元のソース: Qubit大型モデルの改良に最適な GPU **NVIDIA H100**、**完売**!今注文しても、2024 年の第 1 四半期、さらには第 2 四半期まで入手可能になりません。これは、Nvidia と密接な関係にあるクラウド ベンダーである CoreWeave がウォール ストリート ジャーナルに明らかにした最新ニュースです。> 4 月初旬から供給が非常に逼迫しています。 **わずか 1 週間**で、予想納期は **妥当な水準から年末までに大幅に短縮されました**。 世界最大のクラウドベンダーであるAmazon AWSもこのニュースを認め、CEOのアダム・セリプスキー氏は最近次のように述べた。> A100 と H100 は最先端のものです...**AWS でも入手するのは困難**。以前、マスク氏はトークショーで、**GPUは現在、製品よりも入手が困難になっている**とも述べた。 購入できる「ダフ屋」を見つけた場合、プレミアムは **25%** となります。たとえば、Ebay での価格は工場出荷時の約 36,000 米ドルから 45,000 米ドル** に上昇しており、供給は不足しています。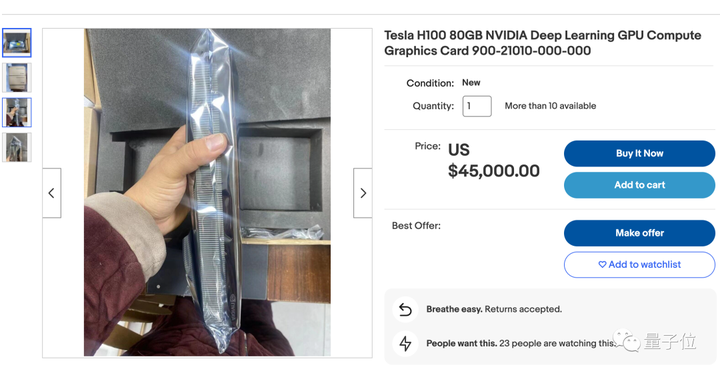 こうした状況を受けて、Baidu、Byte、Ali、Tencent** などの国内大手テクノロジー企業も、総額 50 億ドル** で A800 などのチップを Nvidia に発注しています。このうち、年内に納品できるのは10億ドルのみで、残りの80%は2024年まで待たなければならない。では、既存のハイエンド GPU は誰に販売されているのでしょうか?この生産能力の波はどこで止まっているのでしょうか?## **H100 を誰に売るか、ラオ・ファンが最終決定権を持っています**ChatGPT の発生以来、大規模モデルのトレーニングに優れた Nvidia A100 および H100 が人気になりました。H100であっても、新興企業が住宅ローンを取得するための投資資金を見つけるための資産としてすでに使用できます。OpenAI や Meta に代表される **AI 企業**、Amazon や Microsoft に代表される **クラウド コンピューティング企業**、プライベート クラウド Coreweave や Lambda、および独自の大規模モデルを改良したいと考えているすべての **さまざまなテクノロジー企業**、需要は膨大です。**ただし、基本的に、誰に販売するかについて最終決定権を持っているのは、Nvidia CEO の Huang Renxun です。 ** The Information によると、H100 は供給が非常に不足しているため、Nvidia** は大量の新しいカードを CoreWeave** に割り当て、Amazon や Microsoft などの既存のクラウド コンピューティング企業への供給を限定しています**。(Nvidia は CoreWeave にも直接投資しています。)外部分析は、これらの確立された企業がNvidiaへの依存を減らしたいと考えて独自のAI加速チップを開発しているためで、Lao Huangはそれらを支援することになります。Lao Huang は、**「営業担当者が小規模な潜在顧客に話す内容の確認」** も含め、NVIDIA 内での日常業務のあらゆる側面を管理しています。同社の幹部約 40 名は Lao Huang** に直接報告されており、これは Meta Xiaozha と Microsoft Xiaona の直属の部下を合わせた数よりも多いです。Nvidia の元マネージャーは、「Nvidia では、**Huang Renxun が実際にすべての製品の最高製品責任者** です。」と明らかにしました。 少し前には、Lao Huang が、GPU のエンド ユーザーが誰であるかを知りたくて、**いくつかの小規模なクラウド コンピューティング会社に顧客リストの提供を依頼する**という大げさな行動をとったという噂もありました。外部分析によると、この動きにより、Nvidia は自社製品に対する顧客のニーズをより深く理解できるようになり、Nvidia がこの情報をさらなる利益のために利用する可能性があるという懸念も生じています。また、別の理由として、老黄氏が誰がカードを実際に使用しているのか、誰がカードを貯め込んで使用していないのかを知りたがっているのではないかと考える人もいます。 なぜ今、Nvidia と Lao Huang がこれほど大きな声を上げているのでしょうか?その主な理由は、ハイエンド GPU の需要と供給のバランスがあまりにもアンバランスであるためで、GPU Utils Web サイトの計算によると、H100** ギャップは 430,000** にも上ります。著者のClay Pascal氏は、さまざまな既知の情報や噂に基づいて、近い将来AI業界のさまざまなプレーヤーが必要とするH100の数を推定しました。**AI企業側:*** OpenAI が GPT-5 をトレーニングするには 50,000 個の H100 が必要な場合があります※メタには10万必要と言われています* InflectionAI の 22,000 枚カードのコンピューティング パワー クラスター計画が発表されました* ヨーロッパの Anthropic、Character.ai、MistraAI、HelsingAI などの主要な AI スタートアップ企業では、それぞれ 10,000 程度のコストが必要です。**クラウド コンピューティング会社:*** 大規模なパブリック クラウドでは、Amazon、Microsoft、Google、Oracle はすべて 30,000、合計 120,000 として計算されます。※CoreWeaveやLambdaに代表されるプライベートクラウドは合計10万必要合計すると432,000になります。これには、一部の金融会社や、独自のコンピューティング パワー クラスターの展開を開始した JP モルガン チェースやツー シグマなどの他の業界参加者は含まれていません。そこで問題は、これほど大きな供給ギャップがあると、もっと生産できないのかということです。Lao Huang もそれを考えましたが、**生産能力が行き詰まっています**。## **今回、生産能力はどこで行き詰まっているのでしょうか? **実際、TSMCはすでにNvidia向けの生産計画を調整している。しかし、それでもそのような大きなギャップを埋めることはできませんでした。NvidiaのDGXシステム担当副社長兼ゼネラルマネージャーのチャーリー・ボイル氏は、今回はウェハ上にスタックしていないが、TSMCのCoWoSパッケージング技術が生産能力のボトルネックに遭遇していると述べた。TSMCの生産能力をめぐってNvidiaと競合しているのはAppleであり、9月のカンファレンス前に次世代iPhone用のA17チップを入手することになる。TSMC は最近、パッケージング プロセスのバックログを通常の状態に戻すには 1.5 年かかると予想されると発表しました。CoWoS パッケージング技術は TSMC のハウスキーピング技術であり、TSMC がサムスンを破って Apple の独占的なチップファウンドリになれる理由はこれにかかっています。このテクノロジーによってパッケージ化された製品は高性能と強力な信頼性を備えているため、H100 は 3TB/s (またはそれ以上) の帯域幅を実現できます。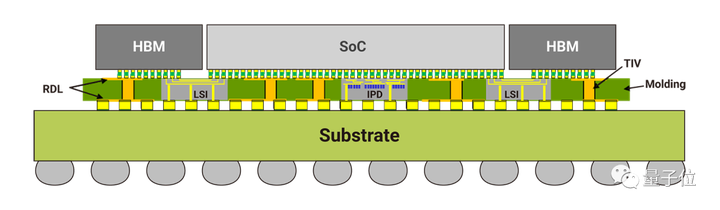 CoWoS の正式名称は Chip-on-Wafer-on-Substrate で、ウェーハレベルで独自のチップ集積技術です。この技術により、厚さわずか 100μm** のシリコン インターポーザー上に複数のチップをパッケージングすることが可能になります。報道によると、次世代インターポーザーの面積はレチクルの6倍、約5000mm²に達するとのこと。今のところ、TSMC を除けば、このレベルのパッケージング能力を備えたメーカーはありません。 CoWoS は確かに強力ですが、CoWoS なしでは機能しないのでしょうか?他のメーカーでもできるでしょうか?言うまでもなく、Lao Huang氏はすでに「2番目のH100鋳造工場の追加は検討しない」と述べています。実際には不可能かもしれません。Nvidiaは以前にもSamsungと協力したことがあるが、SamsungはNvidia向けのH100シリーズ製品や他の5nmプロセスチップさえも生産したことがない。このことから、Samsungの技術レベルではNvidiaの最先端GPUに対する技術的ニーズを満たすことができないのではないかと推測する人もいる。Intelに関しては...5nm製品はまだ登場していないようです。 Lao Huang のメーカーを変更するのは現実的ではないので、ユーザーは直接 AMD に切り替えるのはどうでしょうか。## **AMD、はい?**パフォーマンスだけを見れば、AMD は確かにゆっくりと追いつきつつあります。AMD の最新の MI300X は、192 GB の HBM3 メモリ、5.2 TB/秒の帯域幅を備え、800 億のパラメータ モデルを実行できます。Nvidia がリリースしたばかりの DGX GH200 は、141 GB の HBM3e メモリと 5 TB/s の帯域幅を備えています。しかし、これはAMDがすぐにNカードの空きを埋めることができるという意味ではありません—Nvidia の本当の「堀」は CUDA プラットフォームにあります。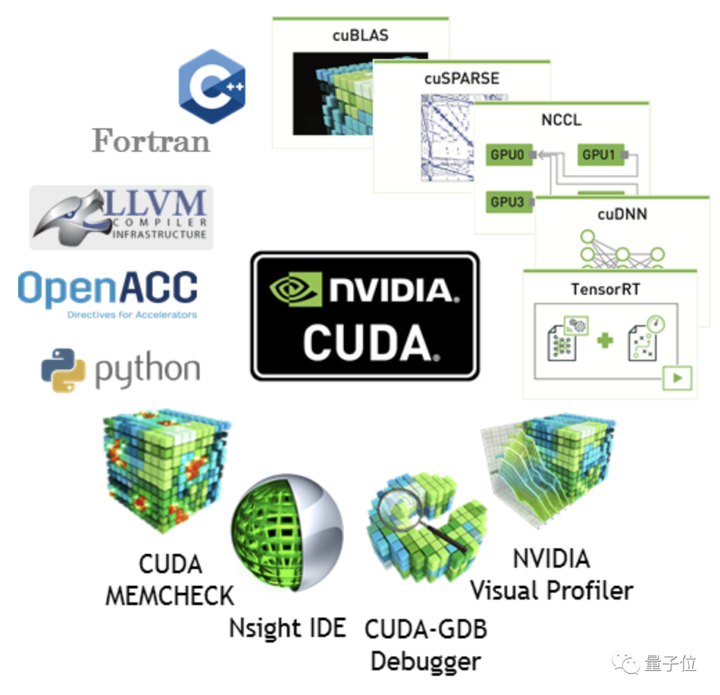 ###### CUDA は完全な開発エコシステムを確立しています。つまり、ユーザーが AMD 製品を購入すると、デバッグに時間がかかります。あるプライベートクラウド会社の幹部は、1万基のAMD GPUを実験的に導入するために3億ドルを投じるリスクを冒す人はいないだろうと語った。同幹部は、開発とデバッグのサイクルには少なくとも 2 か月かかる可能性があると考えています。AI製品の急速な置き換えを背景に、2か月のギャップはどのメーカーにとっても致命的となる可能性があります。 しかし、Microsoft は AMD にもオリーブの枝を広げました。以前、Microsoftがコードネーム「Athena」というAIチップをAMDと共同開発する準備をしているという噂が流れた。以前、MI200 がリリースされたとき、Microsoft は最初に購入を発表し、クラウド プラットフォーム Azure に導入しました。たとえば、MSRA の新しい大規模モデル インフラストラクチャ RetNet は、少し前に 512 台の AMD MI200 でトレーニングされました。 Nvidia が AI 市場のほぼ全体を占めている状況では、誰かが先陣を切って主導権を握る必要があるかもしれません。また、誰かがフォローアップする前に、大規模な AMD コンピューティング パワー クラスター全体のプロトタイプを作成する必要があります。ただし、短期間では、Nvidia H100 および A100 が依然として最も主流の選択肢となっています。## **もう一つ**少し前に、Apple が最大 192 GB のメモリ** をサポートする新しい M2 Ultra チップをリリースしたとき、多くの実務者がそれを使って大型モデルを微調整することを楽しみました。結局のところ、Apple の M シリーズ チップのメモリとビデオ メモリは統合されており、**192GB メモリは 192GB ビデオ メモリ**であり、これは 80GB H100 の 2.4 倍、または 24GB RTX4090 の 8 倍です。 しかし、誰かが実際にこのマシンを購入した後、実際のテストとトレーニングの速度**は Nvidia RTX3080TI** ほど良くなく、トレーニングはおろか、微調整もコスト効率が良くありません。結局のところ、M シリーズ チップの計算能力は AI コンピューティング用に特に最適化されておらず、Everbright ビデオ メモリは役に立ちません。大型モデルのリファインは主にH100に頼っているようで、H100は求められないものです。このような状況に直面して、インターネット上では魔法のような「GPU ソング」** まで出回っています。非常に洗脳されているので、慎重に入力してください。、再生時間 04:10GPUソングホーム参考リンク:[1][2][3][4][5][6][7][8][9]
黄老の勝利! NvidiaのH100発注は24年前から計画されており、マスク氏は黙ってはいられない
元のソース: Qubit
大型モデルの改良に最適な GPU NVIDIA H100、完売!
今注文しても、2024 年の第 1 四半期、さらには第 2 四半期まで入手可能になりません。
これは、Nvidia と密接な関係にあるクラウド ベンダーである CoreWeave がウォール ストリート ジャーナルに明らかにした最新ニュースです。
以前、マスク氏はトークショーで、GPUは現在、製品よりも入手が困難になっているとも述べた。
たとえば、Ebay での価格は工場出荷時の約 36,000 米ドルから 45,000 米ドル** に上昇しており、供給は不足しています。
このうち、年内に納品できるのは10億ドルのみで、残りの80%は2024年まで待たなければならない。
では、既存のハイエンド GPU は誰に販売されているのでしょうか?この生産能力の波はどこで止まっているのでしょうか?
H100 を誰に売るか、ラオ・ファンが最終決定権を持っています
ChatGPT の発生以来、大規模モデルのトレーニングに優れた Nvidia A100 および H100 が人気になりました。
H100であっても、新興企業が住宅ローンを取得するための投資資金を見つけるための資産としてすでに使用できます。
OpenAI や Meta に代表される AI 企業、Amazon や Microsoft に代表される クラウド コンピューティング企業、プライベート クラウド Coreweave や Lambda、および独自の大規模モデルを改良したいと考えているすべての さまざまなテクノロジー企業、需要は膨大です。
**ただし、基本的に、誰に販売するかについて最終決定権を持っているのは、Nvidia CEO の Huang Renxun です。 **
(Nvidia は CoreWeave にも直接投資しています。)
外部分析は、これらの確立された企業がNvidiaへの依存を減らしたいと考えて独自のAI加速チップを開発しているためで、Lao Huangはそれらを支援することになります。
Lao Huang は、「営業担当者が小規模な潜在顧客に話す内容の確認」 も含め、NVIDIA 内での日常業務のあらゆる側面を管理しています。
同社の幹部約 40 名は Lao Huang** に直接報告されており、これは Meta Xiaozha と Microsoft Xiaona の直属の部下を合わせた数よりも多いです。
Nvidia の元マネージャーは、「Nvidia では、Huang Renxun が実際にすべての製品の最高製品責任者 です。」と明らかにしました。
外部分析によると、この動きにより、Nvidia は自社製品に対する顧客のニーズをより深く理解できるようになり、Nvidia がこの情報をさらなる利益のために利用する可能性があるという懸念も生じています。
また、別の理由として、老黄氏が誰がカードを実際に使用しているのか、誰がカードを貯め込んで使用していないのかを知りたがっているのではないかと考える人もいます。
その主な理由は、ハイエンド GPU の需要と供給のバランスがあまりにもアンバランスであるためで、GPU Utils Web サイトの計算によると、H100** ギャップは 430,000** にも上ります。
著者のClay Pascal氏は、さまざまな既知の情報や噂に基づいて、近い将来AI業界のさまざまなプレーヤーが必要とするH100の数を推定しました。
AI企業側:
クラウド コンピューティング会社:
合計すると432,000になります。
これには、一部の金融会社や、独自のコンピューティング パワー クラスターの展開を開始した JP モルガン チェースやツー シグマなどの他の業界参加者は含まれていません。
そこで問題は、これほど大きな供給ギャップがあると、もっと生産できないのかということです。
Lao Huang もそれを考えましたが、生産能力が行き詰まっています。
**今回、生産能力はどこで行き詰まっているのでしょうか? **
実際、TSMCはすでにNvidia向けの生産計画を調整している。
しかし、それでもそのような大きなギャップを埋めることはできませんでした。
NvidiaのDGXシステム担当副社長兼ゼネラルマネージャーのチャーリー・ボイル氏は、今回はウェハ上にスタックしていないが、TSMCのCoWoSパッケージング技術が生産能力のボトルネックに遭遇していると述べた。
TSMCの生産能力をめぐってNvidiaと競合しているのはAppleであり、9月のカンファレンス前に次世代iPhone用のA17チップを入手することになる。
TSMC は最近、パッケージング プロセスのバックログを通常の状態に戻すには 1.5 年かかると予想されると発表しました。
CoWoS パッケージング技術は TSMC のハウスキーピング技術であり、TSMC がサムスンを破って Apple の独占的なチップファウンドリになれる理由はこれにかかっています。
このテクノロジーによってパッケージ化された製品は高性能と強力な信頼性を備えているため、H100 は 3TB/s (またはそれ以上) の帯域幅を実現できます。
この技術により、厚さわずか 100μm** のシリコン インターポーザー上に複数のチップをパッケージングすることが可能になります。
報道によると、次世代インターポーザーの面積はレチクルの6倍、約5000mm²に達するとのこと。
今のところ、TSMC を除けば、このレベルのパッケージング能力を備えたメーカーはありません。
言うまでもなく、Lao Huang氏はすでに「2番目のH100鋳造工場の追加は検討しない」と述べています。
実際には不可能かもしれません。
Nvidiaは以前にもSamsungと協力したことがあるが、SamsungはNvidia向けのH100シリーズ製品や他の5nmプロセスチップさえも生産したことがない。
このことから、Samsungの技術レベルではNvidiaの最先端GPUに対する技術的ニーズを満たすことができないのではないかと推測する人もいる。
Intelに関しては...5nm製品はまだ登場していないようです。
AMD、はい?
パフォーマンスだけを見れば、AMD は確かにゆっくりと追いつきつつあります。
AMD の最新の MI300X は、192 GB の HBM3 メモリ、5.2 TB/秒の帯域幅を備え、800 億のパラメータ モデルを実行できます。
Nvidia がリリースしたばかりの DGX GH200 は、141 GB の HBM3e メモリと 5 TB/s の帯域幅を備えています。
しかし、これはAMDがすぐにNカードの空きを埋めることができるという意味ではありません—
Nvidia の本当の「堀」は CUDA プラットフォームにあります。
CUDA は完全な開発エコシステムを確立しています。つまり、ユーザーが AMD 製品を購入すると、デバッグに時間がかかります。
あるプライベートクラウド会社の幹部は、1万基のAMD GPUを実験的に導入するために3億ドルを投じるリスクを冒す人はいないだろうと語った。
同幹部は、開発とデバッグのサイクルには少なくとも 2 か月かかる可能性があると考えています。
AI製品の急速な置き換えを背景に、2か月のギャップはどのメーカーにとっても致命的となる可能性があります。
以前、Microsoftがコードネーム「Athena」というAIチップをAMDと共同開発する準備をしているという噂が流れた。
以前、MI200 がリリースされたとき、Microsoft は最初に購入を発表し、クラウド プラットフォーム Azure に導入しました。
たとえば、MSRA の新しい大規模モデル インフラストラクチャ RetNet は、少し前に 512 台の AMD MI200 でトレーニングされました。
ただし、短期間では、Nvidia H100 および A100 が依然として最も主流の選択肢となっています。
## もう一つ
少し前に、Apple が最大 192 GB のメモリ** をサポートする新しい M2 Ultra チップをリリースしたとき、多くの実務者がそれを使って大型モデルを微調整することを楽しみました。
結局のところ、Apple の M シリーズ チップのメモリとビデオ メモリは統合されており、192GB メモリは 192GB ビデオ メモリであり、これは 80GB H100 の 2.4 倍、または 24GB RTX4090 の 8 倍です。
結局のところ、M シリーズ チップの計算能力は AI コンピューティング用に特に最適化されておらず、Everbright ビデオ メモリは役に立ちません。
大型モデルのリファインは主にH100に頼っているようで、H100は求められないものです。
このような状況に直面して、インターネット上では魔法のような「GPU ソング」** まで出回っています。
非常に洗脳されているので、慎重に入力してください。
、再生時間 04:10
GPUソングホーム
参考リンク: [1] [2] [3] [4] [5] [6] [7] [8] [9]