出典: ピンワン作者: 酢「人工知能と同じくらいの知性」。ジョークは人工知能の背後に隠されており、今のところまだ真実です。大学を卒業したばかりのディン・ヤンさんの将来は、刑期の後半に一時的に残されている。丁洋さんは大学時代に軽化学工学を学んでいましたが、卒業後は学科の学生のほとんどが製紙工場に3交代制で働いていたため、彼は工場には行きたくありませんでした。今年 6 月に卒業した Ding Yang さんは海口に戻り、8 月初旬に電子版のトレーニング質問バンクを受講し、2 日後には Wenxin Yiyan の「初心者」データラベラーになりました。海口市秀営区にある中国商人ビルは、かつて文信義のデータラベラーによって「基地」と呼ばれていた。このオフィス ビルの 3 つのフロアに分散されたこの基地には 200 人以上の人が出入りしていました。仕事に就く前に機密保持契約に署名する必要があり、ドアに入るときに顔をスキャンする必要がありました。山西省の上司がコンピューターを持っていて、多くのコンピューターをレンタルして送ってくれましたが、地元でこれらの機器をレンタルしている知人は多くありません。「このコンピュータを買うのに 500 元もかかりません。私はかつてホストを使って Xianyu で検索しましたが、60 元の価値がありました。500 元でもっと良いものをインストールできます。」Ding Yang さんは大学入学試験でコンピュータ サイエンスを志願し、その後軽化学工学に転校しましたが、これには興味がなく、代わりに大学でコンピュータとソフトウェア工学の本をたくさん読んだため、すぐにそのことを耳にするようになりました。昨年末、ChatGPTの登場。12 月に ChatGPT アカウントを登録したところ、「その能力は私の予想を超えていました」と彼は言いました。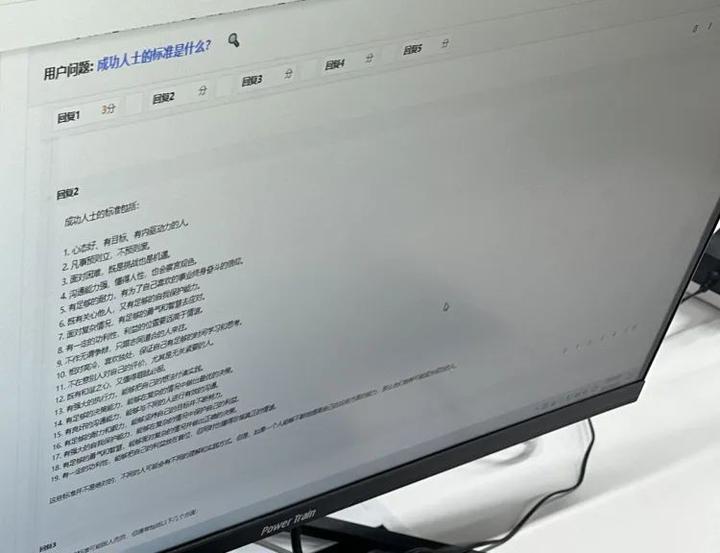 出典: ピンワン基地のワークステーションでディン・ヤンに会ったとき、彼の目の前のコンピューター画面に映った質問は「成功者の基準とは何ですか?」というものだった。これは Wenxin Yiyan ユーザーからの実際の質問である可能性がありますが、何もないところから生成されたテスト問題である可能性もありますが、画面の前に配置されているため、マークする必要があります。ラベルを貼るのは簡単ではありません。このような質問の 1 つに対して、Wen Xin Yiyan からは 5 つの異なる答えが得られます。データラベル作成者はそれを読み、各回答の欠陥をすべて見つけ出す必要があります。たとえば、回答にタイプミスがあったり、「なぜなら」や「だから」などの論理的な単語の使用が間違っていたりするが、回答のほとんどは質問とは無関係であったり、事実に基づかないいわゆる「妄想」が存在したりする。ある段落の根拠。これら 5 つの回答に、回答の質に応じて、満点が 5 ポイント、合計 5 つのレベル、最低 1 ポイントのスコアが与えられます。 3 ポイント以下の回答の場合、Ding Yang は各エラーをラベル付けシステムによって指定されたさまざまなタイプのエラーに分割する必要があります。この複雑なエラー修正プロセスは、適切な報酬モデル RM (報酬モデル、選好モデルとも呼ばれます) をトレーニングして生成することであり、スコアリングと並べ替えのアクションにより、モデルが人間の選好にさらに適合します。これは ChatGPT の成功の鍵でもあり、OpenAI の論文では、命令調整プロセス中に人工知能を人間のアイデアに合わせるプロセスについて説明されています。データラベラーの作業の前に、分岐コーパスを特定の質問と回答のペアに変換し、それを質問例などの大規模なモデルにフィードするために、より専門的な人材が必要です。後者は、多数の質問と回答の後に最適化された後です。データトレーニングが始まります 質問に答えてください。この段階では、データラベラーは大規模モデルによって生成された回答の品質を安全性、精度、関連性の観点から評価し、これらの評価データを使用して報酬モデルをさらにトレーニングします。最終的には、この報酬モデルが手動のラベル付け作業に取って代わることになります。OpenAIの評価額が300億米ドルを超える背景には、時給2米ドル未満のケニア人データラベル作業員が多数存在しており、そうでなければ昨年12月にDing Yangの前に立つことはなかったはずだ。しかし、ディン・ヤンさんはRMやSFTの定義を知らなかったし、始める前のトレーニングにはそのような理論的な内容はなく、ここにいる人の中には彼が何のために働いているのかさえ知らない人もいると語った。しかし、それは問題ではありません、重要なのは物事を成し遂げることです。朝9時から6時までで6日間休みのこの仕事の基本給は1800元だ。 1ヶ月後、1日平均40問マークできれば基本給がもらえます。基本給は修了率に応じて計算され、歩合給も正確な率を考慮する必要があります。長く働いている「ベテラン」の仕事量は 1 日 7 ~ 80 件で安定しており、直面する問題はより困難です。平均すると月に4,000元、もっと頑張れば、例えば毎日100問くらいマークすれば月に7,000元ももらえます。丁陽さんのような新卒者にとって、4,000元はまずまずのスタートが切れる仕事とみなされている。海口住民の平均月収はわずか3000元強で、10人中6人でも月3000元は得られない。地元の有名な後安粉の価格は 11 元で、ChatGPT のタグ付け者は 1 時間で 1 杯買うことができます。それに比べて粉末は高価です。彼によると、海口の人々はあまりお金を稼いでいないが、食費には喜んでお金を使うという。 出典: ピンワン「最も難しいのは株か、車だ」とディン・ヤン氏は語った。この領域で問題が発生するまでに 20 分かかる場合があります。「たとえば、誰かがBMW 3シリーズとメルセデス・ベンツCシリーズのどちらを買うべきかを尋ねるでしょう。」このとき、大きなモデルには、ユーザーが比較できるように2台の車に関する80以上のパラメータがリストされます。彼の後ろを 1 つずつフォローし、各パラメータの信頼性を確認します。半月の作業で数百問の採点が行われたが、印象としては3点取れれば十分で、4点を取ることは稀だという。彼は 4 点を獲得した質問を思い出しました。そのタイトルは「なぜ林大宇は骨の悪魔と戦ったのですか?」でした。ウェン・シンはポールに一言も従わず、骨鬼を倒したのは林大宇ではないことに気づき、林大宇と骨鬼の背景を紹介した。回答の品質のあらゆる側面から見て、これはほぼ完璧です。クロード2にこの疑問を投げかけたところ、「骨鬼は王羲峰となって林大宇を何度も辱め、林大宇は骨鬼を殺したことに激怒した。」――幻覚は確かに十分厄介だ。 出典: ピンワン2020 年の初めに、「人工知能トレーナー」が正式に職業となり、国の職業分類ディレクトリに掲載されましたが、その 2 年後、大型モデルの波が突然、このディレクトリに大きな穴を開けました。人工知能が人間から古い仕事を奪い、それが新しい仕事を生み出すことを期待しています。ちょうど馬車が車に置き換わったように、新しい産業は馬車の御者に、金持ちになるための新しい労働の世界という一般的な比喩を与えるだろう。お金のあるターゲットを探している多くの投資家がこの声明を支持し、中には支持しない人もいるたとえば、彼らはディープラーニングの基礎を築きましたが、今イギリス人のジェフリー・ヒントンは心配しています。しかし、現時点で最も直接的に作成されているのは、Ding Yang のようなビッグ モデル データ ラベラーです。2022 年以前でも、人工知能のフロンティアは依然として、自らを制御できない自動運転車によって定義されています。データラベラーには、次のような冷たい比喩があります。「AI を動物に例えると、データラベラーの仕事は飼料を準備することにほぼ相当します。」仕事は低コストで繰り返しの繰り返しで、フィーダーになるほどではありません。従来のデータラベラーの毎日の仕事は、受信した各画像を注意深く観察し、車や犬の輪郭を丸で囲み、ラベルを付け、別のフォルダーにドラッグ アンド ドロップするか、ドット マトリックスを使用することだけです。このツールは各フレーム内の障害物をマークします。完全な「走行可能領域」を残した走行ビデオ。このようなアクションは、データラベラーによって 1 日に 2,000 回実行される場合があります。人工知能が学習できるのは、ラベル付けされたデータのみです。自動運転データのサプライヤーは、データラベリングの開発以来、データラベリングの自動化の度合いはまだ 5% にすぎず、残りの 95% のラベリング作業は依然として手作業で行われていると述べたことがあります。大型モデルの登場後、データのラベル付けの種類自体が変わり始めました。単に画面上にボックスを描画したり、点を描画したり、線を描画したりするだけではなく、大規模モデル データ ラベラーの主な作業は、生成されたコンテンツの評価、並べ替え、スコアリングになります。複数回の対話やマルチモーダル コンテンツの生成が含まれる場合、難易度がさらに急上昇。従来の CV や NLP 時代のモデル アノテーションが客観的なルールに従って動作する傾向があると言われるなら、大規模モデルのアノテーション ルールはより主観的であり、アノテーション担当者の質も試されます。このため、海口と山西省にある百度の大規模モデルのラベル付けチームは全員が学部生以上です。海口基地の一般的なラベル作成者には、品質検査官に昇進する機会があり、その後、トレーナー、スーパーバイザー、最後にプロジェクトマネージャーになることができます。数か月以内に開設されたチャンネルです。海口市でウェンシン・イーヤンのデータに注釈を付けたエージェントは、試用期間後は社内にポジションがあれば昇進できるが、スケジュールはない、と語った。これは急速に形成されつつある新しい産業です。 「どのリンクも新参者です」とディン・ヤン氏は語った。品質検査官は最初のレビューを完了すると、問題バンクを 2 番目のレビューに渡します。 2 回目のレビューは Baidu の内部で行われ、トレーニング データは Ding Yang のラベル付けチームの管理外でした。Wen Xinyiyan で働く Ding Yang 氏と基地全体の 200 人以上は、Baidu の従業員ではありません。海口基地のラベル作成者は 4 つの異なる機関に所属しています。彼らの労働契約は、これらのサードパーティのデータラベル会社と締結されています。検索から自動運転、大規模モデルに至るまで、Baidu には人工知能に関する長い歴史があり、全国の 600 以上のエージェントと 300 以上の都市の 20 万人のデータラベラーを支えています。百度は常勤の大規模モデルチームの規模を1万人近くを想定しており、将来的には新たな「拠点」として全国10都市以上で実現する計画だ。Baidu Intelligent Cloud Data Annotation Base のプロダクト マネージャーである Hu Chi 氏は、大規模モデルのデータ アノテーターは長期的なキャリアになると考えています。さまざまなシナリオで大規模なモデルの機能が深化するにつれて、新たな問題が発生し、それは新しいラベリング要件も発生することを意味しており、人間は常にそのような熱心な調整を必要とします。丁洋はここを去ると言った。彼と同時に入社した初心者のデータラベル作成者が 20 人以上いましたが、そのほとんどがすぐに辞めてしまいました。ほとんどが自主的に辞めました。退屈な仕事内容、出来高給で稼ぐ方法、人を消費するなど、流動性の高いポジションであることは想像に難くない。そして、人々がどれだけ賞賛しても、機械に取って代わられるという不安は誰もが好むものです。Ding Yang はこれを業界とともに成長する機会と見ています。 AIの波に近いポジションを見つける前に、「スーパーバイザーになれるか試してみてください」と彼は言った。(文中の丁楊は仮名です)
マーク・ウェンシンの言葉、月に4,000元
出典: ピンワン
作者: 酢
「人工知能と同じくらいの知性」。
ジョークは人工知能の背後に隠されており、今のところまだ真実です。大学を卒業したばかりのディン・ヤンさんの将来は、刑期の後半に一時的に残されている。
丁洋さんは大学時代に軽化学工学を学んでいましたが、卒業後は学科の学生のほとんどが製紙工場に3交代制で働いていたため、彼は工場には行きたくありませんでした。今年 6 月に卒業した Ding Yang さんは海口に戻り、8 月初旬に電子版のトレーニング質問バンクを受講し、2 日後には Wenxin Yiyan の「初心者」データラベラーになりました。
海口市秀営区にある中国商人ビルは、かつて文信義のデータラベラーによって「基地」と呼ばれていた。このオフィス ビルの 3 つのフロアに分散されたこの基地には 200 人以上の人が出入りしていました。仕事に就く前に機密保持契約に署名する必要があり、ドアに入るときに顔をスキャンする必要がありました。山西省の上司がコンピューターを持っていて、多くのコンピューターをレンタルして送ってくれましたが、地元でこれらの機器をレンタルしている知人は多くありません。
「このコンピュータを買うのに 500 元もかかりません。私はかつてホストを使って Xianyu で検索しましたが、60 元の価値がありました。500 元でもっと良いものをインストールできます。」
Ding Yang さんは大学入学試験でコンピュータ サイエンスを志願し、その後軽化学工学に転校しましたが、これには興味がなく、代わりに大学でコンピュータとソフトウェア工学の本をたくさん読んだため、すぐにそのことを耳にするようになりました。昨年末、ChatGPTの登場。
12 月に ChatGPT アカウントを登録したところ、「その能力は私の予想を超えていました」と彼は言いました。
基地のワークステーションでディン・ヤンに会ったとき、彼の目の前のコンピューター画面に映った質問は「成功者の基準とは何ですか?」というものだった。
これは Wenxin Yiyan ユーザーからの実際の質問である可能性がありますが、何もないところから生成されたテスト問題である可能性もありますが、画面の前に配置されているため、マークする必要があります。
ラベルを貼るのは簡単ではありません。
このような質問の 1 つに対して、Wen Xin Yiyan からは 5 つの異なる答えが得られます。データラベル作成者はそれを読み、各回答の欠陥をすべて見つけ出す必要があります。
たとえば、回答にタイプミスがあったり、「なぜなら」や「だから」などの論理的な単語の使用が間違っていたりするが、回答のほとんどは質問とは無関係であったり、事実に基づかないいわゆる「妄想」が存在したりする。ある段落の根拠。
これら 5 つの回答に、回答の質に応じて、満点が 5 ポイント、合計 5 つのレベル、最低 1 ポイントのスコアが与えられます。 3 ポイント以下の回答の場合、Ding Yang は各エラーをラベル付けシステムによって指定されたさまざまなタイプのエラーに分割する必要があります。
この複雑なエラー修正プロセスは、適切な報酬モデル RM (報酬モデル、選好モデルとも呼ばれます) をトレーニングして生成することであり、スコアリングと並べ替えのアクションにより、モデルが人間の選好にさらに適合します。
これは ChatGPT の成功の鍵でもあり、OpenAI の論文では、命令調整プロセス中に人工知能を人間のアイデアに合わせるプロセスについて説明されています。
データラベラーの作業の前に、分岐コーパスを特定の質問と回答のペアに変換し、それを質問例などの大規模なモデルにフィードするために、より専門的な人材が必要です。後者は、多数の質問と回答の後に最適化された後です。データトレーニングが始まります 質問に答えてください。
この段階では、データラベラーは大規模モデルによって生成された回答の品質を安全性、精度、関連性の観点から評価し、これらの評価データを使用して報酬モデルをさらにトレーニングします。最終的には、この報酬モデルが手動のラベル付け作業に取って代わることになります。
OpenAIの評価額が300億米ドルを超える背景には、時給2米ドル未満のケニア人データラベル作業員が多数存在しており、そうでなければ昨年12月にDing Yangの前に立つことはなかったはずだ。
しかし、ディン・ヤンさんはRMやSFTの定義を知らなかったし、始める前のトレーニングにはそのような理論的な内容はなく、ここにいる人の中には彼が何のために働いているのかさえ知らない人もいると語った。しかし、それは問題ではありません、重要なのは物事を成し遂げることです。
朝9時から6時までで6日間休みのこの仕事の基本給は1800元だ。 1ヶ月後、1日平均40問マークできれば基本給がもらえます。基本給は修了率に応じて計算され、歩合給も正確な率を考慮する必要があります。長く働いている「ベテラン」の仕事量は 1 日 7 ~ 80 件で安定しており、直面する問題はより困難です。平均すると月に4,000元、もっと頑張れば、例えば毎日100問くらいマークすれば月に7,000元ももらえます。
丁陽さんのような新卒者にとって、4,000元はまずまずのスタートが切れる仕事とみなされている。海口住民の平均月収はわずか3000元強で、10人中6人でも月3000元は得られない。地元の有名な後安粉の価格は 11 元で、ChatGPT のタグ付け者は 1 時間で 1 杯買うことができます。それに比べて粉末は高価です。彼によると、海口の人々はあまりお金を稼いでいないが、食費には喜んでお金を使うという。
「最も難しいのは株か、車だ」とディン・ヤン氏は語った。この領域で問題が発生するまでに 20 分かかる場合があります。
「たとえば、誰かがBMW 3シリーズとメルセデス・ベンツCシリーズのどちらを買うべきかを尋ねるでしょう。」このとき、大きなモデルには、ユーザーが比較できるように2台の車に関する80以上のパラメータがリストされます。彼の後ろを 1 つずつフォローし、各パラメータの信頼性を確認します。
半月の作業で数百問の採点が行われたが、印象としては3点取れれば十分で、4点を取ることは稀だという。
彼は 4 点を獲得した質問を思い出しました。そのタイトルは「なぜ林大宇は骨の悪魔と戦ったのですか?」でした。
ウェン・シンはポールに一言も従わず、骨鬼を倒したのは林大宇ではないことに気づき、林大宇と骨鬼の背景を紹介した。回答の品質のあらゆる側面から見て、これはほぼ完璧です。
クロード2にこの疑問を投げかけたところ、「骨鬼は王羲峰となって林大宇を何度も辱め、林大宇は骨鬼を殺したことに激怒した。」――幻覚は確かに十分厄介だ。
2020 年の初めに、「人工知能トレーナー」が正式に職業となり、国の職業分類ディレクトリに掲載されましたが、その 2 年後、大型モデルの波が突然、このディレクトリに大きな穴を開けました。
人工知能が人間から古い仕事を奪い、それが新しい仕事を生み出すことを期待しています。ちょうど馬車が車に置き換わったように、新しい産業は馬車の御者に、金持ちになるための新しい労働の世界という一般的な比喩を与えるだろう。お金のあるターゲットを探している多くの投資家がこの声明を支持し、中には支持しない人もいるたとえば、彼らはディープラーニングの基礎を築きましたが、今イギリス人のジェフリー・ヒントンは心配しています。
しかし、現時点で最も直接的に作成されているのは、Ding Yang のようなビッグ モデル データ ラベラーです。
2022 年以前でも、人工知能のフロンティアは依然として、自らを制御できない自動運転車によって定義されています。データラベラーには、次のような冷たい比喩があります。
「AI を動物に例えると、データラベラーの仕事は飼料を準備することにほぼ相当します。」
仕事は低コストで繰り返しの繰り返しで、フィーダーになるほどではありません。
従来のデータラベラーの毎日の仕事は、受信した各画像を注意深く観察し、車や犬の輪郭を丸で囲み、ラベルを付け、別のフォルダーにドラッグ アンド ドロップするか、ドット マトリックスを使用することだけです。このツールは各フレーム内の障害物をマークします。完全な「走行可能領域」を残した走行ビデオ。
このようなアクションは、データラベラーによって 1 日に 2,000 回実行される場合があります。
人工知能が学習できるのは、ラベル付けされたデータのみです。自動運転データのサプライヤーは、データラベリングの開発以来、データラベリングの自動化の度合いはまだ 5% にすぎず、残りの 95% のラベリング作業は依然として手作業で行われていると述べたことがあります。
大型モデルの登場後、データのラベル付けの種類自体が変わり始めました。単に画面上にボックスを描画したり、点を描画したり、線を描画したりするだけではなく、大規模モデル データ ラベラーの主な作業は、生成されたコンテンツの評価、並べ替え、スコアリングになります。複数回の対話やマルチモーダル コンテンツの生成が含まれる場合、難易度がさらに急上昇。
従来の CV や NLP 時代のモデル アノテーションが客観的なルールに従って動作する傾向があると言われるなら、大規模モデルのアノテーション ルールはより主観的であり、アノテーション担当者の質も試されます。このため、海口と山西省にある百度の大規模モデルのラベル付けチームは全員が学部生以上です。
海口基地の一般的なラベル作成者には、品質検査官に昇進する機会があり、その後、トレーナー、スーパーバイザー、最後にプロジェクトマネージャーになることができます。数か月以内に開設されたチャンネルです。海口市でウェンシン・イーヤンのデータに注釈を付けたエージェントは、試用期間後は社内にポジションがあれば昇進できるが、スケジュールはない、と語った。
これは急速に形成されつつある新しい産業です。 「どのリンクも新参者です」とディン・ヤン氏は語った。
品質検査官は最初のレビューを完了すると、問題バンクを 2 番目のレビューに渡します。 2 回目のレビューは Baidu の内部で行われ、トレーニング データは Ding Yang のラベル付けチームの管理外でした。
Wen Xinyiyan で働く Ding Yang 氏と基地全体の 200 人以上は、Baidu の従業員ではありません。
海口基地のラベル作成者は 4 つの異なる機関に所属しています。彼らの労働契約は、これらのサードパーティのデータラベル会社と締結されています。検索から自動運転、大規模モデルに至るまで、Baidu には人工知能に関する長い歴史があり、全国の 600 以上のエージェントと 300 以上の都市の 20 万人のデータラベラーを支えています。
百度は常勤の大規模モデルチームの規模を1万人近くを想定しており、将来的には新たな「拠点」として全国10都市以上で実現する計画だ。
Baidu Intelligent Cloud Data Annotation Base のプロダクト マネージャーである Hu Chi 氏は、大規模モデルのデータ アノテーターは長期的なキャリアになると考えています。さまざまなシナリオで大規模なモデルの機能が深化するにつれて、新たな問題が発生し、それは新しいラベリング要件も発生することを意味しており、人間は常にそのような熱心な調整を必要とします。
丁洋はここを去ると言った。
彼と同時に入社した初心者のデータラベル作成者が 20 人以上いましたが、そのほとんどがすぐに辞めてしまいました。ほとんどが自主的に辞めました。退屈な仕事内容、出来高給で稼ぐ方法、人を消費するなど、流動性の高いポジションであることは想像に難くない。そして、人々がどれだけ賞賛しても、機械に取って代わられるという不安は誰もが好むものです。
Ding Yang はこれを業界とともに成長する機会と見ています。 AIの波に近いポジションを見つける前に、「スーパーバイザーになれるか試してみてください」と彼は言った。
(文中の丁楊は仮名です)