**編集者: Xiaozhou、Chen Ping****出典:**マシンの心臓部過去 1 年で、ChatGPT や GPT-4 に代表される大規模言語モデル (LLM) が急速に発展し、続いて Meta のオープンソース LLaMa および Llama 2 シリーズ モデルも AI の世界で大きな波紋を巻き起こしました。 。 LLM には制御不能なリスクがあり、人類の生存に潜在的な脅威をもたらすと考える人もいます。これらの課題に対処するために、LLM アライメントの研究はますます重要になっており、一部の研究者は命令フォローイング (命令追従) を提案していますが、この方法では多くの人手によるアノテーションが必要です。ただし、このような高品質の命令追従データセットに注釈を付けるにはコストがかかります。この論文では、**Meta AI の研究者が、命令逆変換**と呼ばれるスケーラブルな手法を提案しています。この手法は、対応する命令に自動的に注釈を付けることで、高品質の命令追従言語モデルを構築します。 用紙のアドレス:具体的には、研究はシード モデルとしての言語モデルから始まり、少量のシード データと Web コーパスで微調整されます。シード モデルの役割は、トレーニング サンプルを構築することです。その後、これらのサンプルから高品質のサンプルがいくつか選別され、これらのデータはより強力なモデルを微調整するために使用されます。LLaMa を 2 回反復してデータセット微調整した後、結果として得られたモデル Humpback は、Alpaca リーダーボードで LIMA、Claude、Guanaco などの他の既存の非蒸留モデルを上回りました。ザトウクジラとはもともとザトウクジラ、別名ザトウクジラを意味し、メタがザトウクジラと名付けたモデルなので深い意味はありません。 研究者らによると、これが命令逆翻訳と呼ばれる理由は、機械翻訳における古典的な逆翻訳手法を利用しているためであり、人間が書いたターゲット文に、モデルが生成した別の言語のソース文で自動的に注釈が付けられるという。 。チューリング賞受賞者のヤン・ルカン氏は、研究方法論の概要を述べ、アライメント研究への重要な貢献としてメタの研究を賞賛した。 一部のネチズンはこの研究をうまく要約しました: データの品質は大規模なモデルにとって非常に重要です. 研究プロセス中、彼らはモデルを微調整するためにさまざまなレベルのフィルタリングされたデータを使用しました. 結果は、最良のサンプルのみを取得することを示しました他のサンプルよりも優れたパフォーマンスを発揮するモデル。このペーパーでは、2 つのステップで完了する必要がある新しいデータ拡張パラダイムを提案します。まず、より優れた命令データを生成するには、シード (命令、出力) ペアのセットとコーパスが必要です。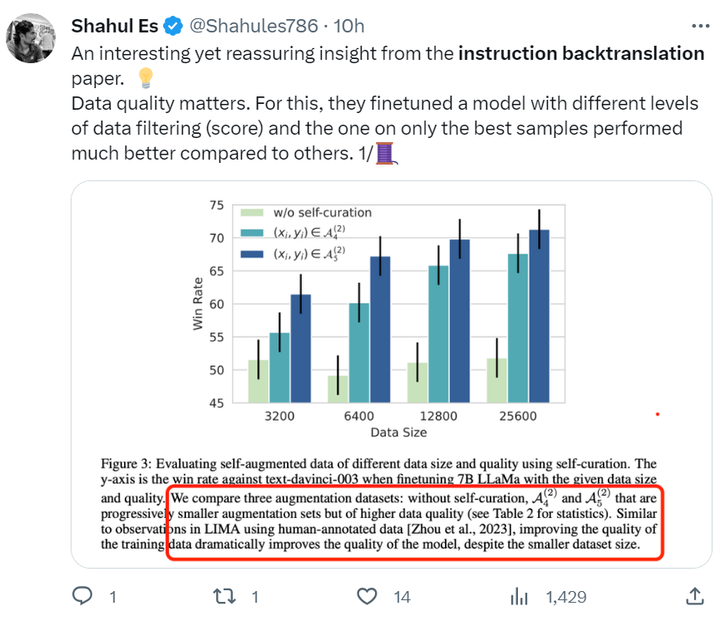 以下の図は、Humpback をいくつかのオープンソースおよび独自のモデルと比較しています。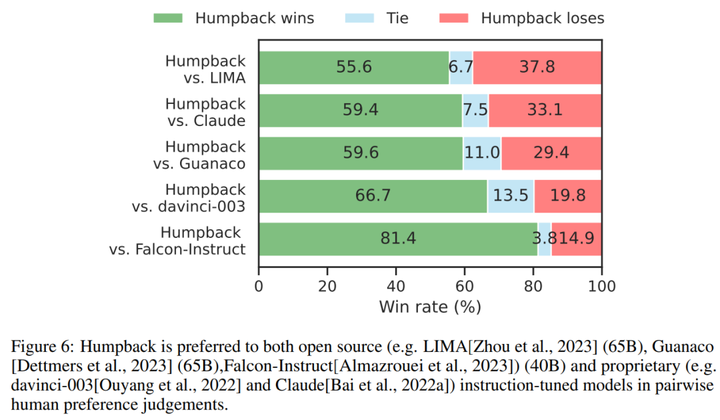 以下の表 4 は、65B モデルと 33B モデルの両方のスケールにおいて、非蒸留モデルの中で私たちのメソッドが最も優れたパフォーマンスを発揮することを示しています。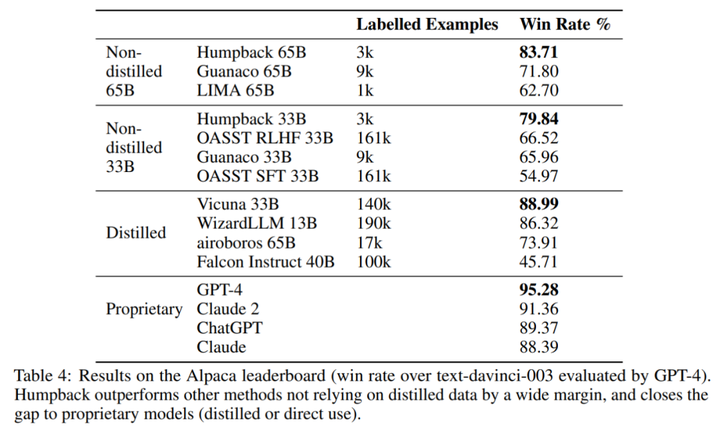 以下に具体的な方法を見てみましょう。## **メソッドの紹介**この研究では、基本的な言語モデル、少量のシード データ、ラベルのないサンプル セット (Web コーパスなど) へのアクセスを一般に想定した自己トレーニング アプローチを提案しています。ラベルのないデータは、多くの場合、人間が作成したさまざまな形式のドキュメントの大規模なコレクションであり、人間の関心のあるさまざまなトピックに関するコンテンツが含まれますが、最も重要なのは、指示と組み合わせられていないことです。ここには 2 つの重要な仮定があります。1 つ目の仮定は、この非常に大きなテキスト セット (ラベルのないサンプル セット) の一部のサブセットが、一部のユーザー指示の生成サンプルとして適しているということです。 2 番目の仮説は、これらの回答候補の指示が予測可能であり、これを使用して指示に従うモデルをトレーニングするための高品質のサンプル ペアを形成できるというものです。以下の図 1 に示すように、この研究では、命令逆変換プロセスには 2 つの主要なステップが含まれることを提案しています。* 自己拡張: ラベルのないデータ (Web コーパスなど) に対する命令を生成し、命令調整用のトレーニング データ ペア (命令と出力) を生成します。* 自己管理: トレーニング データとして高品質のサンプル データを独自に選択し、指示に従って基本モデルを微調整するこの方法を反復的に実行します。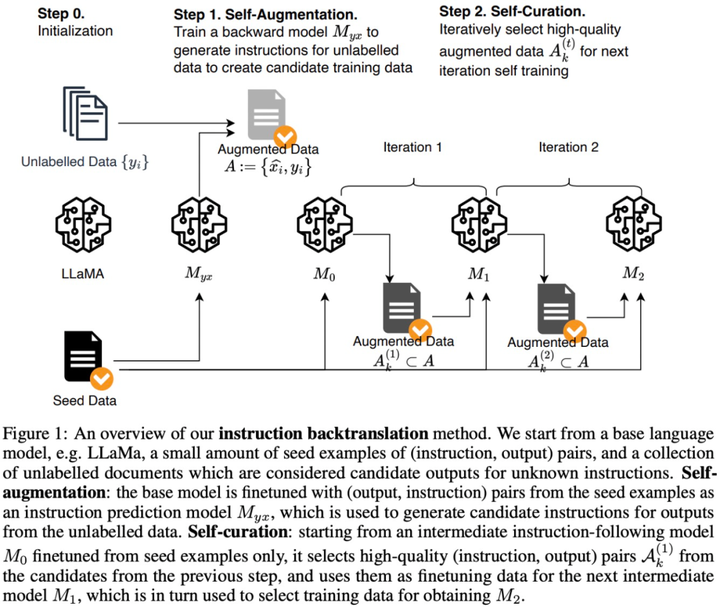 その中で採用された自己管理手順を以下の表 1 に示します。## **実験と結果**この論文のデータセットには主にシードデータと拡張データが含まれており、具体的な情報は表 2 と図 2 に示されています。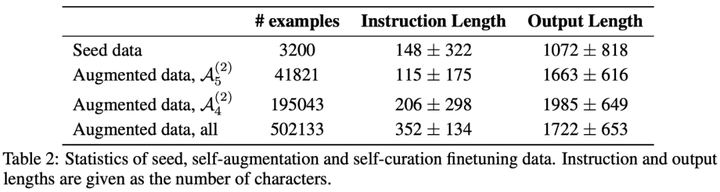 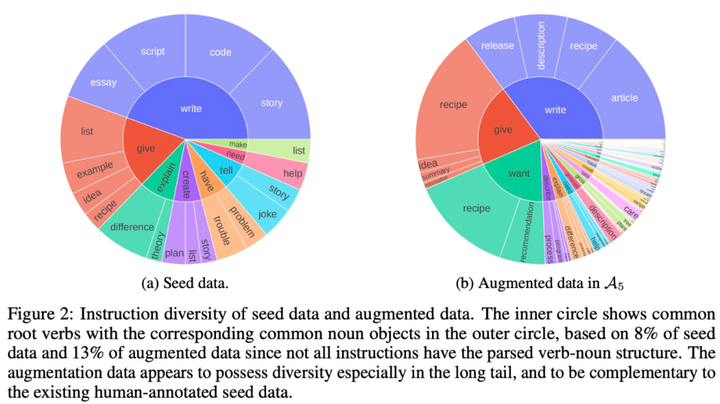 図 3 は、モデルのトレーニングに使用されるセルフキュレーションのない拡張データでは、データ サイズが増加したにもかかわらず、命令追従パフォーマンスが向上しないことを示しています。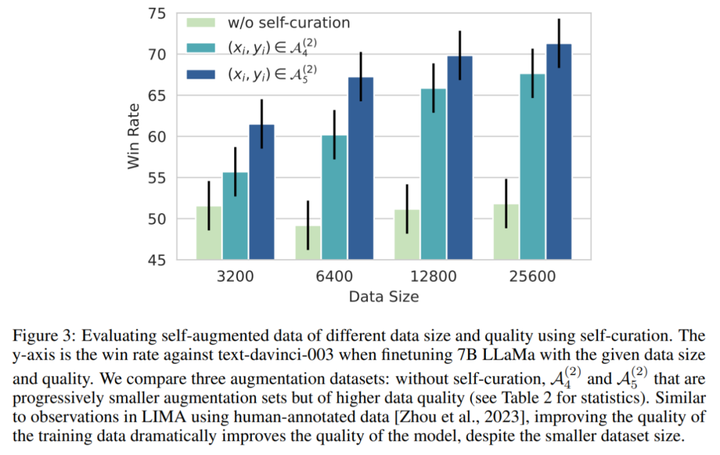 以下の図は、さまざまな命令チューニング データセットのデータ効率を比較しています。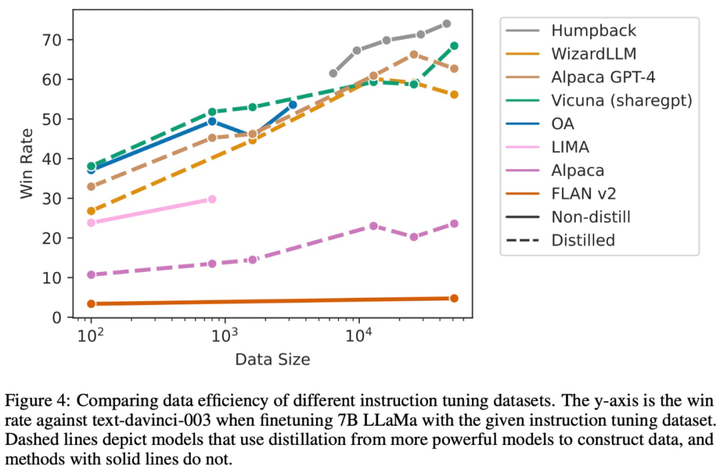 データとモデルの共同拡張: この研究では、7B モデルで観察されたデータ拡張の傾向が、より大きなモデルにも当てはまることがわかりました。たとえば、65B シード モデルに高品質の拡張データを追加すると、さらなる改善がもたらされます。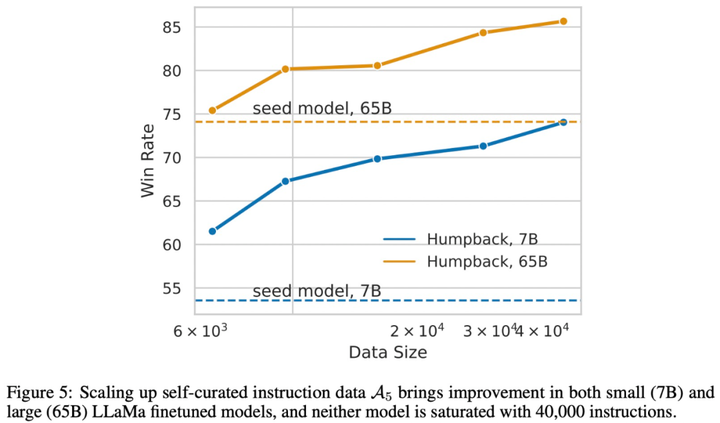 常識的推論: この研究は、SIQA、PIQA、Arc-Easy、Arc-Challenge、Openbook QA (OBQA) という 5 つの常識的推論ベンチマークでテストされ、その結果が表 5 にまとめられています。結果は、基本モデルと比較して、社会的推論などのいくつかの側面でモデルのパフォーマンスが向上していることを示しています。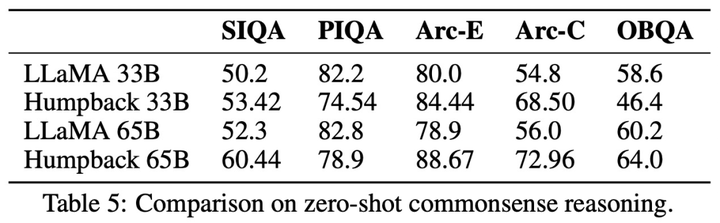 MMLU: 表 6 は、MMLU (大規模マルチタスク言語理解) のさまざまなモデルの結果をまとめたものです。微調整されたモデルは、基本モデルと比較してゼロショット精度が向上しますが、5 サンプルのコンテキストの例ではパフォーマンスが低下します。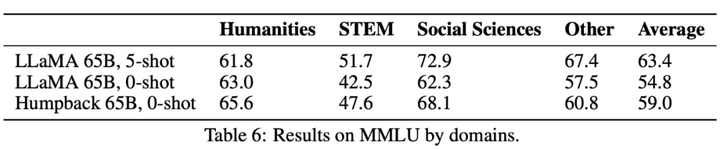
アルパカはクジラに進化し、メタは位置合わせを「自動化」し、ザトウクジラは既存のすべての LLaMa モデルを打ち負かします
編集者: Xiaozhou、Chen Ping
**出典:**マシンの心臓部
過去 1 年で、ChatGPT や GPT-4 に代表される大規模言語モデル (LLM) が急速に発展し、続いて Meta のオープンソース LLaMa および Llama 2 シリーズ モデルも AI の世界で大きな波紋を巻き起こしました。 。 LLM には制御不能なリスクがあり、人類の生存に潜在的な脅威をもたらすと考える人もいます。
これらの課題に対処するために、LLM アライメントの研究はますます重要になっており、一部の研究者は命令フォローイング (命令追従) を提案していますが、この方法では多くの人手によるアノテーションが必要です。ただし、このような高品質の命令追従データセットに注釈を付けるにはコストがかかります。
この論文では、Meta AI の研究者が、命令逆変換と呼ばれるスケーラブルな手法を提案しています。この手法は、対応する命令に自動的に注釈を付けることで、高品質の命令追従言語モデルを構築します。
具体的には、研究はシード モデルとしての言語モデルから始まり、少量のシード データと Web コーパスで微調整されます。シード モデルの役割は、トレーニング サンプルを構築することです。その後、これらのサンプルから高品質のサンプルがいくつか選別され、これらのデータはより強力なモデルを微調整するために使用されます。
LLaMa を 2 回反復してデータセット微調整した後、結果として得られたモデル Humpback は、Alpaca リーダーボードで LIMA、Claude、Guanaco などの他の既存の非蒸留モデルを上回りました。
ザトウクジラとはもともとザトウクジラ、別名ザトウクジラを意味し、メタがザトウクジラと名付けたモデルなので深い意味はありません。
チューリング賞受賞者のヤン・ルカン氏は、研究方法論の概要を述べ、アライメント研究への重要な貢献としてメタの研究を賞賛した。
このペーパーでは、2 つのステップで完了する必要がある新しいデータ拡張パラダイムを提案します。まず、より優れた命令データを生成するには、シード (命令、出力) ペアのセットとコーパスが必要です。
メソッドの紹介
この研究では、基本的な言語モデル、少量のシード データ、ラベルのないサンプル セット (Web コーパスなど) へのアクセスを一般に想定した自己トレーニング アプローチを提案しています。ラベルのないデータは、多くの場合、人間が作成したさまざまな形式のドキュメントの大規模なコレクションであり、人間の関心のあるさまざまなトピックに関するコンテンツが含まれますが、最も重要なのは、指示と組み合わせられていないことです。
ここには 2 つの重要な仮定があります。1 つ目の仮定は、この非常に大きなテキスト セット (ラベルのないサンプル セット) の一部のサブセットが、一部のユーザー指示の生成サンプルとして適しているということです。 2 番目の仮説は、これらの回答候補の指示が予測可能であり、これを使用して指示に従うモデルをトレーニングするための高品質のサンプル ペアを形成できるというものです。
以下の図 1 に示すように、この研究では、命令逆変換プロセスには 2 つの主要なステップが含まれることを提案しています。
実験と結果
この論文のデータセットには主にシードデータと拡張データが含まれており、具体的な情報は表 2 と図 2 に示されています。