元のソース: Qubit 画像ソース: Unbounded AI によって生成オープンソース データ セットは著作権侵害のため棚から削除されました。LLaMA、GPT-J などはこれでトレーニングされています。本日、3 年間ホストしていた Web サイトが一夜にして関連コンテンツをすべて削除しました。これは **Books3** で、約 200,000 冊の書籍で構成され、サイズが約 37 GB のデータ セットです。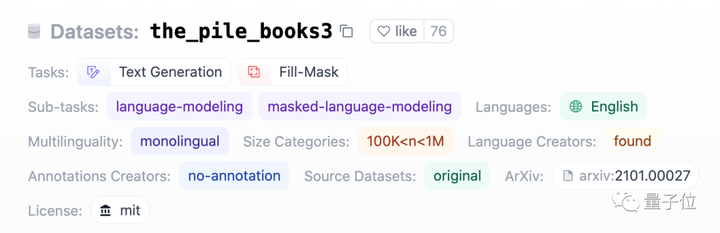 デンマークの海賊版対策団体は、データセット内に会員の書籍150冊が見つかり、著作権侵害に当たると述べ、プラットフォームに対し削除を求めた。現在、プラットフォーム上の Books3 Web ページのリンクは「404」になっています。データセットの元の開発者は、Books3 の削除はオープンソース界にとって悲劇であると力なく語った。## **Books3 とは何ですか? **Books3 は 2020 年にリリースされ、AI 開発者の Shawn Presser によってアップロードされ、Eleuther AI のオープンソース データセット Pile に含まれていました。これには、OpenAI のデータセットのベンチマークを目的とした海賊版 Web サイト Bibliotik のすべての書籍を含む、合計 197,000 冊の書籍が含まれていますが、**主要なオープンソース**です。**Books3** という名前の由来はここにあります—GPT-3 のリリース後、そのトレーニング データ セットのコンテンツの 15% が「Books1」と「Books2」という 2 つの電子書籍コーパスからのものであることが公式に明らかにされましたが、具体的なコンテンツは公開されていません。 オープンソースの Books3 は、より多くのプロジェクトに OpenAI と競合する機会を提供します。たとえば、今年爆発的に普及した LLaMA や Eleuther AI の GPT-J はすべて Books3 を使用しています。書籍データは常に大規模モデルの事前トレーニングにおけるコア コーパス マテリアルであり、モデルが高品質の長文テキストを出力するための参照を提供できることを知っておく必要があります。多くの AI 大手が使用している書籍データ セットはオープンソースではなく、非常に謎に満ちたものですらありません。たとえば、Books1/2 では、そのソースと規模に関する理解は、ほとんどが各界の推測に基づいています。 したがって、オープンソース データセットは AI サークルにとって非常に重要です。簡単にアクセスできるように、Books3 は The Eye でホストされています。これは、情報をアーカイブし、公開データを抽出できるプラットフォームです。そして今回棚から外されたのは、このプラットフォームに関するものでもありました。デンマークの反海賊団体ライツ・アライアンスはザ・アイに削除を要請し、認められた。しかし、良いニュースは、**Books3 が完全に消えたわけではない**、それを入手する他の方法がまだあるということです。Wayback Machine にもバックアップがあり、トレント クライアントからダウンロードすることもできます。著者の兄はTwitterで複数の方法を公開した。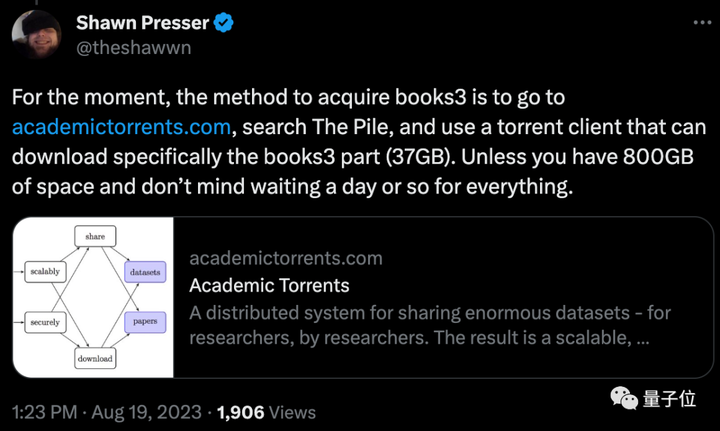## **「Books3 がなければ、独自の ChatGPT を行うことはできません」**実際、データセットの作成者は、この上場廃止事件について多くのことを語っています。彼は、ChatGPT のようなモデルを作成する唯一の方法は、Books3 のようなデータセットを作成することであると述べました。> あらゆる営利企業が秘密裏にデータセットを作成している Books3 が存在しない場合、これらの書籍データにアクセスできるのは OpenAI などの大手テクノロジー企業のみであるため、独自の ChatGPT を作成することはできません。著者の意見では、ChatGPT は 90 年代の個人 Web サイトのようなもので、誰でもできることが非常に重要です。ただし、Books3 のデータの大部分は海賊版 Web サイトからのものであるため、著者は、将来的に誰かが Books3 よりも優れたデータセットを作成してくれることを期待しています。これにより、データの品質が向上するだけでなく、書籍の著作権も尊重されます。 。 これと同様の状況がOpenAIでも起こりました。1 か月以上前、2 人のフルタイム作家が、許可なく ChatGPT をトレーニングするために自分たちの作品を使用したとして OpenAI を訴えました。このようなことが起こった理由は、OpenAI のデータセット Books2 がシャドウ ライブラリ (海賊版 Web サイト) から大量のデータを取得したためです。そのため、AIは新たな技術的進歩をもたらしただけでなく、海賊対策組織に新たな課題をもたらしたのではないかと冗談を言う声もあった。参考リンク:[1][2][3][4]
LLaMA が使用しているオープンソース データ セットは棚から撤去されました。これには約 200,000 冊の書籍が含まれており、OpenAI データ セットに対してベンチマークされています。
元のソース: Qubit
オープンソース データ セットは著作権侵害のため棚から削除されました。
LLaMA、GPT-J などはこれでトレーニングされています。
本日、3 年間ホストしていた Web サイトが一夜にして関連コンテンツをすべて削除しました。
これは Books3 で、約 200,000 冊の書籍で構成され、サイズが約 37 GB のデータ セットです。
現在、プラットフォーム上の Books3 Web ページのリンクは「404」になっています。
データセットの元の開発者は、Books3 の削除はオープンソース界にとって悲劇であると力なく語った。
**Books3 とは何ですか? **
Books3 は 2020 年にリリースされ、AI 開発者の Shawn Presser によってアップロードされ、Eleuther AI のオープンソース データセット Pile に含まれていました。
これには、OpenAI のデータセットのベンチマークを目的とした海賊版 Web サイト Bibliotik のすべての書籍を含む、合計 197,000 冊の書籍が含まれていますが、主要なオープンソースです。
Books3 という名前の由来はここにあります—
GPT-3 のリリース後、そのトレーニング データ セットのコンテンツの 15% が「Books1」と「Books2」という 2 つの電子書籍コーパスからのものであることが公式に明らかにされましたが、具体的なコンテンツは公開されていません。
たとえば、今年爆発的に普及した LLaMA や Eleuther AI の GPT-J はすべて Books3 を使用しています。
書籍データは常に大規模モデルの事前トレーニングにおけるコア コーパス マテリアルであり、モデルが高品質の長文テキストを出力するための参照を提供できることを知っておく必要があります。
多くの AI 大手が使用している書籍データ セットはオープンソースではなく、非常に謎に満ちたものですらありません。たとえば、Books1/2 では、そのソースと規模に関する理解は、ほとんどが各界の推測に基づいています。
簡単にアクセスできるように、Books3 は The Eye でホストされています。これは、情報をアーカイブし、公開データを抽出できるプラットフォームです。
そして今回棚から外されたのは、このプラットフォームに関するものでもありました。
デンマークの反海賊団体ライツ・アライアンスはザ・アイに削除を要請し、認められた。
しかし、良いニュースは、Books3 が完全に消えたわけではない、それを入手する他の方法がまだあるということです。
Wayback Machine にもバックアップがあり、トレント クライアントからダウンロードすることもできます。
著者の兄はTwitterで複数の方法を公開した。
「Books3 がなければ、独自の ChatGPT を行うことはできません」
実際、データセットの作成者は、この上場廃止事件について多くのことを語っています。
彼は、ChatGPT のようなモデルを作成する唯一の方法は、Books3 のようなデータセットを作成することであると述べました。
著者の意見では、ChatGPT は 90 年代の個人 Web サイトのようなもので、誰でもできることが非常に重要です。
ただし、Books3 のデータの大部分は海賊版 Web サイトからのものであるため、著者は、将来的に誰かが Books3 よりも優れたデータセットを作成してくれることを期待しています。これにより、データの品質が向上するだけでなく、書籍の著作権も尊重されます。 。
1 か月以上前、2 人のフルタイム作家が、許可なく ChatGPT をトレーニングするために自分たちの作品を使用したとして OpenAI を訴えました。
このようなことが起こった理由は、OpenAI のデータセット Books2 がシャドウ ライブラリ (海賊版 Web サイト) から大量のデータを取得したためです。
そのため、AIは新たな技術的進歩をもたらしただけでなく、海賊対策組織に新たな課題をもたらしたのではないかと冗談を言う声もあった。
参考リンク: [1] [2] [3] [4]