La tempête des grands modèles a soufflé pendant la majeure partie de l’année, et le marché de l’AIGC a commencé à changer à nouveau :
Les démonstrations de technologies sympas sont remplacées par des expériences de produits complètes. **
Par exemple, le dernier modèle de peinture IA d’OpenAI, DALL· Dès ses débuts, le E 3 s’est associé à ChatGPT pour devenir le nouvel outil de productivité le plus attendu de ChatGPT Plus.
** **###### △DALL· E3 reproduit avec précision chaque détail de la saisie de texte
Par exemple, le Copilot de Microsoft basé sur GPT-4 a été entièrement installé dans Windows 11, remplaçant officiellement Cortana en tant que nouvelle génération d’assistants IA dans le système d’exploitation.
** **###### △ Utilisez Copilot pour résumer les articles de blog en un clic
Pour un autre exemple, les voitures domestiques telles que Jiyue 01 ont officiellement équipé de grands modèles dans le cockpit, et ils sont complètement hors ligne ...
Si « les grands modèles remodèlent tout » en mars 2023 n’était qu’une prédiction optimiste des pionniers de la technologie, aujourd’hui, la guerre toujours féroce des 100 modèles et les progrès des applications pratiques ont rendu ce point de vue de plus en plus résonnant à l’intérieur et à l’extérieur de l’industrie.
En d’autres termes, de l’ensemble de la méthode de production Internet au cockpit intelligent dans chaque voiture, une ère d’auto-innovation avec de grands modèles comme base technique et moteur de milliers d’industries est à venir.
Selon la méthode de dénomination de l’ère de la vapeur et de l’ère électrique, elle peut être appelée « l’ère de la force modulaire ».
À l’ère Moli, l’un des scénarios les plus préoccupants est celui du terminal intelligent.
La raison en est simple : l’industrie des terminaux intelligents, représentée par les téléphones intelligents, les PC, les voitures intelligentes et même les appareils XR, est l’une des industries technologiques les plus étroitement liées à la vie des gens contemporains, et est naturellement devenue une référence pour tester la maturité des technologies de pointe.
Par conséquent, lorsque la première vague d’engouement provoquée par le boom technologique se calmera progressivement, avec le scénario des terminaux intelligents comme point d’ancrage, comment les nouvelles opportunités et les nouveaux défis de « l’ère de l’énergie modulaire » devraient-ils être considérés et interprétés ?
Maintenant, il est temps de le briser, de le pétrir et de le peigner.
Terminal intelligent, nouveau champ de bataille grand modèle
Avant d’analyser en détail les enjeux et les opportunités, revenons à la question essentielle : pourquoi l’IA générative est-elle représentée par de grands modèles si populaire, et même considérée comme la « quatrième révolution industrielle » ?
En réponse à ce phénomène, de nombreuses institutions ont mené des recherches pour tenter de prédire ou de résumer le développement de l’IA générative dans différents scénarios, tels que « Generative AI : A Creative New World » de Sequoia Capital.
Parmi eux, de nombreuses entreprises leaders de l’industrie ont analysé les scénarios d’atterrissage et les changements potentiels de direction de l’IA générative dans des industries spécifiques sur la base de leur propre expérience.
Par exemple, l’IA côté terminal représente l’acteur Qualcomm, et a publié il y a quelque temps un livre blanc sur l’état de développement et la tendance de l’IA générative « L’IA hybride est l’avenir de l’IA ».
À partir de là, il peut être possible d’interpréter les trois principales raisons pour lesquelles l’IA générative est populaire dans l’industrie.
Tout d’abord, la technologie elle-même est déjà assez difficile.
Qu’il s’agisse d’un grand modèle émergeant intelligemment ou d’une peinture IA qui génère une fausse qualité avec une fausse qualité, il s’agit d’utiliser des effets pour parler, et c’est un véritable domaine de travail lié au texte, aux images, à la vidéo et à l’automatisation, démontrant une capacité étonnante à perturber les flux de travail traditionnels.
Deuxièmement, il existe de riches scénarios d’atterrissage potentiels. La percée générationnelle de l’IA apportée par le grand modèle a apporté aux gens une imagination infinie depuis le début : le premier groupe d’expérimentateurs a rapidement perçu les avantages de l’IA générative pour fonctionner.
L’énorme demande du côté des utilisateurs peut être vue par le taux de croissance des utilisateurs d’applications représentatives telles que ChatGPT.
** **#### △ChatGPT a battu le record de plus de 100 millions d’utilisateurs enregistrés d’applications populaires, source Sequoia Capital
De la recherche initiale sur Internet, de la programmation, de la bureautique, à l’émergence du tourisme culturel, du droit, de la médecine, de l’industrie, des transports et d’autres applications de la scène, surfant sur le vent de l’IA générative, bien plus que les entreprises qui peuvent fournir de grands modèles de base, mais aussi un grand nombre de start-ups prospèrent et se développent.
De nombreux experts de l’industrie estiment que pour les entrepreneurs, la couche applicative apportée par les grands modèles offre de plus grandes opportunités.
Il y a une percée générationnelle de la technologie au bas de l’échelle, et une explosion vigoureuse de la demande d’applications au sommet, et l’effet écologique est stimulé.
Selon les prévisions de Bloomberg Intelligence, le marché de l’IA générative va exploser de 40 milliards de dollars à 1,3 billion de dollars** d’ici 2032, couvrant un large éventail d’acteurs de la chaîne écologique, y compris les infrastructures, les modèles de base, les outils de développement, les produits applicatifs, les produits terminaux, etc.
La formation de cette chaîne écologique a favorisé de nouveaux changements dans l’industrie et devrait faire de l’IA le cœur de la productivité sous-jacente.
Sur la base de ce contexte, examinons ce qui se passe dans l’industrie intelligente aujourd’hui.
D’une part, la tempête applicative AIGC représentée par de grands modèles est rapidement ** du cloud au terminal ** dans le rythme itération des jours.
ChatGPT est le premier à mettre à jour la fonction multimodale de « conversation audiovisuelle » sur le terminal mobile, et les utilisateurs peuvent prendre des photos et les télécharger, et ils peuvent parler à ChatGPT pour le contenu photo.
Par exemple, « Comment régler la hauteur de la selle du vélo » :
** **#### △ et dialogue graphique GPT-4, donne 5 suggestions en quelques secondes
Qualcomm a également rapidement réalisé le grand modèle de Stable Diffusion et ControlNet exécutant plus d’un milliard de paramètres côté terminal, et il ne faut que plus d’une douzaine de secondes pour générer des images IA de haute qualité sur les téléphones mobiles.
De nombreux fabricants de téléphones mobiles ont également annoncé qu’ils installeraient le « cerveau » de grands modèles pour leurs assistants vocaux.
Et il n’y a pas que les téléphones.
Dans les expositions à grande échelle au pays et à l’étranger, telles que le salon de l’automobile de Shanghai, le salon de l’automobile de Chengdu, le salon de l’automobile de Munich, etc., la coopération entre les fabricants de modèles de base et les constructeurs automobiles devient de plus en plus courante, et les grands modèles « monter sur la voiture » sont devenus un nouveau point de concurrence dans le domaine du cockpit intelligent.
** **###### △ Une phrase peut faire en sorte que le modèle de voiture achète des ingrédients dans l’APP, et vous pouvez cuisiner lorsque vous rentrez chez vous
D’autre part, l’apparition d’applications ** a exacerbé la situation selon laquelle la puissance de calcul est rare. **
Il est prévisible que le coût d’inférence du modèle augmentera avec l’augmentation du nombre d’utilisateurs actifs quotidiens et de leur fréquence d’utilisation, et il ne suffit pas de s’appuyer uniquement sur la puissance du cloud computing pour promouvoir rapidement l’échelle de l’IA générative.
Cela peut également être vu par le fait que tous les horizons de la société s’intéressent de plus en plus à la puissance de calcul de l’IA côté terminal.
Par exemple, le joueur d’IA côté terminal Qualcomm a publié une nouvelle génération de plate-forme informatique PC pour améliorer les performances de la puce PC, en utilisant le processeur Oryon auto-développé par Qualcomm, en particulier le NPU qui en est équipé fournira des performances plus puissantes pour l’IA générative, qui s’appelle la plate-forme de la série Snapdragon X.
Cette nouvelle plateforme informatique devrait être lancée lors du Snapdragon Summit 2023.
De toute évidence, que ce soit du point de vue de l’application ou de la puissance de calcul, les terminaux intelligents sont devenus l’un des scénarios avec le plus grand potentiel d’atterrissage de l’AIGC.
AIGC Récif sous marée
Les choses ont souvent deux côtés, et il en va de même pour les grands modèles, du développement rapide à l’atterrissage.
Lorsque l’IA générative a explosé jusqu’à aujourd’hui, le véritable goulot d’étranglement sous l’énorme potentiel de l’industrie des terminaux intelligents a fait surface.
**L’une des plus grandes contraintes est le niveau le plus bas du matériel. **
Comme l’ont mentionné les investisseurs de Sequoia, Sonya Huang et Pat Grady, dans leur dernier article d’analyse de l’IA générative « Generative AI’s Act Two », l’AIGC connaît une croissance rapide, mais le goulot d’étranglement attendu n’est pas la demande des clients, mais la puissance de calcul du côté de l’offre.
La puissance de calcul ici se réfère principalement aux accélérateurs matériels d’IA et d’apprentissage automatique, qui peuvent être divisés en cinq catégories du point de vue des scénarios de déploiement :
Des systèmes de classe centre de données, des accélérateurs au niveau du serveur, des accélérateurs pour la conduite assistée et des scénarios de conduite autonome, l’edge computing et des accélérateurs à très faible consommation d’énergie.
** **###### △5 types d’accélérateurs d’IA, source de l’article du MIT « AI and ML Accelerator Survey and Trends »
Avec l’explosion de ChatGPT, le grand modèle a évincé l’AIGC phénoménal du cercle, ce qui fait que la « puissance de calcul en nuage » telle que les centres de données et les processeurs au niveau du serveur reçoit beaucoup d’attention à court terme, et même la situation de pénurie.
Cependant, alors que l’IA générative entre dans sa deuxième phase, certaines questions sur la puissance de calcul deviennent de plus en plus importantes.
**Le premier et le plus gros problème est le coût. Comme indiqué dans le livre blanc de Qualcomm « L’IA hybride est l’avenir de l’IA », plus de six mois se sont écoulés, alors que les grands modèles passent de la recherche technologique à l’atterrissage d’applications, que la formation de base sur le modèle de chaque entreprise s’est progressivement installée et que la majeure partie de la puissance de calcul est tombée sur le raisonnement des grands modèles.
À court terme, le coût d’inférence est acceptable, mais comme il y a de plus en plus d’applications pour les grands modèles et de plus en plus de scénarios d’application, le coût de l’inférence sur les accélérateurs tels que les serveurs augmentera fortement, ce qui finira par entraîner un coût d’appel de grands modèles plus élevé que celui de l’entraînement des grands modèles eux-mêmes.
En d’autres termes, une fois que le grand modèle est entré dans la deuxième étape, la demande à long terme de puissance de calcul pour l’inférence sera beaucoup plus élevée que celle d’un seul entraînement, et s’appuyer uniquement sur la « puissance de calcul en nuage » composée de centres de données et de processeurs au niveau du serveur est totalement insuffisant pour atteindre l’inférence à un coût acceptable pour les utilisateurs.
Selon les statistiques de Qualcomm dans le livre blanc, si l’on prend l’exemple du moteur de recherche avec un grand modèle, le coût de chaque requête de recherche peut atteindre 10 fois celui des méthodes traditionnelles, et le coût annuel dans ce seul domaine peut augmenter de plusieurs milliards de dollars.
Celle-ci est destinée à devenir une contrainte clé à l’atterrissage des grands modèles.
**En plus de cela, il y a des problèmes de latence, de confidentialité et de personnalisation. ** Qualcomm a également mentionné dans « L’IA hybride est l’avenir de l’IA » que les grands modèles sont directement déployés dans le cloud, en plus de la quantité insuffisante de calcul du serveur causée par l’augmentation du nombre d’utilisateurs, la nécessité de « faire la queue pour l’utilisation » et d’autres bugs, il est également tenu de résoudre les problèmes de confidentialité et de personnalisation des utilisateurs.
Si les utilisateurs ne souhaitent pas télécharger de données dans le cloud, les scénarios d’utilisation des grands modèles, tels que la bureautique et l’assistant intelligent, seront soumis à de nombreuses restrictions, et la plupart de ces scénarios sont distribués côté terminal ; Si vous avez besoin d’obtenir de meilleurs résultats, par exemple en personnalisant de grands modèles pour votre propre usage, vous devez utiliser directement les informations personnelles pour l’entraînement des grands modèles.
Sous divers facteurs, la « puissance de calcul terminal » qui peut jouer un rôle dans le raisonnement, c’est-à-dire plusieurs types de processeurs, y compris la conduite automatique et la conduite assistée, l’informatique de pointe (embarquée) et les accélérateurs à très faible consommation d’énergie, ont commencé à entrer dans le champ de vision des gens.
Les terminaux ont une énorme puissance de calcul. Selon les prévisions d’IDC, le nombre d’appareils IoT dans le monde dépassera les 40 milliards d’ici 2025, générant près de 80 zettaoctets de données, et plus de la moitié des données doivent s’appuyer sur la puissance de calcul des terminaux ou des périphéries pour le traitement.
Cependant, le terminal présente également des problèmes tels qu’une consommation d’énergie et une dissipation thermique limitées, ce qui entraîne une puissance de calcul limitée.
Dans ce cas, comment utiliser l’énorme puissance de calcul cachée dans le terminal pour briser le goulot d’étranglement auquel est confronté le développement de la puissance du cloud computing devient l’un des problèmes techniques les plus courants à l’ère de l’énergie modulaire.
**Sans compter qu’en plus de la puissance de calcul, la mise en œuvre de grands modèles est également confrontée à des défis tels que les algorithmes, les données et la concurrence sur le marché. **
Pour l’algorithme, l’architecture du modèle sous-jacent est encore inconnue. ChatGPT a obtenu de bons résultats, mais sa voie technique n’est pas la direction architecturale du modèle de nouvelle génération.
Pour les données, des données de haute qualité sont indispensables pour que d’autres entreprises puissent obtenir les résultats du grand modèle de ChatGPT, mais l’acte deux de l’IA générative souligne également que les données générées par l’entreprise d’application ne créent pas vraiment de barrière.
L’avantage créé par les données est fragile et insoutenable, et la prochaine génération de modèles de base est susceptible de détruire directement ce « mur », en revanche, des utilisateurs continus et stables peuvent réellement construire des sources de données.
Pour le marché, il n’existe actuellement pas d’applications géniales pour les produits de grands modèles, et on ne sait toujours pas à quel type de scénarios il convient.
À l’heure actuelle, quel type de produits il est utilisé et quelles applications peuvent exercer sa plus grande valeur, le marché n’a pas encore donné un ensemble de méthodologies ou de réponses standard pouvant être suivies.
**En réponse à cette série de problèmes, il existe actuellement deux façons principales de résoudre les problèmes dans l’industrie. **
L’une consiste à améliorer l’algorithme du grand modèle lui-même, sans changer « l’essence » du modèle, à améliorer sa taille et à améliorer sa capacité de déploiement sur un plus grand nombre d’appareils ;
Si l’on prend l’exemple de l’algorithme Transformer, de tels modèles avec un grand nombre de paramètres doivent être ajustés dans la structure s’ils veulent fonctionner du côté de l’extrémité, c’est pourquoi de nombreux algorithmes légers tels que MobileViT sont nés pendant cette période.
Ces algorithmes cherchent à améliorer la structure et la quantité de paramètres sans affecter l’effet de sortie, afin qu’ils puissent fonctionner sur plus d’appareils avec des modèles plus petits.
L’autre est d’améliorer la puissance de calcul de l’IA du matériel lui-même, afin que les grands modèles puissent mieux atterrir du côté final.
Ces méthodes comprennent la conception multicœur sur le matériel et les piles logicielles de développement, qui sont utilisées pour améliorer les performances de calcul matériel et la polyvalence des modèles sur différents appareils, afin d’améliorer la possibilité que de grands modèles atterrissent sur le côté de l’extrémité.
Le premier peut être appelé l’adaptation du logiciel au matériel, et le second est que les fabricants de matériel s’adaptent au changement de marée de l’époque. Mais dans un sens comme dans l’autre, il y a un risque d’être dépassé par les seuls paris. **
À l’ère de la puissance modulaire, la technologie évolue de jour en jour, et de nouvelles percées peuvent apparaître de part et d’autre du logiciel et du matériel, et une fois que les réserves techniques nécessaires font défaut, elles peuvent prendre du retard.
Alors, devrions-nous suivre aveuglément ou simplement passer à côté du développement de cette vague de technologie ? Pas vraiment.
**Pour les entreprises qui ont découvert leur propre valeur à l’ère d’Internet et de l’IA, elles peuvent également être en mesure d’explorer une troisième idée de solution à l’ère de l’AIGC en fonction de leurs propres scénarios et de l’accumulation de technologies. **
Prenons l’exemple de Qualcomm, une entreprise d’IA qui propose à la fois des technologies logicielles et matérielles.
Confronté aux défis de la technologie des grands modèles dans différents scénarios, Qualcomm est sorti de l’identité d’une société de puces et a adopté très tôt la vague de l’AIGC.
En plus d’améliorer continuellement la puissance de calcul de l’IA de la puce côté terminal, Qualcomm met également en place une technologie d’IA de base, s’efforçant d’accélérer la vitesse de l’ensemble de l’industrie des terminaux intelligents pour adopter l’AIGC en tant qu’entreprise habilitante.
Cependant, cette approche présente également diverses difficultés prévisibles :
Pour des modèles d’IA plus grands et plus complexes, comment assurer la performance tout en la faisant fonctionner de manière fluide sur le terminal ?
Quand utiliser différents modèles pour répartir au mieux la puissance de calcul entre les terminaux et les clouds ?
Même si le problème des grands modèles déployés côté terminal est résolu, quelle partie doit être déployée dans le cloud et quelle partie doit être déployée sur le terminal, et comment s’assurer que les connexions et les fonctions entre les différentes parties du grand modèle ne sont pas affectées ?
Si l’avantage de performance côté terminal est insuffisant, comment le résoudre ?
......
Ces problèmes n’apparaissent pas dans un seul cas, mais existent déjà dans tous les secteurs ou scénarios touchés par l’AIGC.
Qu’il s’agisse d’une méthode révolutionnaire ou d’une expérience d’atterrissage réelle, la réponse ne peut être explorée qu’à partir de scénarios spécifiques et de cas industriels.
**Comment briser le brouillard de « l’ère du pouvoir modulaire » ? **
L’AIGC est entré dans la deuxième phase, les grands modèles deviennent de plus en plus populaires et l’industrie a commencé à explorer des moyens d’atterrir.
** Le livre blanc de Qualcomm « L’IA hybride est l’avenir de l’IA » mentionne que si l’on prend l’exemple des smartphones et des PC, il y a eu de nombreux cas de scénarios d’atterrissage AIGC dans la nouvelle industrie des terminaux intelligents sur le champ de bataille. **
Les entreprises déploient déjà des modèles plus petits et plus grands côté terminal pour des problèmes plus personnalisés, notamment la recherche de messages, la génération de messages de réponse, la modification des événements du calendrier et la navigation en un clic.
Par exemple, « réserver une place de restaurant préféré », basé sur le grand modèle, en fonction de l’analyse des données utilisateur des restaurants préférés et des horaires libres, donner des recommandations de planification et ajouter les résultats au calendrier.
Qualcomm estime qu’en raison de la quantité limitée de paramètres de modèle volumineux déployés par le terminal et de l’absence de mise en réseau, il peut y avoir une « illusion d’IA » lors de la réponse, et qu’il peut alors être basé sur la technologie d’orchestrateur pour définir des garde-fous lorsque le grand modèle manque d’informations pour éviter les problèmes ci-dessus.
Si vous n’êtes pas satisfait du contenu généré par le grand modèle, vous pouvez également envoyer la question au cloud pour exécution en un clic, puis remonter le résultat de la génération du grand modèle avec une meilleure réponse du côté terminal.
De cette façon, il peut non seulement réduire la pression de puissance de calcul des grands modèles exécutés dans le cloud, mais aussi garantir que les grands modèles peuvent être personnalisés tout en protégeant au maximum la vie privée des utilisateurs.
**En ce qui concerne les goulots d’étranglement techniques qui doivent être surmontés, tels que la puissance de calcul des terminaux et les algorithmes, certains joueurs ont également développé des « moyens de casser le jeu ». **
Dans le livre blanc, Qualcomm a introduit une classe de nouvelles technologies qui ont été largement utilisées dans le livre blanc, telles que le décodage spéculatif, qui a fait l’objet d’un incendie il y a quelque temps.
Il s’agit d’une méthode découverte par Google et DeepMind en même temps pour accélérer l’inférence de grands modèles, et peut appliquer un grand modèle plus petit pour accélérer la génération de grands modèles.
En termes simples, il s’agit d’entraîner un modèle plus petit et de générer à l’avance un lot de « mots candidats » pour le grand modèle, plutôt que de laisser le grand modèle « penser » et générer par lui-même, et faire directement des « choix ».
Étant donné que la vitesse de génération du petit modèle est plusieurs fois plus rapide que celle du grand modèle, une fois que le grand modèle estime que les mots que le petit modèle a déjà sont disponibles, il peut être pris directement sans le générer lentement vous-même.
Cette méthode tire principalement parti du fait que la vitesse d’inférence des grands modèles est plus affectée par la bande passante mémoire que par l’augmentation de la quantité de calcul.
En raison du grand nombre de paramètres et du dépassement de loin de la capacité du cache, les modèles volumineux sont plus susceptibles d’être limités par la bande passante mémoire que par les performances matérielles de calcul lors de l’inférence. Par exemple, GPT-3 a besoin de lire les 175 milliards de paramètres chaque fois qu’il génère un mot, et le matériel informatique est souvent inactif en attendant les données mémoire de la DRAM.
En d’autres termes, lorsque le modèle effectue une inférence par lots, il y a peu de différence de temps entre le traitement de 100 jetons et celui d’un jeton à la fois.
Par conséquent, l’utilisation de l’échantillonnage spéculatif permet non seulement d’exécuter facilement de grands modèles avec des dizaines de milliards de paramètres, mais aussi de mettre une partie de la puissance de calcul du côté terminal, assurant la vitesse d’inférence tout en conservant l’effet de génération des grands modèles.
......
Mais qu’il s’agisse d’un scénario ou d’une technologie, au final, nous devons trouver les points d’adaptation de chacun afin de produire une valeur applicative substantielle**, tout comme la relation entre logiciel et matériel est indissociable :
Les percées d’algorithmes logiciels tels que l’IA générative, lors de la recherche de scénarios d’atterrissage de terminaux intelligents, seront inévitablement confrontées à des exigences techniques combinées à du matériel d’IA mobile tel que Qualcomm.
Qu’il s’agisse des smartphones, des PC, de la XR, de l’automobile ou de l’Internet des objets, comment les différents segments de l’industrie des terminaux intelligents peuvent-ils trouver leur propre jeu et leur propre valeur en fonction des points d’accès de l’AIGC ?
Comment les entreprises peuvent-elles saisir cette vague de l’époque pour stimuler la valeur applicative de ce type de technologie et ne pas manquer l’opportunité de transformation de la productivité dans l’ensemble de l’industrie ?
Voir l'original
Cette page peut inclure du contenu de tiers fourni à des fins d'information uniquement. Gate ne garantit ni l'exactitude ni la validité de ces contenus, n’endosse pas les opinions exprimées, et ne fournit aucun conseil financier ou professionnel à travers ces informations. Voir la section Avertissement pour plus de détails.
La taille du marché sur 10 ans est de 1,3 billion de dollars américains, et l’ère de l’énergie modulaire est arrivée
Source d’origine : Qubits
La tempête des grands modèles a soufflé pendant la majeure partie de l’année, et le marché de l’AIGC a commencé à changer à nouveau :
Les démonstrations de technologies sympas sont remplacées par des expériences de produits complètes. **
Par exemple, le dernier modèle de peinture IA d’OpenAI, DALL· Dès ses débuts, le E 3 s’est associé à ChatGPT pour devenir le nouvel outil de productivité le plus attendu de ChatGPT Plus.
** **###### △DALL· E3 reproduit avec précision chaque détail de la saisie de texte
**###### △DALL· E3 reproduit avec précision chaque détail de la saisie de texte
Par exemple, le Copilot de Microsoft basé sur GPT-4 a été entièrement installé dans Windows 11, remplaçant officiellement Cortana en tant que nouvelle génération d’assistants IA dans le système d’exploitation.
** **###### △ Utilisez Copilot pour résumer les articles de blog en un clic
**###### △ Utilisez Copilot pour résumer les articles de blog en un clic
Pour un autre exemple, les voitures domestiques telles que Jiyue 01 ont officiellement équipé de grands modèles dans le cockpit, et ils sont complètement hors ligne ...
Si « les grands modèles remodèlent tout » en mars 2023 n’était qu’une prédiction optimiste des pionniers de la technologie, aujourd’hui, la guerre toujours féroce des 100 modèles et les progrès des applications pratiques ont rendu ce point de vue de plus en plus résonnant à l’intérieur et à l’extérieur de l’industrie.
En d’autres termes, de l’ensemble de la méthode de production Internet au cockpit intelligent dans chaque voiture, une ère d’auto-innovation avec de grands modèles comme base technique et moteur de milliers d’industries est à venir.
Selon la méthode de dénomination de l’ère de la vapeur et de l’ère électrique, elle peut être appelée « l’ère de la force modulaire ».
À l’ère Moli, l’un des scénarios les plus préoccupants est celui du terminal intelligent.
La raison en est simple : l’industrie des terminaux intelligents, représentée par les téléphones intelligents, les PC, les voitures intelligentes et même les appareils XR, est l’une des industries technologiques les plus étroitement liées à la vie des gens contemporains, et est naturellement devenue une référence pour tester la maturité des technologies de pointe.
Par conséquent, lorsque la première vague d’engouement provoquée par le boom technologique se calmera progressivement, avec le scénario des terminaux intelligents comme point d’ancrage, comment les nouvelles opportunités et les nouveaux défis de « l’ère de l’énergie modulaire » devraient-ils être considérés et interprétés ?
Maintenant, il est temps de le briser, de le pétrir et de le peigner.
Terminal intelligent, nouveau champ de bataille grand modèle
Avant d’analyser en détail les enjeux et les opportunités, revenons à la question essentielle : pourquoi l’IA générative est-elle représentée par de grands modèles si populaire, et même considérée comme la « quatrième révolution industrielle » ?
En réponse à ce phénomène, de nombreuses institutions ont mené des recherches pour tenter de prédire ou de résumer le développement de l’IA générative dans différents scénarios, tels que « Generative AI : A Creative New World » de Sequoia Capital.
Parmi eux, de nombreuses entreprises leaders de l’industrie ont analysé les scénarios d’atterrissage et les changements potentiels de direction de l’IA générative dans des industries spécifiques sur la base de leur propre expérience.
Par exemple, l’IA côté terminal représente l’acteur Qualcomm, et a publié il y a quelque temps un livre blanc sur l’état de développement et la tendance de l’IA générative « L’IA hybride est l’avenir de l’IA ».
À partir de là, il peut être possible d’interpréter les trois principales raisons pour lesquelles l’IA générative est populaire dans l’industrie.
Tout d’abord, la technologie elle-même est déjà assez difficile.
Qu’il s’agisse d’un grand modèle émergeant intelligemment ou d’une peinture IA qui génère une fausse qualité avec une fausse qualité, il s’agit d’utiliser des effets pour parler, et c’est un véritable domaine de travail lié au texte, aux images, à la vidéo et à l’automatisation, démontrant une capacité étonnante à perturber les flux de travail traditionnels.
Deuxièmement, il existe de riches scénarios d’atterrissage potentiels. La percée générationnelle de l’IA apportée par le grand modèle a apporté aux gens une imagination infinie depuis le début : le premier groupe d’expérimentateurs a rapidement perçu les avantages de l’IA générative pour fonctionner.
L’énorme demande du côté des utilisateurs peut être vue par le taux de croissance des utilisateurs d’applications représentatives telles que ChatGPT.
**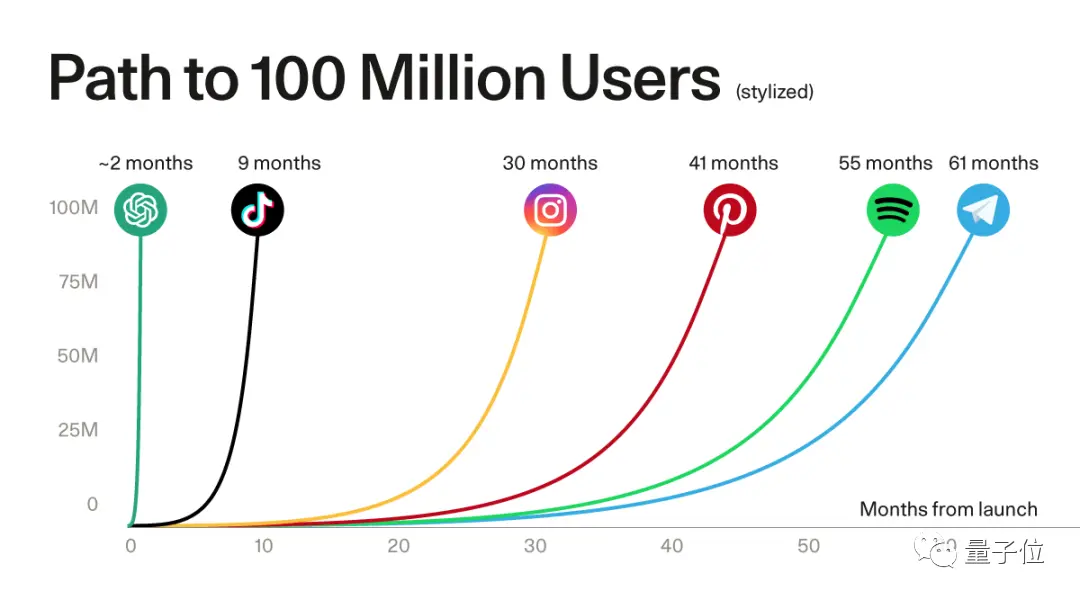 **#### △ChatGPT a battu le record de plus de 100 millions d’utilisateurs enregistrés d’applications populaires, source Sequoia Capital
**#### △ChatGPT a battu le record de plus de 100 millions d’utilisateurs enregistrés d’applications populaires, source Sequoia Capital
De la recherche initiale sur Internet, de la programmation, de la bureautique, à l’émergence du tourisme culturel, du droit, de la médecine, de l’industrie, des transports et d’autres applications de la scène, surfant sur le vent de l’IA générative, bien plus que les entreprises qui peuvent fournir de grands modèles de base, mais aussi un grand nombre de start-ups prospèrent et se développent.
De nombreux experts de l’industrie estiment que pour les entrepreneurs, la couche applicative apportée par les grands modèles offre de plus grandes opportunités.
Il y a une percée générationnelle de la technologie au bas de l’échelle, et une explosion vigoureuse de la demande d’applications au sommet, et l’effet écologique est stimulé.
Selon les prévisions de Bloomberg Intelligence, le marché de l’IA générative va exploser de 40 milliards de dollars à 1,3 billion de dollars** d’ici 2032, couvrant un large éventail d’acteurs de la chaîne écologique, y compris les infrastructures, les modèles de base, les outils de développement, les produits applicatifs, les produits terminaux, etc.
Sur la base de ce contexte, examinons ce qui se passe dans l’industrie intelligente aujourd’hui.
D’une part, la tempête applicative AIGC représentée par de grands modèles est rapidement ** du cloud au terminal ** dans le rythme itération des jours.
ChatGPT est le premier à mettre à jour la fonction multimodale de « conversation audiovisuelle » sur le terminal mobile, et les utilisateurs peuvent prendre des photos et les télécharger, et ils peuvent parler à ChatGPT pour le contenu photo.
Par exemple, « Comment régler la hauteur de la selle du vélo » :
**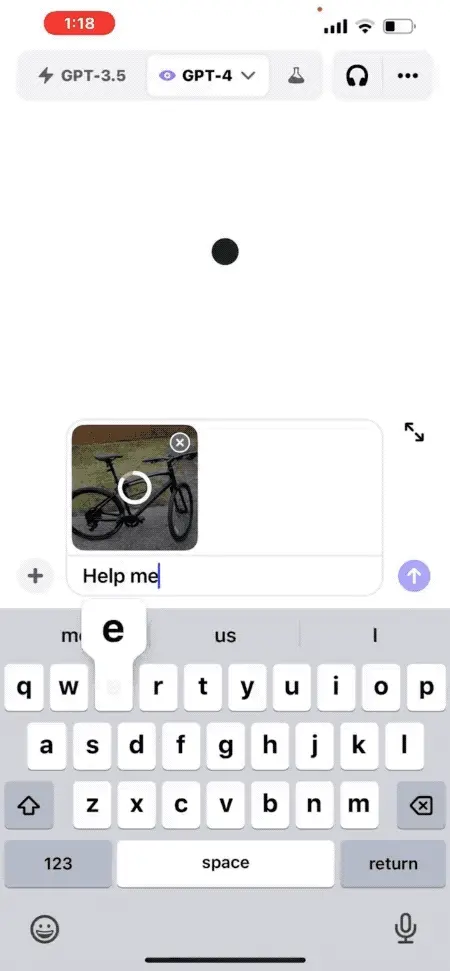 **#### △ et dialogue graphique GPT-4, donne 5 suggestions en quelques secondes
**#### △ et dialogue graphique GPT-4, donne 5 suggestions en quelques secondes
Qualcomm a également rapidement réalisé le grand modèle de Stable Diffusion et ControlNet exécutant plus d’un milliard de paramètres côté terminal, et il ne faut que plus d’une douzaine de secondes pour générer des images IA de haute qualité sur les téléphones mobiles.
De nombreux fabricants de téléphones mobiles ont également annoncé qu’ils installeraient le « cerveau » de grands modèles pour leurs assistants vocaux.
Et il n’y a pas que les téléphones.
Dans les expositions à grande échelle au pays et à l’étranger, telles que le salon de l’automobile de Shanghai, le salon de l’automobile de Chengdu, le salon de l’automobile de Munich, etc., la coopération entre les fabricants de modèles de base et les constructeurs automobiles devient de plus en plus courante, et les grands modèles « monter sur la voiture » sont devenus un nouveau point de concurrence dans le domaine du cockpit intelligent.
**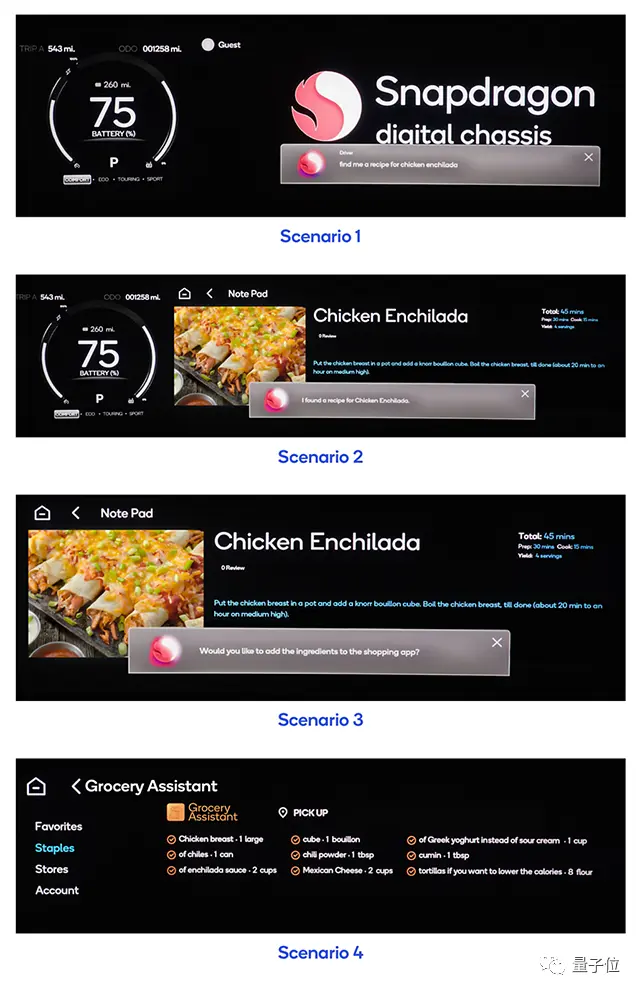 **###### △ Une phrase peut faire en sorte que le modèle de voiture achète des ingrédients dans l’APP, et vous pouvez cuisiner lorsque vous rentrez chez vous
**###### △ Une phrase peut faire en sorte que le modèle de voiture achète des ingrédients dans l’APP, et vous pouvez cuisiner lorsque vous rentrez chez vous
D’autre part, l’apparition d’applications ** a exacerbé la situation selon laquelle la puissance de calcul est rare. **
Il est prévisible que le coût d’inférence du modèle augmentera avec l’augmentation du nombre d’utilisateurs actifs quotidiens et de leur fréquence d’utilisation, et il ne suffit pas de s’appuyer uniquement sur la puissance du cloud computing pour promouvoir rapidement l’échelle de l’IA générative.
Cela peut également être vu par le fait que tous les horizons de la société s’intéressent de plus en plus à la puissance de calcul de l’IA côté terminal.
Par exemple, le joueur d’IA côté terminal Qualcomm a publié une nouvelle génération de plate-forme informatique PC pour améliorer les performances de la puce PC, en utilisant le processeur Oryon auto-développé par Qualcomm, en particulier le NPU qui en est équipé fournira des performances plus puissantes pour l’IA générative, qui s’appelle la plate-forme de la série Snapdragon X.
Cette nouvelle plateforme informatique devrait être lancée lors du Snapdragon Summit 2023.
De toute évidence, que ce soit du point de vue de l’application ou de la puissance de calcul, les terminaux intelligents sont devenus l’un des scénarios avec le plus grand potentiel d’atterrissage de l’AIGC.
AIGC Récif sous marée
Les choses ont souvent deux côtés, et il en va de même pour les grands modèles, du développement rapide à l’atterrissage.
Lorsque l’IA générative a explosé jusqu’à aujourd’hui, le véritable goulot d’étranglement sous l’énorme potentiel de l’industrie des terminaux intelligents a fait surface.
**L’une des plus grandes contraintes est le niveau le plus bas du matériel. **
Comme l’ont mentionné les investisseurs de Sequoia, Sonya Huang et Pat Grady, dans leur dernier article d’analyse de l’IA générative « Generative AI’s Act Two », l’AIGC connaît une croissance rapide, mais le goulot d’étranglement attendu n’est pas la demande des clients, mais la puissance de calcul du côté de l’offre.
La puissance de calcul ici se réfère principalement aux accélérateurs matériels d’IA et d’apprentissage automatique, qui peuvent être divisés en cinq catégories du point de vue des scénarios de déploiement :
Des systèmes de classe centre de données, des accélérateurs au niveau du serveur, des accélérateurs pour la conduite assistée et des scénarios de conduite autonome, l’edge computing et des accélérateurs à très faible consommation d’énergie.
**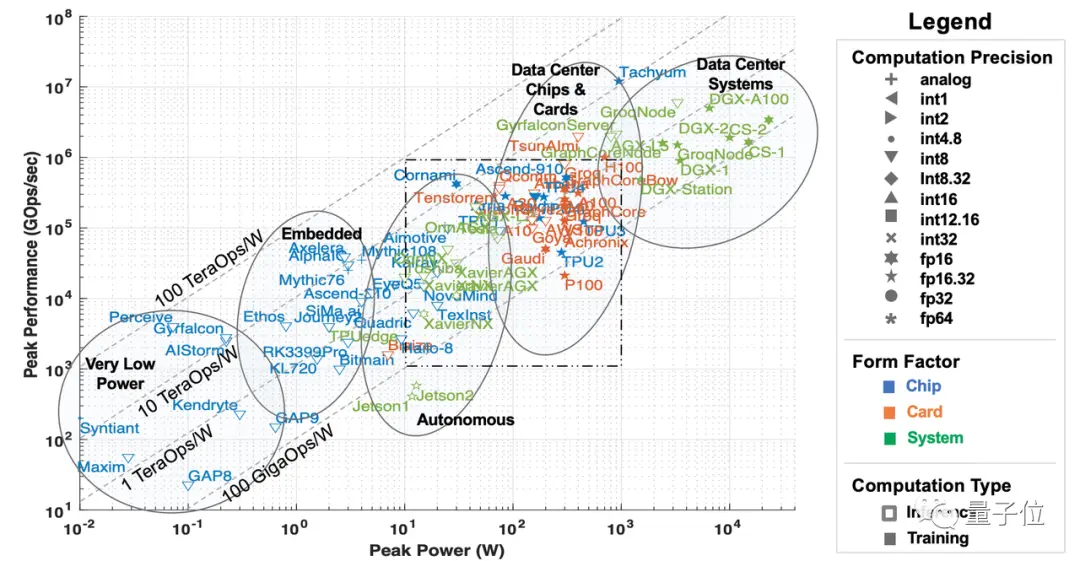 **###### △5 types d’accélérateurs d’IA, source de l’article du MIT « AI and ML Accelerator Survey and Trends »
**###### △5 types d’accélérateurs d’IA, source de l’article du MIT « AI and ML Accelerator Survey and Trends »
Avec l’explosion de ChatGPT, le grand modèle a évincé l’AIGC phénoménal du cercle, ce qui fait que la « puissance de calcul en nuage » telle que les centres de données et les processeurs au niveau du serveur reçoit beaucoup d’attention à court terme, et même la situation de pénurie.
Cependant, alors que l’IA générative entre dans sa deuxième phase, certaines questions sur la puissance de calcul deviennent de plus en plus importantes.
**Le premier et le plus gros problème est le coût. Comme indiqué dans le livre blanc de Qualcomm « L’IA hybride est l’avenir de l’IA », plus de six mois se sont écoulés, alors que les grands modèles passent de la recherche technologique à l’atterrissage d’applications, que la formation de base sur le modèle de chaque entreprise s’est progressivement installée et que la majeure partie de la puissance de calcul est tombée sur le raisonnement des grands modèles.
À court terme, le coût d’inférence est acceptable, mais comme il y a de plus en plus d’applications pour les grands modèles et de plus en plus de scénarios d’application, le coût de l’inférence sur les accélérateurs tels que les serveurs augmentera fortement, ce qui finira par entraîner un coût d’appel de grands modèles plus élevé que celui de l’entraînement des grands modèles eux-mêmes.
En d’autres termes, une fois que le grand modèle est entré dans la deuxième étape, la demande à long terme de puissance de calcul pour l’inférence sera beaucoup plus élevée que celle d’un seul entraînement, et s’appuyer uniquement sur la « puissance de calcul en nuage » composée de centres de données et de processeurs au niveau du serveur est totalement insuffisant pour atteindre l’inférence à un coût acceptable pour les utilisateurs.
Selon les statistiques de Qualcomm dans le livre blanc, si l’on prend l’exemple du moteur de recherche avec un grand modèle, le coût de chaque requête de recherche peut atteindre 10 fois celui des méthodes traditionnelles, et le coût annuel dans ce seul domaine peut augmenter de plusieurs milliards de dollars.
Celle-ci est destinée à devenir une contrainte clé à l’atterrissage des grands modèles.
**En plus de cela, il y a des problèmes de latence, de confidentialité et de personnalisation. ** Qualcomm a également mentionné dans « L’IA hybride est l’avenir de l’IA » que les grands modèles sont directement déployés dans le cloud, en plus de la quantité insuffisante de calcul du serveur causée par l’augmentation du nombre d’utilisateurs, la nécessité de « faire la queue pour l’utilisation » et d’autres bugs, il est également tenu de résoudre les problèmes de confidentialité et de personnalisation des utilisateurs.
Si les utilisateurs ne souhaitent pas télécharger de données dans le cloud, les scénarios d’utilisation des grands modèles, tels que la bureautique et l’assistant intelligent, seront soumis à de nombreuses restrictions, et la plupart de ces scénarios sont distribués côté terminal ; Si vous avez besoin d’obtenir de meilleurs résultats, par exemple en personnalisant de grands modèles pour votre propre usage, vous devez utiliser directement les informations personnelles pour l’entraînement des grands modèles.
Sous divers facteurs, la « puissance de calcul terminal » qui peut jouer un rôle dans le raisonnement, c’est-à-dire plusieurs types de processeurs, y compris la conduite automatique et la conduite assistée, l’informatique de pointe (embarquée) et les accélérateurs à très faible consommation d’énergie, ont commencé à entrer dans le champ de vision des gens.
Les terminaux ont une énorme puissance de calcul. Selon les prévisions d’IDC, le nombre d’appareils IoT dans le monde dépassera les 40 milliards d’ici 2025, générant près de 80 zettaoctets de données, et plus de la moitié des données doivent s’appuyer sur la puissance de calcul des terminaux ou des périphéries pour le traitement.
Cependant, le terminal présente également des problèmes tels qu’une consommation d’énergie et une dissipation thermique limitées, ce qui entraîne une puissance de calcul limitée.
Dans ce cas, comment utiliser l’énorme puissance de calcul cachée dans le terminal pour briser le goulot d’étranglement auquel est confronté le développement de la puissance du cloud computing devient l’un des problèmes techniques les plus courants à l’ère de l’énergie modulaire.
**Sans compter qu’en plus de la puissance de calcul, la mise en œuvre de grands modèles est également confrontée à des défis tels que les algorithmes, les données et la concurrence sur le marché. **
Pour l’algorithme, l’architecture du modèle sous-jacent est encore inconnue. ChatGPT a obtenu de bons résultats, mais sa voie technique n’est pas la direction architecturale du modèle de nouvelle génération.
Pour les données, des données de haute qualité sont indispensables pour que d’autres entreprises puissent obtenir les résultats du grand modèle de ChatGPT, mais l’acte deux de l’IA générative souligne également que les données générées par l’entreprise d’application ne créent pas vraiment de barrière.
L’avantage créé par les données est fragile et insoutenable, et la prochaine génération de modèles de base est susceptible de détruire directement ce « mur », en revanche, des utilisateurs continus et stables peuvent réellement construire des sources de données.
Pour le marché, il n’existe actuellement pas d’applications géniales pour les produits de grands modèles, et on ne sait toujours pas à quel type de scénarios il convient.
À l’heure actuelle, quel type de produits il est utilisé et quelles applications peuvent exercer sa plus grande valeur, le marché n’a pas encore donné un ensemble de méthodologies ou de réponses standard pouvant être suivies.
L’une consiste à améliorer l’algorithme du grand modèle lui-même, sans changer « l’essence » du modèle, à améliorer sa taille et à améliorer sa capacité de déploiement sur un plus grand nombre d’appareils ;
Si l’on prend l’exemple de l’algorithme Transformer, de tels modèles avec un grand nombre de paramètres doivent être ajustés dans la structure s’ils veulent fonctionner du côté de l’extrémité, c’est pourquoi de nombreux algorithmes légers tels que MobileViT sont nés pendant cette période.
Ces algorithmes cherchent à améliorer la structure et la quantité de paramètres sans affecter l’effet de sortie, afin qu’ils puissent fonctionner sur plus d’appareils avec des modèles plus petits.
L’autre est d’améliorer la puissance de calcul de l’IA du matériel lui-même, afin que les grands modèles puissent mieux atterrir du côté final.
Ces méthodes comprennent la conception multicœur sur le matériel et les piles logicielles de développement, qui sont utilisées pour améliorer les performances de calcul matériel et la polyvalence des modèles sur différents appareils, afin d’améliorer la possibilité que de grands modèles atterrissent sur le côté de l’extrémité.
Le premier peut être appelé l’adaptation du logiciel au matériel, et le second est que les fabricants de matériel s’adaptent au changement de marée de l’époque. Mais dans un sens comme dans l’autre, il y a un risque d’être dépassé par les seuls paris. **
À l’ère de la puissance modulaire, la technologie évolue de jour en jour, et de nouvelles percées peuvent apparaître de part et d’autre du logiciel et du matériel, et une fois que les réserves techniques nécessaires font défaut, elles peuvent prendre du retard.
Alors, devrions-nous suivre aveuglément ou simplement passer à côté du développement de cette vague de technologie ? Pas vraiment.
**Pour les entreprises qui ont découvert leur propre valeur à l’ère d’Internet et de l’IA, elles peuvent également être en mesure d’explorer une troisième idée de solution à l’ère de l’AIGC en fonction de leurs propres scénarios et de l’accumulation de technologies. **
Prenons l’exemple de Qualcomm, une entreprise d’IA qui propose à la fois des technologies logicielles et matérielles.
Confronté aux défis de la technologie des grands modèles dans différents scénarios, Qualcomm est sorti de l’identité d’une société de puces et a adopté très tôt la vague de l’AIGC.
En plus d’améliorer continuellement la puissance de calcul de l’IA de la puce côté terminal, Qualcomm met également en place une technologie d’IA de base, s’efforçant d’accélérer la vitesse de l’ensemble de l’industrie des terminaux intelligents pour adopter l’AIGC en tant qu’entreprise habilitante.
Cependant, cette approche présente également diverses difficultés prévisibles :
Pour des modèles d’IA plus grands et plus complexes, comment assurer la performance tout en la faisant fonctionner de manière fluide sur le terminal ?
Quand utiliser différents modèles pour répartir au mieux la puissance de calcul entre les terminaux et les clouds ?
Même si le problème des grands modèles déployés côté terminal est résolu, quelle partie doit être déployée dans le cloud et quelle partie doit être déployée sur le terminal, et comment s’assurer que les connexions et les fonctions entre les différentes parties du grand modèle ne sont pas affectées ?
Si l’avantage de performance côté terminal est insuffisant, comment le résoudre ?
......
Ces problèmes n’apparaissent pas dans un seul cas, mais existent déjà dans tous les secteurs ou scénarios touchés par l’AIGC.
Qu’il s’agisse d’une méthode révolutionnaire ou d’une expérience d’atterrissage réelle, la réponse ne peut être explorée qu’à partir de scénarios spécifiques et de cas industriels.
**Comment briser le brouillard de « l’ère du pouvoir modulaire » ? **
L’AIGC est entré dans la deuxième phase, les grands modèles deviennent de plus en plus populaires et l’industrie a commencé à explorer des moyens d’atterrir.
** Le livre blanc de Qualcomm « L’IA hybride est l’avenir de l’IA » mentionne que si l’on prend l’exemple des smartphones et des PC, il y a eu de nombreux cas de scénarios d’atterrissage AIGC dans la nouvelle industrie des terminaux intelligents sur le champ de bataille. **
Les entreprises déploient déjà des modèles plus petits et plus grands côté terminal pour des problèmes plus personnalisés, notamment la recherche de messages, la génération de messages de réponse, la modification des événements du calendrier et la navigation en un clic.
Par exemple, « réserver une place de restaurant préféré », basé sur le grand modèle, en fonction de l’analyse des données utilisateur des restaurants préférés et des horaires libres, donner des recommandations de planification et ajouter les résultats au calendrier.
Qualcomm estime qu’en raison de la quantité limitée de paramètres de modèle volumineux déployés par le terminal et de l’absence de mise en réseau, il peut y avoir une « illusion d’IA » lors de la réponse, et qu’il peut alors être basé sur la technologie d’orchestrateur pour définir des garde-fous lorsque le grand modèle manque d’informations pour éviter les problèmes ci-dessus.
Si vous n’êtes pas satisfait du contenu généré par le grand modèle, vous pouvez également envoyer la question au cloud pour exécution en un clic, puis remonter le résultat de la génération du grand modèle avec une meilleure réponse du côté terminal.
De cette façon, il peut non seulement réduire la pression de puissance de calcul des grands modèles exécutés dans le cloud, mais aussi garantir que les grands modèles peuvent être personnalisés tout en protégeant au maximum la vie privée des utilisateurs.
Dans le livre blanc, Qualcomm a introduit une classe de nouvelles technologies qui ont été largement utilisées dans le livre blanc, telles que le décodage spéculatif, qui a fait l’objet d’un incendie il y a quelque temps.
Il s’agit d’une méthode découverte par Google et DeepMind en même temps pour accélérer l’inférence de grands modèles, et peut appliquer un grand modèle plus petit pour accélérer la génération de grands modèles.
En termes simples, il s’agit d’entraîner un modèle plus petit et de générer à l’avance un lot de « mots candidats » pour le grand modèle, plutôt que de laisser le grand modèle « penser » et générer par lui-même, et faire directement des « choix ».
Étant donné que la vitesse de génération du petit modèle est plusieurs fois plus rapide que celle du grand modèle, une fois que le grand modèle estime que les mots que le petit modèle a déjà sont disponibles, il peut être pris directement sans le générer lentement vous-même.
Cette méthode tire principalement parti du fait que la vitesse d’inférence des grands modèles est plus affectée par la bande passante mémoire que par l’augmentation de la quantité de calcul.
En raison du grand nombre de paramètres et du dépassement de loin de la capacité du cache, les modèles volumineux sont plus susceptibles d’être limités par la bande passante mémoire que par les performances matérielles de calcul lors de l’inférence. Par exemple, GPT-3 a besoin de lire les 175 milliards de paramètres chaque fois qu’il génère un mot, et le matériel informatique est souvent inactif en attendant les données mémoire de la DRAM.
En d’autres termes, lorsque le modèle effectue une inférence par lots, il y a peu de différence de temps entre le traitement de 100 jetons et celui d’un jeton à la fois.
Par conséquent, l’utilisation de l’échantillonnage spéculatif permet non seulement d’exécuter facilement de grands modèles avec des dizaines de milliards de paramètres, mais aussi de mettre une partie de la puissance de calcul du côté terminal, assurant la vitesse d’inférence tout en conservant l’effet de génération des grands modèles.
Mais qu’il s’agisse d’un scénario ou d’une technologie, au final, nous devons trouver les points d’adaptation de chacun afin de produire une valeur applicative substantielle**, tout comme la relation entre logiciel et matériel est indissociable :
Les percées d’algorithmes logiciels tels que l’IA générative, lors de la recherche de scénarios d’atterrissage de terminaux intelligents, seront inévitablement confrontées à des exigences techniques combinées à du matériel d’IA mobile tel que Qualcomm.
Qu’il s’agisse des smartphones, des PC, de la XR, de l’automobile ou de l’Internet des objets, comment les différents segments de l’industrie des terminaux intelligents peuvent-ils trouver leur propre jeu et leur propre valeur en fonction des points d’accès de l’AIGC ?
Comment les entreprises peuvent-elles saisir cette vague de l’époque pour stimuler la valeur applicative de ce type de technologie et ne pas manquer l’opportunité de transformation de la productivité dans l’ensemble de l’industrie ?