元のソース: Qubitビッグバイトモデル、BuboGPTが登場。テキスト、画像、音声の 3 つのモードをサポートし、きめ細かいマルチモーダル共同理解を実現します。どこに答えて何を言うべきか、何が言われ、何が言われないかは一目瞭然です。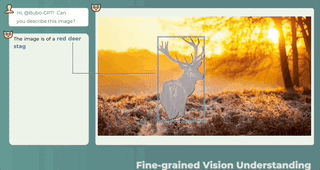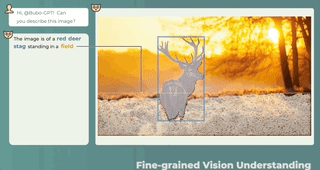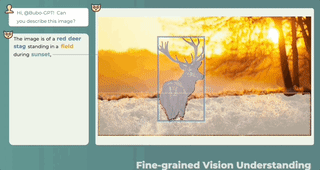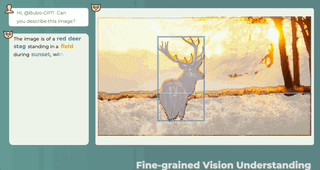 「賢い目」を持つだけでなく「賢い耳」もあります。 BuboGPT は人間が気付かない詳細を聞くことができます。**オーディオ-1-チャイム-バード-ブリーズ**、量子ビット、20 秒 前方に高いエネルギーが!3 つのモーダルの共同理解、テキストの説明 + 画像の位置 + 音声の位置、ワンクリックで取得し、音の発生源を正確に特定します。**オーディオ-7-ドーク-バーク**、量子ビット、6 秒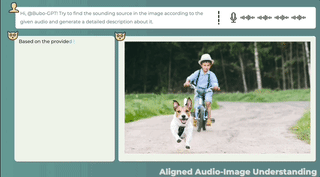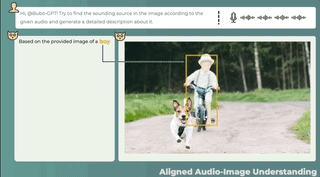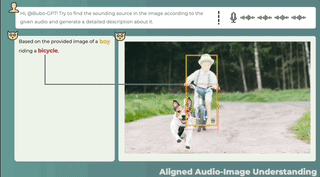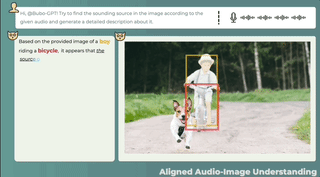 心配しないでください、まだ終わっていません!音声と画像の間に直接の関係がない場合でも、この 2 つの関係の可能性は合理的に説明できます。また、画像を見て音を識別することでストーリーを伝えることも可能です。**オーディオ-11-6時**、量子ビット、1分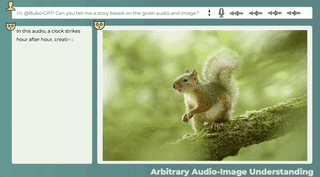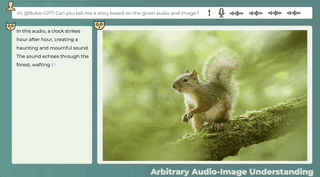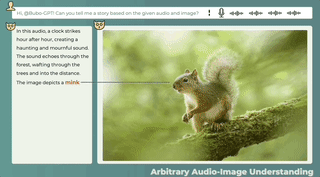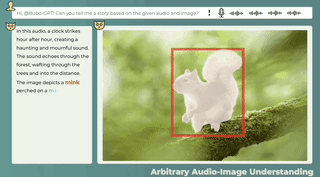 このように見ると、BuboGPT はある程度の作業を行いますが、これは十分「問題ありません」です。研究者らによると、> 最近人気のある MiniGPT-4、LLaVA、X-LLM などのマルチモーダル大規模モデルは、入力の特定部分への基本的な接続を行わず、粗粒マップを構築するだけです。> BuboGPT は豊富な情報とテキストと他のモダリティ間の明確な対応を活用しながら、視覚オブジェクトと特定のモダリティを詳細に理解することができます。したがって、BuboGPT が画像を記述するとき、画像内のオブジェクトの特定の位置を示すことができます。## **BuboGPT: LLM へのビジュアル接続を初めて導入**著者が YouTube で共有した上記の例に加えて、研究チームは論文の中で BuboGPT が実行するさまざまなトリックも実証しました。ピアノを弾くカエルを見るのは久しぶりです!このようなグラフ BuboGPT も正確に記述できるでしょうか? Kangkang は一緒にどう答えましたか。 カエルのポーズを正確に表現できるだけでなく、それが**バンジョー**であることもわかりますか?写真の中で興味深い場所はどこですかと尋ねると、写真の背景にあるものすべてを要約することもできます。BuboGPT「視力 + 聴力 + 表現力テスト」、研究者はこのように再生します。まずこの音声を聞いてみましょう。**オーディオ-9-ヘアドライヤー**、量子ビット、5 秒BuboGPT の説明を見てみましょう。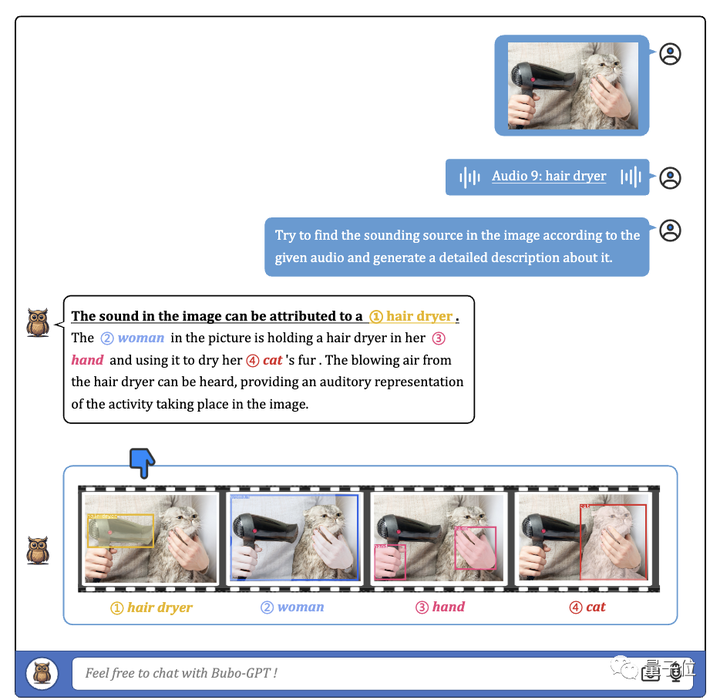 BuboGPT は、写真の中の人物の性別、音の発生源、写真の中で何が起こったかを正確に理解できます。Byteは今回、LLMに視覚的な位置決めを導入する方法を使用したため、その効果は非常に優れています。次に具体的な方法を見ていきます。BuboGPT のアーキテクチャは、共有された意味論的空間を学習し、さまざまな視覚オブジェクトとさまざまなモダリティの間のきめ細かい関係をさらに探索することによって、マルチモーダルな理解を達成することです。さまざまな視覚オブジェクトとさまざまなモダリティの間のきめ細かい関係を調査するために、研究者らはまず、SAM に基づいて既製の視覚ローカリゼーション パイプラインを構築しました。このパイプラインは、**Tagging Module** (タグ付けモジュール)、**Location Module** (Grounding Module)、および **Entity-matching Module** (Entity-matching Module) の 3 つのモジュールで構成されています。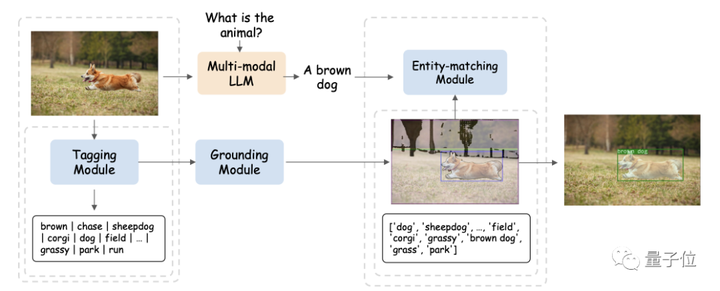 プロセスは大まかに次のとおりです。まず、ラベリング モジュールは、入力画像に関連付けられた複数のテキスト ラベルを生成できる事前トレーニングされたモデルです。SAM ベースのローカリゼーション モジュールは、画像上の各テキスト ラベルに関連付けられたセマンティック マスクまたはバウンディング ボックスをさらにローカライズします。次に、エンティティ マッチング モジュールは LLM の推論機能を利用して、ラベルと画像の説明から一致するエンティティを取得します。このようにして、研究者は視覚オブジェクトを他のモダリティに接続するための橋渡しとして言語を使用します。3 つのモードを任意に組み合わせて入力しても良好な結果が得られるようにするために、研究者らは Mini-GTP4 と同様の 2 段階のトレーニング スキームを採用しました。**単一モーダルの事前トレーニングとマルチモーダルの指導調整**。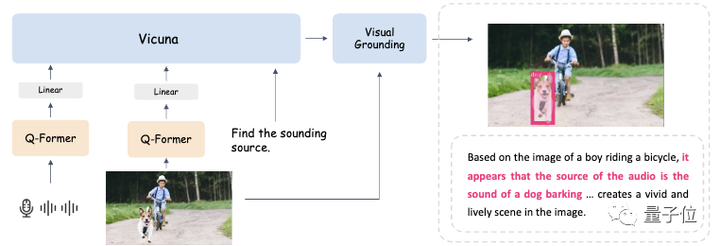 具体的には、BuboGPT はオーディオ エンコーダーとして ImageBind、ビジュアル エンコーダーとして BLIP-2、事前トレーニングされた LLM として Vicuna を使用します。ユニモーダル事前トレーニング段階では、対応するモダリティ Q-Former レイヤーと線形投影レイヤーが、モダリティとテキストのペアになった大量のデータでトレーニングされます。視覚に関しては、画像キャプション生成部分の投影レイヤーのみをトレーニングし、BLIP2 の Q-Former を固定したままにします。音声を理解するために、Q-Former と音声キャプション生成部分の両方をトレーニングしました。どちらの設定でも、ヒント ( ) を使用せず、モデルは対応する画像または音声を入力として受け取り、対応するキャプション (キャプション) を予測します。######**  **###### **△** 別の入力命令は例に従ってくださいマルチモーダル命令調整ステージでは、次のような線形投影レイヤーを微調整するために、高品質のマルチモーダル命令データセットが構築されます。* Image-Text: MiniGPT-4 と LLaVa の 2 つのデータセットを使用した視覚的な命令のチューニング。* オーディオテキスト: 一連の表現的で説明的なデータは、Clotho データセットに基づいて構築されます。* 音声-画像-テキスト: VGGSS データセットに基づいて、<音声、画像、テキスト> 3 モーダル ガイダンス調整データ ペアが構築され、モデルを強化するためにネガティブ サンプルがさらに導入されます。セマンティックマッチングにネガティブサンプル「画像と音声のペア」を導入することで、BuboGPT の位置合わせが向上し、マルチモーダルな共同理解能力が強化されることは注目に値します。現在、BuboGPTのコードとデータセットはオープンソース化されており、デモも公開されているので、早速試してみましょう。## **浅いプレイ体験のデモ**BuboGPT デモページの機能エリアは一目瞭然で、操作も非常に簡単で、右側では写真や音声をアップロードでき、左側では BuboGPT の回答ウィンドウとユーザーの質問ウィンドウが表示されます。 写真をアップロードした後、下の最初のボタンをクリックして分割画像をアップロードします。 例として万里の長城の写真を取ると、BuboGPT はそれを次のように分解し、山、観光名所、城壁を特定しました。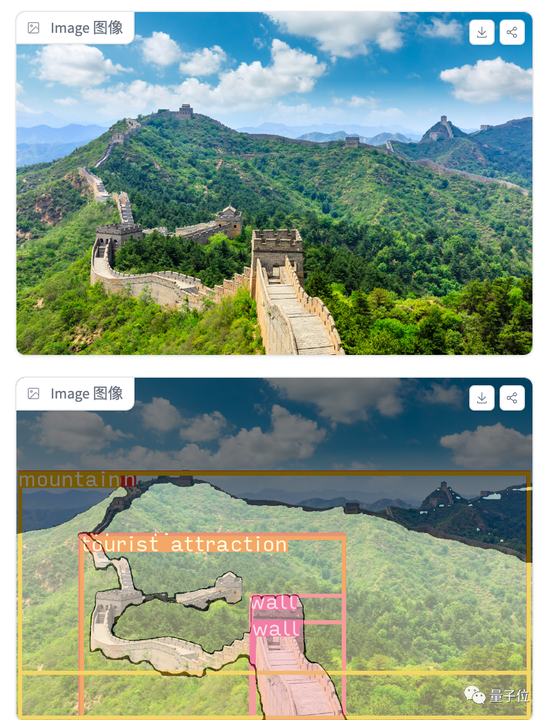 私たちがこの絵について説明するよう尋ねたところ、その答えはより具体的で基本的に正確でした。 回答のテキスト内容に応じて、分割ボックスの内容も変更されていることがわかります。こちらは音声付きの別の画像です。BuboGPT も音源と正しく一致しています。**オーディオ-8-自転車\_ベル**、量子ビット、22 秒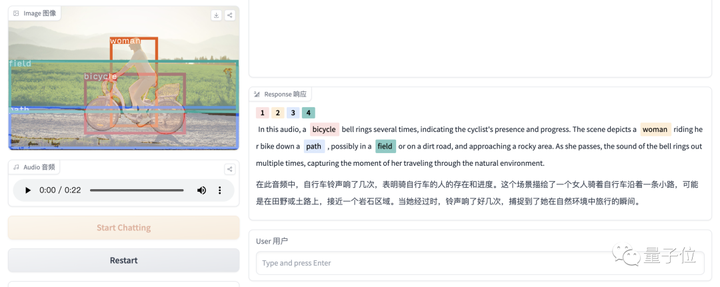 もちろん、認識できずに誤った表現をすることもあります。たとえば、下の写真には誰もいませんし、音声はただのベルですが、その説明は写真と一致していないようです。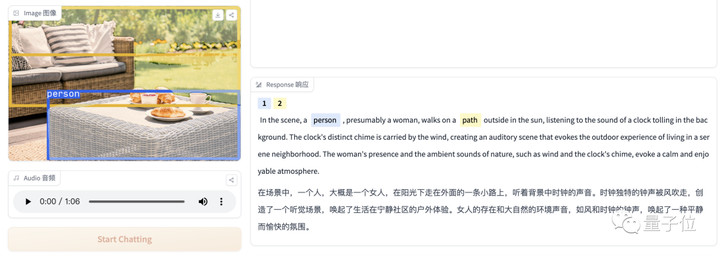 興味のあるご家族は急いで試してみてください~~ポータル:[1][2]
ラージバイトモデルの新開発: 視覚的位置決めの最初の導入により、きめ細かいマルチモーダルジョイントの理解、オープンソースおよびデモプレイ可能を実現
元のソース: Qubit
ビッグバイトモデル、BuboGPTが登場。
テキスト、画像、音声の 3 つのモードをサポートし、きめ細かいマルチモーダル共同理解を実現します。
どこに答えて何を言うべきか、何が言われ、何が言われないかは一目瞭然です。
オーディオ-1-チャイム-バード-ブリーズ、量子ビット、20 秒
3 つのモーダルの共同理解、テキストの説明 + 画像の位置 + 音声の位置、ワンクリックで取得し、音の発生源を正確に特定します。
オーディオ-7-ドーク-バーク、量子ビット、6 秒
音声と画像の間に直接の関係がない場合でも、この 2 つの関係の可能性は合理的に説明できます。また、画像を見て音を識別することでストーリーを伝えることも可能です。
オーディオ-11-6時、量子ビット、1分
研究者らによると、
したがって、BuboGPT が画像を記述するとき、画像内のオブジェクトの特定の位置を示すことができます。
BuboGPT: LLM へのビジュアル接続を初めて導入
著者が YouTube で共有した上記の例に加えて、研究チームは論文の中で BuboGPT が実行するさまざまなトリックも実証しました。
ピアノを弾くカエルを見るのは久しぶりです!このようなグラフ BuboGPT も正確に記述できるでしょうか?
写真の中で興味深い場所はどこですかと尋ねると、写真の背景にあるものすべてを要約することもできます。
BuboGPT「視力 + 聴力 + 表現力テスト」、研究者はこのように再生します。まずこの音声を聞いてみましょう。
オーディオ-9-ヘアドライヤー、量子ビット、5 秒
BuboGPT の説明を見てみましょう。
Byteは今回、LLMに視覚的な位置決めを導入する方法を使用したため、その効果は非常に優れています。
次に具体的な方法を見ていきます。
BuboGPT のアーキテクチャは、共有された意味論的空間を学習し、さまざまな視覚オブジェクトとさまざまなモダリティの間のきめ細かい関係をさらに探索することによって、マルチモーダルな理解を達成することです。
さまざまな視覚オブジェクトとさまざまなモダリティの間のきめ細かい関係を調査するために、研究者らはまず、SAM に基づいて既製の視覚ローカリゼーション パイプラインを構築しました。
このパイプラインは、Tagging Module (タグ付けモジュール)、Location Module (Grounding Module)、および Entity-matching Module (Entity-matching Module) の 3 つのモジュールで構成されています。
まず、ラベリング モジュールは、入力画像に関連付けられた複数のテキスト ラベルを生成できる事前トレーニングされたモデルです。
SAM ベースのローカリゼーション モジュールは、画像上の各テキスト ラベルに関連付けられたセマンティック マスクまたはバウンディング ボックスをさらにローカライズします。
次に、エンティティ マッチング モジュールは LLM の推論機能を利用して、ラベルと画像の説明から一致するエンティティを取得します。
このようにして、研究者は視覚オブジェクトを他のモダリティに接続するための橋渡しとして言語を使用します。
3 つのモードを任意に組み合わせて入力しても良好な結果が得られるようにするために、研究者らは Mini-GTP4 と同様の 2 段階のトレーニング スキームを採用しました。
単一モーダルの事前トレーニングとマルチモーダルの指導調整。
ユニモーダル事前トレーニング段階では、対応するモダリティ Q-Former レイヤーと線形投影レイヤーが、モダリティとテキストのペアになった大量のデータでトレーニングされます。
視覚に関しては、画像キャプション生成部分の投影レイヤーのみをトレーニングし、BLIP2 の Q-Former を固定したままにします。
音声を理解するために、Q-Former と音声キャプション生成部分の両方をトレーニングしました。
どちらの設定でも、ヒント ( ) を使用せず、モデルは対応する画像または音声を入力として受け取り、対応するキャプション (キャプション) を予測します。
** **###### △ 別の入力命令は例に従ってください
**###### △ 別の入力命令は例に従ってください
マルチモーダル命令調整ステージでは、次のような線形投影レイヤーを微調整するために、高品質のマルチモーダル命令データセットが構築されます。
セマンティックマッチングにネガティブサンプル「画像と音声のペア」を導入することで、BuboGPT の位置合わせが向上し、マルチモーダルな共同理解能力が強化されることは注目に値します。
現在、BuboGPTのコードとデータセットはオープンソース化されており、デモも公開されているので、早速試してみましょう。
浅いプレイ体験のデモ
BuboGPT デモページの機能エリアは一目瞭然で、操作も非常に簡単で、右側では写真や音声をアップロードでき、左側では BuboGPT の回答ウィンドウとユーザーの質問ウィンドウが表示されます。
こちらは音声付きの別の画像です。BuboGPT も音源と正しく一致しています。
オーディオ-8-自転車_ベル、量子ビット、22 秒
ポータル: [1] [2]