Faites en sorte que les grands modèles regardent les diagrammes plutôt que la dactylographie fonctionne ! Une nouvelle étude de NeurIPS 2023 propose une méthode de requête multimodale, la précision s’améliore de 7,8 %
La capacité des grands modèles à « lire les images » est si forte, pourquoi continuez-vous à chercher les mauvaises choses ?
Par exemple, confondre les chauves-souris qui ne leur ressemblent pas avec les raquettes, ou ne pas reconnaître les poissons rares dans certains jeux de données...
En effet, lorsque nous laissons un grand modèle « trouver quelque chose », nous saisissons souvent texte.
Si la description est ambiguë ou trop partielle, comme « chauve-souris » (chauve-souris ou battement ?). Ou « Cyprinodon diabolis », et l’IA sera confuse.
Cela conduit à l’utilisation de grands modèles pour faire de la détection d’objets, en particulier des tâches de détection d’objets en monde ouvert (scène inconnue), l’effet n’est souvent pas aussi bon que prévu.
Aujourd’hui, un article inclus dans NeurIPS 2023 a enfin résolu ce problème.
Cet article propose une méthode de détection d’objets MQ-Det basée sur une requête multimodale, qui n’a besoin que d’ajouter un exemple d’image à l’entrée, ce qui peut grandement améliorer la précision de la recherche d’objets dans de grands modèles.
Sur l’ensemble de données de détection de référence LVIS, MQ-Det améliore la précision GLIP des grands modèles de détection grand public d’environ 7,8 % en moyenne, et améliore la précision de 13 tâches en aval de petits échantillons de référence de 6,3 % en moyenne.
Comment cela se fait-il exactement ? Jetons un coup d’œil.
Ce qui suit est reproduit de l’auteur de l’article, le blogueur Zhihu @Qinyuanxia :
Table des matières
MQ-Det : Grand modèle de détection d’objets en monde ouvert pour l’interrogation multimodale
1.1 De la requête textuelle à la requête multimodale
1.2 Architecture du modèle de requête multimodale plug-and-play MQ-Det
1.3 Stratégie d’entraînement efficace MQ-Det
1.4 Résultats expérimentaux : Évaluation sans réglage fin
*1.5 Résultats expérimentaux : Évaluation en quelques coups
1.6 Interrogation multimodale de la perspective de détection d’objets
MQ-Det : Grand modèle de détection d’objets en monde ouvert pour les requêtes multimodales**
Détection d’objets interrogés multimodaux dans la nature
Lien vers le papier :
Adresse de code :**
### 1.1 De la requête texte à la requête multimodale
Une image vaut mille mots : Avec l’essor du pré-entraînement graphique, à l’aide de la sémantique ouverte du texte, la détection d’objets est progressivement entrée dans le stade de la perception du monde ouvert. Pour cette raison, de nombreux grands modèles de détection suivent le modèle de requête textuelle, c’est-à-dire l’utilisation de descriptions textuelles catégorielles pour interroger des cibles potentielles dans les images cibles. Cependant, cette approche se heurte souvent au problème de l’approche « large mais non raffinée ».
Par exemple, (1) la détection d’objets à grain fin (alevins) dans la figure 1 est souvent difficile à décrire les différentes espèces à grain fin avec un texte limité, et (2) l’ambiguïté de la catégorie (« chauve-souris » peut faire référence à la fois à une chauve-souris et à une raquette).
Cependant, les problèmes ci-dessus peuvent être résolus par des exemples d’images, qui fournissent des indices de caractéristiques plus riches sur l’objet cible que le texte, mais en même temps le texte a une forte généralisation.
Par conséquent, la façon de combiner organiquement les deux méthodes de requête est devenue une idée naturelle.
Difficultés à obtenir des capacités de requête multimodale : il existe trois défis dans l’obtention d’un tel modèle avec des requêtes multimodales : (1) Un réglage précis direct avec des exemples d’images limités peut facilement conduire à des oublis catastrophiques ; (2) L’entraînement d’un grand modèle de détection à partir de zéro aura une bonne généralisation mais une consommation énorme, par exemple, l’entraînement GLIP sur une seule carte nécessite 480 jours d’entraînement avec un volume de 30 millions de données.
Détection d’objets de requête multimodale : Sur la base des considérations ci-dessus, l’auteur propose une stratégie simple et efficace de conception et d’entraînement de modèles - MQ-Det.
MQ-Det insère un petit nombre de modules de perception à portes (GCP) pour recevoir l’entrée d’exemples visuels sur la base du grand modèle existant de détection de requête de texte gelé, et conçoit une stratégie d’entraînement à la prédiction du langage de masque de condition visuelle pour obtenir efficacement un détecteur pour les requêtes multimodales hautes performances.
1.2 Architecture de modèle de requête multimodale plug-and-play MQ-Det
** **####### △Figure 1 Schéma d’architecture de la méthode MQ-Det
Module de perception fermée
Comme le montre la figure 1, l’auteur insère un module de contrôle de contrôle (GCP) couche par couche du côté de l’encodeur de texte du grand modèle existant de détection de requête de texte gelé, et le mode de fonctionnement de GCP peut être représenté succinctement par la formule suivante :
Pour la ième catégorie, entrez l’exemple visuel Vi, qui croise d’abord l’attention croisée (X-MHA) avec l’image cible I
pour élargir ses capacités de représentation, puis chaque texte de catégorie ti et l’exemple visuel de catégorie correspondante
Effectuer des échanges d’attention croisée
, après quoi le texte original ti et l’augmentation visuelle du texte sont mis en valeur par une porte de module de contrôle
Fusion pour obtenir la sortie de la couche courante
。 Cette conception simple suit trois principes : (1) l’évolutivité des catégories ; (2) la complétude sémantique ; (3) Anti-amnésie, une discussion spécifique peut être trouvée dans le texte original.
1.3 Stratégie d’entraînement efficace MQ-Det
Entraînement à la modulation basé sur un détecteur de requêtes de langue figée
Étant donné que le grand modèle actuel de détection de pré-entraînement de la requête de texte lui-même a une bonne généralisation, les auteurs pensent qu’il suffit d’apporter de légers ajustements avec des détails visuels sur la base des caractéristiques du texte d’origine.
Dans l’article, il y a aussi une démonstration expérimentale spécifique qu’il est facile d’entraîner un oubli catastrophique après avoir ouvert les paramètres du modèle pré-entraîné d’origine et affiné, mais en perdant la capacité de détection du monde ouvert.
Par conséquent, MQ-Det peut insérer efficacement des informations visuelles dans le détecteur de requête de texte existante sur la base du détecteur pré-entraîné de requête de texte figé et ne moduler que le module GCP inséré par entraînement.
Dans l’article, les auteurs appliquent les techniques de conception structurelle et d’entraînement de MQ-Det aux modèles SOTA actuels GLIP et GroundingDINO respectivement pour vérifier la polyvalence de la méthode.
Stratégie d’entraînement à la prédiction du langage des masques avec condition visuelle
Les auteurs proposent également une stratégie d’entraînement prédictif du langage de masquage conditionné visuellement pour résoudre le problème de la paresse d’apprentissage causée par le gel des modèles pré-entraînés.
Ce que l’on appelle la paresse d’apprentissage signifie que le détecteur a tendance à conserver les caractéristiques de la requête textuelle d’origine pendant le processus d’apprentissage, ignorant ainsi les nouvelles fonctionnalités de requête visuelle.
À cette fin, MQ-Det est utilisé de manière aléatoire pendant l’entraînement[MASK] token remplace le jeton textuel, forçant le modèle à apprendre du côté de la fonctionnalité de requête visuelle, à savoir :
Bien que cette stratégie soit simple, elle est très efficace et, d’après les résultats expérimentaux, cette stratégie a permis d’améliorer considérablement les performances.
1.4 Résultats expérimentaux : Évaluation sans mise au point
Sans réglage fin : MQ-Det propose une stratégie d’évaluation plus pratique : sans réglage fin, par rapport à l’évaluation traditionnelle sans coup qui n’utilise que le texte de la catégorie. Il s’agit d’une détection d’objets à l’aide d’un texte de catégorie, d’exemples d’images ou d’une combinaison des deux, sans aucun réglage fin en aval.
Dans le cadre du paramètre sans réglage fin, MQ-Det sélectionne 5 exemples visuels pour chaque catégorie et combine le texte de la catégorie pour la détection d’objets, alors que d’autres modèles existants ne prennent pas en charge les requêtes visuelles et ne peuvent utiliser que des descriptions en texte brut pour la détection d’objets. Le tableau ci-dessous présente les résultats sur LVIS MiniVal et LVIS v1.0. On peut constater que l’introduction de la requête multimodale a considérablement amélioré la capacité de détection d’objets en monde ouvert.
** **###### △Tableau 1 Performances sans réglage fin de chaque modèle de détection sous l’ensemble de données de référence LVIS
Comme on peut le voir dans le tableau 1, MQ-GLIP-L a amélioré l’AP de plus de 7% sur la base de GLIP-L, et l’effet est très significatif !
1.5 Résultats expérimentaux : Évaluation de quelques clichés
** **####### △Tableau 2 Performances de chaque modèle dans ODinW-35 et de 13 sous-ensembles d’ODinW-13 dans 35 tâches de détection
Les auteurs ont ensuite effectué des expériences complètes dans ODinW-35, une tâche de détection 35 en aval. Comme on peut le voir dans le tableau 2, MQ-Det a non seulement de bonnes performances sans réglage fin, mais a également de bonnes capacités de détection de petits échantillons, ce qui confirme le potentiel des requêtes multimodales. La figure 2 montre également l’amélioration significative de MQ-Det par rapport à GLIP.
** **###### △Figure 2 Comparaison de l’efficacité de l’utilisation des données ; Axe horizontal : le nombre d’échantillons d’entraînement, axe vertical : PA moyen sur OdinW-13
1.6 Perspectives pour la détection d’objets de requête multimodale
En tant que domaine de recherche basé sur des applications pratiques, la détection d’objets accorde une grande attention à l’atterrissage des algorithmes.
Bien que le modèle précédent de détection d’objets de requête en texte brut montre une bonne généralisation, il est difficile de couvrir des informations à grain fin dans la détection du monde ouvert en chinois, et la riche granularité de l’information dans l’image complète parfaitement ce lien.
Jusqu’à présent, nous pouvons constater que le texte est générique mais pas précis, et que l’image est précise mais pas générale, et si nous pouvons combiner efficacement les deux, c’est-à-dire la requête multimodale, cela favorisera la détection d’objets en monde ouvert pour aller plus loin.
MQ-Det a fait le premier pas dans le domaine des requêtes multimodales, et l’amélioration significative de ses performances montre également le grand potentiel de la détection de cibles de requêtes multimodales.
Dans le même temps, l’introduction de descriptions textuelles et d’exemples visuels offre aux utilisateurs plus de choix, ce qui rend la détection d’objets plus flexible et plus conviviale.
Lien d’origine :
Voir l'original
Cette page peut inclure du contenu de tiers fourni à des fins d'information uniquement. Gate ne garantit ni l'exactitude ni la validité de ces contenus, n’endosse pas les opinions exprimées, et ne fournit aucun conseil financier ou professionnel à travers ces informations. Voir la section Avertissement pour plus de détails.
Faites en sorte que les grands modèles regardent les diagrammes plutôt que la dactylographie fonctionne ! Une nouvelle étude de NeurIPS 2023 propose une méthode de requête multimodale, la précision s’améliore de 7,8 %
Source d’origine : Qubits
La capacité des grands modèles à « lire les images » est si forte, pourquoi continuez-vous à chercher les mauvaises choses ?
Par exemple, confondre les chauves-souris qui ne leur ressemblent pas avec les raquettes, ou ne pas reconnaître les poissons rares dans certains jeux de données...
Si la description est ambiguë ou trop partielle, comme « chauve-souris » (chauve-souris ou battement ?). Ou « Cyprinodon diabolis », et l’IA sera confuse.
Cela conduit à l’utilisation de grands modèles pour faire de la détection d’objets, en particulier des tâches de détection d’objets en monde ouvert (scène inconnue), l’effet n’est souvent pas aussi bon que prévu.
Aujourd’hui, un article inclus dans NeurIPS 2023 a enfin résolu ce problème.
Sur l’ensemble de données de détection de référence LVIS, MQ-Det améliore la précision GLIP des grands modèles de détection grand public d’environ 7,8 % en moyenne, et améliore la précision de 13 tâches en aval de petits échantillons de référence de 6,3 % en moyenne.
Comment cela se fait-il exactement ? Jetons un coup d’œil.
Ce qui suit est reproduit de l’auteur de l’article, le blogueur Zhihu @Qinyuanxia :
Table des matières
MQ-Det : Grand modèle de détection d’objets en monde ouvert pour les requêtes multimodales**
Détection d’objets interrogés multimodaux dans la nature
Lien vers le papier :
Adresse de code :**
Une image vaut mille mots : Avec l’essor du pré-entraînement graphique, à l’aide de la sémantique ouverte du texte, la détection d’objets est progressivement entrée dans le stade de la perception du monde ouvert. Pour cette raison, de nombreux grands modèles de détection suivent le modèle de requête textuelle, c’est-à-dire l’utilisation de descriptions textuelles catégorielles pour interroger des cibles potentielles dans les images cibles. Cependant, cette approche se heurte souvent au problème de l’approche « large mais non raffinée ».
Par exemple, (1) la détection d’objets à grain fin (alevins) dans la figure 1 est souvent difficile à décrire les différentes espèces à grain fin avec un texte limité, et (2) l’ambiguïté de la catégorie (« chauve-souris » peut faire référence à la fois à une chauve-souris et à une raquette).
Cependant, les problèmes ci-dessus peuvent être résolus par des exemples d’images, qui fournissent des indices de caractéristiques plus riches sur l’objet cible que le texte, mais en même temps le texte a une forte généralisation.
Par conséquent, la façon de combiner organiquement les deux méthodes de requête est devenue une idée naturelle.
Difficultés à obtenir des capacités de requête multimodale : il existe trois défis dans l’obtention d’un tel modèle avec des requêtes multimodales : (1) Un réglage précis direct avec des exemples d’images limités peut facilement conduire à des oublis catastrophiques ; (2) L’entraînement d’un grand modèle de détection à partir de zéro aura une bonne généralisation mais une consommation énorme, par exemple, l’entraînement GLIP sur une seule carte nécessite 480 jours d’entraînement avec un volume de 30 millions de données.
Détection d’objets de requête multimodale : Sur la base des considérations ci-dessus, l’auteur propose une stratégie simple et efficace de conception et d’entraînement de modèles - MQ-Det.
MQ-Det insère un petit nombre de modules de perception à portes (GCP) pour recevoir l’entrée d’exemples visuels sur la base du grand modèle existant de détection de requête de texte gelé, et conçoit une stratégie d’entraînement à la prédiction du langage de masque de condition visuelle pour obtenir efficacement un détecteur pour les requêtes multimodales hautes performances.
1.2 Architecture de modèle de requête multimodale plug-and-play MQ-Det
** **####### △Figure 1 Schéma d’architecture de la méthode MQ-Det
**####### △Figure 1 Schéma d’architecture de la méthode MQ-Det
Module de perception fermée
Comme le montre la figure 1, l’auteur insère un module de contrôle de contrôle (GCP) couche par couche du côté de l’encodeur de texte du grand modèle existant de détection de requête de texte gelé, et le mode de fonctionnement de GCP peut être représenté succinctement par la formule suivante :
1.3 Stratégie d’entraînement efficace MQ-Det
Entraînement à la modulation basé sur un détecteur de requêtes de langue figée
Étant donné que le grand modèle actuel de détection de pré-entraînement de la requête de texte lui-même a une bonne généralisation, les auteurs pensent qu’il suffit d’apporter de légers ajustements avec des détails visuels sur la base des caractéristiques du texte d’origine.
Dans l’article, il y a aussi une démonstration expérimentale spécifique qu’il est facile d’entraîner un oubli catastrophique après avoir ouvert les paramètres du modèle pré-entraîné d’origine et affiné, mais en perdant la capacité de détection du monde ouvert.
Par conséquent, MQ-Det peut insérer efficacement des informations visuelles dans le détecteur de requête de texte existante sur la base du détecteur pré-entraîné de requête de texte figé et ne moduler que le module GCP inséré par entraînement.
Dans l’article, les auteurs appliquent les techniques de conception structurelle et d’entraînement de MQ-Det aux modèles SOTA actuels GLIP et GroundingDINO respectivement pour vérifier la polyvalence de la méthode.
Stratégie d’entraînement à la prédiction du langage des masques avec condition visuelle
Les auteurs proposent également une stratégie d’entraînement prédictif du langage de masquage conditionné visuellement pour résoudre le problème de la paresse d’apprentissage causée par le gel des modèles pré-entraînés.
Ce que l’on appelle la paresse d’apprentissage signifie que le détecteur a tendance à conserver les caractéristiques de la requête textuelle d’origine pendant le processus d’apprentissage, ignorant ainsi les nouvelles fonctionnalités de requête visuelle.
À cette fin, MQ-Det est utilisé de manière aléatoire pendant l’entraînement[MASK] token remplace le jeton textuel, forçant le modèle à apprendre du côté de la fonctionnalité de requête visuelle, à savoir :
1.4 Résultats expérimentaux : Évaluation sans mise au point
Sans réglage fin : MQ-Det propose une stratégie d’évaluation plus pratique : sans réglage fin, par rapport à l’évaluation traditionnelle sans coup qui n’utilise que le texte de la catégorie. Il s’agit d’une détection d’objets à l’aide d’un texte de catégorie, d’exemples d’images ou d’une combinaison des deux, sans aucun réglage fin en aval.
Dans le cadre du paramètre sans réglage fin, MQ-Det sélectionne 5 exemples visuels pour chaque catégorie et combine le texte de la catégorie pour la détection d’objets, alors que d’autres modèles existants ne prennent pas en charge les requêtes visuelles et ne peuvent utiliser que des descriptions en texte brut pour la détection d’objets. Le tableau ci-dessous présente les résultats sur LVIS MiniVal et LVIS v1.0. On peut constater que l’introduction de la requête multimodale a considérablement amélioré la capacité de détection d’objets en monde ouvert.
**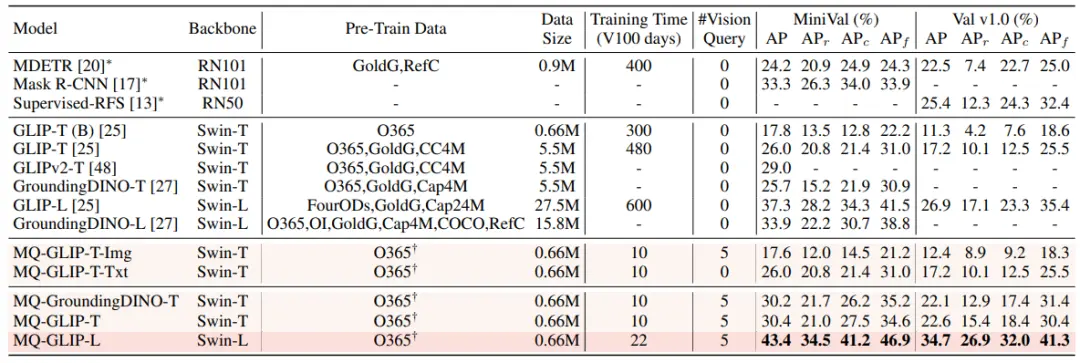 **###### △Tableau 1 Performances sans réglage fin de chaque modèle de détection sous l’ensemble de données de référence LVIS
**###### △Tableau 1 Performances sans réglage fin de chaque modèle de détection sous l’ensemble de données de référence LVIS
Comme on peut le voir dans le tableau 1, MQ-GLIP-L a amélioré l’AP de plus de 7% sur la base de GLIP-L, et l’effet est très significatif !
1.5 Résultats expérimentaux : Évaluation de quelques clichés
**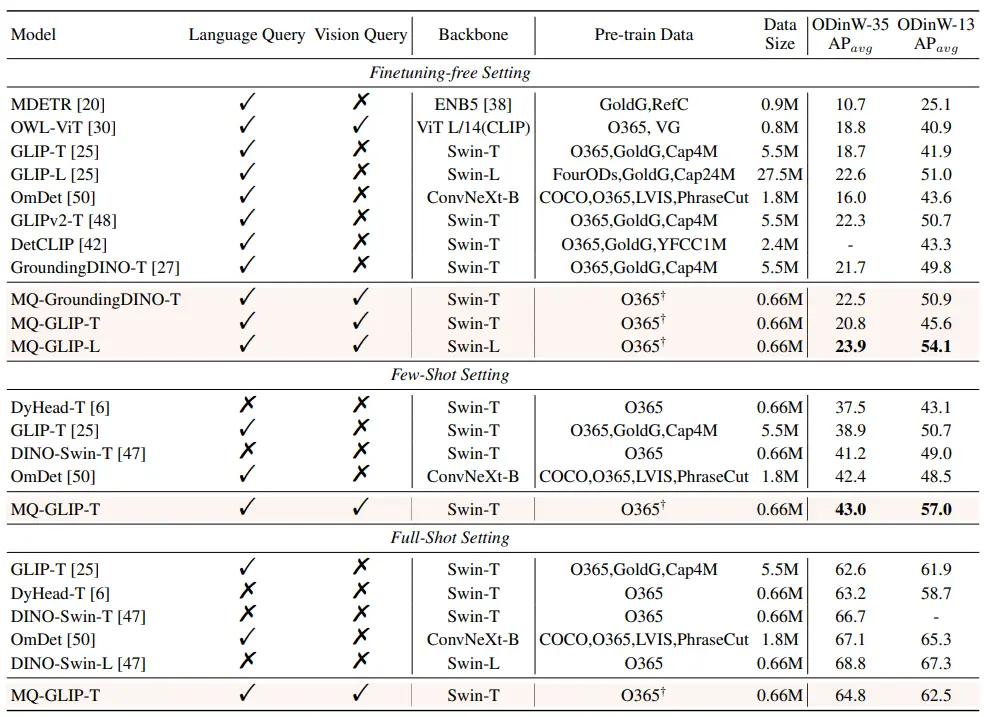 **####### △Tableau 2 Performances de chaque modèle dans ODinW-35 et de 13 sous-ensembles d’ODinW-13 dans 35 tâches de détection
**####### △Tableau 2 Performances de chaque modèle dans ODinW-35 et de 13 sous-ensembles d’ODinW-13 dans 35 tâches de détection
Les auteurs ont ensuite effectué des expériences complètes dans ODinW-35, une tâche de détection 35 en aval. Comme on peut le voir dans le tableau 2, MQ-Det a non seulement de bonnes performances sans réglage fin, mais a également de bonnes capacités de détection de petits échantillons, ce qui confirme le potentiel des requêtes multimodales. La figure 2 montre également l’amélioration significative de MQ-Det par rapport à GLIP.
**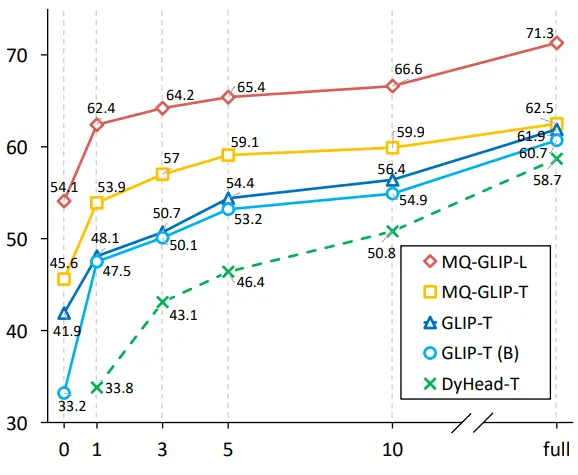 **###### △Figure 2 Comparaison de l’efficacité de l’utilisation des données ; Axe horizontal : le nombre d’échantillons d’entraînement, axe vertical : PA moyen sur OdinW-13
**###### △Figure 2 Comparaison de l’efficacité de l’utilisation des données ; Axe horizontal : le nombre d’échantillons d’entraînement, axe vertical : PA moyen sur OdinW-13
1.6 Perspectives pour la détection d’objets de requête multimodale
En tant que domaine de recherche basé sur des applications pratiques, la détection d’objets accorde une grande attention à l’atterrissage des algorithmes.
Bien que le modèle précédent de détection d’objets de requête en texte brut montre une bonne généralisation, il est difficile de couvrir des informations à grain fin dans la détection du monde ouvert en chinois, et la riche granularité de l’information dans l’image complète parfaitement ce lien.
Jusqu’à présent, nous pouvons constater que le texte est générique mais pas précis, et que l’image est précise mais pas générale, et si nous pouvons combiner efficacement les deux, c’est-à-dire la requête multimodale, cela favorisera la détection d’objets en monde ouvert pour aller plus loin.
MQ-Det a fait le premier pas dans le domaine des requêtes multimodales, et l’amélioration significative de ses performances montre également le grand potentiel de la détection de cibles de requêtes multimodales.
Dans le même temps, l’introduction de descriptions textuelles et d’exemples visuels offre aux utilisateurs plus de choix, ce qui rend la détection d’objets plus flexible et plus conviviale.
Lien d’origine :