*記事の出典:新志源**追記:アエネアスはとても眠いです*> この喫茶店では、客がどれくらい滞在し、店員が何杯コーヒーを淹れたかがAIカメラではっきりと見える。何百万人ものネチズンがこれを見てひどいと言い、マスク氏はショックを受けた。私たちはプライバシーがますます失われていく世界に住んでいます。今日、インターネット上に流出したこのビデオは多くの人を怖がらせました。コーヒーショップでは、各顧客が店内に数分間滞在し、各ウェイターが顧客に何杯のコーヒーを持ってきたかがビデオではっきりと示されています。 このビデオは公開されてからわずか10時間以上ですが、100万人以上のネチズンが視聴しました。 このビデオを投稿したネチズンは次のように述べています: このコンセプトは、コーヒーショップが AI を使用してバリスタと顧客を分析する方法を示しています。喫茶店でのプライベートを存分に「楽しんで」ください。 😂 別のネチズンは、それは驚くべきことではないと述べた。消費者として、多くの店は入った瞬間にあなたのことをすべて知っていることを知っておくべきです。それに比べれば「ケンブリッジ・アナリティカ事件」は見劣りする。(2018年、Facebookは英国のデータ分析会社が2016年に5,000万人のFacebookユーザーの情報を違法に入手し、この情報を利用して投票箱の結果を予測し影響を与え、トランプ氏の大統領当選を支援するソフトウェアプログラムを構築したことを認めた)選挙。) マスク氏自身もコメント欄に現れ、感嘆符を2つ続けて残した。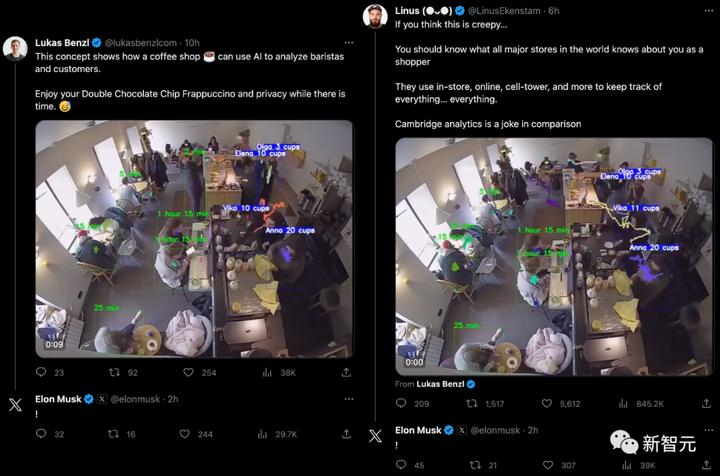 AI がコーヒー ショップのスタッフや顧客を監視するだけでも十分に恐ろしいと思うなら、現実には、コストが問題でなければ、空には何千機ものドローンがリアルタイムの追跡データを規制当局に送信することができます。すべてが追跡され、記録されます。現在の物体検出と画像認識テクノロジーは強力すぎるため、専門部門さえ必要なく、アマチュアのドローンで誰でも追跡を行うことができます。 ご存知のとおり、数年前に個別のグラフィック カードで 1080p ストリーミングを実行していたとき、最大容量はわずか 6 オブジェクトでした。## **どこにでもある「目」**現実には、私たちの現在の世界はカメラでいっぱいです。その中には、多くの企業が消費者を追跡するための非常に秘密の戦略を展開しており、すべて AI とビデオ フィードの視覚認識を使用して行われています。たとえば、ウォルマートのスマート リテール ラボでは、IRL センサーとカメラを使用して、スタッフが店内のすべてを把握できるようにしています。 ファストフード店も従業員の監督にAI技術を導入している。従業員のマスク着用は規定されており、マスクを外した人がいると管理者にすぐにバレてしまいます。 また、モバイル位置データも販売されています。 ほぼすべての携帯電話事業者は、本業の一部ともいえるデータを匿名で小売店に販売している。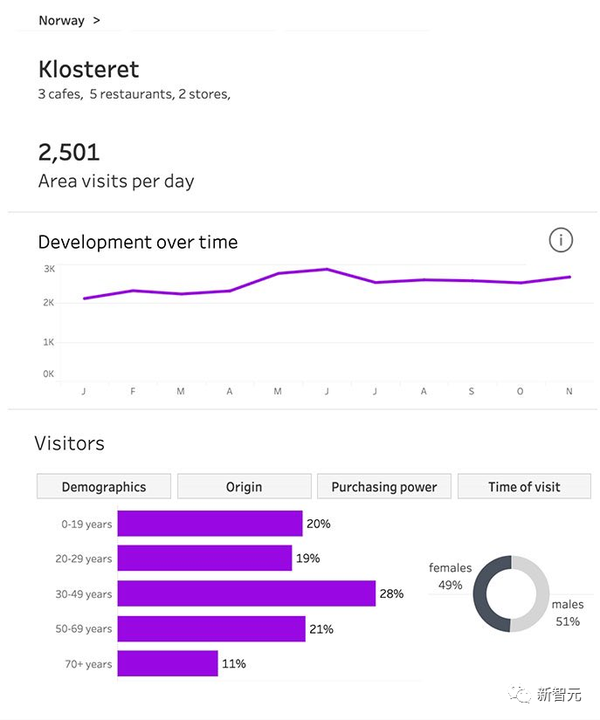 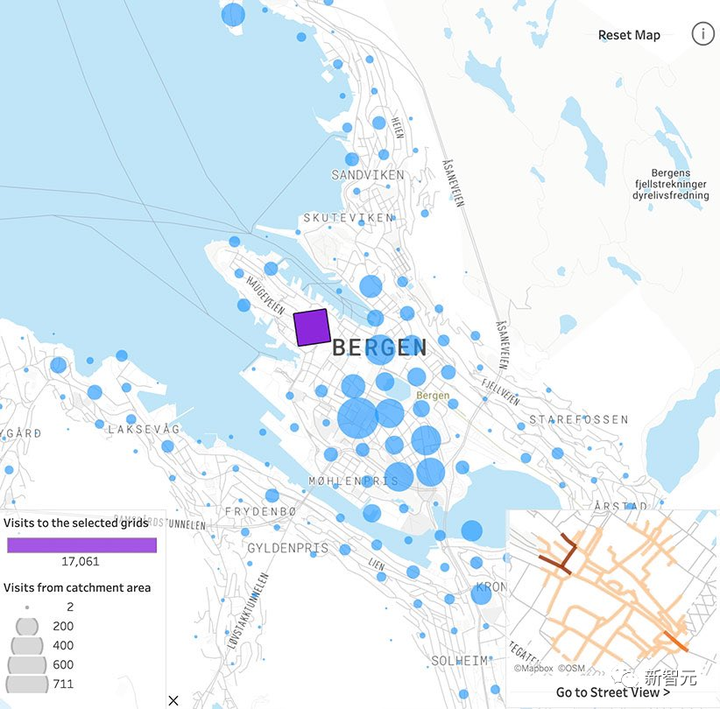 「オペレーター名 + クラウド インサイト」で Google するだけで、驚くような結果が得られます。「一定期間に、ある場所を何人の人が通過するのか知りたいですか?彼らの年齢や収入状況は何ですか。そのうち何人が潜在顧客になり得るでしょうか?」もちろん、「クラウド インサイト」サービスは、データが匿名であり、レシートの収集方法によって個人のプライバシーが明らかにならないことを強調します。 誰かがこう言いました。「私のデータは収集されたので、会社に支払いを依頼できますか?」 企業で使用されているカメラについて、コメント欄で自身の経験を披露した人もいた——「私はスタジアムのバックエンド監視カメラ システムに取り組んでいますが、一般に公開しているのは実際のデータの 1/3 にすぎません。」 「まるで映画のようです。自分の顔を入力すると、システムがあなたがどこにいるかを認識します。」 これらすべてを行うには、任意のカメラを用意し、300 ドルのソフトウェアをインストールし、ディスク容量がなくなるまで実行するだけです。## **長所と短所? **これに関して、AI コンサルティングの専門家であるディエゴ・サン・エステバン氏は次のように見解を述べています。 同氏は、従業員のパフォーマンスと生産性を継続的に監視し、管理者がより適切に戦略を立てることができるなど、AI 監視には確かに多くの利点があると考えています。さらに、AI は人間による評価のバイアスを回避するために客観的なパフォーマンス データも提供できます。欠点も数多くありますが、最も批判されているのは従業員のプライバシー権の侵害であり、企業内に不信感の雰囲気を生み出し、士気や仕事の満足度にも影響を及ぼします。AI はまた、作業が行われている状況を適切に理解することができず、人間の共感力にも欠けています。また、トレーニング データ固有のバイアスの影響を受けて間違いを犯す可能性が高く、これは従業員にとって非常に不公平です。## **ターゲット検出アルゴリズム**実際、この物議を醸したインシデントの背後には、非常に一般的な AI テクノロジーによるターゲット検出があります。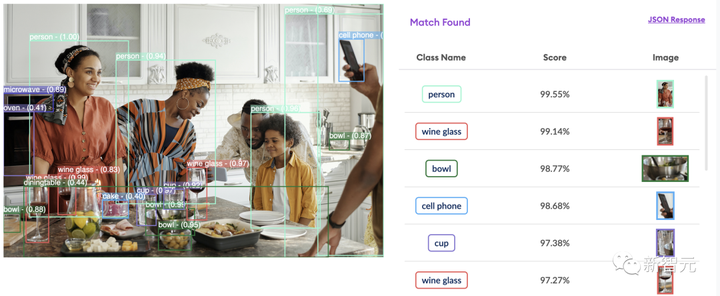 たとえば、街路の写真が与えられた場合、物体検出モデルは、信号機、車両、道路標識、建物など、画像内のすべてのさまざまな物体に対する注釈またはラベルのリストを返します。これらのラベルには、「人物」などの各オブジェクトに適切なクラスと、オブジェクトを完全に囲む長方形の領域である「境界ボックス」が含まれます。 ### **業界での応用**物体の検出は人間にとって重要なタスクです。新しい部屋やシーンに入ったとき、私たちの最初の本能は、その中にある物体や人を視覚的に評価し、理解することです。人間と同様、物体検出はコンピューターが視覚世界を理解し、対話できるようにする上で重要な役割を果たしており、多くの業界で広く使用されています。 **- サイトのセキュリティ:**物体検出モデルは、職場の安全性とセキュリティの向上に役立ちます。たとえば、敏感なエリアにある不審な人物や車両の存在を検出できます。さらに創造的にすれば、作業者が手袋、ヘルメット、マスクなどの個人用保護具 (PPE) を確実に使用できるようになります。**- ソーシャルメディア:**物体検出モデルは、デジタル メディア内の特定のブランド、製品、ロゴ、または人物の存在を識別するのに役立ちます。広告主はこの情報を使用してデータを収集し、より関連性の高い広告をユーザーに表示できます。また、不適切なコンテンツや禁止されたコンテンツを検出してフラグを立てるプロセスを自動化するのにも役立ちます。**- 品質管理:**物体検出モデルにより、視覚データの自動レビューが可能になります。コンピューターとカメラはリアルタイムでデータを分析し、視覚情報を自動的に検出して処理し、その重要性を理解することで、継続的な視覚的なレビューが必要なタスクにおける人間の介入を軽減します。これは、製造の品質管理に特に役立ちます。効率が向上するだけでなく、人間の目では見逃す可能性のある生産の異常を検出し、潜在的な生産中断や製品リコールを防ぐこともできます。## **初めて 66 AP を達成、最強の SOTA アルゴリズムがリストを独占**現在、ターゲット検出アルゴリズムの性能に関しては、国内チームの「DETRs with Collaborative Hybrid Assignments Training」が66 APのスコアでCOCOを圧倒している。この作品はICCV 2023に採択されました。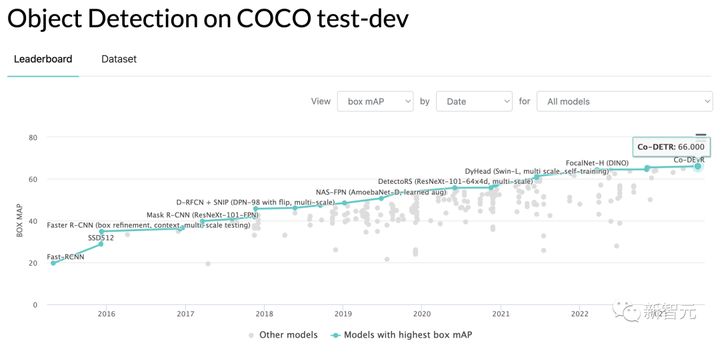 この論文では、著者らは、多様なラベル割り当てからより効率的かつ効果的な DETR ベースの検出器を学習できる、新しい協調ハイブリッド割り当てトレーニング スキーム Co-DETR を提案しています。複数の並列補助ヘッド (ATSS や Faster RCNN などの 1 対多のラベル割り当てによって監視される) をトレーニングすることにより、新しい Co-DETR はエンドツーエンド検出器のエンコーダーの学習能力を簡単に向上させることができます。追加のカスタマイズされたポジティブ クエリのためにこれらの補助ヘッドからポジティブ座標を抽出することにより、Co-DETR はデコーダー内のポジティブ サンプルのトレーニング効率も向上させることができます。さらに、これらの補助ヘッドは推論中に破棄されるため、この方法では元の検出器に追加のパラメーターや計算コストが導入されず、手動の非最大値抑制 (NMS) も必要ありません。 用紙のアドレス:プロジェクトアドレス:**- エンコーダーの最適化:**このトレーニング スキームは、1 対多のラベル割り当てによって監視される複数の並列補助ヘッドをトレーニングすることにより、エンドツーエンド検出器のエンコーダーの学習能力を簡単に高めることができます。**- コーデックの最適化:**デコーダでの注意学習は、追加のカスタム ポジティブ クエリに対してこれらの補助ヘッドからポジティブ座標を抽出することによって改善されます。**- SOTA パフォーマンス:**ViT-L (304M パラメータ) を搭載した Co-DETR は、COCO テスト開発で 66.0% の AP を達成した最初のモデルです。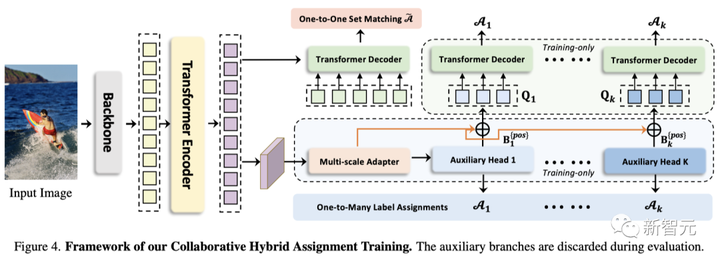 実験結果は、Swin-L バックボーン ネットワークに基づいて、Co-DETR メソッドが既存の SOTA モデル DINO-Deformable-DETR のパフォーマンスを 58.5% から 59.5% (COCO 検証セット上) 改善できることを示しています。ViT-L バックボーン ネットワークのサポートにより、Co-DETR は COCO テスト開発で 66.0% の AP、LVIS 検証セットで 67.9% の AP を達成します。さらに、Co-DETR は、以前の方法よりも小さいモデル サイズでも優れたパフォーマンスを実現します。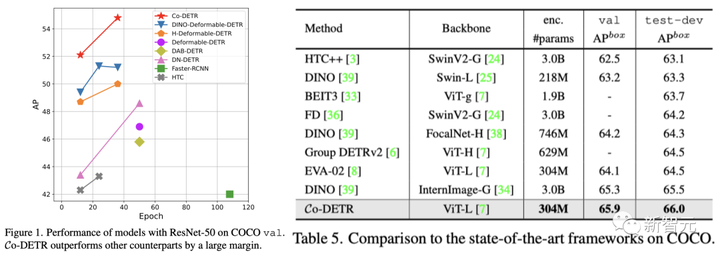 参考文献:
何百万人もの人々がコーヒーショップのモニタリングから見守り、マスク氏は「ひどい!」と叫んだ。数分間コーヒーを飲むと、AI がすべてを把握します
記事の出典:新志源
追記:アエネアスはとても眠いです
私たちはプライバシーがますます失われていく世界に住んでいます。
今日、インターネット上に流出したこのビデオは多くの人を怖がらせました。
コーヒーショップでは、各顧客が店内に数分間滞在し、各ウェイターが顧客に何杯のコーヒーを持ってきたかがビデオではっきりと示されています。
それに比べれば「ケンブリッジ・アナリティカ事件」は見劣りする。
(2018年、Facebookは英国のデータ分析会社が2016年に5,000万人のFacebookユーザーの情報を違法に入手し、この情報を利用して投票箱の結果を予測し影響を与え、トランプ氏の大統領当選を支援するソフトウェアプログラムを構築したことを認めた)選挙。)
現在の物体検出と画像認識テクノロジーは強力すぎるため、専門部門さえ必要なく、アマチュアのドローンで誰でも追跡を行うことができます。
どこにでもある「目」
現実には、私たちの現在の世界はカメラでいっぱいです。
その中には、多くの企業が消費者を追跡するための非常に秘密の戦略を展開しており、すべて AI とビデオ フィードの視覚認識を使用して行われています。
たとえば、ウォルマートのスマート リテール ラボでは、IRL センサーとカメラを使用して、スタッフが店内のすべてを把握できるようにしています。
「一定期間に、ある場所を何人の人が通過するのか知りたいですか?彼らの年齢や収入状況は何ですか。そのうち何人が潜在顧客になり得るでしょうか?」
もちろん、「クラウド インサイト」サービスは、データが匿名であり、レシートの収集方法によって個人のプライバシーが明らかにならないことを強調します。
「私はスタジアムのバックエンド監視カメラ システムに取り組んでいますが、一般に公開しているのは実際のデータの 1/3 にすぎません。」
**長所と短所? **
これに関して、AI コンサルティングの専門家であるディエゴ・サン・エステバン氏は次のように見解を述べています。
さらに、AI は人間による評価のバイアスを回避するために客観的なパフォーマンス データも提供できます。
欠点も数多くありますが、最も批判されているのは従業員のプライバシー権の侵害であり、企業内に不信感の雰囲気を生み出し、士気や仕事の満足度にも影響を及ぼします。
AI はまた、作業が行われている状況を適切に理解することができず、人間の共感力にも欠けています。
また、トレーニング データ固有のバイアスの影響を受けて間違いを犯す可能性が高く、これは従業員にとって非常に不公平です。
ターゲット検出アルゴリズム
実際、この物議を醸したインシデントの背後には、非常に一般的な AI テクノロジーによるターゲット検出があります。
これらのラベルには、「人物」などの各オブジェクトに適切なクラスと、オブジェクトを完全に囲む長方形の領域である「境界ボックス」が含まれます。
物体の検出は人間にとって重要なタスクです。新しい部屋やシーンに入ったとき、私たちの最初の本能は、その中にある物体や人を視覚的に評価し、理解することです。
人間と同様、物体検出はコンピューターが視覚世界を理解し、対話できるようにする上で重要な役割を果たしており、多くの業界で広く使用されています。
物体検出モデルは、職場の安全性とセキュリティの向上に役立ちます。たとえば、敏感なエリアにある不審な人物や車両の存在を検出できます。さらに創造的にすれば、作業者が手袋、ヘルメット、マスクなどの個人用保護具 (PPE) を確実に使用できるようになります。
- ソーシャルメディア:
物体検出モデルは、デジタル メディア内の特定のブランド、製品、ロゴ、または人物の存在を識別するのに役立ちます。広告主はこの情報を使用してデータを収集し、より関連性の高い広告をユーザーに表示できます。また、不適切なコンテンツや禁止されたコンテンツを検出してフラグを立てるプロセスを自動化するのにも役立ちます。
- 品質管理:
物体検出モデルにより、視覚データの自動レビューが可能になります。コンピューターとカメラはリアルタイムでデータを分析し、視覚情報を自動的に検出して処理し、その重要性を理解することで、継続的な視覚的なレビューが必要なタスクにおける人間の介入を軽減します。これは、製造の品質管理に特に役立ちます。効率が向上するだけでなく、人間の目では見逃す可能性のある生産の異常を検出し、潜在的な生産中断や製品リコールを防ぐこともできます。
初めて 66 AP を達成、最強の SOTA アルゴリズムがリストを独占
現在、ターゲット検出アルゴリズムの性能に関しては、国内チームの「DETRs with Collaborative Hybrid Assignments Training」が66 APのスコアでCOCOを圧倒している。この作品はICCV 2023に採択されました。
複数の並列補助ヘッド (ATSS や Faster RCNN などの 1 対多のラベル割り当てによって監視される) をトレーニングすることにより、新しい Co-DETR はエンドツーエンド検出器のエンコーダーの学習能力を簡単に向上させることができます。
追加のカスタマイズされたポジティブ クエリのためにこれらの補助ヘッドからポジティブ座標を抽出することにより、Co-DETR はデコーダー内のポジティブ サンプルのトレーニング効率も向上させることができます。
さらに、これらの補助ヘッドは推論中に破棄されるため、この方法では元の検出器に追加のパラメーターや計算コストが導入されず、手動の非最大値抑制 (NMS) も必要ありません。
プロジェクトアドレス:
- エンコーダーの最適化:
このトレーニング スキームは、1 対多のラベル割り当てによって監視される複数の並列補助ヘッドをトレーニングすることにより、エンドツーエンド検出器のエンコーダーの学習能力を簡単に高めることができます。
- コーデックの最適化:
デコーダでの注意学習は、追加のカスタム ポジティブ クエリに対してこれらの補助ヘッドからポジティブ座標を抽出することによって改善されます。
- SOTA パフォーマンス:
ViT-L (304M パラメータ) を搭載した Co-DETR は、COCO テスト開発で 66.0% の AP を達成した最初のモデルです。
ViT-L バックボーン ネットワークのサポートにより、Co-DETR は COCO テスト開発で 66.0% の AP、LVIS 検証セットで 67.9% の AP を達成します。
さらに、Co-DETR は、以前の方法よりも小さいモデル サイズでも優れたパフォーマンスを実現します。