Kemampuan model besar untuk "membaca gambar" begitu kuat, mengapa Anda terus mencari hal yang salah?
Misalnya, membingungkan kelelawar yang tidak terlihat seperti mereka dengan raket, atau tidak mengenali ikan langka di beberapa kumpulan data ...
Ini karena ketika kita membiarkan model besar "menemukan sesuatu", kita sering memasukkan teks.
Jika deskripsinya ambigu atau terlalu parsial, seperti "kelelawar" (kelelawar atau pukulan?). Atau "Cyprinodon diabolis," dan AI akan bingung.
Hal ini menyebabkan penggunaan model besar untuk melakukan ** deteksi objek **, terutama tugas deteksi objek dunia terbuka (pemandangan tidak diketahui), efeknya seringkali tidak sebaik yang diharapkan.
Sekarang, sebuah makalah yang termasuk dalam NeurIPS 2023 akhirnya memecahkan masalah ini.
Makalah ini mengusulkan metode deteksi objek MQ-Det berdasarkan kueri multimodal, yang hanya perlu menambahkan contoh gambar ke input, yang dapat sangat meningkatkan akurasi menemukan sesuatu dalam model besar.
Pada dataset deteksi benchmark LVIS, MQ-Det meningkatkan akurasi GLIP model besar deteksi mainstream rata-rata sekitar 7,8%, dan meningkatkan akurasi 13 tugas hilir sampel kecil benchmark rata-rata 6,3%.
Bagaimana tepatnya ini dilakukan? Mari kita lihat.
Berikut ini direproduksi dari penulis makalah, Zhihu blogger @Qinyuanxia:
Daftar Isi
MQ-Det: Open-world object detection large model untuk query multimodal
1.1 Dari kueri teks ke kueri multimodal
1.2 MQ-Det plug-and-play arsitektur model query multimodal
1.3 Strategi pelatihan MQ-Det yang efisien
1.4 Hasil eksperimen: Evaluasi bebas finetuning
*1.5 Hasil eksperimen: Evaluasi few-shot
1.6 Permintaan multimodal dari prospek deteksi objek
MQ-DET: Model Besar Deteksi Objek Dunia Terbuka untuk Kueri Multimodal**
Deteksi Objek Kueri Multi-modal di Alam Liar
Tautan Kertas:
Alamat Kode:**
### 1.1 Dari kueri teks ke kueri multimodal
** Satu gambar bernilai seribu kata **: Dengan munculnya pra-pelatihan grafis, dengan bantuan semantik teks terbuka, deteksi objek secara bertahap memasuki tahap persepsi dunia terbuka. Untuk alasan ini, banyak model deteksi besar mengikuti pola kueri teks, yaitu menggunakan deskripsi teks kategoris untuk mengkueri target potensial dalam gambar target. Namun, pendekatan ini sering menghadapi masalah "luas tetapi tidak halus".
Misalnya, (1) deteksi objek berbutir halus (fingerling) pada Gambar 1 seringkali sulit untuk menggambarkan berbagai spesies berbutir halus dengan teks terbatas, dan (2) ambiguitas kategori ("kelelawar" dapat merujuk pada kelelawar dan raket).
Namun, masalah di atas dapat diselesaikan dengan contoh gambar, yang memberikan petunjuk fitur yang lebih kaya ke objek target daripada teks, tetapi pada saat yang sama teks memiliki ** generalisasi kuat **.
Oleh karena itu, bagaimana menggabungkan dua metode kueri secara organik telah menjadi ide alami.
Kesulitan dalam memperoleh kemampuan kueri multimodal: Ada tiga tantangan dalam cara mendapatkan model seperti itu dengan kueri multimodal: (1) Penyempurnaan langsung dengan contoh gambar terbatas dapat dengan mudah menyebabkan bencana lupa; (2) Pelatihan model deteksi besar dari awal akan memiliki generalisasi yang baik tetapi konsumsi besar, misalnya, pelatihan kartu tunggal GLIP membutuhkan 480 hari pelatihan dengan 30 juta volume data.
Deteksi objek kueri multimodal: Berdasarkan pertimbangan di atas, penulis mengusulkan desain model dan strategi pelatihan yang sederhana dan efektif - MQ-Det.
MQ-Det menyisipkan sejumlah kecil modul persepsi terjaga keamanannya (GCP) untuk menerima input contoh visual berdasarkan model besar deteksi kueri teks beku yang ada, dan merancang strategi pelatihan prediksi bahasa topeng kondisi visual untuk mendapatkan detektor secara efisien untuk kueri multimodal berkinerja tinggi.
1.2 MQ-Det plug-and-play arsitektur model kueri multimodal
** **####### △Gambar 1 Diagram arsitektur metode MQ-Det
** Modul Persepsi Gated **
Seperti yang ditunjukkan pada Gambar 1, penulis menyisipkan modul kesadaran gating (GCP) lapis demi lapis di sisi encoder teks dari model besar deteksi kueri teks beku yang ada, dan mode kerja GCP dapat dinyatakan secara ringkas dengan rumus berikut:
Untuk kategori ith, masukkan contoh visual Vi, yang pertama perhatian silang (X-MHA) dengan gambar target I
untuk memperluas kemampuan representasionalnya, lalu setiap teks kategori ti dan contoh visual kategori yang sesuai
Lakukan perhatian silang
, setelah itu teks asli ti dan augmentasi visual teks ditingkatkan oleh gerbang modul gating
Fusion untuk mendapatkan output dari layer saat ini
。 Desain sederhana ini mengikuti tiga prinsip: (1) skalabilitas kategori; (2) kelengkapan semantik; (3) Anti-amnesia, diskusi khusus dapat ditemukan dalam teks asli.
1.3 Strategi Pelatihan Efisien MQ-Det
Pelatihan modulasi berdasarkan detektor kueri bahasa beku
Karena model besar kueri teks deteksi pra-pelatihan saat ini sendiri memiliki generalisasi yang baik, penulis percaya bahwa hanya perlu melakukan sedikit penyesuaian dengan detail visual berdasarkan fitur teks asli.
Dalam artikel tersebut, ada juga demonstrasi eksperimental khusus yang mudah untuk menyebabkan bencana lupa setelah membuka parameter model pra-terlatih asli dan penyempurnaan, tetapi kehilangan kemampuan deteksi dunia terbuka.
Oleh karena itu, MQ-Det dapat menyisipkan informasi visual secara efisien ke detektor kueri teks yang ada berdasarkan detektor kueri teks beku yang telah dilatih sebelumnya dan hanya memodulasi modul GCP yang disisipkan oleh pelatihan.
Dalam makalah ini, penulis menerapkan desain struktural dan teknik pelatihan MQ-Det ke model SOTA saat ini GLIP dan GroundingDINO masing-masing untuk memverifikasi fleksibilitas metode.
Strategi Pelatihan Prediksi Bahasa Topeng dengan Kondisi Visual
Para penulis juga mengusulkan strategi pelatihan prediktif bahasa masking yang dikondisikan secara visual untuk memecahkan masalah kemalasan belajar yang disebabkan oleh pembekuan model pra-pelatihan.
Yang disebut kemalasan belajar berarti bahwa detektor cenderung mempertahankan karakteristik kueri teks asli selama proses pelatihan, sehingga mengabaikan fitur kueri visual yang baru ditambahkan.
Untuk tujuan ini, MQ-Det digunakan secara acak selama pelatihan[MASK] Token menggantikan token teks, memaksa model untuk belajar dari sisi fitur Visual Query, yaitu:
Meskipun strategi ini sederhana, namun sangat efektif, dan dari hasil eksperimen, strategi ini telah membawa peningkatan kinerja yang signifikan.
1.4 Hasil Eksperimen: Evaluasi Bebas Finetuning
Finetuning-free: MQ-Det mengusulkan strategi evaluasi yang lebih praktis: finetuning-free, dibandingkan dengan evaluasi zero-shot tradisional yang hanya menggunakan teks kategori. Ini didefinisikan sebagai deteksi objek menggunakan teks kategori, contoh gambar, atau kombinasi keduanya tanpa penyetelan halus hilir.
Di bawah pengaturan finetuning-free, MQ-Det memilih 5 contoh visual untuk setiap kategori, dan menggabungkan teks kategori untuk deteksi objek, sementara model lain yang ada tidak mendukung kueri visual, dan hanya dapat menggunakan deskripsi teks biasa untuk deteksi objek. Tabel di bawah ini menunjukkan hasil pada LVIS MiniVal dan LVIS v1.0. Dapat ditemukan bahwa pengenalan kueri multimodal telah sangat meningkatkan kemampuan deteksi objek dunia terbuka.
** **###### △Tabel 1 Kinerja bebas finetuning dari setiap model deteksi di bawah dataset benchmark LVIS
Seperti dapat dilihat dari Tabel 1, MQ-GLIP-L telah meningkatkan AP lebih dari 7% berdasarkan GLIP-L, dan efeknya sangat signifikan!
1.5 Hasil Eksperimen: Evaluasi Few-shot
** **####### △Tabel 2 Kinerja setiap model dalam ODinW-35 dan 13 subset ODinW-13 dalam 35 tugas deteksi
Para penulis selanjutnya melakukan eksperimen komprehensif di ODinW-35, tugas deteksi hilir 35. Seperti dapat dilihat dari Tabel 2, MQ-Det tidak hanya memiliki kinerja finetuning-free yang kuat, tetapi juga memiliki kemampuan deteksi sampel kecil yang baik, yang selanjutnya menegaskan potensi kueri multimodal. Gambar 2 juga menunjukkan peningkatan yang signifikan dari MQ-Det ke GLIP.
** **###### △Gambar 2 Perbandingan efisiensi pemanfaatan data; Sumbu horizontal: jumlah sampel pelatihan, sumbu vertikal: rata-rata AP pada OdinW-13
1.6 Prospek untuk Deteksi Objek Kueri Multimodal
Sebagai bidang penelitian berdasarkan aplikasi praktis, deteksi objek sangat memperhatikan pendaratan algoritma.
Meskipun model deteksi objek kueri teks biasa sebelumnya menunjukkan generalisasi yang baik, sulit untuk menutupi informasi berbutir halus dalam bahasa Cina deteksi dunia terbuka yang sebenarnya, dan perincian informasi yang kaya dalam gambar melengkapi tautan ini dengan sempurna.
Sejauh ini, kita dapat menemukan bahwa teksnya generik tetapi tidak tepat, dan gambarnya tepat tetapi tidak umum, dan jika kita dapat secara efektif menggabungkan keduanya, yaitu kueri multimodal, itu akan mempromosikan deteksi objek dunia terbuka untuk bergerak lebih jauh.
MQ-Det telah mengambil langkah pertama dalam kueri multimodal, dan peningkatan kinerjanya yang signifikan juga menunjukkan potensi besar deteksi target kueri multimodal.
Pada saat yang sama, pengenalan deskripsi teks dan contoh visual memberi pengguna lebih banyak pilihan, membuat deteksi objek lebih fleksibel dan ramah pengguna.
Tautan asli:
Lihat Asli
Halaman ini mungkin berisi konten pihak ketiga, yang disediakan untuk tujuan informasi saja (bukan pernyataan/jaminan) dan tidak boleh dianggap sebagai dukungan terhadap pandangannya oleh Gate, atau sebagai nasihat keuangan atau profesional. Lihat Penafian untuk detailnya.
Buat model besar melihat diagram daripada mengetik karya! Studi Baru NeurIPS 2023 Mengusulkan Metode Kueri Multimodal, Akurasi Meningkat 7.8%
Sumber asli: Qubits
Kemampuan model besar untuk "membaca gambar" begitu kuat, mengapa Anda terus mencari hal yang salah?
Misalnya, membingungkan kelelawar yang tidak terlihat seperti mereka dengan raket, atau tidak mengenali ikan langka di beberapa kumpulan data ...
Jika deskripsinya ambigu atau terlalu parsial, seperti "kelelawar" (kelelawar atau pukulan?). Atau "Cyprinodon diabolis," dan AI akan bingung.
Hal ini menyebabkan penggunaan model besar untuk melakukan ** deteksi objek **, terutama tugas deteksi objek dunia terbuka (pemandangan tidak diketahui), efeknya seringkali tidak sebaik yang diharapkan.
Sekarang, sebuah makalah yang termasuk dalam NeurIPS 2023 akhirnya memecahkan masalah ini.
Pada dataset deteksi benchmark LVIS, MQ-Det meningkatkan akurasi GLIP model besar deteksi mainstream rata-rata sekitar 7,8%, dan meningkatkan akurasi 13 tugas hilir sampel kecil benchmark rata-rata 6,3%.
Bagaimana tepatnya ini dilakukan? Mari kita lihat.
Berikut ini direproduksi dari penulis makalah, Zhihu blogger @Qinyuanxia:
Daftar Isi
MQ-Det: Open-world object detection large model untuk query multimodal
MQ-DET: Model Besar Deteksi Objek Dunia Terbuka untuk Kueri Multimodal**
Deteksi Objek Kueri Multi-modal di Alam Liar
Tautan Kertas:
Alamat Kode:**
** Satu gambar bernilai seribu kata **: Dengan munculnya pra-pelatihan grafis, dengan bantuan semantik teks terbuka, deteksi objek secara bertahap memasuki tahap persepsi dunia terbuka. Untuk alasan ini, banyak model deteksi besar mengikuti pola kueri teks, yaitu menggunakan deskripsi teks kategoris untuk mengkueri target potensial dalam gambar target. Namun, pendekatan ini sering menghadapi masalah "luas tetapi tidak halus".
Misalnya, (1) deteksi objek berbutir halus (fingerling) pada Gambar 1 seringkali sulit untuk menggambarkan berbagai spesies berbutir halus dengan teks terbatas, dan (2) ambiguitas kategori ("kelelawar" dapat merujuk pada kelelawar dan raket).
Namun, masalah di atas dapat diselesaikan dengan contoh gambar, yang memberikan petunjuk fitur yang lebih kaya ke objek target daripada teks, tetapi pada saat yang sama teks memiliki ** generalisasi kuat **.
Oleh karena itu, bagaimana menggabungkan dua metode kueri secara organik telah menjadi ide alami.
Kesulitan dalam memperoleh kemampuan kueri multimodal: Ada tiga tantangan dalam cara mendapatkan model seperti itu dengan kueri multimodal: (1) Penyempurnaan langsung dengan contoh gambar terbatas dapat dengan mudah menyebabkan bencana lupa; (2) Pelatihan model deteksi besar dari awal akan memiliki generalisasi yang baik tetapi konsumsi besar, misalnya, pelatihan kartu tunggal GLIP membutuhkan 480 hari pelatihan dengan 30 juta volume data.
Deteksi objek kueri multimodal: Berdasarkan pertimbangan di atas, penulis mengusulkan desain model dan strategi pelatihan yang sederhana dan efektif - MQ-Det.
MQ-Det menyisipkan sejumlah kecil modul persepsi terjaga keamanannya (GCP) untuk menerima input contoh visual berdasarkan model besar deteksi kueri teks beku yang ada, dan merancang strategi pelatihan prediksi bahasa topeng kondisi visual untuk mendapatkan detektor secara efisien untuk kueri multimodal berkinerja tinggi.
1.2 MQ-Det plug-and-play arsitektur model kueri multimodal
** **####### △Gambar 1 Diagram arsitektur metode MQ-Det
**####### △Gambar 1 Diagram arsitektur metode MQ-Det
** Modul Persepsi Gated **
Seperti yang ditunjukkan pada Gambar 1, penulis menyisipkan modul kesadaran gating (GCP) lapis demi lapis di sisi encoder teks dari model besar deteksi kueri teks beku yang ada, dan mode kerja GCP dapat dinyatakan secara ringkas dengan rumus berikut:
1.3 Strategi Pelatihan Efisien MQ-Det
Pelatihan modulasi berdasarkan detektor kueri bahasa beku
Karena model besar kueri teks deteksi pra-pelatihan saat ini sendiri memiliki generalisasi yang baik, penulis percaya bahwa hanya perlu melakukan sedikit penyesuaian dengan detail visual berdasarkan fitur teks asli.
Dalam artikel tersebut, ada juga demonstrasi eksperimental khusus yang mudah untuk menyebabkan bencana lupa setelah membuka parameter model pra-terlatih asli dan penyempurnaan, tetapi kehilangan kemampuan deteksi dunia terbuka.
Oleh karena itu, MQ-Det dapat menyisipkan informasi visual secara efisien ke detektor kueri teks yang ada berdasarkan detektor kueri teks beku yang telah dilatih sebelumnya dan hanya memodulasi modul GCP yang disisipkan oleh pelatihan.
Dalam makalah ini, penulis menerapkan desain struktural dan teknik pelatihan MQ-Det ke model SOTA saat ini GLIP dan GroundingDINO masing-masing untuk memverifikasi fleksibilitas metode.
Strategi Pelatihan Prediksi Bahasa Topeng dengan Kondisi Visual
Para penulis juga mengusulkan strategi pelatihan prediktif bahasa masking yang dikondisikan secara visual untuk memecahkan masalah kemalasan belajar yang disebabkan oleh pembekuan model pra-pelatihan.
Yang disebut kemalasan belajar berarti bahwa detektor cenderung mempertahankan karakteristik kueri teks asli selama proses pelatihan, sehingga mengabaikan fitur kueri visual yang baru ditambahkan.
Untuk tujuan ini, MQ-Det digunakan secara acak selama pelatihan[MASK] Token menggantikan token teks, memaksa model untuk belajar dari sisi fitur Visual Query, yaitu:
1.4 Hasil Eksperimen: Evaluasi Bebas Finetuning
Finetuning-free: MQ-Det mengusulkan strategi evaluasi yang lebih praktis: finetuning-free, dibandingkan dengan evaluasi zero-shot tradisional yang hanya menggunakan teks kategori. Ini didefinisikan sebagai deteksi objek menggunakan teks kategori, contoh gambar, atau kombinasi keduanya tanpa penyetelan halus hilir.
Di bawah pengaturan finetuning-free, MQ-Det memilih 5 contoh visual untuk setiap kategori, dan menggabungkan teks kategori untuk deteksi objek, sementara model lain yang ada tidak mendukung kueri visual, dan hanya dapat menggunakan deskripsi teks biasa untuk deteksi objek. Tabel di bawah ini menunjukkan hasil pada LVIS MiniVal dan LVIS v1.0. Dapat ditemukan bahwa pengenalan kueri multimodal telah sangat meningkatkan kemampuan deteksi objek dunia terbuka.
**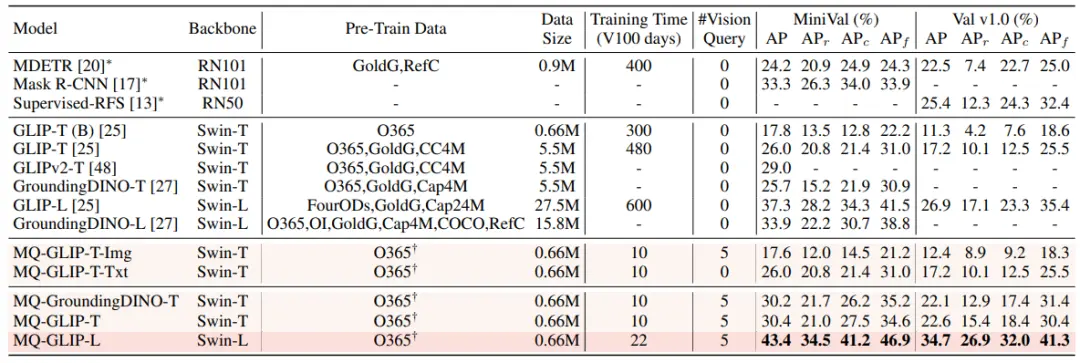 **###### △Tabel 1 Kinerja bebas finetuning dari setiap model deteksi di bawah dataset benchmark LVIS
**###### △Tabel 1 Kinerja bebas finetuning dari setiap model deteksi di bawah dataset benchmark LVIS
Seperti dapat dilihat dari Tabel 1, MQ-GLIP-L telah meningkatkan AP lebih dari 7% berdasarkan GLIP-L, dan efeknya sangat signifikan!
1.5 Hasil Eksperimen: Evaluasi Few-shot
**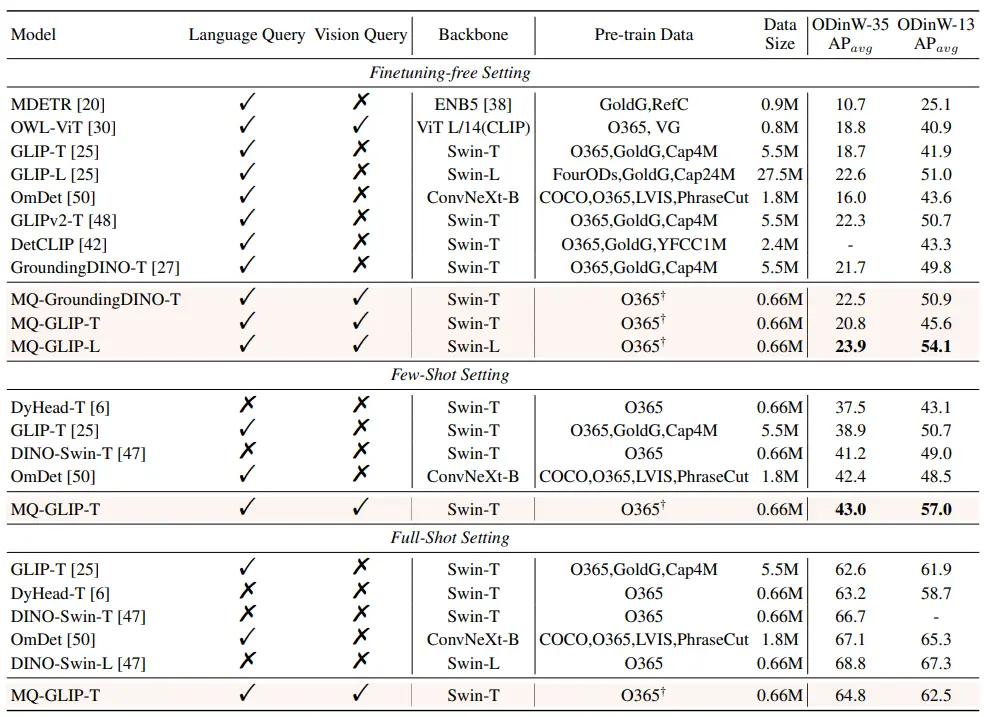 **####### △Tabel 2 Kinerja setiap model dalam ODinW-35 dan 13 subset ODinW-13 dalam 35 tugas deteksi
**####### △Tabel 2 Kinerja setiap model dalam ODinW-35 dan 13 subset ODinW-13 dalam 35 tugas deteksi
Para penulis selanjutnya melakukan eksperimen komprehensif di ODinW-35, tugas deteksi hilir 35. Seperti dapat dilihat dari Tabel 2, MQ-Det tidak hanya memiliki kinerja finetuning-free yang kuat, tetapi juga memiliki kemampuan deteksi sampel kecil yang baik, yang selanjutnya menegaskan potensi kueri multimodal. Gambar 2 juga menunjukkan peningkatan yang signifikan dari MQ-Det ke GLIP.
**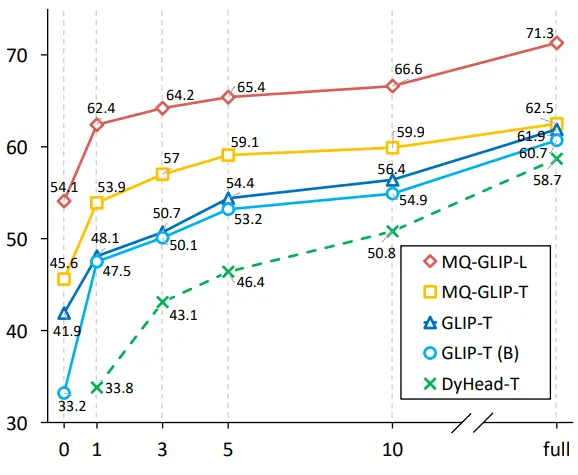 **###### △Gambar 2 Perbandingan efisiensi pemanfaatan data; Sumbu horizontal: jumlah sampel pelatihan, sumbu vertikal: rata-rata AP pada OdinW-13
**###### △Gambar 2 Perbandingan efisiensi pemanfaatan data; Sumbu horizontal: jumlah sampel pelatihan, sumbu vertikal: rata-rata AP pada OdinW-13
1.6 Prospek untuk Deteksi Objek Kueri Multimodal
Sebagai bidang penelitian berdasarkan aplikasi praktis, deteksi objek sangat memperhatikan pendaratan algoritma.
Meskipun model deteksi objek kueri teks biasa sebelumnya menunjukkan generalisasi yang baik, sulit untuk menutupi informasi berbutir halus dalam bahasa Cina deteksi dunia terbuka yang sebenarnya, dan perincian informasi yang kaya dalam gambar melengkapi tautan ini dengan sempurna.
Sejauh ini, kita dapat menemukan bahwa teksnya generik tetapi tidak tepat, dan gambarnya tepat tetapi tidak umum, dan jika kita dapat secara efektif menggabungkan keduanya, yaitu kueri multimodal, itu akan mempromosikan deteksi objek dunia terbuka untuk bergerak lebih jauh.
MQ-Det telah mengambil langkah pertama dalam kueri multimodal, dan peningkatan kinerjanya yang signifikan juga menunjukkan potensi besar deteksi target kueri multimodal.
Pada saat yang sama, pengenalan deskripsi teks dan contoh visual memberi pengguna lebih banyak pilihan, membuat deteksi objek lebih fleksibel dan ramah pengguna.
Tautan asli: