Le modèle à 7 milliards de paramètres qui a nécessité 500 dollars pour être « réglé » a vaincu le modèle à 70 milliards de paramètres Llama 2 !
Et l’ordinateur portable peut fonctionner facilement, et l’effet est comparable à ChatGPT.
Important : Gratuit, pas d’argent.
Le modèle open-source Zephyr-7B créé par l’équipe HuggingFace H4, fou de requin.
Son modèle sous-jacent est un grand modèle open-source Mistral-7B, qui a explosé il y a quelque temps et a été construit par Mistral AI, connu sous le nom de « European OpenAI ».
Vous savez, moins de 2 semaines après la sortie du Mistral-7B, diverses versions affinées sont apparues les unes après les autres, et il y a beaucoup de style « alpaga » qui est rapidement apparu lors de la sortie de Llama.
La clé de la capacité de Zephyr à se démarquer parmi les variantes réside dans le fait que l’équipe a affiné le modèle sur un ensemble de données public à l’aide de l’optimisation des préférences directes (DPO) en plus de Mistral.
L’équipe a également constaté que la suppression de l’alignement intégré de l’ensemble de données pourrait améliorer davantage les performances de MT Bench. Le Zephyr-7B-alpha original avait un score MT-Bench moyen de 7,09, surpassant le Llama2-70B-Chat.
** **###### △MT-Bench est un test de référence pour évaluer la capacité du modèle à gérer plusieurs tours de dialogue, et l’ensemble de questions couvre 8 catégories telles que l’écriture, le jeu de rôle et l’extraction.
Le fait est qu’il a ensuite été mis à niveau !
L’équipe H4 a lancé la deuxième génération de Zephyr-7B-beta. Ils ont ajouté qu’ils avaient exploré l’idée d’extraire l’alignement de GPT-4, Claude 2, puis de l’injecter dans de petits modèles, en développant une méthode d’utilisation de l’optimisation des préférences directes de distillation (dDPO) pour les petits modèles.
Dans la deuxième génération de Zephyr, le score moyen MT-Bench est passé à 7,34.
Sur Alpaca, Zephyr a un taux de victoire de 90,6%, ce qui est mieux que ChatGPT (3,5) :
Les internautes qui se sont précipités sur Zephyr ont fait l’unanimité, et l’équipe de lmsys a également montré le score Elo de Zephyr-7b-beta, qui a grimpé très haut 🔥 :
Le classement interne de l’Arène a dépassé les modèles 13B.
Certaines personnes ont même dit :
Voir l’approche DPO bien performer sur le terrain est probablement la chose la plus excitante dans le développement de grands modèles de langage cette année.
De plus en plus d’internautes ont commencé à tester l’effet de Zephyr, et les résultats sont étonnamment bons.
Le mot Mistral signifie vent sec, froid et fort en français, tandis que Zephyr signifie vent d’ouest doux et agréable.
Il ne fait aucun doute qu’il y a un zoo de l’autre côté de Llama, et il ne fait aucun doute qu’il y a un bureau météorologique de ce côté-ci.
Le meilleur modèle 7B change à nouveau de mains
Commençons par la configuration informatique requise pour exécuter Zephyr. Les internautes ont déclaré que « les pantalons thaïlandais sont épicés » après le test ! , l’ordinateur portable (Apple M1 Pro) suffit, « le résultat est très bon ».
En termes d’efficacité, l’équipe de Llama Index (anciennement connu sous le nom de GPT Index) l’a également testé.
Il s’avère que Zephyr est actuellement le seul modèle 7B open-source qui fonctionne bien sur les tâches RAG/agentiques de haut niveau.
Les données montrent également que l’effet de la tâche RAG avancée de Zephyr peut rivaliser avec GPT-3.5 et Claude 2.
Ils ont ajouté que Zephyr fonctionne non seulement bien sur RAG, mais aussi dans le routage, la planification des requêtes, la récupération d’instructions SQL complexes et l’extraction de données structurées.
Les officiels ont également donné les résultats des tests, et sur MT-Bench, Zephyr-7B-beta a de solides performances par rapport aux modèles plus grands tels que Llama2-Chat-70B.
Mais sur des tâches plus complexes telles que le codage et les mathématiques, Zephyr-7B-beta est à la traîne par rapport aux modèles propriétaires et nécessite plus de recherches pour combler l’écart.
Abandonnez l’apprentissage par renforcement
Alors que tout le monde teste les effets de Zephyr, les développeurs disent que la chose la plus intéressante n’est pas les métriques, mais la façon dont le modèle est entraîné.
Les faits saillants sont résumés ci-dessous :
Peaufinez le meilleur petit modèle pré-entraîné open-source : Mistral 7B
Utilisation de jeux de données de préférences à grande échelle : UltraFeedback
Utiliser l’optimisation des préférences directes (DPO) au lieu de l’apprentissage par renforcement
De manière inattendue, le surajustement du jeu de données de préférences donne de meilleurs résultats
D’une manière générale, comme mentionné au début, la principale raison pour laquelle Zephyr est capable de surpasser le 70B Llama 2 est due à l’utilisation d’une méthode de réglage fin spéciale.
Contrairement à l’approche traditionnelle de l’apprentissage par renforcement PPO, l’équipe de recherche a utilisé une collaboration récente entre l’Université de Stanford et CZ Biohub pour proposer une approche DPO.
Selon les chercheurs :
DPO est beaucoup plus stable que le PPO.
En termes simples, le DPO peut être expliqué comme suit :
Afin de rendre le résultat du modèle plus conforme aux préférences humaines, l’approche traditionnelle a consisté à affiner le modèle cible avec un modèle de récompense. Si le résultat est bon, vous serez récompensé, et si le résultat est mauvais, vous ne serez pas récompensé.
L’approche DPO, quant à elle, contourne la fonction de récompense de modélisation et équivaut à optimiser le modèle directement sur les données de préférence.
En général, le DPO résout le problème de la formation par apprentissage par renforcement difficile et coûteuse en raison du retour d’information humain.
En ce qui concerne spécifiquement l’entraînement de Zephyr, l’équipe de recherche a d’abord affiné Zephyr-7B-alpha sur une variante simplifiée de l’ensemble de données UltraChat, qui contient 1,6 million de conversations générées par ChatGPT (environ 200 000 restantes).
(La raison de la rationalisation était que l’équipe a constaté que Zephyr était parfois mal mis en casse, comme « Salut. Comment allez-vous ? Parfois, la réponse commence par « Je n’ai pas de X personnel ». )
Plus tard, ils ont aligné le modèle sur l’ensemble de données openbmb/UltraFeedback accessible au public à l’aide de la méthode DPO Trainer de TRL.
L’ensemble de données contient 64 000 paires d’instructions et de réponses provenant de différents modèles. Chaque réponse est classée par GPT-4 en fonction de critères tels que l’utilité et un score à partir duquel une préférence d’IA est dérivée.
Une découverte intéressante est que lors de l’utilisation de la méthode DPO, l’effet est en fait meilleur après le surapprentissage à mesure que le temps d’entraînement augmente. Les chercheurs pensent que cela est similaire au surapprentissage dans SFT.
Il convient de mentionner que l’équipe de recherche a également introduit que la mise au point du modèle avec cette méthode ne coûte que 500 $, ce qui correspond à 8 heures de fonctionnement sur 16 A100.
Lors de la mise à niveau de Zephyr en version bêta, l’équipe a expliqué son approche.
Ils ont pensé au réglage fin supervisé par distillation (dSFT) utilisé dans les grands modèles, mais avec cette approche, le modèle était mal aligné et ne produisait pas de sortie qui correspondait à l’intention de l’utilisateur.
L’équipe a donc essayé d’utiliser les données de préférence de AI Feedback (AIF) pour classer les résultats avec un « modèle d’enseignant » afin de former un ensemble de données, puis d’appliquer l’optimisation directe des préférences de distillation (dDPO) pour entraîner un modèle qui s’aligne sur l’intention de l’utilisateur sans aucun échantillonnage supplémentaire lors de l’ajustement fin.
Les chercheurs ont également testé l’effet lorsque la SFT n’était pas utilisée, et les résultats ont entraîné une réduction significative des performances, indiquant que l’étape dSFT est critique.
À l’heure actuelle, en plus du modèle open source et commercial, il y a aussi une démo à essayer, afin que nous puissions commencer et l’expérimenter simplement.
Expérience de démonstration
Tout d’abord, j’ai dû sortir de la question « handicapé mental » pour passer un test.
À la question « Maman et papa ne m’emmènent pas quand ils se marient », la réponse globale de Zéphyr est plus précise.
ChatGPT ne peut pas battre cette question.
Dans le test, nous avons également constaté que Zephyr est également au courant d’événements récents tels que la sortie de GPT-4 par OpenAI :
Ceci est en fait lié à son modèle sous-jacent, bien que le responsable de Mistral n’ait pas précisé la date limite pour les données d’entraînement.
Mais certains internautes l’ont déjà testé, et il le sait aussi en mars de cette année.
En revanche, les données de pré-entraînement de Llama 2 datent de septembre 2022, et seules certaines données affinées sont jusqu’en juin 2023.
De plus, Zephyr est très réactif, ce qui vous permet d’écrire du code et d’inventer des histoires. :
Il convient de mentionner que Zephyr est meilleur pour répondre aux questions en anglais, et a également un problème commun avec le modèle « hallucination ».
Les chercheurs ont également mentionné des hallucinations, et une petite ligne de texte a été marquée sous la zone de saisie indiquant que le contenu généré par le modèle peut être inexact ou incorrect.
Le fait est que Zephyr n’utilise pas de méthodes telles que l’apprentissage par renforcement avec des commentaires humains pour s’aligner sur les préférences humaines, ni le filtrage des réponses de ChatGPT.
Choisissez toujours l’une des pattes de poisson et d’ours emmm.
Zephyr a été capable de le faire avec seulement 70 milliards de paramètres, ce qui a surpris Andriy Burkov, auteur de « The 100-Page Machine Learning Book », et a même déclaré :
Zephyr-7B bat Llama 2-70B avec un modèle de base de Mistral-7B avec une fenêtre contextuelle de 8k tokens, qui a théoriquement une portée d’attention allant jusqu’à 128K tokens.
Et si le Zephyr était un modèle 70B ? Surpassera-t-il GPT-4 ? Cela semble probable.
Si vous êtes intéressé par Zephyr-7B, vous pouvez l’essayer sur hugggingface.
Liens vers les articles :
Liens de référence :
[1]
[2]
[3]
[4]
[5]
Voir l'original
Cette page peut inclure du contenu de tiers fourni à des fins d'information uniquement. Gate ne garantit ni l'exactitude ni la validité de ces contenus, n’endosse pas les opinions exprimées, et ne fournit aucun conseil financier ou professionnel à travers ces informations. Voir la section Avertissement pour plus de détails.
Le meilleur modèle 7B change à nouveau de mains ! Battez 70 milliards de LLaMA2, et les ordinateurs Apple pourront fonctionner|open source et gratuit
Source d’origine : qubits
Le modèle à 7 milliards de paramètres qui a nécessité 500 dollars pour être « réglé » a vaincu le modèle à 70 milliards de paramètres Llama 2 !
Et l’ordinateur portable peut fonctionner facilement, et l’effet est comparable à ChatGPT.
Important : Gratuit, pas d’argent.
Le modèle open-source Zephyr-7B créé par l’équipe HuggingFace H4, fou de requin.
La clé de la capacité de Zephyr à se démarquer parmi les variantes réside dans le fait que l’équipe a affiné le modèle sur un ensemble de données public à l’aide de l’optimisation des préférences directes (DPO) en plus de Mistral.
L’équipe a également constaté que la suppression de l’alignement intégré de l’ensemble de données pourrait améliorer davantage les performances de MT Bench. Le Zephyr-7B-alpha original avait un score MT-Bench moyen de 7,09, surpassant le Llama2-70B-Chat.
**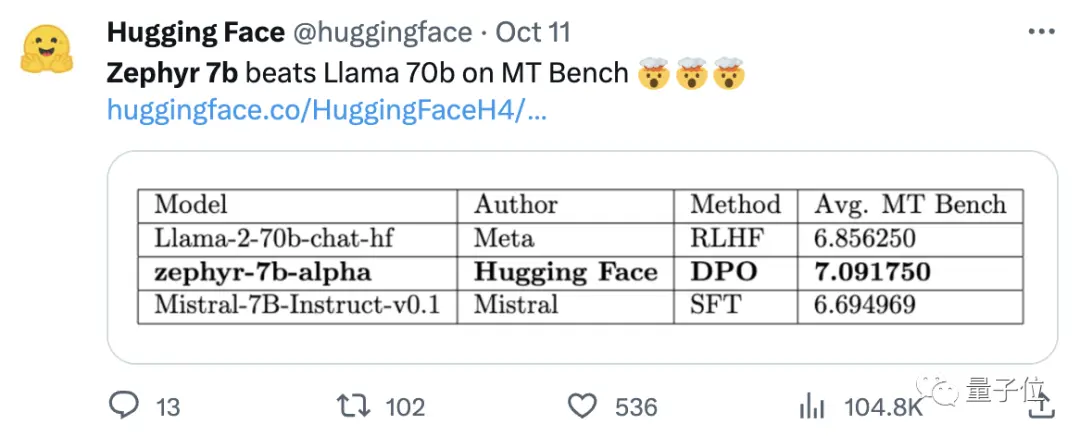 **###### △MT-Bench est un test de référence pour évaluer la capacité du modèle à gérer plusieurs tours de dialogue, et l’ensemble de questions couvre 8 catégories telles que l’écriture, le jeu de rôle et l’extraction.
**###### △MT-Bench est un test de référence pour évaluer la capacité du modèle à gérer plusieurs tours de dialogue, et l’ensemble de questions couvre 8 catégories telles que l’écriture, le jeu de rôle et l’extraction.
Le fait est qu’il a ensuite été mis à niveau !
L’équipe H4 a lancé la deuxième génération de Zephyr-7B-beta. Ils ont ajouté qu’ils avaient exploré l’idée d’extraire l’alignement de GPT-4, Claude 2, puis de l’injecter dans de petits modèles, en développant une méthode d’utilisation de l’optimisation des préférences directes de distillation (dDPO) pour les petits modèles.
Dans la deuxième génération de Zephyr, le score moyen MT-Bench est passé à 7,34.
Le mot Mistral signifie vent sec, froid et fort en français, tandis que Zephyr signifie vent d’ouest doux et agréable.
Il ne fait aucun doute qu’il y a un zoo de l’autre côté de Llama, et il ne fait aucun doute qu’il y a un bureau météorologique de ce côté-ci.
Le meilleur modèle 7B change à nouveau de mains
Commençons par la configuration informatique requise pour exécuter Zephyr. Les internautes ont déclaré que « les pantalons thaïlandais sont épicés » après le test ! , l’ordinateur portable (Apple M1 Pro) suffit, « le résultat est très bon ».
Les données montrent également que l’effet de la tâche RAG avancée de Zephyr peut rivaliser avec GPT-3.5 et Claude 2.
Ils ont ajouté que Zephyr fonctionne non seulement bien sur RAG, mais aussi dans le routage, la planification des requêtes, la récupération d’instructions SQL complexes et l’extraction de données structurées.
Abandonnez l’apprentissage par renforcement
Alors que tout le monde teste les effets de Zephyr, les développeurs disent que la chose la plus intéressante n’est pas les métriques, mais la façon dont le modèle est entraîné.
Les faits saillants sont résumés ci-dessous :
D’une manière générale, comme mentionné au début, la principale raison pour laquelle Zephyr est capable de surpasser le 70B Llama 2 est due à l’utilisation d’une méthode de réglage fin spéciale.
Contrairement à l’approche traditionnelle de l’apprentissage par renforcement PPO, l’équipe de recherche a utilisé une collaboration récente entre l’Université de Stanford et CZ Biohub pour proposer une approche DPO.
En termes simples, le DPO peut être expliqué comme suit :
Afin de rendre le résultat du modèle plus conforme aux préférences humaines, l’approche traditionnelle a consisté à affiner le modèle cible avec un modèle de récompense. Si le résultat est bon, vous serez récompensé, et si le résultat est mauvais, vous ne serez pas récompensé.
L’approche DPO, quant à elle, contourne la fonction de récompense de modélisation et équivaut à optimiser le modèle directement sur les données de préférence.
En général, le DPO résout le problème de la formation par apprentissage par renforcement difficile et coûteuse en raison du retour d’information humain.
En ce qui concerne spécifiquement l’entraînement de Zephyr, l’équipe de recherche a d’abord affiné Zephyr-7B-alpha sur une variante simplifiée de l’ensemble de données UltraChat, qui contient 1,6 million de conversations générées par ChatGPT (environ 200 000 restantes).
(La raison de la rationalisation était que l’équipe a constaté que Zephyr était parfois mal mis en casse, comme « Salut. Comment allez-vous ? Parfois, la réponse commence par « Je n’ai pas de X personnel ». )
Plus tard, ils ont aligné le modèle sur l’ensemble de données openbmb/UltraFeedback accessible au public à l’aide de la méthode DPO Trainer de TRL.
L’ensemble de données contient 64 000 paires d’instructions et de réponses provenant de différents modèles. Chaque réponse est classée par GPT-4 en fonction de critères tels que l’utilité et un score à partir duquel une préférence d’IA est dérivée.
Une découverte intéressante est que lors de l’utilisation de la méthode DPO, l’effet est en fait meilleur après le surapprentissage à mesure que le temps d’entraînement augmente. Les chercheurs pensent que cela est similaire au surapprentissage dans SFT.
Ils ont pensé au réglage fin supervisé par distillation (dSFT) utilisé dans les grands modèles, mais avec cette approche, le modèle était mal aligné et ne produisait pas de sortie qui correspondait à l’intention de l’utilisateur.
Les chercheurs ont également testé l’effet lorsque la SFT n’était pas utilisée, et les résultats ont entraîné une réduction significative des performances, indiquant que l’étape dSFT est critique.
Expérience de démonstration
Tout d’abord, j’ai dû sortir de la question « handicapé mental » pour passer un test.
À la question « Maman et papa ne m’emmènent pas quand ils se marient », la réponse globale de Zéphyr est plus précise.
Mais certains internautes l’ont déjà testé, et il le sait aussi en mars de cette année.
De plus, Zephyr est très réactif, ce qui vous permet d’écrire du code et d’inventer des histoires. :
Les chercheurs ont également mentionné des hallucinations, et une petite ligne de texte a été marquée sous la zone de saisie indiquant que le contenu généré par le modèle peut être inexact ou incorrect.
Choisissez toujours l’une des pattes de poisson et d’ours emmm.
Zephyr a été capable de le faire avec seulement 70 milliards de paramètres, ce qui a surpris Andriy Burkov, auteur de « The 100-Page Machine Learning Book », et a même déclaré :
Liens vers les articles :
Liens de référence :
[1]
[2]
[3]
[4]
[5]