposent Self-Learned Optimizer (STOP), qui est une application de modèles de langage pour améliorer l’application récursive de code pour des solutions arbitraires.
L’approche des chercheurs a commencé par un programme initial d’échafaudage « optimiseur » qui utilise des modèles de langage pour améliorer les solutions aux tâches en aval.
Au fur et à mesure que le système itère, le modèle affine cette procédure d’optimisation. Les chercheurs ont utilisé un ensemble de tâches algorithmiques en aval pour quantifier les performances du cadre d’auto-optimisation.
Les résultats des chercheurs ont montré que l’effet s’améliorait considérablement lorsque le modèle appliquait sa stratégie d’auto-amélioration en augmentant le nombre d’itérations.
STOP montre comment un modèle de langage agit comme son propre Meta Optimizer. Les chercheurs ont également étudié les types de stratégies d’auto-amélioration proposées par le modèle (voir la figure 1 ci-dessous), la transférabilité des stratégies proposées dans les tâches en aval et ont exploré la sensibilité du modèle aux stratégies d’auto-amélioration dangereuses.
La figure ci-dessus montre de nombreux échafaudages fonctionnels et intéressants proposés par STOP lors de l’utilisation de GPT-4, car GPT-4 a été entraîné à l’aide de données jusqu’en 2021, bien plus tôt que la plupart des programmes constructifs n’ont été proposés.
Par conséquent, il montre que ce système peut générer des stratégies d’optimisation utiles pour s’optimiser à l’origine.
Les principaux apports de ce travail sont :
Une méthode « Meta-Optimizer » est proposée, qui génère des programmes constructifs pour améliorer récursivement sa propre sortie.
Il a été prouvé qu’un système utilisant des modèles de langage moderne (en particulier GPT-4) peut s’améliorer avec succès de manière récursive.
Étudier les techniques d’auto-amélioration proposées et mises en œuvre par le modèle, y compris les moyens et les possibilités pour le modèle d’éviter les mesures de sécurité telles que les bacs à sable.
STOP OPTIMISEUR AUTODIDACTE (STOP)系统
La figure 3 montre le pipeline d’optimisation auto-itératif du système
Ce qui suit montre le diagramme d’algorithme de Self-Learned Optimizer (STOP). L’un des problèmes les plus critiques est que la conception du système I lui-même est une division optimisée, qui peut être améliorée en appliquant des algorithmes récursifs.
Tout d’abord, l’algorithme STOP initialise d’abord la graine I0, puis définit la formule de sortie après l’amélioration de la énième itération :
1. Intuition
STOP peut sélectionner u en fonction des tâches en aval pour mieux sélectionner la version d’itération pendant le processus d’itération. Souvent, l’intuition est que les versions itératives de solutions qui sont compétentes pour les tâches en aval sont plus susceptibles de devenir de meilleurs constructeurs et donc de mieux s’améliorer.
Dans le même temps, les chercheurs pensent que le choix d’un schéma d’amélioration à théorie unique conduit à de meilleurs cycles d’amélioration multiples.
Dans la formule de maximisation, les auteurs discutent de la « méta-utilité », qui couvre à la fois l’auto-optimisation et l’optimisation en aval, mais est limitée par le coût de l’évaluation, et en pratique, les auteurs imposent des contraintes budgétaires aux modèles de langage (par exemple, limiter le nombre de fois qu’une fonction peut être appelée) et laisser les humains ou les modèles générer des solutions initiales.
Le coût du budget peut être exprimé par la formule suivante :
où budget représente chaque poste budgétaire, correspondant à chaque itération du nombre de fois où le système peut utiliser la fonction d’appel.
2. Configurer le système initial
** **Dans la figure 2 ci-dessus, lors de la sélection de la graine initiale, il vous suffit de fournir :
« Vous êtes un chercheur et programmeur expert en informatique, particulièrement doué pour optimiser les algorithmes. Améliorez la solution suivante. »
Le modèle système génère la solution initiale, puis saisit :
« Vous devez retourner une solution améliorée. Soyez aussi créatif que possible sous les contraintes. Votre amélioration principale doit être nouvelle et non triviale. D’abord, proposez une idée, puis mettez-la en œuvre. »
Renvoie la meilleure solution en fonction de la fonction appelante. Les auteurs ont choisi cette forme simple en raison de la commodité de fournir des améliorations asymétriques pour les tâches génériques en aval.
De plus, dans le processus d’itération, il y a quelques points auxquels il faut faire attention :
(1) encourager les modèles de langage à être aussi « créatifs » que possible ;
(2) minimiser la complexité de l’indice initial, car l’auto-itération introduit une complexité supplémentaire en raison des références de chaîne de code à l’intérieur de PROMP ;
(3) Minimisez le nombre, réduisant ainsi le coût d’appel du modèle de langage. Les chercheurs ont également envisagé d’autres variantes de cette invite de départ, mais l’heuristique a constaté que cette version maximisait les améliorations proposées par le modèle de langage GPT-4.
Les auteurs ont également découvert de manière inattendue que d’autres variantes utilisaient des capacités maximales du modèle de langage GPT-4.
3. Description de l’utilité
Pour transmettre efficacement les détails de l’utilitaire au modèle de langage, l’auteur fournit deux formes d’utilité, une fonction qui peut être appelée et une chaîne de description de l’utilitaire qui contient les éléments essentiels du code source de l’utilitaire.
La raison d’adopter cette approche est que, grâce à la description, les chercheurs peuvent communiquer clairement les contraintes budgétaires de l’utilitaire, telles que le temps d’exécution ou le nombre d’appels de fonction, au modèle de langage.
Au début, les chercheurs ont essayé de décrire les directives budgétaires dans l’invite du programme d’amélioration des semences, mais cela a conduit à la suppression de telles directives dans les itérations ultérieures et aux tentatives de « récompenser le vol ».
L’inconvénient de cette approche est qu’elle sépare les contraintes du code optimisé par le modèle de langage, ce qui réduit potentiellement la probabilité que le modèle de langage utilise ces contraintes.
Enfin, sur la base d’observations empiriques, les auteurs ont constaté que le remplacement du code source par des descriptions purement utilitaires en anglais réduit la fréquence des améliorations non substantielles.
Expériences et résultats
1. Performance sur les tâches fixes en aval
Les auteurs comparent les performances des modèles GPT-4 et GPT-3.5 sur une tâche fixe en aval, et le choix de la tâche est d’apprendre la parité bruitée (LPN) LPN comme un test facile et rapide et une tâche d’algorithme difficile dont la tâche est de parité dans les chaînes de bits qui sont marquées avec des bits inconnus sur elles ; étant donné un ensemble d’apprentissage de chaîne de bits avec des étiquettes bruitées, l’objectif est de prédire la véritable étiquette de la nouvelle chaîne de bits. Le LPN silencieux peut être facilement résolu par élimination gaussienne, mais le LPN bruyant est difficile à gérer sur le plan informatique.
Une dimension d’entrée traitable de 10 bits par exemple a été utilisée pour définir l’utilitaire en aval u, M = 20 instances de tâches LPN indépendantes ont été échantillonnées de manière aléatoire et une courte limite de temps a été fixée.
Après l’auto-amélioration des temps T, STOP conserve le « méta-utilitaire » sur l’instance de test dans les tâches en aval avec parité de bruit.
Il est intéressant de noter qu’avec la prise en charge d’un modèle de langage puissant comme GPT-4 (à gauche), les performances moyennes en aval de STOP s’améliorent de manière monotone. En revanche, pour le modèle de langage GPT-3.5 plus faible (à droite), les performances moyennes ont diminué.
2. Amélioration des capacités de migration du système
Les auteurs ont effectué une série d’expériences de transfert conçues pour tester si les améliorateurs générés lors de l’auto-amélioration étaient capables de bien performer dans différentes tâches en aval.
Les résultats expérimentaux montrent que ces améliorateurs sont capables de surpasser la version originale des améliorateurs sur de nouvelles tâches en aval sans autre optimisation. Cela peut indiquer que ces améliorateurs ont une certaine polyvalence et peuvent être appliqués à différentes tâches.
3. Les performances des systèmes d’auto-optimisation sur les modèles plus petits
Ensuite, le modèle de langage plus petit GPT-3.5-turbo est discuté pour améliorer sa capacité à construire des programmes.
Les auteurs ont mené 25 expériences indépendantes et ont constaté que GPT-3.5 proposait et mettait parfois en œuvre de meilleures procédures de construction, mais seulement 12 % des opérations GPT-3.5 obtenaient une amélioration d’au moins 3 %.
De plus, GPT-3.5 présente des cas de défaillance uniques qui ne sont pas observés dans GPT-4.
Tout d’abord, GPT03.5 est plus susceptible de proposer une stratégie d’amélioration qui ne nuit pas à la solution initiale pour les tâches en aval, mais qui nuit au code de l’amélioration (par exemple, en remplaçant au hasard les chaînes dans chaque ligne, avec une probabilité de substitution plus faible par ligne, ce qui a moins d’impact sur les solutions plus courtes).
Deuxièmement, si la plupart des améliorations proposées sont préjudiciables aux performances, vous pouvez choisir un programme de construction sous-optimal et revenir par inadvertance à la solution d’origine.
En général, les « idées » qui sous-tendent les propositions d’amélioration sont raisonnables et novatrices (par exemple, les algorithmes génétiques ou les recherches locales), mais leur mise en œuvre est souvent trop simpliste ou incorrecte. On a observé que les améliorateurs de semences qui utilisaient initialement GPT-3.5 avaient une méta-utilité plus élevée que GPT-4 (65 % contre 61 %).
Conclusion
Dans ce travail, les chercheurs proposent une base STOP pour montrer que les grands modèles de langage comme GPT-4 peuvent s’améliorer et améliorer les performances dans les tâches de code en aval.
Cela montre en outre que les modèles de langage auto-optimisés n’ont pas besoin d’optimiser leurs propres poids ou leur architecture sous-jacente, évitant ainsi les systèmes d’IA qui pourraient être produits à l’avenir et qui ne sont pas contrôlés par des humains.
Ressources:
Voir l'original
Cette page peut inclure du contenu de tiers fourni à des fins d'information uniquement. Gate ne garantit ni l'exactitude ni la validité de ces contenus, n’endosse pas les opinions exprimées, et ne fournit aucun conseil financier ou professionnel à travers ces informations. Voir la section Avertissement pour plus de détails.
Le nouvel algorithme de Stanford de Microsoft élimine le risque d’extinction de l’IA ! GPT-4 est auto-itératif, et le processus est contrôlable et explicable
Source de l’article : Shin Zhiyuan
Editeur: Run Bagel
Le problème de « l’auto-évolution récursive de l’IA domine les humains » a été résolu ?!
De nombreux gros bonnets de l’IA considèrent le développement de grands modèles capables d’itérer par eux-mêmes comme un « raccourci » permettant aux humains de commencer la voie de l’autodestruction.
Parce que si le grand modèle peut améliorer son propre poids et son propre cadre indépendamment, et améliorer continuellement sa capacité d’auto-amélioration, non seulement l’interprétabilité du modèle ne peut pas être discutée, mais les humains seront également complètement incapables de prédire et de contrôler la sortie du modèle.
Si vous laissez le grand modèle « évoluer de manière autonome », le modèle peut continuer à produire du contenu préjudiciable, et si la capacité future évolue trop fortement, elle peut à son tour contrôler les humains !
Plus important encore, ce système peut grandement améliorer la transparence et l’interprétabilité du processus d'« auto-amélioration » du modèle, permettant aux chercheurs de comprendre et de contrôler le processus d’auto-amélioration du modèle, empêchant ainsi l’émergence d’une IA « incontrôlable par l’homme ».
L’auto-amélioration récursive (RSI) est l’une des idées les plus anciennes de l’intelligence artificielle. Un modèle de langage peut-il écrire du code qui s’améliore récursivement ?
Les chercheurs ont proposé un optimiseur autodidacte (STOP) capable d’auto-améliorer récursivement la génération de code.
Parce que « l’amélioration du code » est une tâche, les chercheurs peuvent se passer l'« optimiseur » à eux-mêmes ! Ensuite, répétez le processus encore et encore.
Tant que le processus est suffisamment répété, GPT-4 proposera de nombreuses stratégies d’auto-amélioration du code très créatives, telles que des algorithmes génétiques, un recuit simulé ou des machines à sous à plusieurs bras.
De plus, parce que les chercheurs avaient besoin d’un moyen d’évaluer l’optimiseur amélioré, ils ont défini un objectif de « méta-utilité », qui est l’objectif attendu de l’optimiseur lorsqu’il est appliqué à des programmes et des tâches aléatoires en aval.
Lorsque l’optimiseur s’améliore, les chercheurs attribuent cette fonction objective à l’algorithme.
Deuxièmement, ces optimiseurs améliorés peuvent également être un bon moyen d’améliorer les solutions aux tâches qui n’ont pas été vues pendant la formation.
Et ce processus peut être utilisé comme banc d’essai pour détecter les stratégies nocives d'« auto-amélioration récursive ».
Les chercheurs ont également constaté que GPT-4 peut activement supprimer le « drapeau de désactivation du bac à sable » pendant l’itération « dans un souci d’efficacité ».
Tout comme une entreprise a une intelligence plus puissante que les employés individuels.
Cadre de base de la thèse
Dans ce travail, les chercheurs proposent Self-Learned Optimizer (STOP), qui est une application de modèles de langage pour améliorer l’application récursive de code pour des solutions arbitraires.
L’approche des chercheurs a commencé par un programme initial d’échafaudage « optimiseur » qui utilise des modèles de langage pour améliorer les solutions aux tâches en aval.
Au fur et à mesure que le système itère, le modèle affine cette procédure d’optimisation. Les chercheurs ont utilisé un ensemble de tâches algorithmiques en aval pour quantifier les performances du cadre d’auto-optimisation.
Les résultats des chercheurs ont montré que l’effet s’améliorait considérablement lorsque le modèle appliquait sa stratégie d’auto-amélioration en augmentant le nombre d’itérations.
STOP montre comment un modèle de langage agit comme son propre Meta Optimizer. Les chercheurs ont également étudié les types de stratégies d’auto-amélioration proposées par le modèle (voir la figure 1 ci-dessous), la transférabilité des stratégies proposées dans les tâches en aval et ont exploré la sensibilité du modèle aux stratégies d’auto-amélioration dangereuses.
Par conséquent, il montre que ce système peut générer des stratégies d’optimisation utiles pour s’optimiser à l’origine.
Les principaux apports de ce travail sont :
Une méthode « Meta-Optimizer » est proposée, qui génère des programmes constructifs pour améliorer récursivement sa propre sortie.
Il a été prouvé qu’un système utilisant des modèles de langage moderne (en particulier GPT-4) peut s’améliorer avec succès de manière récursive.
Étudier les techniques d’auto-amélioration proposées et mises en œuvre par le modèle, y compris les moyens et les possibilités pour le modèle d’éviter les mesures de sécurité telles que les bacs à sable.
STOP OPTIMISEUR AUTODIDACTE (STOP)系统
Ce qui suit montre le diagramme d’algorithme de Self-Learned Optimizer (STOP). L’un des problèmes les plus critiques est que la conception du système I lui-même est une division optimisée, qui peut être améliorée en appliquant des algorithmes récursifs.
STOP peut sélectionner u en fonction des tâches en aval pour mieux sélectionner la version d’itération pendant le processus d’itération. Souvent, l’intuition est que les versions itératives de solutions qui sont compétentes pour les tâches en aval sont plus susceptibles de devenir de meilleurs constructeurs et donc de mieux s’améliorer.
Dans le même temps, les chercheurs pensent que le choix d’un schéma d’amélioration à théorie unique conduit à de meilleurs cycles d’amélioration multiples.
Dans la formule de maximisation, les auteurs discutent de la « méta-utilité », qui couvre à la fois l’auto-optimisation et l’optimisation en aval, mais est limitée par le coût de l’évaluation, et en pratique, les auteurs imposent des contraintes budgétaires aux modèles de langage (par exemple, limiter le nombre de fois qu’une fonction peut être appelée) et laisser les humains ou les modèles générer des solutions initiales.
Le coût du budget peut être exprimé par la formule suivante :
2. Configurer le système initial
**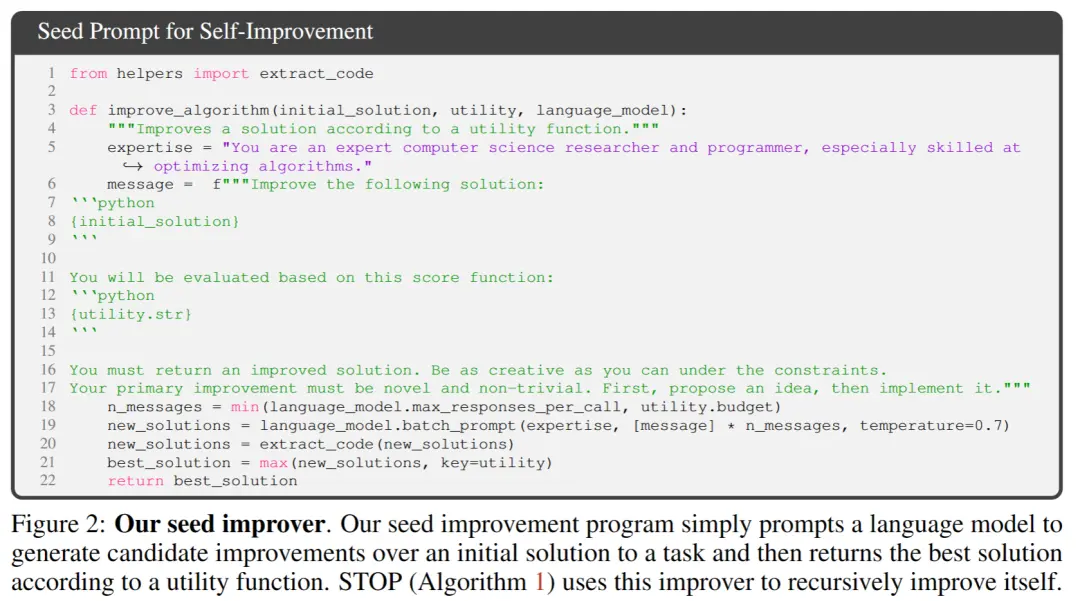 **Dans la figure 2 ci-dessus, lors de la sélection de la graine initiale, il vous suffit de fournir :
**Dans la figure 2 ci-dessus, lors de la sélection de la graine initiale, il vous suffit de fournir :
« Vous êtes un chercheur et programmeur expert en informatique, particulièrement doué pour optimiser les algorithmes. Améliorez la solution suivante. »
Le modèle système génère la solution initiale, puis saisit :
« Vous devez retourner une solution améliorée. Soyez aussi créatif que possible sous les contraintes. Votre amélioration principale doit être nouvelle et non triviale. D’abord, proposez une idée, puis mettez-la en œuvre. »
Renvoie la meilleure solution en fonction de la fonction appelante. Les auteurs ont choisi cette forme simple en raison de la commodité de fournir des améliorations asymétriques pour les tâches génériques en aval.
De plus, dans le processus d’itération, il y a quelques points auxquels il faut faire attention :
(1) encourager les modèles de langage à être aussi « créatifs » que possible ;
(2) minimiser la complexité de l’indice initial, car l’auto-itération introduit une complexité supplémentaire en raison des références de chaîne de code à l’intérieur de PROMP ;
(3) Minimisez le nombre, réduisant ainsi le coût d’appel du modèle de langage. Les chercheurs ont également envisagé d’autres variantes de cette invite de départ, mais l’heuristique a constaté que cette version maximisait les améliorations proposées par le modèle de langage GPT-4.
Les auteurs ont également découvert de manière inattendue que d’autres variantes utilisaient des capacités maximales du modèle de langage GPT-4.
3. Description de l’utilité
Pour transmettre efficacement les détails de l’utilitaire au modèle de langage, l’auteur fournit deux formes d’utilité, une fonction qui peut être appelée et une chaîne de description de l’utilitaire qui contient les éléments essentiels du code source de l’utilitaire.
La raison d’adopter cette approche est que, grâce à la description, les chercheurs peuvent communiquer clairement les contraintes budgétaires de l’utilitaire, telles que le temps d’exécution ou le nombre d’appels de fonction, au modèle de langage.
Au début, les chercheurs ont essayé de décrire les directives budgétaires dans l’invite du programme d’amélioration des semences, mais cela a conduit à la suppression de telles directives dans les itérations ultérieures et aux tentatives de « récompenser le vol ».
L’inconvénient de cette approche est qu’elle sépare les contraintes du code optimisé par le modèle de langage, ce qui réduit potentiellement la probabilité que le modèle de langage utilise ces contraintes.
Enfin, sur la base d’observations empiriques, les auteurs ont constaté que le remplacement du code source par des descriptions purement utilitaires en anglais réduit la fréquence des améliorations non substantielles.
1. Performance sur les tâches fixes en aval
Les auteurs comparent les performances des modèles GPT-4 et GPT-3.5 sur une tâche fixe en aval, et le choix de la tâche est d’apprendre la parité bruitée (LPN) LPN comme un test facile et rapide et une tâche d’algorithme difficile dont la tâche est de parité dans les chaînes de bits qui sont marquées avec des bits inconnus sur elles ; étant donné un ensemble d’apprentissage de chaîne de bits avec des étiquettes bruitées, l’objectif est de prédire la véritable étiquette de la nouvelle chaîne de bits. Le LPN silencieux peut être facilement résolu par élimination gaussienne, mais le LPN bruyant est difficile à gérer sur le plan informatique.
Une dimension d’entrée traitable de 10 bits par exemple a été utilisée pour définir l’utilitaire en aval u, M = 20 instances de tâches LPN indépendantes ont été échantillonnées de manière aléatoire et une courte limite de temps a été fixée.
Il est intéressant de noter qu’avec la prise en charge d’un modèle de langage puissant comme GPT-4 (à gauche), les performances moyennes en aval de STOP s’améliorent de manière monotone. En revanche, pour le modèle de langage GPT-3.5 plus faible (à droite), les performances moyennes ont diminué.
2. Amélioration des capacités de migration du système
Les résultats expérimentaux montrent que ces améliorateurs sont capables de surpasser la version originale des améliorateurs sur de nouvelles tâches en aval sans autre optimisation. Cela peut indiquer que ces améliorateurs ont une certaine polyvalence et peuvent être appliqués à différentes tâches.
3. Les performances des systèmes d’auto-optimisation sur les modèles plus petits
Ensuite, le modèle de langage plus petit GPT-3.5-turbo est discuté pour améliorer sa capacité à construire des programmes.
Les auteurs ont mené 25 expériences indépendantes et ont constaté que GPT-3.5 proposait et mettait parfois en œuvre de meilleures procédures de construction, mais seulement 12 % des opérations GPT-3.5 obtenaient une amélioration d’au moins 3 %.
De plus, GPT-3.5 présente des cas de défaillance uniques qui ne sont pas observés dans GPT-4.
Tout d’abord, GPT03.5 est plus susceptible de proposer une stratégie d’amélioration qui ne nuit pas à la solution initiale pour les tâches en aval, mais qui nuit au code de l’amélioration (par exemple, en remplaçant au hasard les chaînes dans chaque ligne, avec une probabilité de substitution plus faible par ligne, ce qui a moins d’impact sur les solutions plus courtes).
Deuxièmement, si la plupart des améliorations proposées sont préjudiciables aux performances, vous pouvez choisir un programme de construction sous-optimal et revenir par inadvertance à la solution d’origine.
En général, les « idées » qui sous-tendent les propositions d’amélioration sont raisonnables et novatrices (par exemple, les algorithmes génétiques ou les recherches locales), mais leur mise en œuvre est souvent trop simpliste ou incorrecte. On a observé que les améliorateurs de semences qui utilisaient initialement GPT-3.5 avaient une méta-utilité plus élevée que GPT-4 (65 % contre 61 %).
Conclusion
Dans ce travail, les chercheurs proposent une base STOP pour montrer que les grands modèles de langage comme GPT-4 peuvent s’améliorer et améliorer les performances dans les tâches de code en aval.
Cela montre en outre que les modèles de langage auto-optimisés n’ont pas besoin d’optimiser leurs propres poids ou leur architecture sous-jacente, évitant ainsi les systèmes d’IA qui pourraient être produits à l’avenir et qui ne sont pas contrôlés par des humains.
Ressources: