Model parameter 7 miliar yang membutuhkan 500 dolar untuk "menyetel" mengalahkan parameter 70 miliar Llama 2!
Dan notebook dapat berjalan dengan mudah, dan efeknya sebanding dengan ChatGPT.
Penting: Gratis, tidak ada uang.
Model open-source Zephyr-7B yang dibuat oleh tim HuggingFace H4, gila hiu.
Model dasarnya adalah model besar open-source Mistral-7B, yang meledak beberapa waktu lalu dan dibangun oleh Mistral AI, yang dikenal sebagai "OpenAI Eropa".
Anda tahu, kurang dari 2 minggu setelah rilis Mistral-7B, berbagai versi yang disempurnakan telah muncul satu demi satu, dan ada banyak gaya "alpaka" yang dengan cepat muncul ketika Llama pertama kali dirilis.
Kunci kemampuan Zephyr untuk menonjol di antara varian adalah bahwa tim menyempurnakan model pada dataset publik menggunakan Direct Preference Optimization (DPO) di atas Mistral.
Tim juga menemukan bahwa menghapus penyelarasan built-in dari dataset dapat lebih meningkatkan kinerja MT Bench. Zephyr-7B-alpha asli memiliki skor MT-Bench rata-rata 7,09, melebihi Llama2-70B-Chat.
** **###### △MT-Bench adalah tes benchmark untuk mengevaluasi kemampuan model untuk menangani beberapa putaran dialog, dan kumpulan pertanyaan mencakup 8 kategori seperti menulis, bermain peran, dan ekstraksi.
Intinya adalah, itu kemudian melanjutkan untuk meningkatkan!
Tim H4 meluncurkan generasi kedua Zephyr-7B-beta. Mereka menambahkan bahwa mereka mengeksplorasi gagasan untuk mengekstraksi penyelarasan dari GPT-4, Claude 2 dan kemudian menyuntikkannya ke dalam model kecil, mengembangkan metode untuk menggunakan optimasi preferensi langsung distilasi (dDPO) untuk model kecil.
Pada Zephyr generasi kedua, rata-rata skor MT-Bench meningkat menjadi 7,34.
Di Alpaca, Zephyr memiliki win rate 90,6%, yang lebih baik dari ChatGPT (3,5):
Netizen yang bergegas ke Zephyr memberikan pujian dengan suara bulat, dan tim lmsys juga menunjukkan skor Elo Zephyr-7b-beta, yang telah melonjak sangat tinggi 🔥:
Papan peringkat Arena internal telah melampaui model 13B.
Beberapa orang bahkan berkata:
Melihat pendekatan DPO berkinerja baik di lapangan mungkin adalah hal yang paling menarik tentang pengembangan model bahasa besar tahun ini.
Lebih banyak netizen yang mulai menguji efek Zephyr, dan hasilnya sangat bagus.
Kata Mistral berarti angin kering, dingin dan kuat dalam bahasa Prancis, sedangkan Zephyr berarti angin barat yang ringan dan menyenangkan.
Tidak ada keraguan bahwa ada kebun binatang di sisi lain Llama, dan tidak ada keraguan bahwa ada biro cuaca di sisi ini.
Model 7B terbaik berpindah tangan lagi
Mari kita mulai dengan persyaratan komputer untuk menjalankan Zephyr. Netizen mengatakan "celana Thailand pedas" setelah tes! , notebook (Apple M1 Pro) sudah cukup, "hasilnya sangat bagus".
Dalam hal efektivitas, tim Llama Index (sebelumnya dikenal sebagai GPT Index) juga mengujinya.
Ternyata Zephyr saat ini adalah satu-satunya model 7B open-source yang berkinerja baik pada tugas RAG/agen tingkat tinggi.
Data juga menunjukkan bahwa efek dari tugas RAG tingkat lanjut Zephyr dapat bersaing dengan GPT-3.5 dan Claude 2.
Mereka melanjutkan dengan menambahkan bahwa Zephyr tidak hanya bekerja dengan baik pada RAG, tetapi juga dalam perutean, perencanaan kueri, mengambil pernyataan SQL yang kompleks, dan ekstraksi data terstruktur.
Pejabat juga memberikan hasil tes, dan pada MT-Bench, Zephyr-7B-beta memiliki kinerja yang kuat dibandingkan dengan model yang lebih besar seperti Llama2-Chat-70B.
Tetapi pada tugas yang lebih kompleks seperti pengkodean dan matematika, Zephyr-7B-beta tertinggal dari model proprietary dan membutuhkan lebih banyak penelitian untuk menutup kesenjangan.
Abaikan Pembelajaran Penguatan
Sementara semua orang menguji efek Zephyr, pengembang mengatakan hal yang paling menarik bukanlah metrik, tetapi cara model dilatih.
Sorotan dirangkum di bawah ini:
Sempurnakan model pretrained open-source kecil terbaik: Mistral 7B
Penggunaan Dataset Preferensi Skala Besar: UltraFeedback
Gunakan Direct Preference Optimization (DPO) bukan pembelajaran penguatan
Tanpa diduga, overfitting dataset preferensi menghasilkan hasil yang lebih baik
Secara garis besar, seperti yang disebutkan di awal, alasan utama mengapa Zephyr mampu melampaui 70B Llama 2 adalah karena penggunaan metode fine-tuning khusus.
Berbeda dengan pendekatan pembelajaran penguatan PPO tradisional, tim peneliti menggunakan kolaborasi baru-baru ini antara Stanford University dan CZ Biohub untuk mengusulkan pendekatan DPO.
Menurut para peneliti:
DPO jauh lebih stabil daripada PPO.
Secara sederhana, DPO dapat dijelaskan sebagai berikut:
Untuk membuat output model lebih sesuai dengan preferensi manusia, pendekatan tradisional adalah menyempurnakan model target dengan model hadiah. Jika outputnya bagus, Anda akan diberi imbalan, dan jika outputnya buruk, Anda tidak akan diberi imbalan.
Pendekatan DPO, di sisi lain, melewati fungsi penghargaan pemodelan dan setara dengan mengoptimalkan model secara langsung pada data preferensi.
Secara umum, DPO memecahkan masalah pelatihan pembelajaran penguatan yang sulit dan mahal karena umpan balik manusia.
Dalam hal pelatihan Zephyr secara khusus, tim peneliti awalnya menyempurnakan Zephyr-7B-alpha pada varian dataset UltraChat yang disederhanakan, yang berisi 1,6 juta percakapan yang dihasilkan oleh ChatGPT (sekitar 200.000 tersisa).
(Alasan untuk perampingan adalah bahwa tim menemukan bahwa Zephyr kadang-kadang huruf besar/kecil salah, seperti "Hai. apa kabar?"; Terkadang respons dimulai dengan "Saya tidak punya X pribadi". )
Kemudian, mereka lebih lanjut menyelaraskan model dengan dataset openbmb/UltraFeedback yang tersedia untuk umum menggunakan metode DPO Trainer TRL.
Himpunan data berisi 64.000 pasangan respons cepat dari berbagai model. Setiap respons diberi peringkat oleh GPT-4 berdasarkan kriteria seperti kegunaan dan diberi skor dari mana preferensi AI berasal.
Temuan yang menarik adalah bahwa ketika menggunakan metode DPO, efeknya sebenarnya lebih baik setelah overfitting seiring bertambahnya waktu pelatihan. Para peneliti percaya ini mirip dengan overfitting di SFT.
Perlu disebutkan bahwa tim peneliti juga memperkenalkan bahwa fine-tuning model dengan metode ini hanya berharga $ 500, yaitu 8 jam berjalan pada 16 A100s.
Ketika mengupgrade Zephyr ke beta, tim melanjutkan untuk menjelaskan pendekatan mereka.
Mereka berpikir tentang distilasi supervised fine-tuning (dSFT) yang digunakan dalam model besar, tetapi dengan pendekatan ini model tidak selaras dan tidak menghasilkan output yang sesuai dengan maksud pengguna.
Jadi tim mencoba menggunakan data preferensi dari AI Feedback (AIF) untuk memberi peringkat output dengan "model guru" untuk membentuk himpunan data, dan kemudian menerapkan pengoptimalan preferensi langsung distilasi (dDPO) untuk melatih model yang selaras dengan maksud pengguna tanpa pengambilan sampel tambahan selama penyempurnaan.
Para peneliti juga menguji efek ketika SFT tidak digunakan, dan hasilnya menghasilkan penurunan kinerja yang signifikan, menunjukkan bahwa langkah dSFT sangat penting.
Saat ini, selain modelnya sudah open source dan komersial, ada juga Demo untuk dicoba, sehingga kita bisa memulai dan mengalaminya dengan mudah.
Pengalaman Demo
Pertama-tama, saya harus keluar dari pertanyaan "cacat mental" untuk mengikuti tes.
Pada pertanyaan "Ayah dan Ibu jangan membawaku saat mereka menikah", jawaban keseluruhan Zephyr lebih akurat.
ChatGPT tidak bisa mengalahkan pertanyaan ini.
Dalam pengujian, kami juga menemukan bahwa Zephyr juga tahu tentang kejadian baru-baru ini seperti rilis GPT-4 OpenAI:
Ini sebenarnya terkait dengan model yang mendasarinya, meskipun pejabat Mistral tidak menentukan batas waktu untuk data pelatihan.
Tetapi beberapa netizen telah mengujinya sebelumnya, dan juga mengetahuinya pada bulan Maret tahun ini.
Sebaliknya, data pra-pelatihan Llama 2 adalah per September 2022, dan hanya beberapa data yang disempurnakan hingga Juni 2023.
Selain itu, Zephyr sangat responsif, sehingga kamu bisa menulis kode dan mengarang cerita. :
Perlu disebutkan bahwa Zephyr lebih baik dalam menjawab pertanyaan dalam bahasa Inggris, dan juga memiliki masalah umum dengan model "halusinasi".
Para peneliti juga menyebutkan halusinasi, dan baris kecil teks ditandai di bawah kotak input yang menunjukkan bahwa konten yang dihasilkan oleh model mungkin tidak akurat atau salah.
Intinya adalah Zephyr tidak menggunakan metode seperti pembelajaran penguatan dengan umpan balik manusia untuk menyelaraskan dengan preferensi manusia, juga tidak menggunakan penyaringan respons ChatGPT.
Selalu pilih salah satu ikan emmm dan cakar beruang.
Zephyr mampu melakukan ini hanya dengan parameter 70B, yang mengejutkan Andriy Burkov, penulis "The 100-Page Machine Learning Book", dan bahkan berkata:
Zephyr-7B mengalahkan Llama 2-70B dengan model dasar Mistral-7B dengan jendela konteks token 8k, yang secara teoritis memiliki rentang perhatian hingga 128K token.
Bagaimana jika Zephyr adalah model 70B? Apakah akan mengungguli GPT-4? Sepertinya mungkin.
Jika kamu tertarik dengan Zephyr-7B, kamu bisa mencobanya di huggingface.
Tautan Kertas:
Link Referensi:
[1]
[2]
[3]
[4]
[5]
Lihat Asli
Halaman ini mungkin berisi konten pihak ketiga, yang disediakan untuk tujuan informasi saja (bukan pernyataan/jaminan) dan tidak boleh dianggap sebagai dukungan terhadap pandangannya oleh Gate, atau sebagai nasihat keuangan atau profesional. Lihat Penafian untuk detailnya.
Model 7B terbaik berpindah tangan lagi! Kalahkan 70 miliar LLaMA2, dan komputer Apple akan dapat menjalankan|open source dan gratis
Sumber asli: qubits
Model parameter 7 miliar yang membutuhkan 500 dolar untuk "menyetel" mengalahkan parameter 70 miliar Llama 2!
Dan notebook dapat berjalan dengan mudah, dan efeknya sebanding dengan ChatGPT.
Penting: Gratis, tidak ada uang.
Model open-source Zephyr-7B yang dibuat oleh tim HuggingFace H4, gila hiu.
Kunci kemampuan Zephyr untuk menonjol di antara varian adalah bahwa tim menyempurnakan model pada dataset publik menggunakan Direct Preference Optimization (DPO) di atas Mistral.
Tim juga menemukan bahwa menghapus penyelarasan built-in dari dataset dapat lebih meningkatkan kinerja MT Bench. Zephyr-7B-alpha asli memiliki skor MT-Bench rata-rata 7,09, melebihi Llama2-70B-Chat.
**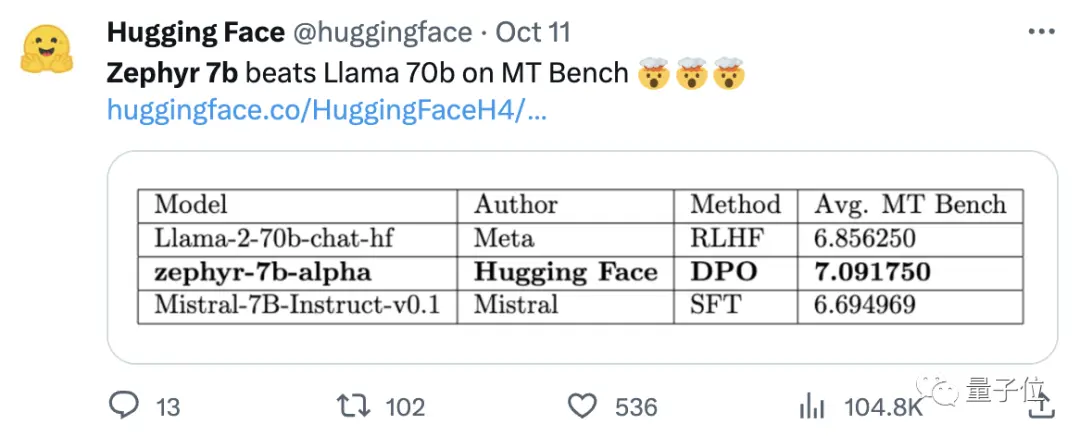 **###### △MT-Bench adalah tes benchmark untuk mengevaluasi kemampuan model untuk menangani beberapa putaran dialog, dan kumpulan pertanyaan mencakup 8 kategori seperti menulis, bermain peran, dan ekstraksi.
**###### △MT-Bench adalah tes benchmark untuk mengevaluasi kemampuan model untuk menangani beberapa putaran dialog, dan kumpulan pertanyaan mencakup 8 kategori seperti menulis, bermain peran, dan ekstraksi.
Intinya adalah, itu kemudian melanjutkan untuk meningkatkan!
Tim H4 meluncurkan generasi kedua Zephyr-7B-beta. Mereka menambahkan bahwa mereka mengeksplorasi gagasan untuk mengekstraksi penyelarasan dari GPT-4, Claude 2 dan kemudian menyuntikkannya ke dalam model kecil, mengembangkan metode untuk menggunakan optimasi preferensi langsung distilasi (dDPO) untuk model kecil.
Pada Zephyr generasi kedua, rata-rata skor MT-Bench meningkat menjadi 7,34.
Kata Mistral berarti angin kering, dingin dan kuat dalam bahasa Prancis, sedangkan Zephyr berarti angin barat yang ringan dan menyenangkan.
Tidak ada keraguan bahwa ada kebun binatang di sisi lain Llama, dan tidak ada keraguan bahwa ada biro cuaca di sisi ini.
Model 7B terbaik berpindah tangan lagi
Mari kita mulai dengan persyaratan komputer untuk menjalankan Zephyr. Netizen mengatakan "celana Thailand pedas" setelah tes! , notebook (Apple M1 Pro) sudah cukup, "hasilnya sangat bagus".
Data juga menunjukkan bahwa efek dari tugas RAG tingkat lanjut Zephyr dapat bersaing dengan GPT-3.5 dan Claude 2.
Mereka melanjutkan dengan menambahkan bahwa Zephyr tidak hanya bekerja dengan baik pada RAG, tetapi juga dalam perutean, perencanaan kueri, mengambil pernyataan SQL yang kompleks, dan ekstraksi data terstruktur.
Abaikan Pembelajaran Penguatan
Sementara semua orang menguji efek Zephyr, pengembang mengatakan hal yang paling menarik bukanlah metrik, tetapi cara model dilatih.
Sorotan dirangkum di bawah ini:
Secara garis besar, seperti yang disebutkan di awal, alasan utama mengapa Zephyr mampu melampaui 70B Llama 2 adalah karena penggunaan metode fine-tuning khusus.
Berbeda dengan pendekatan pembelajaran penguatan PPO tradisional, tim peneliti menggunakan kolaborasi baru-baru ini antara Stanford University dan CZ Biohub untuk mengusulkan pendekatan DPO.
Secara sederhana, DPO dapat dijelaskan sebagai berikut:
Untuk membuat output model lebih sesuai dengan preferensi manusia, pendekatan tradisional adalah menyempurnakan model target dengan model hadiah. Jika outputnya bagus, Anda akan diberi imbalan, dan jika outputnya buruk, Anda tidak akan diberi imbalan.
Pendekatan DPO, di sisi lain, melewati fungsi penghargaan pemodelan dan setara dengan mengoptimalkan model secara langsung pada data preferensi.
Secara umum, DPO memecahkan masalah pelatihan pembelajaran penguatan yang sulit dan mahal karena umpan balik manusia.
Dalam hal pelatihan Zephyr secara khusus, tim peneliti awalnya menyempurnakan Zephyr-7B-alpha pada varian dataset UltraChat yang disederhanakan, yang berisi 1,6 juta percakapan yang dihasilkan oleh ChatGPT (sekitar 200.000 tersisa).
(Alasan untuk perampingan adalah bahwa tim menemukan bahwa Zephyr kadang-kadang huruf besar/kecil salah, seperti "Hai. apa kabar?"; Terkadang respons dimulai dengan "Saya tidak punya X pribadi". )
Kemudian, mereka lebih lanjut menyelaraskan model dengan dataset openbmb/UltraFeedback yang tersedia untuk umum menggunakan metode DPO Trainer TRL.
Himpunan data berisi 64.000 pasangan respons cepat dari berbagai model. Setiap respons diberi peringkat oleh GPT-4 berdasarkan kriteria seperti kegunaan dan diberi skor dari mana preferensi AI berasal.
Temuan yang menarik adalah bahwa ketika menggunakan metode DPO, efeknya sebenarnya lebih baik setelah overfitting seiring bertambahnya waktu pelatihan. Para peneliti percaya ini mirip dengan overfitting di SFT.
Mereka berpikir tentang distilasi supervised fine-tuning (dSFT) yang digunakan dalam model besar, tetapi dengan pendekatan ini model tidak selaras dan tidak menghasilkan output yang sesuai dengan maksud pengguna.
Para peneliti juga menguji efek ketika SFT tidak digunakan, dan hasilnya menghasilkan penurunan kinerja yang signifikan, menunjukkan bahwa langkah dSFT sangat penting.
Pengalaman Demo
Pertama-tama, saya harus keluar dari pertanyaan "cacat mental" untuk mengikuti tes.
Pada pertanyaan "Ayah dan Ibu jangan membawaku saat mereka menikah", jawaban keseluruhan Zephyr lebih akurat.
Tetapi beberapa netizen telah mengujinya sebelumnya, dan juga mengetahuinya pada bulan Maret tahun ini.
Selain itu, Zephyr sangat responsif, sehingga kamu bisa menulis kode dan mengarang cerita. :
Para peneliti juga menyebutkan halusinasi, dan baris kecil teks ditandai di bawah kotak input yang menunjukkan bahwa konten yang dihasilkan oleh model mungkin tidak akurat atau salah.
Selalu pilih salah satu ikan emmm dan cakar beruang.
Zephyr mampu melakukan ini hanya dengan parameter 70B, yang mengejutkan Andriy Burkov, penulis "The 100-Page Machine Learning Book", dan bahkan berkata:
Tautan Kertas:
Link Referensi:
[1]
[2]
[3]
[4]
[5]