元のソース: Qubit 画像ソース: Unbounded AI によって生成人間のデータが不足しており、AI が生成したデータを AI が食べ始めることになります。これが、**Microsoft** や **OpenAI** などの AI 最先端企業が直面している現状です。彼らは、Wikipedia、電子書籍、ニュース サイト、ブログ、Twitter、Reddit などのプラットフォームやフォーラムから大量のデータを収集しましたが、今ではデータが枯渇しつつあります。 しかし、より優れた大規模モデルをトレーニングするには、データがいくらあっても十分ではありません。「フィナンシャル・タイムズ」紙によると、多くの企業が大規模モデルで生成された結果、いわゆる**合成データ**(合成データ)をより小さいパラメータを持つ大規模モデルにフィードしており、その結果は悪くないことが判明したという。合成データの使用について、**OpenAI** CEO のサム アルトマンは気にしないだけでなく、「**将来のすべてのデータは合成データになる**」と述べています。評価額20億ドルのビッグモデル新興企業Cohereも合成データを利用している。同社の CEO であり、古典的な大型モデルのトランスフォーマー論文の著者の 1 人であるエイダン ゴメス氏は、次のようにさえ信じています。> 合成データは、「**超インテリジェント**」AI システムへの道を加速する可能性があります。では、どの大規模モデルがすでに合成データを使用しているのでしょうか?また、これらの合成データはどこから来たのでしょうか?## **大きな AI はデータを合成し、小さな AI はデータを食べる**これらのいわゆる **合成データ**は、本質的には、**手動調整**後に、より優れたパフォーマンスを備えた現在の大規模モデルによって生成されたデータであり、その後、わずかに小さい大規模モデルに供給されます。たとえば、Cohere は 2 つの大きなモデルを使用して「ロールプレイング」対話を実行し、それらによって生成された結果を合成データにしようとしました。この2つの大型モデルはそれぞれ「数学の先生」と「生徒」の役割を果たし、仮想の数学指導授業を行っています。一方、Cohere は対話の生成を監督するために人間の従業員を傍観者に配置しました。 会話がうまくいかないたびに、人間が介入してテキストを**修正**します。人手は必要ですが、科学、医学、ビジネスの専門家を雇って文章を書くよりもはるかに安価です。では、どのような大規模モデルがこれらの合成データを使用するのでしょうか?Microsoft Research の最近の研究では、合成データを使用して GPT-4 または PaLM-2** よりわずかに小さい言語モデルをトレーニングできることが示されました。GPT-4 によって生成された「4 歳児小説」データ セット **TinyStories** を例に挙げます。このデータ セットには、4 歳児が理解できる単語のみが含まれていることが証明されていますが、トレーニング後は大きなモデル、同じ 文法的に正しく、スムーズに読めるストーリー: 合成データを使用する理由について、Cohere CEO の Aidan Gomez 氏は次のように考えています。> もちろんインターネットからデータが取得できればそれに越したことはありませんが、ネットワークのデータが乱雑すぎて全くニーズを満たせません。対照的に、合成データは、広く普及していなくても、すでに豊富に存在します。## **背後にある産業チェーンが出現**現在、Scale AIやGretel.aiなどの企業が合成データサービスを外部に提供し始めている。まず、**Scale AI** は、企業に合成データ サービスを提供するために、合成データ製品 Scale Synthetic を発売しました。SemiAnalysis が GPT-4 の「ビッグレース」に関するニュースを発表した前回のニュースでは、GPT-4 データセットには Scale AI と内部命令の微調整データからの数百万行が含まれていることにも言及しました。 合成データ プラットフォーム **Gretel.ai** については、公式 Web サイトから引用すると、Google、Riot Games、HSBC などのさまざまな企業と協力して、他の開発者が使用できる合成データをさらに生成しています。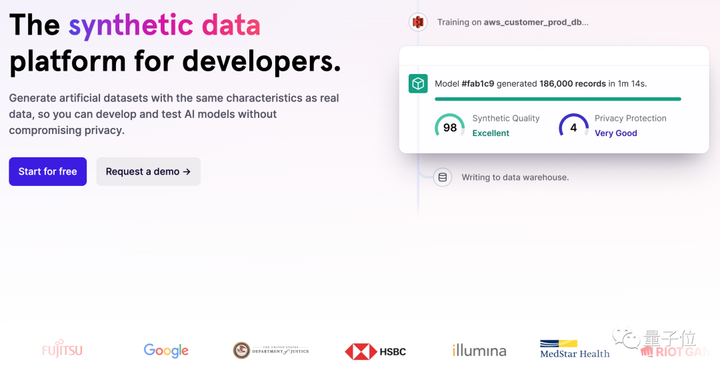 Gretel.ai の CEO、Ali Golshan 氏は、合成データの利点は、統計的な整合性を維持しながら、データセット内のすべての個人のプライバシーを保護できることであると考えています。しかし、すべての人が合成データの「魔法のような操作」を受け入れているわけではなく、現在、各関係者の意見は主に 2 つの波に分かれています。合成データの使用を**承認**する人もいます。 CohereのようなAI企業を含め、大規模モデルに携わる多くの企業は今でもこのアプローチに固執しており、それがより優れたAIを生成し、さらには「超知能」を生み出す可能性があると信じています。別の部分では、合成データによって最終的には AI が「**自分自身を食べさせる**」ことができるようになると考えています。たとえば、オックスフォード大学、ケンブリッジ大学、インペリアル カレッジ、トロント大学、エディンバラ大学、および Vector Institute の研究では次のことが示されています。> 合成データを使用してトレーニングすると、モデルに不可逆的な欠陥が発生します。> **忘れてください**、最終的に自己生成データによって汚染される「ありえない出来事」を考えてください。 一部のネチズンは、これらの合成データは最終的には「使用不可能な汚泥」のプールになり、それを *浄化**するためにデータ サイエンティストを雇わなければならなくなると信じています。 一部のネチズンは、これが「**AI 近親交配**」のように聞こえると嘲笑しました。 AI は合成データを使用する必要があると思いますか?参考リンク:[1][2][3][4]
人間のデータは急いでいる、Microsoft OpenAIはAIにAIを供給し始めた、アルトマン氏「将来的にはすべてのデータが合成データになる」
元のソース: Qubit
人間のデータが不足しており、AI が生成したデータを AI が食べ始めることになります。
これが、Microsoft や OpenAI などの AI 最先端企業が直面している現状です。
彼らは、Wikipedia、電子書籍、ニュース サイト、ブログ、Twitter、Reddit などのプラットフォームやフォーラムから大量のデータを収集しましたが、今ではデータが枯渇しつつあります。
「フィナンシャル・タイムズ」紙によると、多くの企業が大規模モデルで生成された結果、いわゆる合成データ(合成データ)をより小さいパラメータを持つ大規模モデルにフィードしており、その結果は悪くないことが判明したという。
合成データの使用について、OpenAI CEO のサム アルトマンは気にしないだけでなく、「将来のすべてのデータは合成データになる」と述べています。
評価額20億ドルのビッグモデル新興企業Cohereも合成データを利用している。同社の CEO であり、古典的な大型モデルのトランスフォーマー論文の著者の 1 人であるエイダン ゴメス氏は、次のようにさえ信じています。
では、どの大規模モデルがすでに合成データを使用しているのでしょうか?また、これらの合成データはどこから来たのでしょうか?
大きな AI はデータを合成し、小さな AI はデータを食べる
これらのいわゆる 合成データは、本質的には、手動調整後に、より優れたパフォーマンスを備えた現在の大規模モデルによって生成されたデータであり、その後、わずかに小さい大規模モデルに供給されます。
たとえば、Cohere は 2 つの大きなモデルを使用して「ロールプレイング」対話を実行し、それらによって生成された結果を合成データにしようとしました。
この2つの大型モデルはそれぞれ「数学の先生」と「生徒」の役割を果たし、仮想の数学指導授業を行っています。一方、Cohere は対話の生成を監督するために人間の従業員を傍観者に配置しました。
人手は必要ですが、科学、医学、ビジネスの専門家を雇って文章を書くよりもはるかに安価です。
では、どのような大規模モデルがこれらの合成データを使用するのでしょうか?
Microsoft Research の最近の研究では、合成データを使用して GPT-4 または PaLM-2** よりわずかに小さい言語モデルをトレーニングできることが示されました。
GPT-4 によって生成された「4 歳児小説」データ セット TinyStories を例に挙げます。このデータ セットには、4 歳児が理解できる単語のみが含まれていることが証明されていますが、トレーニング後は大きなモデル、同じ 文法的に正しく、スムーズに読めるストーリー:
背後にある産業チェーンが出現
現在、Scale AIやGretel.aiなどの企業が合成データサービスを外部に提供し始めている。
まず、Scale AI は、企業に合成データ サービスを提供するために、合成データ製品 Scale Synthetic を発売しました。
SemiAnalysis が GPT-4 の「ビッグレース」に関するニュースを発表した前回のニュースでは、GPT-4 データセットには Scale AI と内部命令の微調整データからの数百万行が含まれていることにも言及しました。
しかし、すべての人が合成データの「魔法のような操作」を受け入れているわけではなく、現在、各関係者の意見は主に 2 つの波に分かれています。
合成データの使用を承認する人もいます。 CohereのようなAI企業を含め、大規模モデルに携わる多くの企業は今でもこのアプローチに固執しており、それがより優れたAIを生成し、さらには「超知能」を生み出す可能性があると信じています。
別の部分では、合成データによって最終的には AI が「自分自身を食べさせる」ことができるようになると考えています。
たとえば、オックスフォード大学、ケンブリッジ大学、インペリアル カレッジ、トロント大学、エディンバラ大学、および Vector Institute の研究では次のことが示されています。
参考リンク: [1] [2] [3] [4]