**出典:**新志源**ガイド: ** 「ユニバーサル ロボット インテリジェンス」への道の途中で、Google は RT-2 で人気を博しました。現在、Meta チームと CMU チームが 2 年をかけて構築した RoboAgent は、少量のデータを使用して 12 の複雑なスキルを実現し、お茶を淹れることからテーブルを拭くことまであらゆることを実行できます。爆発モデルは「万能ロボットエージェント」の研究を再構築している。少し前に、Google DeepMind が 7 か月をかけて構築したプロジェクト RT-2 を立ち上げました。これは数学的に推論して星を識別することができ、インターネットで人気になりました。 Googleに加え、MetaとCMUの研究者らが2年をかけて史上最強の汎用ロボットエージェント「RoboAgent」を構築した。違いは、RoboAgent は 7500 の軌道でのみトレーニングされることです。 具体的には、RoboAgent は、パンを焼く、商品を拾う、お茶を出す、キッチンの掃除など、38 のタスクに 12 の異なる複雑なスキルを実装しました。その能力は、100 の未知のシナリオに一般化することもできます。ホールに上がったら厨房に降りることができると言えます。 興味深いことに、どれだけ干渉しても、RoboAgent はタスクをなんとか完了します。 ロボエージェントは他に何ができるのでしょうか?## **パンを焼いたり、お茶を出したり、テーブルを掃除したりするのはすべて手作業**まず、RoboAgentは引き出しの開閉がスムーズに行えます。開封時にヨーグルトが倒れそうになったが、基本的に動作のつながりにラグはなく、押し引き動作はスムーズに完了した。 引き出しだけでなく、電子レンジのドアもロボエージェントで簡単に開閉できます。しかし、人間のようにハンドルを握るのではなく、ハンドルとドアの隙間に体を突っ込んで、電子レンジのドアを勢いよく開け閉めしたのです。 同様に、ボトルや缶の蓋に直面したときも、RoboAgent は蓋を正確に処理し、開閉することができます。決して乱雑になることはありません。しかし、キッチンには蓋付きの調味料瓶の他に、クッキングワインやラオガンマなど、ネジを外す必要のある瓶もいくつかあります。 幸いなことに、さまざまなピック アンド プレイス タスクに関しては、RoboAgent は基本的に心配する必要はありません。ビデオでは、ロボエージェントが引き出しから物を取り出したり、ティーバッグをカップに入れたり、電子レンジのスイッチを入れてボウルを入れたりします。お茶を淹れる、食べ物を温めるなどの一連の動作をロボエージェントが理解できることがわかります。 上記9つの動作を並べて組み合わせることで、基本的にキッチンでの一連の作業をカバーできます。例としては、パンを焼く準備、キッチンの掃除、スープの提供、お茶の淹れ方、カトラリーの保管などが挙げられます。 ベーキングの準備をするとき、最初のステップは引き出しを開けて中にバターを見つけることです。見つけたらまな板の上にバターを置き、最後に引き出しを閉めます。RoboAgent の一連の動作の論理的な順序は、現実のシーンに非常に近いようです。しかし、ロボエージェントはまだ人間ほど柔軟ではなく、言うまでもなく人間には 2 本の手があるので、片手でバターを持ち、もう一方の手で引き出しを閉めることができます。人間は片手だけでもバターを持ちながら引き出しを横に押し戻すことができます。ただし、RoboAgent ができるのは、最初にバターを置いてから引き出しを閉めることだけです。それほど柔軟性があるようには見えません。 キッチンを掃除するとき、RoboAgent は次の 4 つのステップも実行します。まず引き出しを閉めてから電子レンジを閉めます。次に横からタオルを取り出し、最後にまな板を拭きます。 スープを提供するために、RoboAgent はまず電子レンジの電源を入れ、次にボウルを電子レンジから取り出します。次にボウルをテーブルの上に置き、最後に電子レンジの電源を切ります。しかし、ここでの RoboAgent のパフォーマンスはそれほど安心できるものではありません。デモ動画では幸いにもボウルは空だったとしか言えませんが、実際にロボエージェントが食べ物が入ったボウルを拾うことができた場合、拾った瞬間に食べ物は地面に散らばると推定されます。それをアップします。 ただし、RoboAgent はお茶を淹れるのに便利です。まずティーポットの蓋を外し、中からティーバッグを取り出し、ティーバッグを正確にカップに落とし、最後に蓋を持ち上げてポットに戻します。しかし、水を注ぐことで、完璧な一杯のお茶にまた一歩近づきました。それともロボエージェントがお茶の香りの空気を飲むよう誘っているのでしょうか?前述のRoboAgentのパフォーマンスを見ると、ほとんどのタスクはスムーズに完了できますが、片手だけではまだ不便です。Meta と CMU が RoboAgent にさらに多くの手を与え、RoboAgent が複数のことを同時に実行できるようになり、効率が大幅に向上することを願っています。## **「ユニバーサル ロボット エージェント」の作成には 2 年かかりました**Meta と CMU の研究者は、RoboAgent が真の汎用ロボット エージェントになることを期待しています。過去 2 年間にわたり、彼らはプロジェクトを継続的に進めています。 RoboAgent は多方向の研究の集合体であり、将来のさらなる研究の方向性の出発点でもあります。「ユニバーサル ロボット エージェント」の開発において、研究者は最近の多くの汎用化可能なロボット学習プロジェクトからインスピレーションを受けました。現在、一般的なロボットエージェントに至るまでには、2 つの大きな問題を解決する必要があります。** 1 つは原因と結果のジレンマです。 **さまざまな環境で任意の物体を操作できるロボットを開発することは、何十年にもわたって遠い野心的な目標でした。これは、そのようなエージェントをトレーニングするためのデータセットが不足していることも原因の 1 つですが、そのようなデータを生成できる一般的なエージェントが不足していることも原因です。2つ目は悪循環を断ち切ることです。 **この悪循環から抜け出すために、研究は効果的なパラダイムの開発に焦点を当てています。現実的なデータ予算で複数のスキルを習得し、それらをさまざまな未知の状況に汎用化できる総合エージェントを提供できます。 用紙のアドレス:概要によると、RoboAgent は次のモジュール式の補償可能な要素に基づいて構築されています。**- ロボペン:**汎用ハードウェアを使用して構築された分散ロボット インフラストラクチャは、長期間中断することなく実行できます。**- ロボハイブ:**シミュレーションと現実世界の操作にわたるロボット学習のための統合フレームワーク。**-ロボセット:**さまざまなシーンにおける日常の物体の多様なスキルを表す高品質のデータセット。**-MT-ACT:**言語条件付きマルチタスクにおけるオフライン模倣学習のための効率的なフレームワーク。既存のロボット工学の経験に基づいてセマンティック拡張の多様なセットを作成することでオフライン データセットを増やし、効率的なアクション表現を備えた新しいポリシー アーキテクチャを採用して、データ予算内で高パフォーマンスのポリシーを回復します。## **アクションブロック、新構造MT-ACT**ロボットが一般的な動作ポリシーを学習するには、さまざまなスキルや環境の変化など、豊富で多様な経験を積む必要があります。ただし、このような広範なデータセットを収集する際の運用コストと実際的な課題により、データセット全体のサイズが制限されます。研究者らは、限られたデータ予算で効果的なマルチタスクエージェントを学習できるパラダイムを開発することで、これらの制限に対処することを目指しています。以下の図に示すように、Meta チームと CMU チームは、MT-ACT、Multi-Task Action Chunking Transformer (Multi-Task Action Chunking Transformer) を提案しました。 この方法は 2 つの段階で構成されます。**フェーズ 1: セマンティック強化**RoboAgent は、RoboSet (MT-ACT) データセットのセマンティック拡張を作成することにより、既存の基本モデルからワールド事前分布を挿入します。結果として得られるデータセットは、人やロボットのコストを追加することなく、ロボットの経験を世界の過去の経験と何倍にもします。次に研究者らは、SAM を使用して、ターゲット オブジェクトをセグメント化し、形状、色、テクスチャが異なる個別のオブジェクトに意味的に強化しました。**フェーズ 2: 効率的なポリシーの表現**結果として得られるデータセットはマルチモーダルであり、豊富な種類のスキル、タスク、シナリオが含まれています。研究者らは、アクション チャンクをマルチタスク設定に適応させて、低データ予算設定での過剰適合を回避しながら高度にマルチモーダルなデータセットを取り込むことができる、新しく効率的なポリシー表現である MT-ACT を開発しました。以下は、MT-ACT 戦略のさまざまなコンポーネントです。### **RoboSet データセット**研究の目標は、データ効率の高いロボット学習パラダイムを確立することであり、そのために研究者らは、凍結され、事前に収集された小規模だが多様なデータセットに限定しました。行動の多様性を捉えるために、研究者らはまた、さまざまなキッチンのシナリオでさまざまなタスクにさまざまなスキルを適用しました。このプロジェクトでは、データセット RoboSet (MT-ACT) は人間の遠隔操作によって収集された 7500 の軌跡で構成されています。データセットには、複数のタスクとシナリオにわたる 12 のスキルが含まれています。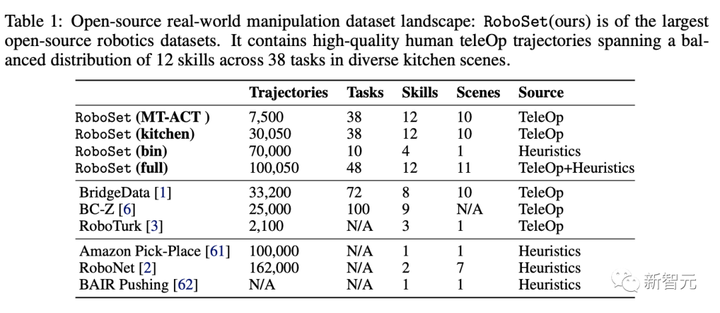 以下の図は、データセット内のスキルの分布を示しています。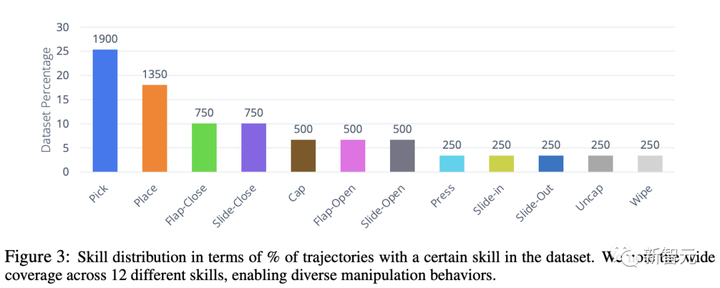 一般的に使用される「ピック アンド プレイス」スキルがデータセットの 40% を占めていますが、ワイピング、キャッピング、多関節オブジェクトを含むスキル (フリップオープン、フリップクローズ) などのリッチコンタクト スキルも含まれています。研究者らは、日常のさまざまな物体を含むキッチン シーンの 4 つの異なるインスタンスでデータセット全体を収集しました。さらに、チームはシーンの各インスタンスをオブジェクトのさまざまなバリエーションと交換し、各能力が複数のターゲット オブジェクトやシーンのインスタンスに到達できるようにしました。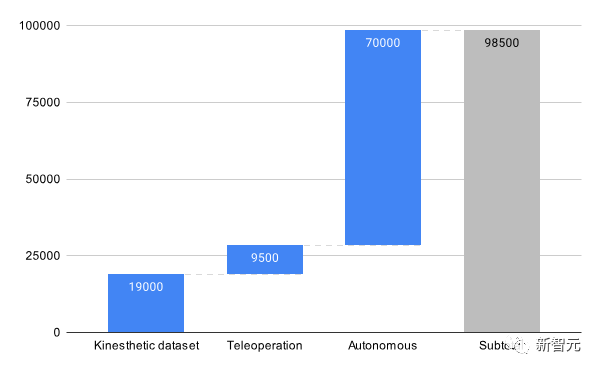## **データ拡張**収集されたデータセットはシーンとオブジェクトの多様性のニーズを満たすことができないため、研究者らは、各軌跡の操作動作を維持しながら、さまざまな変化するシーンをオフラインで追加することでデータセットを強化しました。研究者たちは、セグメンテーションと修復モデルの最近の進歩に基づいて、インターネット データから現実世界の意味事前分布を抽出し、構造化された方法でシーンを変更します。## **MT-ACT アーキテクチャ**MT-ACT のポリシー アーキテクチャは、マルチモーダル マルチタスク ロボット データセットを処理するのに十分な容量を備えた Transformer モデルとして設計されています。マルチモーダル データをキャプチャするために、研究者らは以前の研究に従って、アクション シーケンスを潜在的なスタイルの埋め込み z としてエンコードする CVAE を追加しました。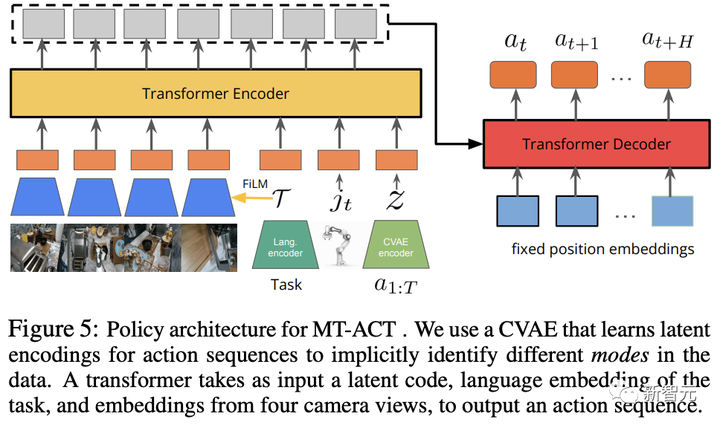 マルチタスク データをモデル化するために、タスク固有の記述の埋め込み T を学習する事前トレーニング済み言語エンコーダーを採用します。複合誤差の問題を軽減するために、H ステップ先のアクションが各タイム ステップで予測され、特定のタイム ステップで予測された重複するアクションの時間的平滑化によって実行されます。さらに、シーンの変化に対する堅牢性を向上させるために、研究者らは 4 つのカメラ アングルを通じてワークスペースの 4 つの異なるビューを MT-ACT 戦略に提供しました。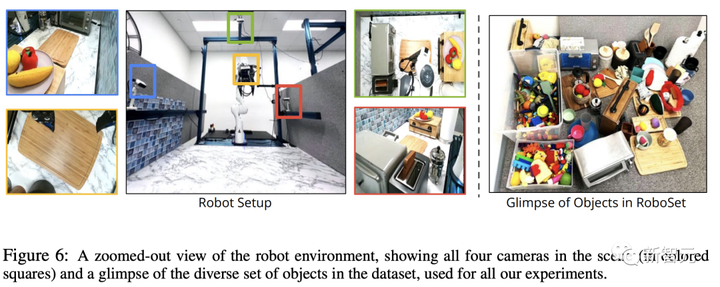  次に、FiLM ベースの調整方法を使用して、イメージ トークンが言語命令に確実に焦点を当てられるようにします。これにより、シーン内に複数のタスクが存在する可能性がある場合に MT-ACT 戦略がタスクを混乱させません。エンコードされたトークンは、固定位置の埋め込みで Transformer ポリシー デコーダに入り、最終的に次のアクション ブロック (H アクション) を出力します。実行時に、研究者は現在のタイム ステップ (H > 1 の場合、アクション ブロックは重複します) で予測されるすべての重複操作の平均を取得し、結果として得られる平均化されたアクションを実行します。## **少量のデータ、Google RT-1 に追いつく**MT-ACT 戦略は現実の世界でどのように機能しますか?研究者らは、提案されたフレームワークのサンプル効率と、さまざまなシナリオにおけるエージェントの汎用性を実験的に評価しました。以下の図は、MT-ACT 戦略と一般的に使用される模倣学習アーキテクチャを比較しています。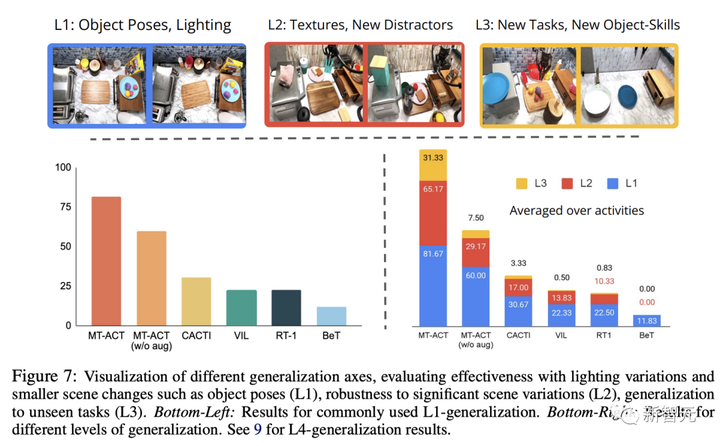 研究者らは、L1 一般化の結果のみをプロットしました。これは、他のほとんどの模倣学習アルゴリズムで使用される標準設定であるためです。図からわかるように、(サブ軌道ではなく) 次のステップの動作のみをシミュレートするすべてのメソッドのパフォーマンスは低くなります。これらの手法の中で、アクション クラスタリング (BeT) に基づく手法は、マルチタスク設定ではパフォーマンスがはるかに悪いことが研究者らによって発見されました。さらに、大量のデータを必要とする RT1 のような手法は、研究で使用されるデータが少ないため、この設定ではうまく機能しません。対照的に、MT-ACT 戦略はアクション検査を使用してサブ軌道をモデル化し、すべてのベースライン手法を大幅に上回ります。図 7 (右下) は、複数の汎化レベル (L1、L2、および L3) にわたるすべてのメソッドの結果を示しています。さらに、研究者は各アクティビティの一般化結果を個別に報告します。図 8 から、各セマンティック強化方法が各アクティビティのパフォーマンスにプラスの影響を与えていることがわかります。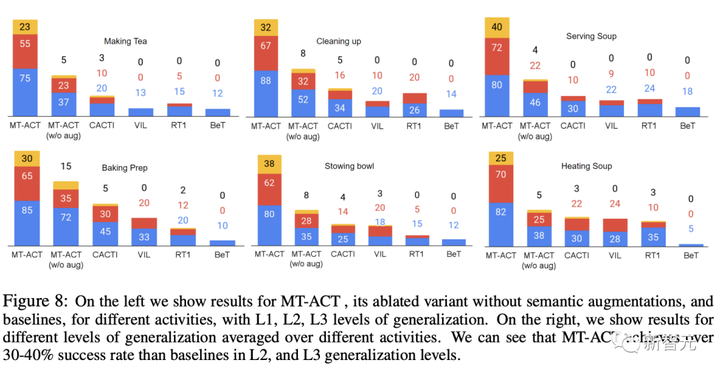 最後に、研究者らは、アクション表現ブロックのサイズ、可塑性、堅牢性など、さまざまな設計を使用してアーキテクチャを調査しました。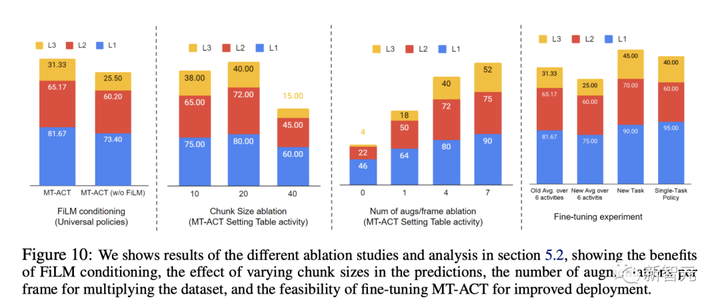 参考文献:ロボセット/補足.html
メタ社は2年の歳月をかけてCMUと協力し、最強の「万能ロボット知能」を作り上げました!お茶や茶わんを拭くジェネラリストは、100 を超える未知のタスクを簡単に一般化します
**出典:**新志源
**ガイド: ** 「ユニバーサル ロボット インテリジェンス」への道の途中で、Google は RT-2 で人気を博しました。現在、Meta チームと CMU チームが 2 年をかけて構築した RoboAgent は、少量のデータを使用して 12 の複雑なスキルを実現し、お茶を淹れることからテーブルを拭くことまであらゆることを実行できます。
爆発モデルは「万能ロボットエージェント」の研究を再構築している。
少し前に、Google DeepMind が 7 か月をかけて構築したプロジェクト RT-2 を立ち上げました。これは数学的に推論して星を識別することができ、インターネットで人気になりました。
違いは、RoboAgent は 7500 の軌道でのみトレーニングされることです。
その能力は、100 の未知のシナリオに一般化することもできます。
ホールに上がったら厨房に降りることができると言えます。
パンを焼いたり、お茶を出したり、テーブルを掃除したりするのはすべて手作業
まず、RoboAgentは引き出しの開閉がスムーズに行えます。
開封時にヨーグルトが倒れそうになったが、基本的に動作のつながりにラグはなく、押し引き動作はスムーズに完了した。
しかし、人間のようにハンドルを握るのではなく、ハンドルとドアの隙間に体を突っ込んで、電子レンジのドアを勢いよく開け閉めしたのです。
しかし、キッチンには蓋付きの調味料瓶の他に、クッキングワインやラオガンマなど、ネジを外す必要のある瓶もいくつかあります。
ビデオでは、ロボエージェントが引き出しから物を取り出したり、ティーバッグをカップに入れたり、電子レンジのスイッチを入れてボウルを入れたりします。お茶を淹れる、食べ物を温めるなどの一連の動作をロボエージェントが理解できることがわかります。
例としては、パンを焼く準備、キッチンの掃除、スープの提供、お茶の淹れ方、カトラリーの保管などが挙げられます。
RoboAgent の一連の動作の論理的な順序は、現実のシーンに非常に近いようです。
しかし、ロボエージェントはまだ人間ほど柔軟ではなく、言うまでもなく人間には 2 本の手があるので、片手でバターを持ち、もう一方の手で引き出しを閉めることができます。人間は片手だけでもバターを持ちながら引き出しを横に押し戻すことができます。ただし、RoboAgent ができるのは、最初にバターを置いてから引き出しを閉めることだけです。
それほど柔軟性があるようには見えません。
まず引き出しを閉めてから電子レンジを閉めます。次に横からタオルを取り出し、最後にまな板を拭きます。
しかし、ここでの RoboAgent のパフォーマンスはそれほど安心できるものではありません。
デモ動画では幸いにもボウルは空だったとしか言えませんが、実際にロボエージェントが食べ物が入ったボウルを拾うことができた場合、拾った瞬間に食べ物は地面に散らばると推定されます。それをアップします。
まずティーポットの蓋を外し、中からティーバッグを取り出し、ティーバッグを正確にカップに落とし、最後に蓋を持ち上げてポットに戻します。
しかし、水を注ぐことで、完璧な一杯のお茶にまた一歩近づきました。それともロボエージェントがお茶の香りの空気を飲むよう誘っているのでしょうか?
前述のRoboAgentのパフォーマンスを見ると、ほとんどのタスクはスムーズに完了できますが、片手だけではまだ不便です。
Meta と CMU が RoboAgent にさらに多くの手を与え、RoboAgent が複数のことを同時に実行できるようになり、効率が大幅に向上することを願っています。
「ユニバーサル ロボット エージェント」の作成には 2 年かかりました
Meta と CMU の研究者は、RoboAgent が真の汎用ロボット エージェントになることを期待しています。
過去 2 年間にわたり、彼らはプロジェクトを継続的に進めています。 RoboAgent は多方向の研究の集合体であり、将来のさらなる研究の方向性の出発点でもあります。
「ユニバーサル ロボット エージェント」の開発において、研究者は最近の多くの汎用化可能なロボット学習プロジェクトからインスピレーションを受けました。
現在、一般的なロボットエージェントに至るまでには、2 つの大きな問題を解決する必要があります。
** 1 つは原因と結果のジレンマです。 **
さまざまな環境で任意の物体を操作できるロボットを開発することは、何十年にもわたって遠い野心的な目標でした。これは、そのようなエージェントをトレーニングするためのデータセットが不足していることも原因の 1 つですが、そのようなデータを生成できる一般的なエージェントが不足していることも原因です。
2つ目は悪循環を断ち切ることです。 **
この悪循環から抜け出すために、研究は効果的なパラダイムの開発に焦点を当てています。
現実的なデータ予算で複数のスキルを習得し、それらをさまざまな未知の状況に汎用化できる総合エージェントを提供できます。
概要によると、RoboAgent は次のモジュール式の補償可能な要素に基づいて構築されています。
- ロボペン:
汎用ハードウェアを使用して構築された分散ロボット インフラストラクチャは、長期間中断することなく実行できます。
- ロボハイブ:
シミュレーションと現実世界の操作にわたるロボット学習のための統合フレームワーク。
-ロボセット: さまざまなシーンにおける日常の物体の多様なスキルを表す高品質のデータセット。
-MT-ACT:
言語条件付きマルチタスクにおけるオフライン模倣学習のための効率的なフレームワーク。既存のロボット工学の経験に基づいてセマンティック拡張の多様なセットを作成することでオフライン データセットを増やし、効率的なアクション表現を備えた新しいポリシー アーキテクチャを採用して、データ予算内で高パフォーマンスのポリシーを回復します。
アクションブロック、新構造MT-ACT
ロボットが一般的な動作ポリシーを学習するには、さまざまなスキルや環境の変化など、豊富で多様な経験を積む必要があります。
ただし、このような広範なデータセットを収集する際の運用コストと実際的な課題により、データセット全体のサイズが制限されます。
研究者らは、限られたデータ予算で効果的なマルチタスクエージェントを学習できるパラダイムを開発することで、これらの制限に対処することを目指しています。
以下の図に示すように、Meta チームと CMU チームは、MT-ACT、Multi-Task Action Chunking Transformer (Multi-Task Action Chunking Transformer) を提案しました。
フェーズ 1: セマンティック強化
RoboAgent は、RoboSet (MT-ACT) データセットのセマンティック拡張を作成することにより、既存の基本モデルからワールド事前分布を挿入します。
結果として得られるデータセットは、人やロボットのコストを追加することなく、ロボットの経験を世界の過去の経験と何倍にもします。
次に研究者らは、SAM を使用して、ターゲット オブジェクトをセグメント化し、形状、色、テクスチャが異なる個別のオブジェクトに意味的に強化しました。
フェーズ 2: 効率的なポリシーの表現
結果として得られるデータセットはマルチモーダルであり、豊富な種類のスキル、タスク、シナリオが含まれています。
研究者らは、アクション チャンクをマルチタスク設定に適応させて、低データ予算設定での過剰適合を回避しながら高度にマルチモーダルなデータセットを取り込むことができる、新しく効率的なポリシー表現である MT-ACT を開発しました。
以下は、MT-ACT 戦略のさまざまなコンポーネントです。
RoboSet データセット
研究の目標は、データ効率の高いロボット学習パラダイムを確立することであり、そのために研究者らは、凍結され、事前に収集された小規模だが多様なデータセットに限定しました。
行動の多様性を捉えるために、研究者らはまた、さまざまなキッチンのシナリオでさまざまなタスクにさまざまなスキルを適用しました。
このプロジェクトでは、データセット RoboSet (MT-ACT) は人間の遠隔操作によって収集された 7500 の軌跡で構成されています。
データセットには、複数のタスクとシナリオにわたる 12 のスキルが含まれています。
研究者らは、日常のさまざまな物体を含むキッチン シーンの 4 つの異なるインスタンスでデータセット全体を収集しました。
さらに、チームはシーンの各インスタンスをオブジェクトのさまざまなバリエーションと交換し、各能力が複数のターゲット オブジェクトやシーンのインスタンスに到達できるようにしました。
データ拡張
収集されたデータセットはシーンとオブジェクトの多様性のニーズを満たすことができないため、研究者らは、各軌跡の操作動作を維持しながら、さまざまな変化するシーンをオフラインで追加することでデータセットを強化しました。
研究者たちは、セグメンテーションと修復モデルの最近の進歩に基づいて、インターネット データから現実世界の意味事前分布を抽出し、構造化された方法でシーンを変更します。
MT-ACT アーキテクチャ
MT-ACT のポリシー アーキテクチャは、マルチモーダル マルチタスク ロボット データセットを処理するのに十分な容量を備えた Transformer モデルとして設計されています。
マルチモーダル データをキャプチャするために、研究者らは以前の研究に従って、アクション シーケンスを潜在的なスタイルの埋め込み z としてエンコードする CVAE を追加しました。
複合誤差の問題を軽減するために、H ステップ先のアクションが各タイム ステップで予測され、特定のタイム ステップで予測された重複するアクションの時間的平滑化によって実行されます。
さらに、シーンの変化に対する堅牢性を向上させるために、研究者らは 4 つのカメラ アングルを通じてワークスペースの 4 つの異なるビューを MT-ACT 戦略に提供しました。
エンコードされたトークンは、固定位置の埋め込みで Transformer ポリシー デコーダに入り、最終的に次のアクション ブロック (H アクション) を出力します。
実行時に、研究者は現在のタイム ステップ (H > 1 の場合、アクション ブロックは重複します) で予測されるすべての重複操作の平均を取得し、結果として得られる平均化されたアクションを実行します。
少量のデータ、Google RT-1 に追いつく
MT-ACT 戦略は現実の世界でどのように機能しますか?
研究者らは、提案されたフレームワークのサンプル効率と、さまざまなシナリオにおけるエージェントの汎用性を実験的に評価しました。
以下の図は、MT-ACT 戦略と一般的に使用される模倣学習アーキテクチャを比較しています。
図からわかるように、(サブ軌道ではなく) 次のステップの動作のみをシミュレートするすべてのメソッドのパフォーマンスは低くなります。
これらの手法の中で、アクション クラスタリング (BeT) に基づく手法は、マルチタスク設定ではパフォーマンスがはるかに悪いことが研究者らによって発見されました。
さらに、大量のデータを必要とする RT1 のような手法は、研究で使用されるデータが少ないため、この設定ではうまく機能しません。
対照的に、MT-ACT 戦略はアクション検査を使用してサブ軌道をモデル化し、すべてのベースライン手法を大幅に上回ります。
図 7 (右下) は、複数の汎化レベル (L1、L2、および L3) にわたるすべてのメソッドの結果を示しています。
さらに、研究者は各アクティビティの一般化結果を個別に報告します。図 8 から、各セマンティック強化方法が各アクティビティのパフォーマンスにプラスの影響を与えていることがわかります。
ロボセット/
補足.html