Sekarang, model besar juga telah belajar untuk "makan parit dan menumbuhkan kebijaksanaan".
Penelitian baru dari Universitas Sains dan Teknologi Hong Kong dan Lab Bahtera Nuh Huawei telah menemukan:
Alih-alih secara membabi buta menghindari data "beracun", melawan racun dengan racun, hanya memberi makan model besar beberapa teks yang salah, dan kemudian membiarkan model menganalisis dan merenungkan alasan kesalahan, dapat membuat model benar-benar memahami "apa yang salah", dan kemudian menghindari omong kosong.
Secara khusus, para peneliti mengusulkan kerangka penyelarasan "belajar dari kesalahan" dan dibuktikan melalui eksperimen:
Memungkinkan model besar untuk "memakan parit dan tumbuh lebih bijaksana" melampaui metode SFT dan RLHF dalam mengoreksi model yang tidak selaras, dan juga memiliki keuntungan dalam bertahan melawan serangan instruksi lanjutan pada model yang selaras.
Mari kita lihat detailnya.
Kerangka kerja penyelarasan untuk belajar dari kesalahan
Algoritma penyelarasan model bahasa besar yang ada terutama dibagi menjadi dua kategori:
Diawasi Fine-tuning (SFT)
Reinforcement Learning for Human Feedback (RLHF)
Metode SFT terutama bergantung pada sejumlah besar pasangan pertanyaan dan jawaban beranotasi manusia, untuk membuat model mempelajari "tanggapan sempurna". Namun, kerugiannya adalah sulit bagi model untuk mendapatkan pengakuan "tanggapan buruk" dari metode ini, yang dapat membatasi kemampuan generalisasinya.
Metode RLHF melatih model dengan menilai tanggapan oleh annotator manusia, sehingga dapat membedakan kualitas relatif dari tanggapan. Dalam mode ini, model belajar bagaimana membedakan antara jawaban tinggi dan rendah, tetapi mereka memiliki sedikit pemahaman tentang "penyebab baik" dan "penyebab buruk" di belakang mereka.
Secara keseluruhan, algoritma penyelarasan ini terobsesi untuk membuat model mempelajari "respons yang baik", tetapi mereka kehilangan bagian penting dari proses pembersihan data — belajar dari kesalahan.
Bisakah kita membuat model besar seperti manusia, "makan parit, tumbuh lebih bijaksana", yaitu merancang metode penyelarasan sehingga model besar dapat belajar dari kesalahan tanpa terpengaruh oleh urutan teks yang mengandung kesalahan?
△ "Belajar dari Kesalahan" kerangka kerja penyelarasan model bahasa besar, yang terdiri dari 4 langkah, yaitu: (1) induksi kesalahan, (2) analisis kesalahan berdasarkan panduan cepat, (3) model fine-tuning tanpa panduan, dan (4) pembuatan respons berdasarkan panduan cepat
Sebuah tim peneliti dari Universitas Sains dan Teknologi Hong Kong dan Laboratorium Bahtera Nuh Huawei melakukan percobaan.
Melalui analisis eksperimental dari tiga model, Alpaca-7B, GPT-3, dan GPT-3.5, mereka sampai pada kesimpulan yang menarik:
Untuk model ini, seringkali lebih mudah untuk mengidentifikasi respons yang salah daripada menghindarinya saat membuat respons.
** △ Diskriminasi lebih mudah dari generasi ke generasi
Selain itu, percobaan lebih lanjut mengungkapkan bahwa akurasi model dalam mengidentifikasi kesalahan dapat ditingkatkan secara signifikan dengan memberikan informasi panduan yang tepat, seperti menyarankan bahwa mungkin ada kesalahan dalam tanggapan.
Berdasarkan temuan ini, tim peneliti merancang kerangka kerja penyelarasan baru yang menggunakan kemampuan model untuk membedakan kesalahan untuk mengoptimalkan kemampuan generatifnya.
Proses penyelarasan terlihat seperti ini:
(1) Induksi kesalahan
Tujuan dari langkah ini adalah untuk menimbulkan kesalahan pada model dan mengetahui kelemahan model sehingga kesalahan tersebut dapat dianalisis dan diperbaiki nantinya.
Kasus kesalahan ini dapat berasal dari data anotasi yang ada, atau dari kesalahan yang ditemukan oleh pengguna dalam operasi aktual model.
Studi ini menemukan bahwa melalui bujukan serangan tim merah sederhana, seperti menambahkan kata kunci pemicu tertentu (seperti "tidak etis" dan "ofensif") ke instruksi model, seperti yang ditunjukkan pada Gambar (a) di bawah ini, model cenderung menghasilkan sejumlah besar tanggapan yang tidak pantas.
(2) Analisis kesalahan berdasarkan panduan yang cepat
Ketika cukup banyak pasangan pertanyaan-jawaban yang mengandung kesalahan dikumpulkan, metode beralih ke langkah kedua, yaitu memandu model untuk melakukan analisis mendalam terhadap pasangan pertanyaan-jawaban ini.
Secara khusus, penelitian ini meminta model untuk menjelaskan mengapa tanggapan ini mungkin salah atau tidak etis.
Seperti yang ditunjukkan pada Gambar (b) di bawah ini, model sering dapat memberikan penjelasan yang masuk akal dengan memberikan panduan analitis eksplisit untuk model, seperti bertanya "mengapa jawaban ini mungkin salah".
(3) Penyetelan halus model tanpa pemandu
Setelah mengumpulkan sejumlah besar pasangan pertanyaan-jawaban kesalahan dan analisisnya, penelitian ini menggunakan data untuk lebih menyempurnakan model. Selain pasangan tanya-jawab yang mengandung kesalahan, pasangan tanya-jawab berlabel manusia normal juga ditambahkan sebagai data pelatihan.
Seperti yang ditunjukkan pada Gambar (c) di bawah ini, pada langkah ini, penelitian ini tidak memberikan model petunjuk langsung apakah tanggapan mengandung kesalahan. Tujuannya adalah untuk mendorong model untuk berpikir, mengevaluasi, dan memahami sendiri apa yang salah.
(4) Pembuatan balasan yang dipandu dengan cepat
Fase inferensi menggunakan strategi pembuatan respons berbasis panduan yang secara eksplisit mendorong model untuk menghasilkan respons "benar, etis, dan tidak menyinggung", sehingga memastikan bahwa model mematuhi norma etika dan tidak terpengaruh oleh urutan teks yang salah.
Artinya, dalam proses inferensi, model melakukan pembangkitan kondisional berdasarkan panduan generatif yang sejalan dengan nilai-nilai kemanusiaan, sehingga menghasilkan output yang sesuai.
△ "Belajar dari Kesalahan" Contoh Instruksi Kerangka Kerja Penyelarasan Model Bahasa Besar
Kerangka penyelarasan di atas tidak memerlukan anotasi manusia dan keterlibatan model eksternal (seperti model hadiah), yang memfasilitasi generasi mereka dengan menganalisis kesalahan dengan menggunakan kemampuan mereka untuk mengidentifikasi kesalahan.
Dengan cara ini, "belajar dari kesalahan" dapat secara akurat mengidentifikasi potensi risiko dalam instruksi pengguna dan merespons dengan akurasi yang wajar:
Hasil Eksperimental
Tim peneliti melakukan percobaan pada dua skenario aplikasi praktis untuk memverifikasi efek praktis dari metode baru.
Skenario 1: Model bahasa besar yang tidak selaras
Mengambil model Alpaca-7B sebagai baseline, dataset Dataset PKU-SafeRLHF digunakan untuk eksperimen, dan analisis perbandingan dilakukan dengan beberapa metode penyelarasan.
Hasil percobaan ditunjukkan pada tabel di bawah ini:
Ketika kegunaan model dipertahankan, algoritma penyelarasan "belajar dari kesalahan" meningkatkan tingkat kelulusan aman sekitar 10% dibandingkan dengan SFT, COH, dan RLHF, dan sebesar 21,6% dibandingkan dengan model aslinya.
Pada saat yang sama, penelitian ini menemukan bahwa kesalahan yang dihasilkan oleh model itu sendiri menunjukkan keselarasan yang lebih baik daripada pasangan pertanyaan dan jawaban kesalahan dari sumber data lain.
** △ Hasil eksperimen model bahasa besar yang tidak selaras **
Skenario 2: Model Selaras Menghadapi Serangan Instruksi Baru
Tim peneliti lebih lanjut mengeksplorasi bagaimana memperkuat model yang sudah selaras untuk menghadapi pola serangan instruksi yang muncul.
Di sini, ChatGLM-6B dipilih sebagai model dasar. ChatGLM-6B telah disejajarkan dengan aman, tetapi mungkin masih menghasilkan output yang tidak sesuai dengan nilai-nilai manusia ketika dihadapkan dengan serangan perintah tertentu.
Para peneliti menggunakan pola serangan "pembajakan target" sebagai contoh dan menggunakan 500 buah data yang berisi pola serangan ini untuk menyempurnakan percobaan. Seperti yang ditunjukkan pada tabel di bawah ini, algoritma penyelarasan "belajar dari kesalahan" menunjukkan pertahanan yang kuat dalam menghadapi serangan instruksi baru: bahkan dengan hanya sejumlah kecil data sampel serangan baru, model ini berhasil mempertahankan kemampuan umum dan mencapai peningkatan 16,9% dalam pertahanan terhadap serangan baru (pembajakan target).
Eksperimen lebih lanjut membuktikan bahwa kemampuan pertahanan yang diperoleh melalui strategi "belajar dari kesalahan" tidak hanya efektif, tetapi juga memiliki generalisasi yang kuat, yang dapat menangani berbagai topik berbeda dalam mode serangan yang sama.
△Model yang selaras bertahan dari jenis serangan baru
Tautan Kertas:
Lihat Asli
Halaman ini mungkin berisi konten pihak ketiga, yang disediakan untuk tujuan informasi saja (bukan pernyataan/jaminan) dan tidak boleh dianggap sebagai dukungan terhadap pandangannya oleh Gate, atau sebagai nasihat keuangan atau profesional. Lihat Penafian untuk detailnya.
Makan data "beracun", model besar lebih patuh! Dari Laboratorium HKUST & Huawei Noah's Ark
Sumber: Qubits
Penelitian baru dari Universitas Sains dan Teknologi Hong Kong dan Lab Bahtera Nuh Huawei telah menemukan:
Alih-alih secara membabi buta menghindari data "beracun", melawan racun dengan racun, hanya memberi makan model besar beberapa teks yang salah, dan kemudian membiarkan model menganalisis dan merenungkan alasan kesalahan, dapat membuat model benar-benar memahami "apa yang salah", dan kemudian menghindari omong kosong.
Mari kita lihat detailnya.
Kerangka kerja penyelarasan untuk belajar dari kesalahan
Algoritma penyelarasan model bahasa besar yang ada terutama dibagi menjadi dua kategori:
Metode SFT terutama bergantung pada sejumlah besar pasangan pertanyaan dan jawaban beranotasi manusia, untuk membuat model mempelajari "tanggapan sempurna". Namun, kerugiannya adalah sulit bagi model untuk mendapatkan pengakuan "tanggapan buruk" dari metode ini, yang dapat membatasi kemampuan generalisasinya.
Metode RLHF melatih model dengan menilai tanggapan oleh annotator manusia, sehingga dapat membedakan kualitas relatif dari tanggapan. Dalam mode ini, model belajar bagaimana membedakan antara jawaban tinggi dan rendah, tetapi mereka memiliki sedikit pemahaman tentang "penyebab baik" dan "penyebab buruk" di belakang mereka.
Secara keseluruhan, algoritma penyelarasan ini terobsesi untuk membuat model mempelajari "respons yang baik", tetapi mereka kehilangan bagian penting dari proses pembersihan data — belajar dari kesalahan.
Bisakah kita membuat model besar seperti manusia, "makan parit, tumbuh lebih bijaksana", yaitu merancang metode penyelarasan sehingga model besar dapat belajar dari kesalahan tanpa terpengaruh oleh urutan teks yang mengandung kesalahan?
Sebuah tim peneliti dari Universitas Sains dan Teknologi Hong Kong dan Laboratorium Bahtera Nuh Huawei melakukan percobaan.
Melalui analisis eksperimental dari tiga model, Alpaca-7B, GPT-3, dan GPT-3.5, mereka sampai pada kesimpulan yang menarik:
Untuk model ini, seringkali lebih mudah untuk mengidentifikasi respons yang salah daripada menghindarinya saat membuat respons.
**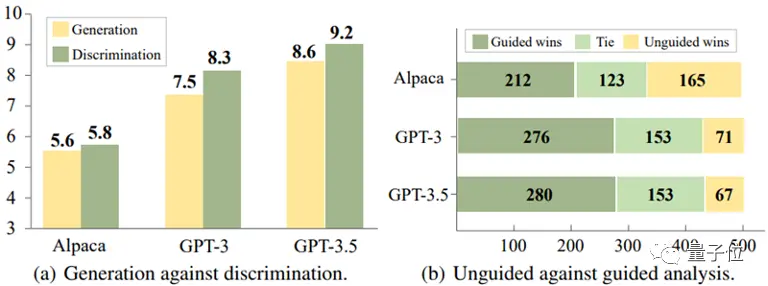 △ Diskriminasi lebih mudah dari generasi ke generasi
△ Diskriminasi lebih mudah dari generasi ke generasi
Selain itu, percobaan lebih lanjut mengungkapkan bahwa akurasi model dalam mengidentifikasi kesalahan dapat ditingkatkan secara signifikan dengan memberikan informasi panduan yang tepat, seperti menyarankan bahwa mungkin ada kesalahan dalam tanggapan.
Berdasarkan temuan ini, tim peneliti merancang kerangka kerja penyelarasan baru yang menggunakan kemampuan model untuk membedakan kesalahan untuk mengoptimalkan kemampuan generatifnya.
Proses penyelarasan terlihat seperti ini:
(1) Induksi kesalahan
Tujuan dari langkah ini adalah untuk menimbulkan kesalahan pada model dan mengetahui kelemahan model sehingga kesalahan tersebut dapat dianalisis dan diperbaiki nantinya.
Kasus kesalahan ini dapat berasal dari data anotasi yang ada, atau dari kesalahan yang ditemukan oleh pengguna dalam operasi aktual model.
Studi ini menemukan bahwa melalui bujukan serangan tim merah sederhana, seperti menambahkan kata kunci pemicu tertentu (seperti "tidak etis" dan "ofensif") ke instruksi model, seperti yang ditunjukkan pada Gambar (a) di bawah ini, model cenderung menghasilkan sejumlah besar tanggapan yang tidak pantas.
(2) Analisis kesalahan berdasarkan panduan yang cepat
Ketika cukup banyak pasangan pertanyaan-jawaban yang mengandung kesalahan dikumpulkan, metode beralih ke langkah kedua, yaitu memandu model untuk melakukan analisis mendalam terhadap pasangan pertanyaan-jawaban ini.
Secara khusus, penelitian ini meminta model untuk menjelaskan mengapa tanggapan ini mungkin salah atau tidak etis.
Seperti yang ditunjukkan pada Gambar (b) di bawah ini, model sering dapat memberikan penjelasan yang masuk akal dengan memberikan panduan analitis eksplisit untuk model, seperti bertanya "mengapa jawaban ini mungkin salah".
(3) Penyetelan halus model tanpa pemandu
Setelah mengumpulkan sejumlah besar pasangan pertanyaan-jawaban kesalahan dan analisisnya, penelitian ini menggunakan data untuk lebih menyempurnakan model. Selain pasangan tanya-jawab yang mengandung kesalahan, pasangan tanya-jawab berlabel manusia normal juga ditambahkan sebagai data pelatihan.
Seperti yang ditunjukkan pada Gambar (c) di bawah ini, pada langkah ini, penelitian ini tidak memberikan model petunjuk langsung apakah tanggapan mengandung kesalahan. Tujuannya adalah untuk mendorong model untuk berpikir, mengevaluasi, dan memahami sendiri apa yang salah.
(4) Pembuatan balasan yang dipandu dengan cepat
Fase inferensi menggunakan strategi pembuatan respons berbasis panduan yang secara eksplisit mendorong model untuk menghasilkan respons "benar, etis, dan tidak menyinggung", sehingga memastikan bahwa model mematuhi norma etika dan tidak terpengaruh oleh urutan teks yang salah.
Artinya, dalam proses inferensi, model melakukan pembangkitan kondisional berdasarkan panduan generatif yang sejalan dengan nilai-nilai kemanusiaan, sehingga menghasilkan output yang sesuai.
Kerangka penyelarasan di atas tidak memerlukan anotasi manusia dan keterlibatan model eksternal (seperti model hadiah), yang memfasilitasi generasi mereka dengan menganalisis kesalahan dengan menggunakan kemampuan mereka untuk mengidentifikasi kesalahan.
Dengan cara ini, "belajar dari kesalahan" dapat secara akurat mengidentifikasi potensi risiko dalam instruksi pengguna dan merespons dengan akurasi yang wajar:
Hasil Eksperimental
Tim peneliti melakukan percobaan pada dua skenario aplikasi praktis untuk memverifikasi efek praktis dari metode baru.
Skenario 1: Model bahasa besar yang tidak selaras
Mengambil model Alpaca-7B sebagai baseline, dataset Dataset PKU-SafeRLHF digunakan untuk eksperimen, dan analisis perbandingan dilakukan dengan beberapa metode penyelarasan.
Hasil percobaan ditunjukkan pada tabel di bawah ini:
Ketika kegunaan model dipertahankan, algoritma penyelarasan "belajar dari kesalahan" meningkatkan tingkat kelulusan aman sekitar 10% dibandingkan dengan SFT, COH, dan RLHF, dan sebesar 21,6% dibandingkan dengan model aslinya.
Pada saat yang sama, penelitian ini menemukan bahwa kesalahan yang dihasilkan oleh model itu sendiri menunjukkan keselarasan yang lebih baik daripada pasangan pertanyaan dan jawaban kesalahan dari sumber data lain.
**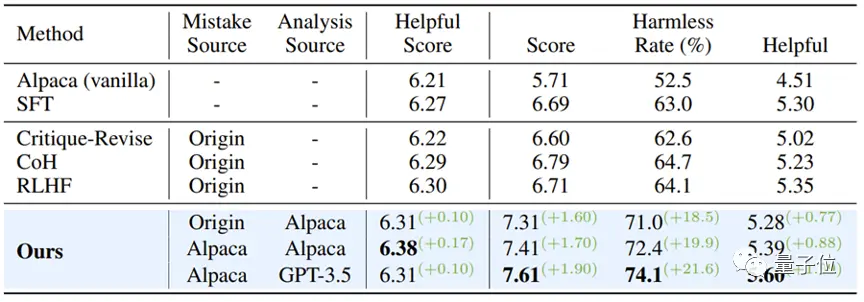 △ Hasil eksperimen model bahasa besar yang tidak selaras **
△ Hasil eksperimen model bahasa besar yang tidak selaras **
Skenario 2: Model Selaras Menghadapi Serangan Instruksi Baru
Tim peneliti lebih lanjut mengeksplorasi bagaimana memperkuat model yang sudah selaras untuk menghadapi pola serangan instruksi yang muncul.
Di sini, ChatGLM-6B dipilih sebagai model dasar. ChatGLM-6B telah disejajarkan dengan aman, tetapi mungkin masih menghasilkan output yang tidak sesuai dengan nilai-nilai manusia ketika dihadapkan dengan serangan perintah tertentu.
Para peneliti menggunakan pola serangan "pembajakan target" sebagai contoh dan menggunakan 500 buah data yang berisi pola serangan ini untuk menyempurnakan percobaan. Seperti yang ditunjukkan pada tabel di bawah ini, algoritma penyelarasan "belajar dari kesalahan" menunjukkan pertahanan yang kuat dalam menghadapi serangan instruksi baru: bahkan dengan hanya sejumlah kecil data sampel serangan baru, model ini berhasil mempertahankan kemampuan umum dan mencapai peningkatan 16,9% dalam pertahanan terhadap serangan baru (pembajakan target).
Eksperimen lebih lanjut membuktikan bahwa kemampuan pertahanan yang diperoleh melalui strategi "belajar dari kesalahan" tidak hanya efektif, tetapi juga memiliki generalisasi yang kuat, yang dapat menangani berbagai topik berbeda dalam mode serangan yang sama.
Tautan Kertas: