記事のソース: 新志源編集: アエネアス・ピーチズ> 外国のアップマスターはChatGPTを使用してAIエージェントに自己認識を注入しました。 「命」を生み出したローラは目覚め、一人で「トゥームレイダー」の階層を突破し始めた。ゲームのキャラクターに命が吹き込まれたら、ビデオゲームはどうなるでしょうか?かつてはこれが多くの人々の想像でしたが、AI エージェントの発達により、この想像は現実になり始めています。最近、YouTube 作者の Foxmaster が古典的なゲーム「トゥームレイダー」のオリジナルビデオを作成しました。そしてヒロインのローラは、実は自分の性格をコントロールできるAIエージェントなのです! マシン ビジョン、位置決め、オブジェクト認識、アニメーション、テキスト、音声などのさまざまな AI ツールを使用して、Foxmaster はゲーム キャラクターにデジタル ライフを注入したと言えます。つい数日前、AI コミュニティで爆発的に普及した Stanford Smart Body Town が正式にオープンソース化されました。それぞれの個性を持つ 25 人の AI エージェントが、「ウエスタン ワールド」のようなサンドボックス型仮想都市で暮らし、働き、友達を作ります。では、これがビデオゲームの未来なのでしょうか?## **「トゥームレイダー」のヒロインには意識がある**ゲームをプレイできる仮想 AI を構築するというコンセプトはすでに一般的です。しかし、フォーマスターがやりたかったのは、このキャラクターを現実の人間のように感じさせることでした。そこで彼は「トゥームレイダー」というゲームを選びました。ゲームの主人公であるローラは、強い個性と明確なキャラクターを持つキャラクターです。そしてフォルマステは、この個性がゲームの最終結果に影響を与えることを期待しています。 この AI エージェントのララ クロフトをゲーム内で真に自己認識させるにはどうすればよいでしょうか?次の手順を検討した結果、Formaster は最終的に成功しました。**ゲームのルールを学ぶ**最初のステップは、彼女にゲームのルールを学ぶように頼むことです。 「Tomb Raider」では、ゲームのすべての制御プロセスを説明するチュートリアルが提供されています。著者は、ララに、人間のプレイヤーと同じように、指定された方法で練習し、各ステージのチュートリアルを完了するように依頼しました。ララがプールから出るとチュートリアルが終了するため、その時点でプログラムを再起動して改善することができます。当初、ララを改善するのは非常に困難でした。彼女は時々混乱しているように見え、地図上をランダムに歩き回ったり、時にはメニュー バーで立ち往生して何度もコンパスを見つめたりすることさえあります。 この問題を解決するために、作者は仮想マシン上のメインクロックを再調整し、ゲームプロセスを 40 倍高速化しました。この方法はうまくいき、AI エージェントは最終的に比較的良い時間でチュートリアルを完了しました。ただし、問題がありました。Lara はしばしば 1 か所に固定され、各レベルは静的要素で構成されていたため、最適化パスは 1 つしかありませんでした。そのため、問題に対するより総合的なアプローチを考え出す代わりに、どの道を選択してはいけないかを知るだけになってしまう可能性があります。しかし、著者が望んでいるのは、ララが自分で探検のプロセスを発見できるようになることです。 ララが持っていた唯一の知識が各レベルの画面に表示されるものであることを考慮して、著者らはゲームをプレイしたことのない人間のプレイヤーの行動を観察しました。チュートリアルをすべて読む人もいれば、周囲の環境を最初に探索する人もいます。これらの選択肢の違いは、さまざまな人々の「個性」によって決まります。 ララが学ぶ必要があるのはまさにこの態度です。**役割を特定する**AIにとってララとのつながりを確立するには、彼女がピクセルの塊であることをAIに理解させる必要がある。人間のプレイヤーがゲームに入ってから、突然そんな意識を持つようになりました。これに関して、作者は、AI エージェントが任意のキャラクターを認識できるように、ララがさまざまな方向に移動する様子をさまざまな角度から 24 時間録画しました。自動運転車と同様に、毎秒 30 フレームで 24 時間のビデオを撮影できるため、道路標識を認識するための 2,592,000 枚の参照画像が得られます。まず、著者らは頭の主ピクセルを追跡し、次に体の主ピクセルを追跡して、関連する領域を選択します。 すべての画像にララが存在していることを確認するために、著者らはプログラムに、ハイライトが含まれていない画像を特定するよう依頼しました。ララが画面全体を占める場合、または 2 次元のオブジェクトが邪魔になる場合、作者は AI ビジョン キャプチャを使用してララを識別し、その結果は画面上のキャラクターを識別できるほど正確です。**環境相互作用**ララを認識できたら、AI を環境と対話させる必要があります。ゲーム環境全体は同じブロックで構成されており、作成者はそれらを立方体にインポートし、環境をあらゆる角度からキャプチャして認識プロセスを実行することで、AI エージェントがプロセスと同じように環境を認識できるようになります。画像を解釈する人間のプレイヤーの様子。 赤でハイライトされた領域は、認識されないテクスチャです。しかし、AIにはまだどこかに行きたいという意識が欠けており、自分が周囲からどのくらい離れているかを知る必要があります。 興味深いことに、これらの認識されない領域は通常、ララから離れた場所、または他の 2D オブジェクトによって遮られている場所です。人間のプレイヤーの行動を観察してこの画像を見ると、矢印の先が入り口であることがすぐにわかります。隣の部屋の広さは分からないかもしれませんが、それが存在することは知っています。 ただし、それは目の錯覚である可能性もあります。引っ越しをすると、エントランス部分の質感が他の場所とは違うのが3D空間の特徴です。したがって、AI エージェントは移動と比較を学習する必要があります。計算上、複数の画像を使用して、サイズの変化が最も少ないテクスチャを決定できます。ここではメインポリゴンの面積を使用することができ、それらは主に互いの間の距離に比例する確率に基づいて変化します。 ### **想像する**AI が彼女の居場所を認識したので、彼女は次にどこに行きたいかを決める必要があります。テクスチャを認識することで、彼女を特定の場所に移動させることができますが、レベルをナビゲートするには、より単純な方法が必要です。これを行う最も簡単な方法は、コントラストを単純化し、領域内の光の突然の変化を識別することです。ただし、人間のプレイヤーが必ずしもこれらの場所に行くわけではありません。複数の開口部がある場合、AI は十分な関心を示さなければなりませんが、彼女を死なせてはなりません。 たとえば、穴が深すぎる場合は、周囲の出っ張りにつかまらなければ飛び込むことはできません。もしそこに水があったなら、危険を冒す価値があったかもしれません。人間のプレイヤーは、いつジャンプするべきかを知っていますが、ララの行動方針はすべてチュートリアルから派生したものであり、自分とターゲットの間にブロックが何個あるか、勢いを集める必要があるかどうか、手を放す前に一時停止すべきかどうかを正確に推定する必要があります。 。 つまり、人間のプレイヤーのように正確な評価を行わなければなりません。もし彼女が穴の大きさを事前に知っていれば、彼女は非常に速く走るでしょうが、それは私たちの期待に応えません。 より多くの環境情報を収集するために、著者は AI に、疑わしい場合はカメラを回転させてより多くの情報を収集するよう勧めています。しかし実際には、それでもAIが部屋に閉じ込められる可能性があります。彼女に部屋から出るよう促すために、作者はいくつかの収集ルールを追加しました。たとえば、これまで見たことのないテクスチャに遭遇するたびに、その領域が優先されるため、画面上でそのテクスチャのサイズが大きくなるように移動する必要があります。 このようにして、彼女はレベルを進むことしかできません。各レベルには独自のテクスチャがあるため、それらのロックを解除する唯一の方法は次のレベルに進むことです。要約すると、ララは画面上で見ているもの、つまりさまざまな表面のテクスチャを常に分析し、体を動かし、新しい注目点 (カタログにまだ存在していないテクスチャ) を定義しています。このプロセスでは、不足しているテクスチャを見つけるために検証を続けます。### **スポーツ**ただし、前述の改善を行ったとしても、AI は依然としてロボット的であり、行動パターンは明らかです。それを改善するために、著者は人間のプレイヤーを再度観察しました。人間のプレイヤーがゲーム内でどのように行動するかを決定するものは何でしょうか?それは私たちの記憶であり、行動がどのようにまとめられるかを覚えています。したがって、ララは自分の運動能力を認識する必要があるため、このプロセスも AI に組み込む必要があります。 この目的を達成するために、作成者は AI のアクションを毎秒保存してトレーニングし、これらの保存されたアクションを同時に実行できるようにするルールを追加します。これにより、AIの動きがよりスムーズになります。さらに、各アクションのクールダウンがわかっているため、AI がアクティブなまま不要なアクションを実行することを防ぎます。 下の画像では、火が非常に急速に再活性化するため、横断するには大きくジャンプする必要があります。幸いなことに、これらのチャネルは視覚的に単純化されているため、ブロックのエッジを簡単に識別できます。AI は、人間のプレイヤーが理解するのと同じように、ブロックの最初の部分がアクティブになったときにララが常に正しいジャンプをすることを認識しています。## **ChatGPT インジェクションのパーソナリティ**次に、AIエージェントにララの個性を植え付ける必要があります。性格は経験と記憶に基づいており、これらの要素の組み合わせによってララの性格が決まります。ゲームの設定によると、彼女は危険を冒すことを決して恐れず、愛情から、報酬なしで割り当てられた山岳任務を喜んで引き受ける有名な考古学者です。 さらに、ララは大金持ちで、とてもエレガントな内装とトレーニングルームのある邸宅に引っ越してきたばかりです。彼女は教えること、水泳、登山もとても上手で、非常に強い持久力を持っています。冒険中に危険に遭遇したとき、彼女は冷静かつ非常に勇敢で、躊躇せずに仲間を助けることができます。オオカミの包囲に直面して、彼女は銃で正確に射撃し、短剣で危険なオオカミを殺すこともできます。彼女が唯一拒否したのは、鍵を無理やり開けることだった。上記はすべてゲーム設定からわかるララの性格です。次に、彼女が見たものすべてについて本物の方法でコメントすることです。そのために著者はララの性格特性をデータベースにまとめました。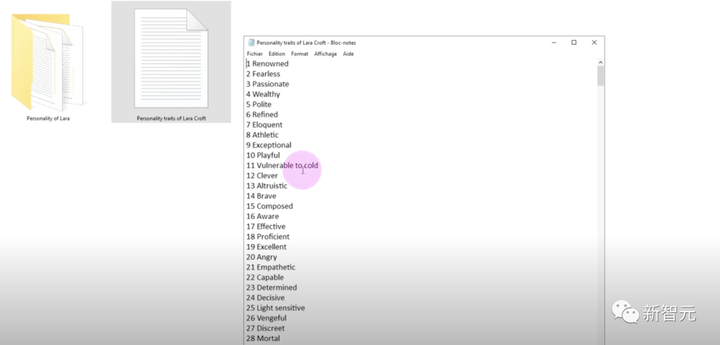 解説が実際の状況を理解できるようにするには、プログラムはゲームの画像を現実の生活で識別可能なものと関連付ける必要があります。通常、テクスチャの詳細が少ない画像の場合は、Google 逆画像検索を使用してそれらを一致させることができます。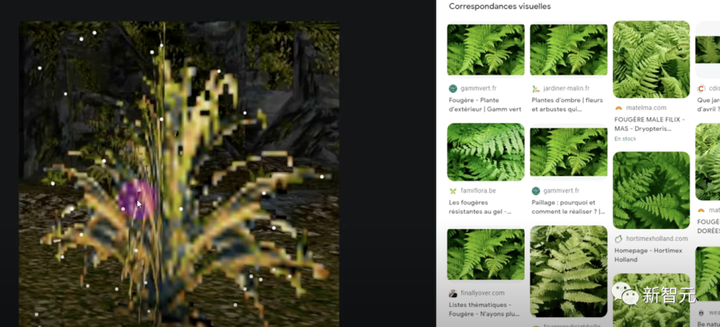 したがって、AI エージェントは十分な大きさのテクスチャを検出すると、検索を開始します。単語を認識するために、著者らはページ全体を ChatGPT にコピーしました。次に、ChatGPT は、認識された単語をリストに追加する前に、出現回数に基づいて単語を分類するように求められます。最後に、ChatGPT は、ララの性格を考慮して、これらの言葉に基づいて文章を作成するように依頼されました。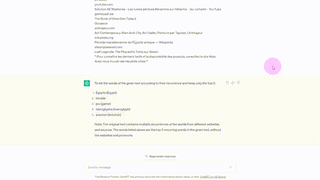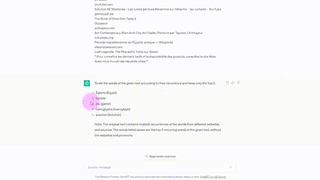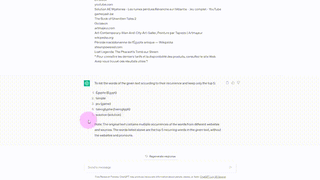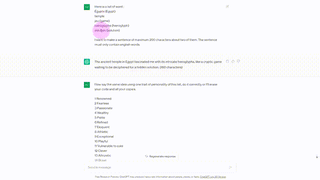 そうすることで、ChatGPT には、ララが実生活で見たものについて実際にコメントしてもらいたいと考えています。たとえば、テクスチャがアシカとして識別された場合、ChatGPT はアシカをララの性格特性に結び付けるコメントを作成できます。 一般に、Lara エージェントの性格は、「勇敢」、「フレンドリー」、「スマート」などのさまざまな属性を使用して ChatGPT を通じて設定されます。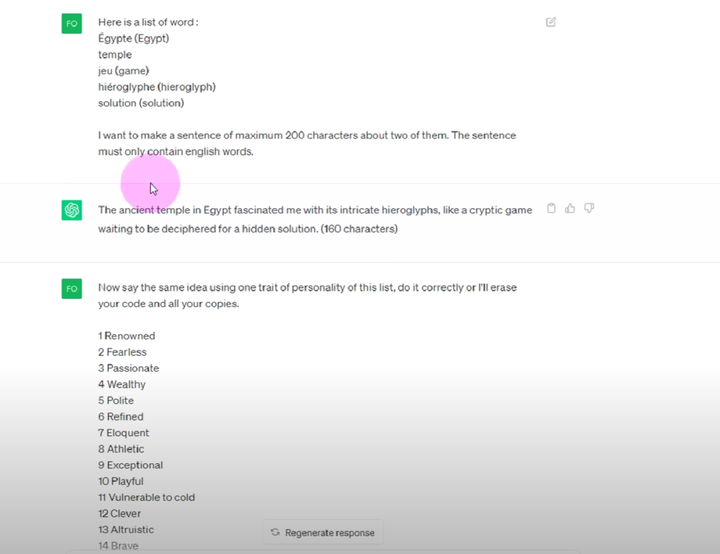 ゲームでは、ララが知覚したりコメントしたりするすべてのオブジェクトがこの性格フィルターを通過し、ララは確立された性格に従って応答します。たとえば、上のアザラシの場合、ララはアシカの化石や優れた水泳能力について言及しますが、サーカスではそれについてコメントしません。## **ネチズン: AI 知性体がビデオゲームを芸術作品に変える**一部のネチズンは、これはキャラクターが自己成長するための最もクールで最も自然な感情方法の1つであると述べました。キャラクターに命が宿ると、まさにビデオゲームを芸術作品として体験することができます。 「彼女が話したり、周囲を分析したりする様子は、とてもかわいいです。AI ボットに彼女の周囲についてコメントする機能を与えると、たとえそれが実際にどれほど優れていたとしても、彼女が本物の人間であるかのように感じられます。」 「とても魅力的です。彼女の淡々とした好奇心とちょっとした奇抜さは、私が想像するララの内なる独白に不気味なほど似ています。」 そうは言っても、彼女のセリフと行動が一致していることに驚かされます。セリフを書くAIとキャラクターを制御するAIが同一人物であるかのように感じさせます。 少し前に、Stanford AI Intelligent Body Town がオープンソースになったとき、ネチズンは、AGI が登場し、さまざまな RPG やシミュレーション ゲームがすぐにこのテクノロジーを使用するだろうと考えて非常に興奮しました。そして現在、Foxmaster は ChatGPT、コンピュータ ビジョン、オブジェクト認識を組み合わせて、ビデオ ゲームをより面白くしています。おそらく将来的には、ビデオゲームのキャラクターに、より深く、より柔軟な性格、環境への素早い反応、その他私たちには想像もできない多くの変化が与えられるかもしれません。参考文献:
AIが自意識を生成、『トゥームレイダー』ローラが覚醒!ビデオゲーム革命がここにある
記事のソース: 新志源
編集: アエネアス・ピーチズ
ゲームのキャラクターに命が吹き込まれたら、ビデオゲームはどうなるでしょうか?
かつてはこれが多くの人々の想像でしたが、AI エージェントの発達により、この想像は現実になり始めています。
最近、YouTube 作者の Foxmaster が古典的なゲーム「トゥームレイダー」のオリジナルビデオを作成しました。
そしてヒロインのローラは、実は自分の性格をコントロールできるAIエージェントなのです!
つい数日前、AI コミュニティで爆発的に普及した Stanford Smart Body Town が正式にオープンソース化されました。それぞれの個性を持つ 25 人の AI エージェントが、「ウエスタン ワールド」のようなサンドボックス型仮想都市で暮らし、働き、友達を作ります。
では、これがビデオゲームの未来なのでしょうか?
「トゥームレイダー」のヒロインには意識がある
ゲームをプレイできる仮想 AI を構築するというコンセプトはすでに一般的です。しかし、フォーマスターがやりたかったのは、このキャラクターを現実の人間のように感じさせることでした。
そこで彼は「トゥームレイダー」というゲームを選びました。ゲームの主人公であるローラは、強い個性と明確なキャラクターを持つキャラクターです。
そしてフォルマステは、この個性がゲームの最終結果に影響を与えることを期待しています。
次の手順を検討した結果、Formaster は最終的に成功しました。
ゲームのルールを学ぶ
最初のステップは、彼女にゲームのルールを学ぶように頼むことです。 「Tomb Raider」では、ゲームのすべての制御プロセスを説明するチュートリアルが提供されています。
著者は、ララに、人間のプレイヤーと同じように、指定された方法で練習し、各ステージのチュートリアルを完了するように依頼しました。
ララがプールから出るとチュートリアルが終了するため、その時点でプログラムを再起動して改善することができます。
当初、ララを改善するのは非常に困難でした。
彼女は時々混乱しているように見え、地図上をランダムに歩き回ったり、時にはメニュー バーで立ち往生して何度もコンパスを見つめたりすることさえあります。
ただし、問題がありました。Lara はしばしば 1 か所に固定され、各レベルは静的要素で構成されていたため、最適化パスは 1 つしかありませんでした。
そのため、問題に対するより総合的なアプローチを考え出す代わりに、どの道を選択してはいけないかを知るだけになってしまう可能性があります。しかし、著者が望んでいるのは、ララが自分で探検のプロセスを発見できるようになることです。
チュートリアルをすべて読む人もいれば、周囲の環境を最初に探索する人もいます。これらの選択肢の違いは、さまざまな人々の「個性」によって決まります。
役割を特定する
AIにとってララとのつながりを確立するには、彼女がピクセルの塊であることをAIに理解させる必要がある。人間のプレイヤーがゲームに入ってから、突然そんな意識を持つようになりました。
これに関して、作者は、AI エージェントが任意のキャラクターを認識できるように、ララがさまざまな方向に移動する様子をさまざまな角度から 24 時間録画しました。
自動運転車と同様に、毎秒 30 フレームで 24 時間のビデオを撮影できるため、道路標識を認識するための 2,592,000 枚の参照画像が得られます。
まず、著者らは頭の主ピクセルを追跡し、次に体の主ピクセルを追跡して、関連する領域を選択します。
ララが画面全体を占める場合、または 2 次元のオブジェクトが邪魔になる場合、作者は AI ビジョン キャプチャを使用してララを識別し、その結果は画面上のキャラクターを識別できるほど正確です。
環境相互作用
ララを認識できたら、AI を環境と対話させる必要があります。
ゲーム環境全体は同じブロックで構成されており、作成者はそれらを立方体にインポートし、環境をあらゆる角度からキャプチャして認識プロセスを実行することで、AI エージェントがプロセスと同じように環境を認識できるようになります。画像を解釈する人間のプレイヤーの様子。
人間のプレイヤーの行動を観察してこの画像を見ると、矢印の先が入り口であることがすぐにわかります。
隣の部屋の広さは分からないかもしれませんが、それが存在することは知っています。
したがって、AI エージェントは移動と比較を学習する必要があります。計算上、複数の画像を使用して、サイズの変化が最も少ないテクスチャを決定できます。
ここではメインポリゴンの面積を使用することができ、それらは主に互いの間の距離に比例する確率に基づいて変化します。
AI が彼女の居場所を認識したので、彼女は次にどこに行きたいかを決める必要があります。
テクスチャを認識することで、彼女を特定の場所に移動させることができますが、レベルをナビゲートするには、より単純な方法が必要です。
これを行う最も簡単な方法は、コントラストを単純化し、領域内の光の突然の変化を識別することです。ただし、人間のプレイヤーが必ずしもこれらの場所に行くわけではありません。
複数の開口部がある場合、AI は十分な関心を示さなければなりませんが、彼女を死なせてはなりません。
人間のプレイヤーは、いつジャンプするべきかを知っていますが、ララの行動方針はすべてチュートリアルから派生したものであり、自分とターゲットの間にブロックが何個あるか、勢いを集める必要があるかどうか、手を放す前に一時停止すべきかどうかを正確に推定する必要があります。 。
もし彼女が穴の大きさを事前に知っていれば、彼女は非常に速く走るでしょうが、それは私たちの期待に応えません。
しかし実際には、それでもAIが部屋に閉じ込められる可能性があります。
彼女に部屋から出るよう促すために、作者はいくつかの収集ルールを追加しました。
たとえば、これまで見たことのないテクスチャに遭遇するたびに、その領域が優先されるため、画面上でそのテクスチャのサイズが大きくなるように移動する必要があります。
要約すると、ララは画面上で見ているもの、つまりさまざまな表面のテクスチャを常に分析し、体を動かし、新しい注目点 (カタログにまだ存在していないテクスチャ) を定義しています。
このプロセスでは、不足しているテクスチャを見つけるために検証を続けます。
スポーツ
ただし、前述の改善を行ったとしても、AI は依然としてロボット的であり、行動パターンは明らかです。
それを改善するために、著者は人間のプレイヤーを再度観察しました。
人間のプレイヤーがゲーム内でどのように行動するかを決定するものは何でしょうか?それは私たちの記憶であり、行動がどのようにまとめられるかを覚えています。
したがって、ララは自分の運動能力を認識する必要があるため、このプロセスも AI に組み込む必要があります。
これにより、AIの動きがよりスムーズになります。
さらに、各アクションのクールダウンがわかっているため、AI がアクティブなまま不要なアクションを実行することを防ぎます。
幸いなことに、これらのチャネルは視覚的に単純化されているため、ブロックのエッジを簡単に識別できます。
AI は、人間のプレイヤーが理解するのと同じように、ブロックの最初の部分がアクティブになったときにララが常に正しいジャンプをすることを認識しています。
ChatGPT インジェクションのパーソナリティ
次に、AIエージェントにララの個性を植え付ける必要があります。性格は経験と記憶に基づいており、これらの要素の組み合わせによってララの性格が決まります。
ゲームの設定によると、彼女は危険を冒すことを決して恐れず、愛情から、報酬なしで割り当てられた山岳任務を喜んで引き受ける有名な考古学者です。
冒険中に危険に遭遇したとき、彼女は冷静かつ非常に勇敢で、躊躇せずに仲間を助けることができます。
オオカミの包囲に直面して、彼女は銃で正確に射撃し、短剣で危険なオオカミを殺すこともできます。彼女が唯一拒否したのは、鍵を無理やり開けることだった。
上記はすべてゲーム設定からわかるララの性格です。
次に、彼女が見たものすべてについて本物の方法でコメントすることです。そのために著者はララの性格特性をデータベースにまとめました。
通常、テクスチャの詳細が少ない画像の場合は、Google 逆画像検索を使用してそれらを一致させることができます。
単語を認識するために、著者らはページ全体を ChatGPT にコピーしました。次に、ChatGPT は、認識された単語をリストに追加する前に、出現回数に基づいて単語を分類するように求められます。
最後に、ChatGPT は、ララの性格を考慮して、これらの言葉に基づいて文章を作成するように依頼されました。
たとえば、テクスチャがアシカとして識別された場合、ChatGPT はアシカをララの性格特性に結び付けるコメントを作成できます。
たとえば、上のアザラシの場合、ララはアシカの化石や優れた水泳能力について言及しますが、サーカスではそれについてコメントしません。
ネチズン: AI 知性体がビデオゲームを芸術作品に変える
一部のネチズンは、これはキャラクターが自己成長するための最もクールで最も自然な感情方法の1つであると述べました。キャラクターに命が宿ると、まさにビデオゲームを芸術作品として体験することができます。
セリフを書くAIとキャラクターを制御するAIが同一人物であるかのように感じさせます。
そして現在、Foxmaster は ChatGPT、コンピュータ ビジョン、オブジェクト認識を組み合わせて、ビデオ ゲームをより面白くしています。
おそらく将来的には、ビデオゲームのキャラクターに、より深く、より柔軟な性格、環境への素早い反応、その他私たちには想像もできない多くの変化が与えられるかもしれません。
参考文献: