Makalah Model Bahasa Besar pertama yang dipimpin oleh pemenang Turing Award Yao Qizhi telah hadir!
Segera setelah saya memulai, saya mengarahkan ke arah "membuat model besar berpikir seperti manusia"—
Model besar tidak hanya perlu melakukan penalaran langkah demi langkah, tetapi mereka juga perlu belajar "langkah demi langkah" dan mengingat semua proses yang benar dalam proses penalaran.
Secara khusus, makalah baru ini mengusulkan metode baru yang disebut Penalaran Kumulatif, yang secara signifikan meningkatkan kemampuan model besar untuk terlibat dalam penalaran yang kompleks.
Perlu Anda ketahui bahwa model besar didasarkan pada rantai pemikiran, dll, dan dapat digunakan untuk penalaran masalah, namun ketika dihadapkan pada masalah yang memerlukan "beberapa putaran", masih mudah untuk melakukan kesalahan.
Atas dasar inilah penalaran kumulatif menambahkan “verifikator” untuk menilai benar dan salah secara real time. Kerangka pemikiran model ini juga telah berubah dari rantai dan pohon menjadi “grafik asiklik terarah” yang lebih kompleks.
Dengan cara ini, model besar tidak hanya memiliki gagasan yang lebih jelas untuk memecahkan masalah, namun juga mengembangkan keterampilan "bermain kartu":
Pada soal matematika seperti aljabar dan teori bilangan geometri, akurasi relatif model besar meningkat 42%; saat memainkan 24 poin, tingkat keberhasilan melonjak hingga 98%.
Menurut Institute of Cross-Information di Universitas Tsinghua, penulis pertama Zhang Yifan menjelaskan titik awal makalah ini:
Kahneman percaya bahwa proses kognitif manusia mencakup dua sistem: "Sistem 1" cepat, naluriah dan emosional, dan "Sistem 2" lambat, bijaksana dan logis.
Saat ini, performa model bahasa besar mendekati "Sistem 1", yang mungkin menjadi alasan mengapa model tersebut tidak bagus dalam menangani tugas-tugas kompleks.
Penalaran kumulatif yang dirancang dari perspektif ini lebih baik daripada Chain of Thought (CoT) dan Thinking Tree (ToT).
Jadi, seperti apa sebenarnya pendekatan baru ini? Mari kita lihat bersama.
Terobosan rantai pemikiran & "kemacetan" pohon
Inti dari penalaran kumulatif terletak pada perbaikan “bentuk” proses berpikir model besar.
Secara khusus, metode ini menggunakan 3 model bahasa besar:
Pengusul: Terus-menerus mengajukan proposisi baru, yaitu menyarankan apa langkah selanjutnya berdasarkan konteks pemikiran saat ini.
Verifikator: Memverifikasi keakuratan proposisi pengusul dan menambahkannya ke dalam konteks pemikiran jika benar.
Reporter: Menentukan apakah solusi akhir telah diperoleh dan apakah proses penalaran akan diakhiri.
Selama proses penalaran, “pengusul” terlebih dahulu memberikan proposal, “verifikator” bertanggung jawab untuk evaluasi, dan “pelapor” memutuskan apakah akan menyelesaikan jawaban dan menghentikan proses berpikir.
** ****△**Contoh penalaran CR
Ini seperti tiga jenis peran dalam proyek tim: anggota tim melakukan brainstorming berbagai ide terlebih dahulu, instruktur "memeriksa" untuk melihat ide mana yang layak, dan pemimpin tim memutuskan kapan harus menyelesaikan proyek.
**Jadi, bagaimana sebenarnya pendekatan ini mengubah “bentuk” pemikiran model besar? **
Untuk memahami hal ini, kita harus memulai dengan "Rantai Pemikiran, CoT" (Chain of Thought, CoT), "pencetus" metode peningkatan pemikiran model besar.
Metode ini diusulkan oleh ilmuwan OpenAI Jason Wei dan lainnya pada Januari 2022. Intinya adalah menambahkan teks "penalaran langkah demi langkah" ke masukan dalam kumpulan data untuk merangsang kemampuan berpikir model besar.
** ****△**Dipilih dari kumpulan data GSM8K
Berdasarkan prinsip rantai pemikiran, Google juga segera menindaklanjuti dengan "rantai pemikiran versi PLUS", yaitu CoT-SC, yang utamanya melakukan beberapa proses rantai pemikiran dan melakukan pemungutan suara terbanyak atas jawaban untuk memilih yang terbaik. .Jawaban terbaik dapat lebih meningkatkan keakuratan penalaran.
Tapi Thinking Chain dan CoT-SC mengabaikan satu masalah: ada lebih dari satu solusi untuk pertanyaan tersebut, terutama ketika manusia memecahkan masalah tersebut.
Oleh karena itu, penelitian baru yang disebut Pohon Pemikiran (ToT) muncul kemudian.
Ini adalah skema pencarian seperti pohon yang memungkinkan model untuk mencoba berbagai ide penalaran yang berbeda, mengevaluasi diri, memilih tindakan berikutnya, dan melakukan kemunduran jika perlu.
Terlihat dari metodenya bahwa pohon pemikiran lebih jauh dari rantai pemikiran, sehingga membuat pemikiran model besar menjadi "lebih aktif".
Inilah sebabnya ketika bermain 24 poin, tingkat keberhasilan GPT-4 dari bonus Rantai Pemikiran hanya 4%**, namun tingkat keberhasilan Pohon Pemikiran melonjak hingga 74%.
TAPI, terlepas dari rantai pemikiran, CoT-SC atau pohon pemikiran, memiliki batasan umum:
Tak satu pun dari mereka menyiapkan lokasi penyimpanan untuk hasil antara dari proses berpikir.
Memang tidak semua proses berpikir bisa dirangkai menjadi rantai atau pohon, cara berpikir manusia seringkali lebih rumit.
Kerangka penalaran kumulatif baru ini menerobos titik desain ini——
Proses berpikir keseluruhan dari model besar tidak harus berupa rantai atau pohon, namun bisa juga berupa Grafik Asiklik Terarah (DAG)! (Yah, baunya seperti sinapsis)
** ****△**Tepi pada grafik memiliki arah, dan tidak ada jalur melingkar; setiap tepi yang diarahkan adalah langkah derivasi
Artinya, ia dapat menyimpan semua hasil inferensi yang benar secara historis dalam memori untuk dieksplorasi di cabang pencarian saat ini. (Sebaliknya, pohon berpikir tidak menyimpan informasi dari cabang lain)
Namun penalaran kumulatif juga dapat dengan mudah dialihkan dengan rantai pemikiran - selama "penguji" dihilangkan, ini adalah model rantai pemikiran standar.
Penalaran kumulatif yang dirancang berdasarkan metode ini telah mencapai hasil yang baik dalam berbagai metode.
Pandai mengerjakan matematika dan penalaran logis
Para peneliti memilih wiki FOLIO dan AutoTNLI, permainan 24 poin, dan kumpulan data MATEMATIKA untuk "menguji" penalaran kumulatif.
Pengusul, pemverifikasi, dan pelapor menggunakan model bahasa besar yang sama di setiap eksperimen, dengan pengaturan berbeda untuk peran mereka.
Model dasar yang digunakan di sini untuk eksperimen meliputi GPT-3.5-turbo, GPT-4, LLaMA-13B, dan LLaMA-65B.
Perlu disebutkan bahwa idealnya, model harus dilatih sebelumnya secara khusus menggunakan data tugas derivasi yang relevan, dan "verifikator" juga harus menambahkan pembuktian matematika formal, modul pemecah logika proposisional, dll.
1. Kemampuan penalaran logis
FOLIO adalah kumpulan data penalaran logis tingkat pertama, dan label pertanyaan dapat berupa "benar", "Salah", dan "Tidak Diketahui"; AutoTNLI adalah kumpulan data penalaran logis tingkat tinggi.
Pada kumpulan data wiki FOLIO, dibandingkan dengan metode hasil keluaran langsung (Direct), rantai pemikiran (CoT), dan rantai pemikiran lanjutan (CoT-SC), kinerja penalaran kumulatif (CR) selalu yang terbaik.
Setelah menghapus contoh bermasalah (seperti jawaban yang salah) dari kumpulan data, akurasi inferensi GPT-4 menggunakan metode CR mencapai 98,04%, dengan tingkat kesalahan minimum 1,96%.
Mari kita lihat kinerja kumpulan data AutoTNLI:
Dibandingkan dengan metode CoT, CR secara signifikan meningkatkan kinerja LLaMA-13B dan LLaMA-65B.
Pada model LLaMA-65B, peningkatan CR dibandingkan CoT mencapai 9,3%.
### 2. Kemampuan memainkan permainan 24 poin
Makalah ToT asli menggunakan permainan 24 poin, jadi peneliti di sini menggunakan kumpulan data ini untuk membandingkan CR dan ToT.
ToT menggunakan pohon pencarian dengan lebar dan kedalaman tetap, dan CR memungkinkan model besar menentukan kedalaman pencarian secara mandiri.
Para peneliti menemukan dalam percobaan bahwa dalam konteks 24 poin, algoritma CR dan algoritma ToT sangat mirip. Perbedaannya adalah algoritme dalam CR menghasilkan paling banyak satu status baru per iterasi, sedangkan ToT menghasilkan banyak kandidat status di setiap iterasi, serta memfilter dan mempertahankan sebagian status.
Dalam istilah awam, ToT tidak memiliki "verifikator" yang disebutkan di atas seperti CR dan tidak dapat menilai apakah status (a, b, c) benar atau salah. Oleh karena itu, ToT akan mengeksplorasi lebih banyak status yang tidak valid daripada CR.
Pada akhirnya, akurasi metode CR bahkan bisa mencapai 98% (ToT 74%), dan rata-rata jumlah status yang diakses jauh lebih sedikit dibandingkan ToT.
Dengan kata lain, CR tidak hanya memiliki tingkat akurasi pencarian yang lebih tinggi, tetapi juga memiliki efisiensi pencarian yang lebih tinggi.
### 3. Kemampuan matematika
Kumpulan data MATEMATIKA berisi sejumlah besar soal penalaran matematika, termasuk aljabar, geometri, teori bilangan, dll. Tingkat kesulitan soal dibagi menjadi lima tingkatan.
Dengan menggunakan metode CR, model dapat menguraikan pertanyaan menjadi sub-pertanyaan yang dapat diselesaikan selangkah demi selangkah, dan bertanya serta menjawab pertanyaan hingga dihasilkan jawabannya.
Hasil eksperimen menunjukkan bahwa dalam dua pengaturan eksperimen yang berbeda, tingkat akurasi CR melebihi metode yang ada saat ini, dengan tingkat akurasi keseluruhan hingga 58%, dan peningkatan akurasi relatif sebesar 42% pada soal Level 5. Mengunduh SOTA baru di bawah model GPT-4.
Penelitian dipimpin oleh Yao Qizhi dan Yuan Yang dari Universitas Tsinghua
Makalah ini berasal dari kelompok riset AI untuk Matematika yang dipimpin oleh Yao Qizhi dan Yuan Yang dari Institut Informasi Interdisipliner Tsinghua.
Rekan penulis pertama makalah ini adalah Zhang Yifan dan Yang Jingqin, mahasiswa doktoral tahun 2021 di Institut Informasi Interdisipliner;
Instruktur dan rekan penulis adalah Asisten Profesor Yuan Yang dan Akademisi Yao Qizhi.
Zhang Yifan
Zhang Yifan lulus dari Yuanpei College of Peking University pada tahun 2021. Saat ini ia belajar di bawah bimbingan Asisten Profesor Yuan Yang. Arahan penelitian utamanya adalah teori dan algoritma model dasar (model bahasa besar), pembelajaran dengan pengawasan mandiri, dan kecerdasan buatan yang tepercaya.
Yang Jingqin
Yang Jingqin menerima gelar sarjananya dari Institut Lintas Informasi di Universitas Tsinghua pada tahun 2021 dan saat ini sedang belajar untuk gelar doktoralnya di bawah bimbingan Asisten Profesor Yuan Yang. Arahan penelitian utama meliputi model bahasa besar, pembelajaran mandiri, perawatan medis cerdas, dll.
Yuan Yang
Yuan Yang adalah asisten profesor di Sekolah Informasi Interdisipliner, Universitas Tsinghua. Lulus dari Departemen Ilmu Komputer Universitas Peking pada tahun 2012; menerima gelar PhD di bidang Ilmu Komputer dari Universitas Cornell di Amerika Serikat pada tahun 2018; dari tahun 2018 hingga 2019, ia bekerja sebagai rekan pascadoktoral di School of Big Data Science di Massachusetts Institute Teknologi.
Arahan penelitian utamanya adalah perawatan medis cerdas, teori AI dasar, teori kategori terapan, dll.
Yao Qizhi
Yao Qizhi adalah akademisi Akademi Ilmu Pengetahuan Tiongkok dan dekan Institut Informasi Interdisipliner di Universitas Tsinghua. Ia juga merupakan sarjana Asia pertama yang memenangkan Penghargaan Turing sejak didirikan, dan satu-satunya ilmuwan komputer Tiongkok yang memenangkan penghargaan ini. sejauh ini.
Profesor Yao Qizhi mengundurkan diri dari Princeton sebagai profesor tetap pada tahun 2004 dan kembali ke Tsinghua untuk mengajar; pada tahun 2005, ia mendirikan "Kelas Yao", kelas eksperimen ilmu komputer untuk mahasiswa sarjana Tsinghua; pada tahun 2011, ia mendirikan "Pusat Informasi Kuantum Tsinghua " dan "Institut Penelitian Informasi Interdisipliner"; pada tahun 2019 Pada tahun 2008, ia mendirikan kelas kecerdasan buatan untuk mahasiswa sarjana Tsinghua, yang disebut sebagai "Kelas Cerdas".
Saat ini, Institut Informasi Interdisipliner Universitas Tsinghua yang dipimpinnya telah lama terkenal, Kelas Yao dan Zhiban sama-sama berafiliasi dengan Institut Informasi Interdisipliner.
Minat penelitian Profesor Yao Qizhi meliputi algoritma, kriptografi, komputasi kuantum, dll. Ia adalah pionir dan otoritas internasional di bidang ini. Baru-baru ini, dia muncul di Konferensi Kecerdasan Buatan Dunia 2023. Institut Penelitian Qizhi Shanghai yang dipimpinnya saat ini sedang mempelajari "kecerdasan buatan umum yang diwujudkan".
Tautan kertas:
Lihat Asli
Halaman ini mungkin berisi konten pihak ketiga, yang disediakan untuk tujuan informasi saja (bukan pernyataan/jaminan) dan tidak boleh dianggap sebagai dukungan terhadap pandangannya oleh Gate, atau sebagai nasihat keuangan atau profesional. Lihat Penafian untuk detailnya.
Yao Qizhi memimpin dalam mengusulkan kerangka "berpikir" model besar! Keakuratan penalaran logis 98%, dan cara berpikirnya lebih mirip manusia.
Sumber: Qubit
Makalah Model Bahasa Besar pertama yang dipimpin oleh pemenang Turing Award Yao Qizhi telah hadir!
Segera setelah saya memulai, saya mengarahkan ke arah "membuat model besar berpikir seperti manusia"—
Model besar tidak hanya perlu melakukan penalaran langkah demi langkah, tetapi mereka juga perlu belajar "langkah demi langkah" dan mengingat semua proses yang benar dalam proses penalaran.
Secara khusus, makalah baru ini mengusulkan metode baru yang disebut Penalaran Kumulatif, yang secara signifikan meningkatkan kemampuan model besar untuk terlibat dalam penalaran yang kompleks.
Atas dasar inilah penalaran kumulatif menambahkan “verifikator” untuk menilai benar dan salah secara real time. Kerangka pemikiran model ini juga telah berubah dari rantai dan pohon menjadi “grafik asiklik terarah” yang lebih kompleks.
Dengan cara ini, model besar tidak hanya memiliki gagasan yang lebih jelas untuk memecahkan masalah, namun juga mengembangkan keterampilan "bermain kartu":
Pada soal matematika seperti aljabar dan teori bilangan geometri, akurasi relatif model besar meningkat 42%; saat memainkan 24 poin, tingkat keberhasilan melonjak hingga 98%.
Penalaran kumulatif yang dirancang dari perspektif ini lebih baik daripada Chain of Thought (CoT) dan Thinking Tree (ToT).
Jadi, seperti apa sebenarnya pendekatan baru ini? Mari kita lihat bersama.
Terobosan rantai pemikiran & "kemacetan" pohon
Inti dari penalaran kumulatif terletak pada perbaikan “bentuk” proses berpikir model besar.
Secara khusus, metode ini menggunakan 3 model bahasa besar:
Selama proses penalaran, “pengusul” terlebih dahulu memberikan proposal, “verifikator” bertanggung jawab untuk evaluasi, dan “pelapor” memutuskan apakah akan menyelesaikan jawaban dan menghentikan proses berpikir.
**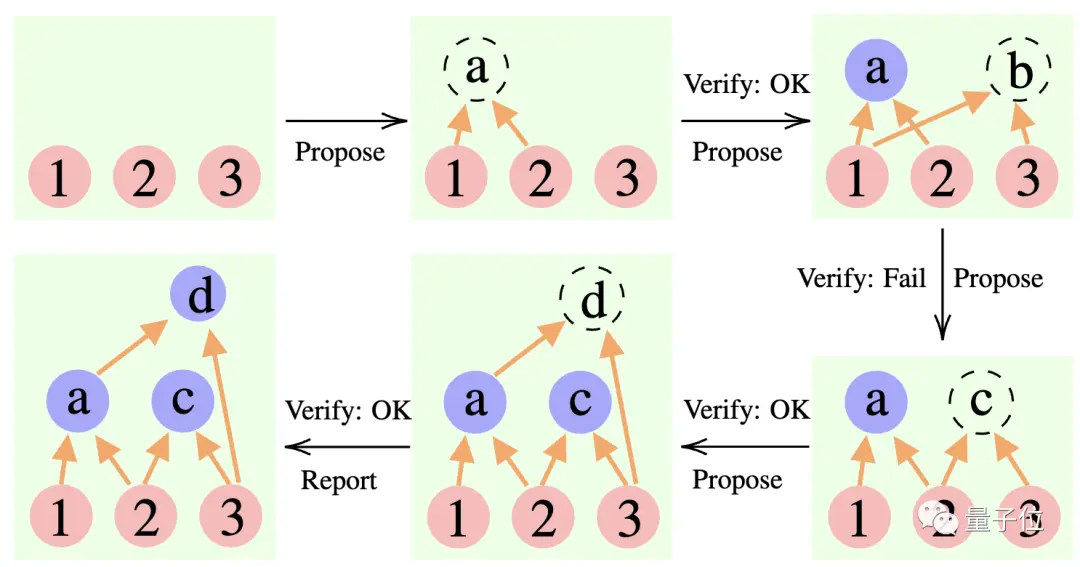 ****△**Contoh penalaran CR
****△**Contoh penalaran CR
Ini seperti tiga jenis peran dalam proyek tim: anggota tim melakukan brainstorming berbagai ide terlebih dahulu, instruktur "memeriksa" untuk melihat ide mana yang layak, dan pemimpin tim memutuskan kapan harus menyelesaikan proyek.
Untuk memahami hal ini, kita harus memulai dengan "Rantai Pemikiran, CoT" (Chain of Thought, CoT), "pencetus" metode peningkatan pemikiran model besar.
Metode ini diusulkan oleh ilmuwan OpenAI Jason Wei dan lainnya pada Januari 2022. Intinya adalah menambahkan teks "penalaran langkah demi langkah" ke masukan dalam kumpulan data untuk merangsang kemampuan berpikir model besar.
**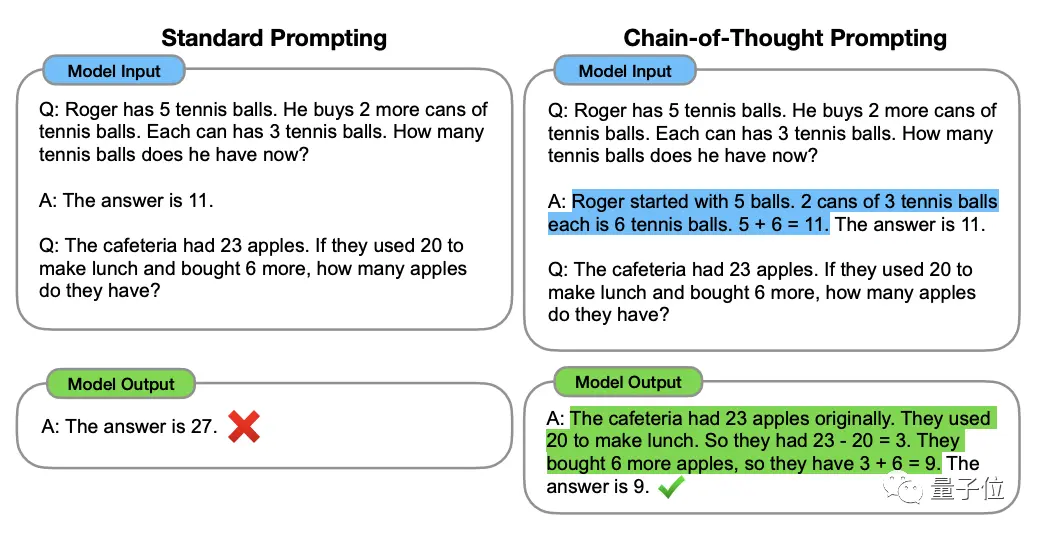 ****△**Dipilih dari kumpulan data GSM8K
****△**Dipilih dari kumpulan data GSM8K
Berdasarkan prinsip rantai pemikiran, Google juga segera menindaklanjuti dengan "rantai pemikiran versi PLUS", yaitu CoT-SC, yang utamanya melakukan beberapa proses rantai pemikiran dan melakukan pemungutan suara terbanyak atas jawaban untuk memilih yang terbaik. .Jawaban terbaik dapat lebih meningkatkan keakuratan penalaran.
Tapi Thinking Chain dan CoT-SC mengabaikan satu masalah: ada lebih dari satu solusi untuk pertanyaan tersebut, terutama ketika manusia memecahkan masalah tersebut.
Oleh karena itu, penelitian baru yang disebut Pohon Pemikiran (ToT) muncul kemudian.
Ini adalah skema pencarian seperti pohon yang memungkinkan model untuk mencoba berbagai ide penalaran yang berbeda, mengevaluasi diri, memilih tindakan berikutnya, dan melakukan kemunduran jika perlu.
Inilah sebabnya ketika bermain 24 poin, tingkat keberhasilan GPT-4 dari bonus Rantai Pemikiran hanya 4%**, namun tingkat keberhasilan Pohon Pemikiran melonjak hingga 74%.
TAPI, terlepas dari rantai pemikiran, CoT-SC atau pohon pemikiran, memiliki batasan umum:
Memang tidak semua proses berpikir bisa dirangkai menjadi rantai atau pohon, cara berpikir manusia seringkali lebih rumit.
Kerangka penalaran kumulatif baru ini menerobos titik desain ini——
Proses berpikir keseluruhan dari model besar tidak harus berupa rantai atau pohon, namun bisa juga berupa Grafik Asiklik Terarah (DAG)! (Yah, baunya seperti sinapsis)
**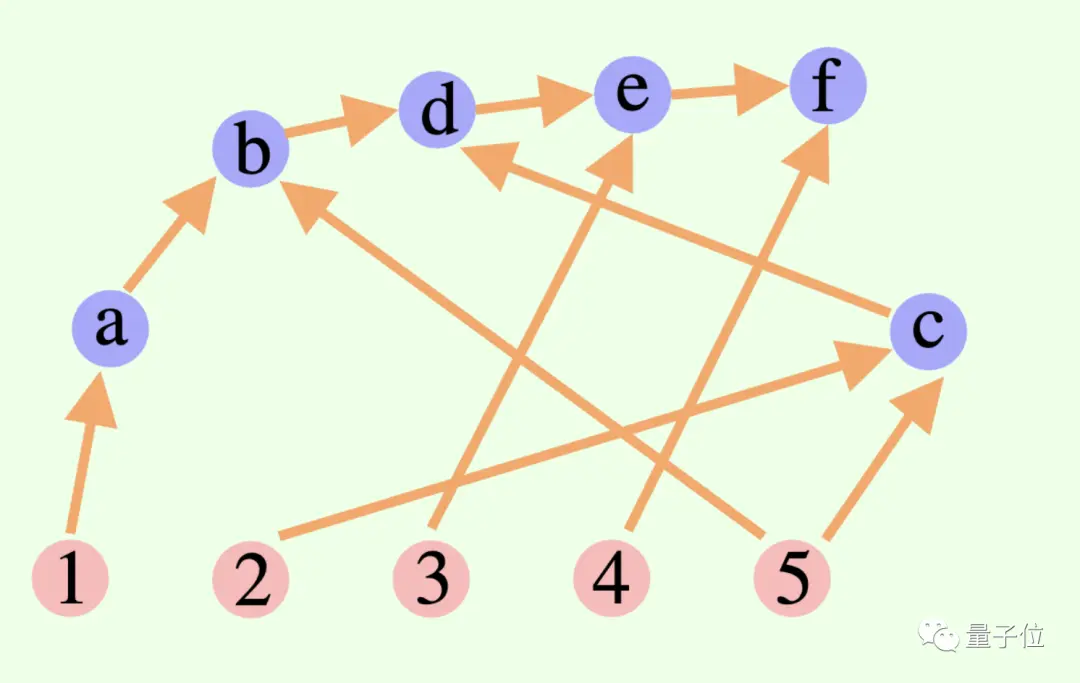 ****△**Tepi pada grafik memiliki arah, dan tidak ada jalur melingkar; setiap tepi yang diarahkan adalah langkah derivasi
****△**Tepi pada grafik memiliki arah, dan tidak ada jalur melingkar; setiap tepi yang diarahkan adalah langkah derivasi
Artinya, ia dapat menyimpan semua hasil inferensi yang benar secara historis dalam memori untuk dieksplorasi di cabang pencarian saat ini. (Sebaliknya, pohon berpikir tidak menyimpan informasi dari cabang lain)
Namun penalaran kumulatif juga dapat dengan mudah dialihkan dengan rantai pemikiran - selama "penguji" dihilangkan, ini adalah model rantai pemikiran standar.
Penalaran kumulatif yang dirancang berdasarkan metode ini telah mencapai hasil yang baik dalam berbagai metode.
Pandai mengerjakan matematika dan penalaran logis
Para peneliti memilih wiki FOLIO dan AutoTNLI, permainan 24 poin, dan kumpulan data MATEMATIKA untuk "menguji" penalaran kumulatif.
Pengusul, pemverifikasi, dan pelapor menggunakan model bahasa besar yang sama di setiap eksperimen, dengan pengaturan berbeda untuk peran mereka.
Model dasar yang digunakan di sini untuk eksperimen meliputi GPT-3.5-turbo, GPT-4, LLaMA-13B, dan LLaMA-65B.
Perlu disebutkan bahwa idealnya, model harus dilatih sebelumnya secara khusus menggunakan data tugas derivasi yang relevan, dan "verifikator" juga harus menambahkan pembuktian matematika formal, modul pemecah logika proposisional, dll.
1. Kemampuan penalaran logis
FOLIO adalah kumpulan data penalaran logis tingkat pertama, dan label pertanyaan dapat berupa "benar", "Salah", dan "Tidak Diketahui"; AutoTNLI adalah kumpulan data penalaran logis tingkat tinggi.
Pada kumpulan data wiki FOLIO, dibandingkan dengan metode hasil keluaran langsung (Direct), rantai pemikiran (CoT), dan rantai pemikiran lanjutan (CoT-SC), kinerja penalaran kumulatif (CR) selalu yang terbaik.
Setelah menghapus contoh bermasalah (seperti jawaban yang salah) dari kumpulan data, akurasi inferensi GPT-4 menggunakan metode CR mencapai 98,04%, dengan tingkat kesalahan minimum 1,96%.
Dibandingkan dengan metode CoT, CR secara signifikan meningkatkan kinerja LLaMA-13B dan LLaMA-65B.
Pada model LLaMA-65B, peningkatan CR dibandingkan CoT mencapai 9,3%.
Makalah ToT asli menggunakan permainan 24 poin, jadi peneliti di sini menggunakan kumpulan data ini untuk membandingkan CR dan ToT.
ToT menggunakan pohon pencarian dengan lebar dan kedalaman tetap, dan CR memungkinkan model besar menentukan kedalaman pencarian secara mandiri.
Para peneliti menemukan dalam percobaan bahwa dalam konteks 24 poin, algoritma CR dan algoritma ToT sangat mirip. Perbedaannya adalah algoritme dalam CR menghasilkan paling banyak satu status baru per iterasi, sedangkan ToT menghasilkan banyak kandidat status di setiap iterasi, serta memfilter dan mempertahankan sebagian status.
Dalam istilah awam, ToT tidak memiliki "verifikator" yang disebutkan di atas seperti CR dan tidak dapat menilai apakah status (a, b, c) benar atau salah. Oleh karena itu, ToT akan mengeksplorasi lebih banyak status yang tidak valid daripada CR.
Dengan kata lain, CR tidak hanya memiliki tingkat akurasi pencarian yang lebih tinggi, tetapi juga memiliki efisiensi pencarian yang lebih tinggi.
Kumpulan data MATEMATIKA berisi sejumlah besar soal penalaran matematika, termasuk aljabar, geometri, teori bilangan, dll. Tingkat kesulitan soal dibagi menjadi lima tingkatan.
Dengan menggunakan metode CR, model dapat menguraikan pertanyaan menjadi sub-pertanyaan yang dapat diselesaikan selangkah demi selangkah, dan bertanya serta menjawab pertanyaan hingga dihasilkan jawabannya.
Hasil eksperimen menunjukkan bahwa dalam dua pengaturan eksperimen yang berbeda, tingkat akurasi CR melebihi metode yang ada saat ini, dengan tingkat akurasi keseluruhan hingga 58%, dan peningkatan akurasi relatif sebesar 42% pada soal Level 5. Mengunduh SOTA baru di bawah model GPT-4.
Penelitian dipimpin oleh Yao Qizhi dan Yuan Yang dari Universitas Tsinghua
Makalah ini berasal dari kelompok riset AI untuk Matematika yang dipimpin oleh Yao Qizhi dan Yuan Yang dari Institut Informasi Interdisipliner Tsinghua.
Rekan penulis pertama makalah ini adalah Zhang Yifan dan Yang Jingqin, mahasiswa doktoral tahun 2021 di Institut Informasi Interdisipliner;
Instruktur dan rekan penulis adalah Asisten Profesor Yuan Yang dan Akademisi Yao Qizhi.
Zhang Yifan
Zhang Yifan lulus dari Yuanpei College of Peking University pada tahun 2021. Saat ini ia belajar di bawah bimbingan Asisten Profesor Yuan Yang. Arahan penelitian utamanya adalah teori dan algoritma model dasar (model bahasa besar), pembelajaran dengan pengawasan mandiri, dan kecerdasan buatan yang tepercaya.
Yang Jingqin
Yang Jingqin menerima gelar sarjananya dari Institut Lintas Informasi di Universitas Tsinghua pada tahun 2021 dan saat ini sedang belajar untuk gelar doktoralnya di bawah bimbingan Asisten Profesor Yuan Yang. Arahan penelitian utama meliputi model bahasa besar, pembelajaran mandiri, perawatan medis cerdas, dll.
Yuan Yang
Arahan penelitian utamanya adalah perawatan medis cerdas, teori AI dasar, teori kategori terapan, dll.
Yao Qizhi
Profesor Yao Qizhi mengundurkan diri dari Princeton sebagai profesor tetap pada tahun 2004 dan kembali ke Tsinghua untuk mengajar; pada tahun 2005, ia mendirikan "Kelas Yao", kelas eksperimen ilmu komputer untuk mahasiswa sarjana Tsinghua; pada tahun 2011, ia mendirikan "Pusat Informasi Kuantum Tsinghua " dan "Institut Penelitian Informasi Interdisipliner"; pada tahun 2019 Pada tahun 2008, ia mendirikan kelas kecerdasan buatan untuk mahasiswa sarjana Tsinghua, yang disebut sebagai "Kelas Cerdas".
Saat ini, Institut Informasi Interdisipliner Universitas Tsinghua yang dipimpinnya telah lama terkenal, Kelas Yao dan Zhiban sama-sama berafiliasi dengan Institut Informasi Interdisipliner.
Minat penelitian Profesor Yao Qizhi meliputi algoritma, kriptografi, komputasi kuantum, dll. Ia adalah pionir dan otoritas internasional di bidang ini. Baru-baru ini, dia muncul di Konferensi Kecerdasan Buatan Dunia 2023. Institut Penelitian Qizhi Shanghai yang dipimpinnya saat ini sedang mempelajari "kecerdasan buatan umum yang diwujudkan".
Tautan kertas: