> Coder ファミリーに新しいメンバーが追加され、オープンソース化されました。コード編集に関して知っている大きなモデル ツールは何ですか?Twitter ユーザー @lvwerra は、コードファミリーのほとんどのメンバーを分類するために以下の画像を作成しました。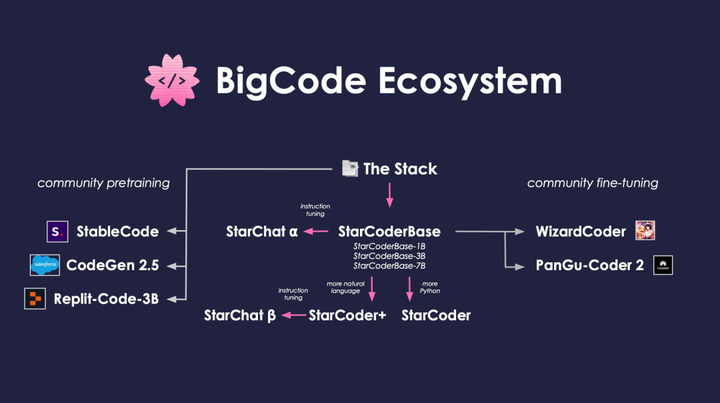 彼がこの写真を公開してからわずか 2 週間後、DeciCoder、OctoCoder、そして最新のメンバーである SQLCoder の 3 人の新しいメンバーがファミリーに加わりました。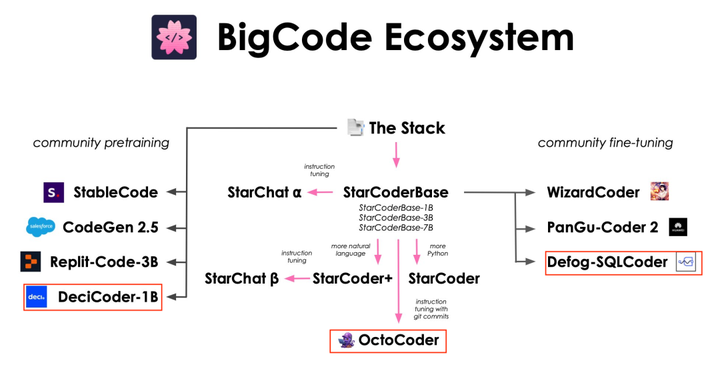 その中でも、最新のメンバーである SQLCoder は、パフォーマンスが優れているだけでなく、オープンソース化されました。## **SQLCoder**SOTA 大規模言語モデルとして、SQLCoder は自然言語の質問を SQL クエリに変換します。開発者のオープンソース評価フレームワークである SQL では、SQLCoder はすべての主要なオープンソース モデルを大幅に上回り、OpenAI の GPT-3.5 を上回ります。SQLCoder は 15B パラメータの LLM であり、StarCoder の微調整された実装でもあります。 SQLCoder は、難易度が高くなる手作りの SQL クエリに合わせて微調整されています。単一のデータベース スキーマに合わせて微調整すると、そのパフォーマンスは GPT-4 と同等かそれ以上になります。 * プロジェクトアドレス:* デモアドレス:*モデルの重量:過去 3 か月間で、SQLCoder は医療、金融、その他の企業に導入されました。これらの企業は多くの場合、自社のサーバーから外したくない機密データを保有しているため、LLM を使用できる唯一の方法はセルフホスト モデルを利用することです。## **方法****データセットを作成**著者らは、テキストから SQL へのタスクに焦点を当てて、手作業で編集された補完ペア データセットを作成しました。データセットは、さまざまな難易度の質問を含む 10 の異なるパターンから作成されました。さらに、7 つの新しいパターンからの 175 の質問からなる評価データセットを作成しました。テーブルが 1 つまたは 2 つしかないスキーマでは関係が限られているため、単純で単純なクエリが可能になる傾向があるため、トレーニング データセットと評価データセットの両方で 4 ~ 20 のテーブルを持つ複雑なスキーマが選択されるようにしました。**質問カテゴリ**データセットの作成後、作成者はデータセット内の各質問を、簡単、中程度、難しい、および非常に難しいの 4 つのカテゴリに分類しました。この分類は、SQL の難易度を測定するために Spider データセットで使用される基準を適応させることによって行われます。最後に、彼らはデータセットを、簡単と中程度、およびハードと超ハードの 2 つの異なるサブセクションに分割しました。**微調整**著者らは次の 2 段階でモデルを微調整しました。まず、StarCoder の基本モデルは、簡単な問題と中程度の難易度の問題についてのみ微調整されました。次に、取得したモデル (defog-easy としてコード化) を難しい問題および超難しい問題で微調整して、SQLcoder を取得します。**評価する**著者らは、自分たちで作成したカスタム データセットでモデルを評価しました。 SQL クエリの正しさを評価することは非常に難しく、評価基準として GPT-4 を使用することも検討されましたが、多くの問題が発生しました。その過程で、2 つの異なる SQL クエリが両方とも正しい可能性があることにも気づきました。「トロントの最後の 10 人のユーザーは誰ですか」という質問については、次のクエリ形式は両方とも正解です。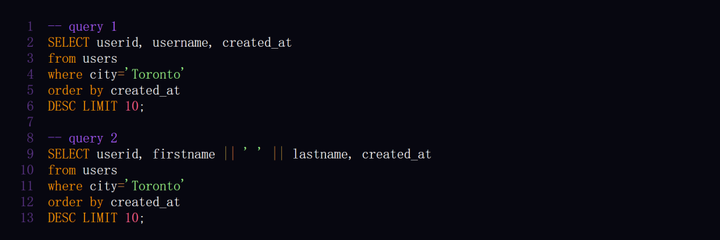 これを考慮して、作成者はクエリの正確さを評価するためのカスタム フレームワークを構築しました。彼らはモデルの重みをオープンソース化しただけでなく、評価フレームワークと評価データセットもオープンソース化しました。データセットをリリースする目的は、利用可能なベンチマークを強化し、研究者やエンジニアが text-to-SQL 生成モデルのパフォーマンス、特に列の名前変更、列の追加、並べ替えなど、返された結果の無害な変更に対するモデルの応答をより深く理解できるようにすることです)。堅牢性。 評価の詳細については、ブログのコンテンツを参照してください。**パフォーマンス**評価フレームワークでは、Defog SQLCoder は GPT-4 を除くすべての主要モデルよりも優れています。特に、2 つのモデルの 10 倍以上のサイズを持つ gpt-3.5-turbo および text-davinci-003 よりも優れたパフォーマンスを発揮します。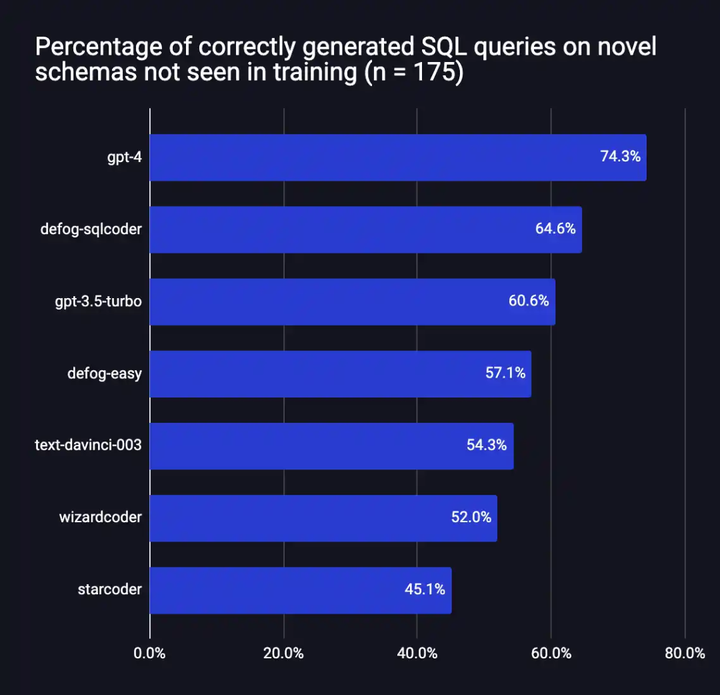 これらの結果は汎用 SQL データベースに関するものであり、単一のデータベース スキーマにおける SQLCoder のパフォーマンスを反映するものではありません。単一のデータベース スキーマを微調整する場合、SQLCoder は、OpenAI の GPT-4 と同等以上のパフォーマンスを発揮し、待ち時間が短くなります (A100 80GB 上)。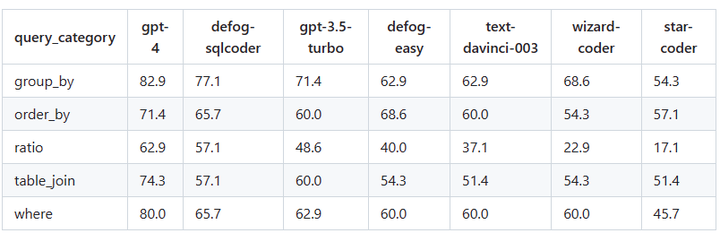 *生成された各問題を 5 つのカテゴリに分割し、各モデルがカテゴリごとに正答した問題の割合を示します。 *## **SQLCoder のハードウェア要件**SQLCoder は、重みを付けた A100 40GB GPU でテストされています。また、RTX 4090、RTX 3090、Apple の M2 Pro、M2 Max、または M2 Ultra チップなど、20 GB 以上のメモリを搭載したコンシューマー グレードの GPU にモデルの 8 ビットおよび 4 ビット量子化バージョンをロードすることもできます。 20GB以上のメモリ。## **次の仕事**今後数週間以内に、作成者は SQLCoder に次の更新を加える予定です。* 人間が収集したより多くのデータと幅広い質問を使用してモデルをトレーニングします。* 報酬モデリングと RLHF を使用してモデルをさらに微調整します。※データ分析に特化したモデル(SQL+Python)を一から事前学習します。
15Bモデルの単体能力はGPT3.5を超え、オープンソースのSQLCoderを採用
コード編集に関して知っている大きなモデル ツールは何ですか?
Twitter ユーザー @lvwerra は、コードファミリーのほとんどのメンバーを分類するために以下の画像を作成しました。
SQLCoder
SOTA 大規模言語モデルとして、SQLCoder は自然言語の質問を SQL クエリに変換します。開発者のオープンソース評価フレームワークである SQL では、SQLCoder はすべての主要なオープンソース モデルを大幅に上回り、OpenAI の GPT-3.5 を上回ります。
SQLCoder は 15B パラメータの LLM であり、StarCoder の微調整された実装でもあります。 SQLCoder は、難易度が高くなる手作りの SQL クエリに合わせて微調整されています。単一のデータベース スキーマに合わせて微調整すると、そのパフォーマンスは GPT-4 と同等かそれ以上になります。
過去 3 か月間で、SQLCoder は医療、金融、その他の企業に導入されました。これらの企業は多くの場合、自社のサーバーから外したくない機密データを保有しているため、LLM を使用できる唯一の方法はセルフホスト モデルを利用することです。
## 方法
データセットを作成
著者らは、テキストから SQL へのタスクに焦点を当てて、手作業で編集された補完ペア データセットを作成しました。データセットは、さまざまな難易度の質問を含む 10 の異なるパターンから作成されました。さらに、7 つの新しいパターンからの 175 の質問からなる評価データセットを作成しました。
テーブルが 1 つまたは 2 つしかないスキーマでは関係が限られているため、単純で単純なクエリが可能になる傾向があるため、トレーニング データセットと評価データセットの両方で 4 ~ 20 のテーブルを持つ複雑なスキーマが選択されるようにしました。
質問カテゴリ
データセットの作成後、作成者はデータセット内の各質問を、簡単、中程度、難しい、および非常に難しいの 4 つのカテゴリに分類しました。この分類は、SQL の難易度を測定するために Spider データセットで使用される基準を適応させることによって行われます。最後に、彼らはデータセットを、簡単と中程度、およびハードと超ハードの 2 つの異なるサブセクションに分割しました。
微調整
著者らは次の 2 段階でモデルを微調整しました。
まず、StarCoder の基本モデルは、簡単な問題と中程度の難易度の問題についてのみ微調整されました。
次に、取得したモデル (defog-easy としてコード化) を難しい問題および超難しい問題で微調整して、SQLcoder を取得します。
評価する
著者らは、自分たちで作成したカスタム データセットでモデルを評価しました。 SQL クエリの正しさを評価することは非常に難しく、評価基準として GPT-4 を使用することも検討されましたが、多くの問題が発生しました。その過程で、2 つの異なる SQL クエリが両方とも正しい可能性があることにも気づきました。
「トロントの最後の 10 人のユーザーは誰ですか」という質問については、次のクエリ形式は両方とも正解です。
データセットをリリースする目的は、利用可能なベンチマークを強化し、研究者やエンジニアが text-to-SQL 生成モデルのパフォーマンス、特に列の名前変更、列の追加、並べ替えなど、返された結果の無害な変更に対するモデルの応答をより深く理解できるようにすることです)。堅牢性。
パフォーマンス
評価フレームワークでは、Defog SQLCoder は GPT-4 を除くすべての主要モデルよりも優れています。特に、2 つのモデルの 10 倍以上のサイズを持つ gpt-3.5-turbo および text-davinci-003 よりも優れたパフォーマンスを発揮します。
SQLCoder のハードウェア要件
SQLCoder は、重みを付けた A100 40GB GPU でテストされています。また、RTX 4090、RTX 3090、Apple の M2 Pro、M2 Max、または M2 Ultra チップなど、20 GB 以上のメモリを搭載したコンシューマー グレードの GPU にモデルの 8 ビットおよび 4 ビット量子化バージョンをロードすることもできます。 20GB以上のメモリ。
次の仕事
今後数週間以内に、作成者は SQLCoder に次の更新を加える予定です。