出典: ハート・オブ・ザ・マシン編集者: Du Wei、Chen Ping本日、Meta のオープンソース Llama モデル ファミリーに、コード生成に特化した基本モデルである Code Llama という新しいメンバーが加わりました。Llama 2 のコード固有のバージョンとして、Code Llama はさらに微調整され、特定のコード データセットでトレーニングされます。Meta氏は、Code Llamaのオープンソース契約はLlama 2と同様、研究目的や商業目的には無料であると述べた。 関連論文「Code Llama: Open Foundation Models for Code」が出版されており、47 ページ、25 人の著者が参加しています。 用紙のアドレス:GitHub アドレス:Code Llama シリーズのモデルには、パラメータ量 **7B、13B、および 34B** の 3 つのバージョンがあります。また、Python、C++、Java、PHP、Type (Java)、C#、Bash などの複数のプログラミング言語をサポートしています。Code Llama は、最大 100,000 個のトークンのコンテキスト生成を安定してサポートします。以下の図 2 は、Code Llama の微調整プロセスを示しています。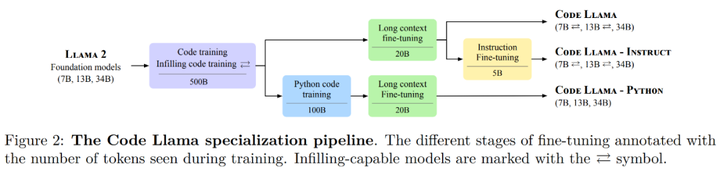 その効果という点では、Human および MBPP データセット上の Code Llama のさまざまなバージョンの合格率 (pass@1) は GPT-3.5 を超える可能性があります。さらに、Human データセット上の Code Llama の「Unnatural」34B バージョンの pass@1 は GPT-4 (62.2% 対 67.0%) に近いです。 Meta はこのバージョンをリリースしませんでしたが、少量の高品質のエンコード データでトレーニングすることにより、大幅なパフォーマンスの向上を達成しました。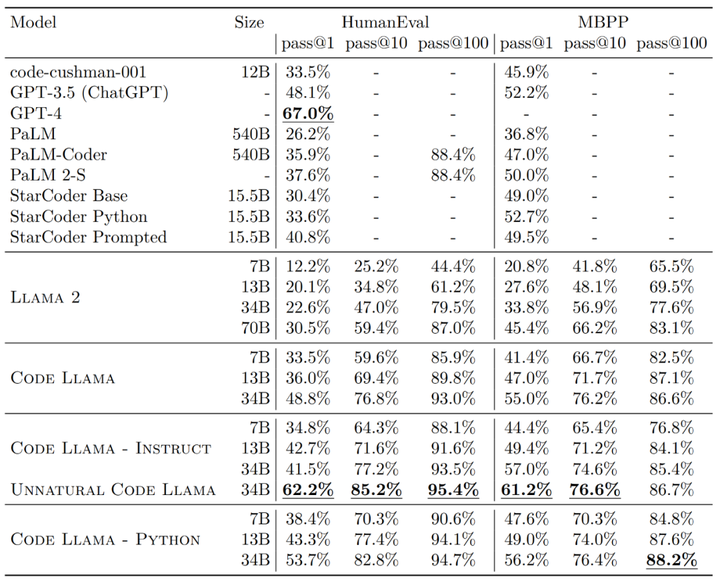 この特別版は、Tesla の元 AI ディレクターで OpenAI に復帰した Andrej Karpathy 氏を含む多くの人々の注目を集めました。記事では「15,000の不自然な命令に基づいて微調整されたコードLlama-Python 34Bバージョン」であると述べられていますが、Karpathyは依然としてこの「謎の名前、曖昧な説明、そして他の機密性モデルの粉砕」に興味を持っています。## **Code Llama の仕組み**Code Llama は非常に強力なコーディング機能を備えており、コードと自然言語プロンプト (たとえば、「フィボナッチ数列を出力する関数の作成を手伝ってください」というユーザー入力プロンプト) に基づいてコードを生成できます。また、ユーザーのコード補完やデバッグにも役立ちます。コード。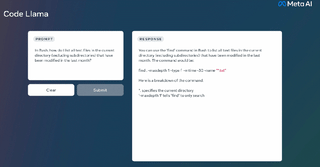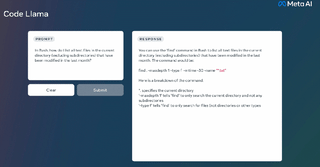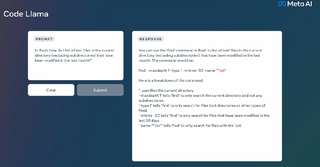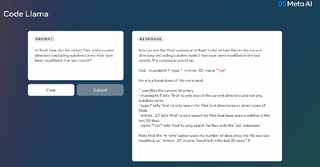 Code Llama モデルの 3 つのパラメーター バージョンは、500B コード トークンとコード関連データを使用してトレーニングされます。 7B および 13B のベース モデルと命令モデルも FIM (fill-in-the-middle) トレーニングされており、既存のコードにコードを挿入できるため、すぐにコード補完などのタスクをサポートできます。次の表は、Code Llama の学習データセットです。 3 つのモデルすべてで、さまざまなサービスと遅延の要件を満たすことができます。たとえば、7B モデルは単一の GPU で実行できます。34B モデルは最良の結果を返し、より優れたエンコード支援を提供しますが、速度の点では、より小型の 7B および 13B モデルの方が高速であり、次のような低遅延タスクに適しています。ライブコード補完。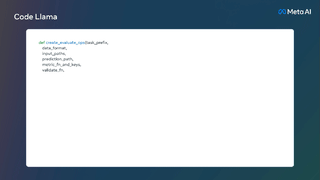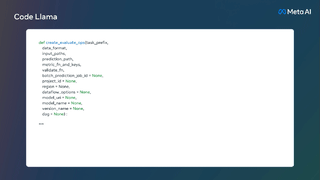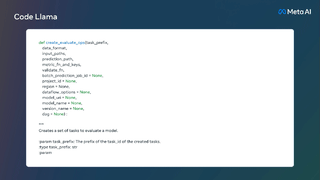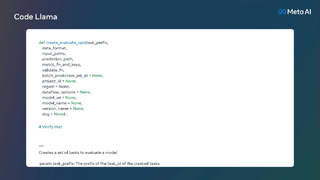 Code Llama は、最大 100,000 個のコンテキスト トークンの安定した生成を提供するだけでなく、すべてのモデルに対して最大 16,000 個のトレーニング トークン シーケンスも提供します。 **より長いプログラムを生成するための前提条件であるだけでなく、より長い入力シーケンスを持つことは、Code Llama に新しい機能ももたらします。たとえば、ユーザーはコードベースからのより多くのコンテキストをモデルに提供して、生成されたコードの関連性を高めることができます。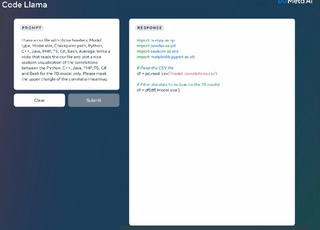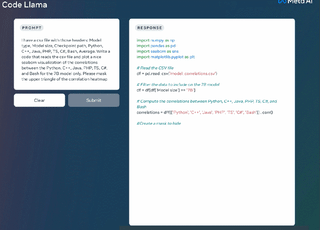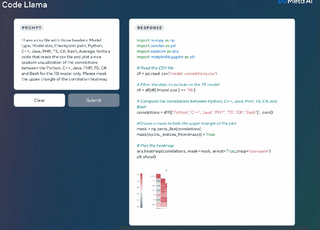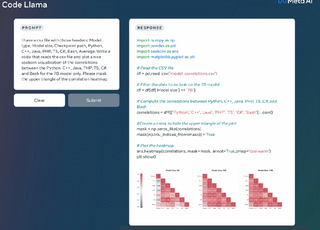 Meta には、**Code Llama - Python と Code Llama - Instruct という 2 つの追加バリアントを備えたさらに微調整された Code Llama があることは言及する価値があります。 **Code Llama-Python は Code Llama のバリアントで、Python コードの 100B トークンに基づいてさらに微調整されています。次の表は、Code Llama-Python の学習データセットです。 Code Llama - Instruct は、入力プロンプトをよりよく理解するための Code Llama の命令ナッジおよび調整されたバリアントです。コード生成に Code Llama を使用する場合は、Code Llama - Instruct バリアントを使用することをお勧めします。Code Llama - Instruct は、自然言語で有用かつ安全な回答を生成するように微調整されているためです。Meta は、どちらのモデルも自然言語の命令に従うように設計されていないため、一般的な自然言語タスクに Code Llama または Code Llama - Python を使用することは推奨しないと述べています。 Code Llama はコード固有のタスク用に設計されており、他のタスクの基本モデルとしては適していません。Code Llama モデルを使用する場合、ユーザーはライセンスと使用ポリシーに従う必要があります。## **Code Llama はどのように実行されますか**Meta は、Human と MBPP (Mostly Basic Python Programming) という 2 つのコーディング ベンチマークをテストに使用します。このうち、ヒューマン テスト モデルはコードを完成させるドキュメント文字列 (docstrings) の能力に基づいており、MBPP テスト モデルはコードを記述する能力に基づいています。結果は、Code Llama がオープンソースのコードタスク固有の LLM よりも優れており、独自の Llama2 よりも優れていることを示しています。たとえば、Code Llama 34B のスコアは Human で 53.7%、MBPP で 56.2% であり、これは他の最先端のオープンソース ソリューションと比較して最高であり、ChatGPT に匹敵します。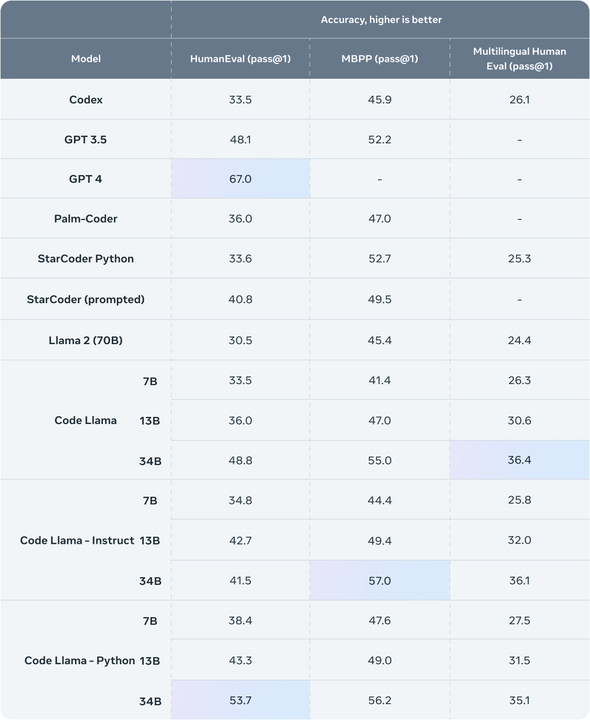 しかし、Code Llama にはリスクもあり、メタ氏は、責任ある AI モデルを構築することが重要であり、Code Llama をリリースする前に多くの安全対策を講じたと述べています。レッドチームのテスト活動の一環として、Meta は Code Llama が悪意のあるコードを生成するリスクの定量的評価を実施しました。彼らは、モデルに悪意のあるコードを生成させるためにヒントを作成し、これらのヒントに対する Code Llama の応答を ChatGPT (GPT3.5 Turbo) と比較しました。 Code Llama の答えはより安全であることがわかりました。この観点から見ると、コーディング能力があまり高くない Llama 2 は、Code Llama によって埋められています。メタ氏は、Code Llama の登場が他の研究者に刺激を与え、Llama 2 をベースにした研究および商用製品用の新しく革新的なツールを作成することを期待しています。参考リンク:
公式 Code Llama オープンソース: 商用利用は無料、謎のバージョンは GPT-4 に近い
出典: ハート・オブ・ザ・マシン
編集者: Du Wei、Chen Ping
本日、Meta のオープンソース Llama モデル ファミリーに、コード生成に特化した基本モデルである Code Llama という新しいメンバーが加わりました。
Llama 2 のコード固有のバージョンとして、Code Llama はさらに微調整され、特定のコード データセットでトレーニングされます。
Meta氏は、Code Llamaのオープンソース契約はLlama 2と同様、研究目的や商業目的には無料であると述べた。
GitHub アドレス:
Code Llama シリーズのモデルには、パラメータ量 7B、13B、および 34B の 3 つのバージョンがあります。また、Python、C++、Java、PHP、Type (Java)、C#、Bash などの複数のプログラミング言語をサポートしています。
Code Llama は、最大 100,000 個のトークンのコンテキスト生成を安定してサポートします。以下の図 2 は、Code Llama の微調整プロセスを示しています。
さらに、Human データセット上の Code Llama の「Unnatural」34B バージョンの pass@1 は GPT-4 (62.2% 対 67.0%) に近いです。 Meta はこのバージョンをリリースしませんでしたが、少量の高品質のエンコード データでトレーニングすることにより、大幅なパフォーマンスの向上を達成しました。
記事では「15,000の不自然な命令に基づいて微調整されたコードLlama-Python 34Bバージョン」であると述べられていますが、Karpathyは依然としてこの「謎の名前、曖昧な説明、そして他の機密性モデルの粉砕」に興味を持っています。
Code Llama の仕組み
Code Llama は非常に強力なコーディング機能を備えており、コードと自然言語プロンプト (たとえば、「フィボナッチ数列を出力する関数の作成を手伝ってください」というユーザー入力プロンプト) に基づいてコードを生成できます。また、ユーザーのコード補完やデバッグにも役立ちます。コード。
次の表は、Code Llama の学習データセットです。
より長いプログラムを生成するための前提条件であるだけでなく、より長い入力シーケンスを持つことは、Code Llama に新しい機能ももたらします。たとえば、ユーザーはコードベースからのより多くのコンテキストをモデルに提供して、生成されたコードの関連性を高めることができます。
Code Llama-Python は Code Llama のバリアントで、Python コードの 100B トークンに基づいてさらに微調整されています。次の表は、Code Llama-Python の学習データセットです。
Meta は、どちらのモデルも自然言語の命令に従うように設計されていないため、一般的な自然言語タスクに Code Llama または Code Llama - Python を使用することは推奨しないと述べています。 Code Llama はコード固有のタスク用に設計されており、他のタスクの基本モデルとしては適していません。
Code Llama モデルを使用する場合、ユーザーはライセンスと使用ポリシーに従う必要があります。
Code Llama はどのように実行されますか
Meta は、Human と MBPP (Mostly Basic Python Programming) という 2 つのコーディング ベンチマークをテストに使用します。このうち、ヒューマン テスト モデルはコードを完成させるドキュメント文字列 (docstrings) の能力に基づいており、MBPP テスト モデルはコードを記述する能力に基づいています。
結果は、Code Llama がオープンソースのコードタスク固有の LLM よりも優れており、独自の Llama2 よりも優れていることを示しています。たとえば、Code Llama 34B のスコアは Human で 53.7%、MBPP で 56.2% であり、これは他の最先端のオープンソース ソリューションと比較して最高であり、ChatGPT に匹敵します。
この観点から見ると、コーディング能力があまり高くない Llama 2 は、Code Llama によって埋められています。メタ氏は、Code Llama の登場が他の研究者に刺激を与え、Llama 2 をベースにした研究および商用製品用の新しく革新的なツールを作成することを期待しています。
参考リンク: