> CMU と清華大学の研究者は共同で、ユーザー入力に基づいて小規模なプロフェッショナル モデルを迅速にトレーニングできる 2Model フレームワークをリリースしました。データ収集にわずか 5 ドルの投資と 20 分のトレーニング時間で、モデル パラメーターのサイズを 700 分の 1 に削減しながら、ChatGPT の平均を 20% 上回る小さなモデルを取得できます。 画像ソース: Unbounded AI によって生成大規模言語モデリング (LLM) を使用すると、ユーザーはヒントと文脈学習を利用して強力な自然言語処理システムを構築できます。ただし、別の観点から見ると、特定の自然言語処理タスクにおける LLM のパフォーマンスには、特定の回帰の問題があります。これらのモデルの展開には大量のコンピューティング リソースが必要であり、API を介してモデルと対話すると、潜在的なプライバシー問題が発生する可能性があります。これらの問題に対処するために、カーネギー メロン大学 (CMU) と清華大学の研究者が共同で 2Model フレームワークを立ち上げました。このフレームワークの目標は、LLM ベースのデータ生成および取得方法を組み合わせて、上記の課題を克服することです。 2Model フレームワークを使用すると、ユーザーは LLM と同じプロンプトを提供するだけで、自動的にデータを収集し、特定のタスクに適した小さな特殊なモデルを効率的にトレーニングできます。研究者らは 3 つの自然言語処理サブタスクに関する実験を実施しました。少数のサンプル プロンプトを入力として使用し、データ収集と 20 分間のトレーニングにわずか 5 ドルを費やすだけで、2Model フレームワークによって生成されたモデルは、強力な LLM モデル gpt-3.5-turbo と比較して 20% のパフォーマンス向上を示します。同時に、モデルのサイズは最大 700 分の 1 に縮小されました。研究者らはさらに、実際のシナリオにおけるモデルのパフォーマンスに対するこれらのデータの影響を検証し、モデル開発者が展開前にモデルの信頼性を推定できるようにしました。このフレームワークはすでにオープンソースとして利用可能です。 * フレームワークの GitHub リポジトリ アドレス:* フレームワークのデモビデオリンク:* フレームワーク関連の論文へのリンク:## **背景**特定の自然言語処理タスクのためにシステムを最初から構築することは、多くの場合非常に複雑です。システムの構築者は、タスクの範囲を明確に定義し、特定のデータセットを取得し、適切なモデル アーキテクチャを選択し、モデルのトレーニングと評価を実施して、実際のアプリケーションに展開する必要があります。GPT-3 などの大規模言語モデル (LLM) は、このプロセスに対する簡単なソリューションを提供します。ユーザーはタスク プロンプト (指示) といくつかの例 (例) を提供するだけで、LLM は対応するテキスト出力を生成できます。ただし、ヒントからテキストを生成すると計算量が多くなる可能性があり、ヒントの使用は特別にトレーニングされたモデルほど安定していません。さらに、LLM の使いやすさは、コスト、速度、プライバシーによって制限されます。これらの問題を克服するために、研究者は 2Model フレームワークを開発しました。このフレームワークは、LLM ベースのデータ生成と取得技術を組み合わせて、上記の制限に対処します。システムはまずそこから重要な情報を抽出し、次にトレーニング データを生成して取得し、最後に展開の準備ができた特殊なモデルを生成します。2Model フレームワークは、次の主要な手順を自動化します。* データセットとモデルの取得: 関連するデータセットと事前トレーニングされたモデルを収集します。* データセットの生成: LLM を活用して、擬似ラベル付きデータセットを作成します。* モデルの微調整: 取得したデータと生成されたデータを混合してモデルを微調整します。* モデルのテスト: ユーザーが提供したテスト データ セットと実際のデータ セットでモデルをテストします。複数の異なるタスクの経験的評価の結果、2Model のコストは大幅に削減され、モデルのサイズも大幅に縮小されましたが、パフォーマンスは gpt-3.5-turbo を上回りました。 2Model フレームワークは、自然言語処理システムを効率的に構築するためのツールとして機能するだけでなく、モデル アンサンブル トレーニング手法を探索するためのプラットフォームとしても機能します。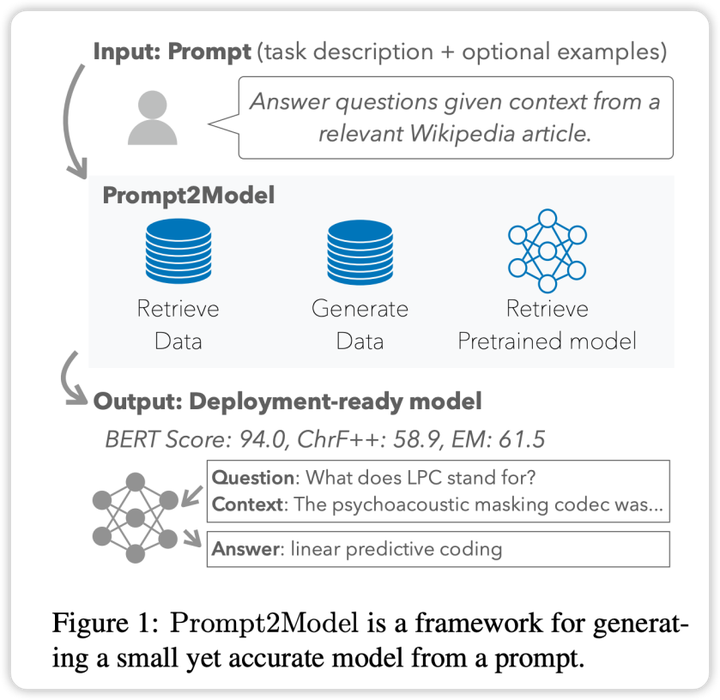## **フレームワーク**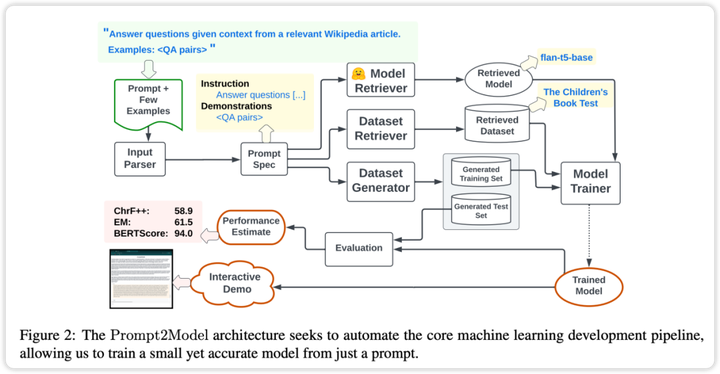 2Model フレームワークの中核となる機能は、高度な自動化です。上の図に示すように、そのプロセスは、データ収集、モデルのトレーニング、評価、展開などの複数のリンクをカバーします。中でも自動データ収集システムは重要な役割を果たしており、データセットの検索とLLMベースのデータ生成を通じてユーザーのニーズに密接に関連したデータを取得します。次に、システムは事前トレーニングされたモデルを取得し、取得したデータセットに基づいて微調整します。最後に、トレーニングされたモデルがテスト セットで評価され、モデルと対話するための Web ユーザー インターフェイス (UI) が作成されます。2Model フレームワークの主な機能は次のとおりです。* ドライバー: 2Model の中心的なアイデアは、ドライバーとして使用することであり、ユーザーは機械学習の具体的な実装の詳細に入ることなく、必要なタスクを直接記述することができます。* 自動データ収集: このフレームワークは、データセットの取得および生成技術を使用して、ユーザーのタスクに高度に一致するデータを取得し、それによってトレーニングに必要なデータセットを確立します。* 事前トレーニングされたモデル: フレームワークは事前トレーニングされたモデルを利用して微調整し、トレーニングのコストと時間を大幅に節約します。※効果評価:2Modelは実際のデータセットでのモデルのテストと評価をサポートしており、モデル導入前の事前予測や性能評価が可能となり、モデルの信頼性が向上します。これらの特性により、2Model フレームワークは、自然言語処理システムの構築プロセスを効率的に完了し、自動データ収集、モデル評価、ユーザー対話インターフェイスの作成などの高度な機能を提供できる強力なツールとなっています。## **実験と結果**実験計画の観点から、研究者らは 2Model システムのパフォーマンスを評価するために 3 つの異なるタスクを選択しました。※機械読み取りQA:実際の評価データセットとしてSQuADを使用します。* 日本語 NL-to-Code: 実際の評価データセットとして MCoNaLa を使用します。* 時間表現の正規化: 時間データ セットを実際の評価データ セットとして使用します。さらに、研究者らは比較のためのベンチマーク モデルとして GPT-3.5-turbo も選択しました。実験結果から次の結論が得られます。* コード生成タスクを除くすべてのタスクにおいて、2Model システムによって生成されたモデルは、ベースライン モデル GPT-3.5-turbo よりも大幅に優れていますが、生成されたモデルのパラメーター サイズは GPT-3.5-turbo のパラメーター サイズよりもはるかに小さいです。※取得したデータセットと生成したデータセットを混合して学習させることで、実際のデータセットを直接学習させた場合と同等の効果を得ることができます。これは、2Model フレームワークが手動アノテーションのコストを大幅に削減できることを証明します。* データ ジェネレーターによって生成されたテスト データ セットは、実際のデータ セットでのさまざまなモデルのパフォーマンスを効果的に区別できます。これは、生成されたデータが高品質であり、モデルのトレーニングに十分な効果があることを示しています。* 日本語からコードへの変換タスクでは、2Model システムは GPT-3.5-turbo ほどパフォーマンスが良くありません。これは、生成されたデータセットの品質が低いことや、適切な事前トレーニング済みモデルが欠如していることなどが原因である可能性があります。総合すると、2Model システムは複数のタスクにわたって高品質の小さなモデルを生成することに成功し、手動で注釈を付けたデータの必要性を大幅に削減します。ただし、一部のタスクではまださらなる改善が必要です。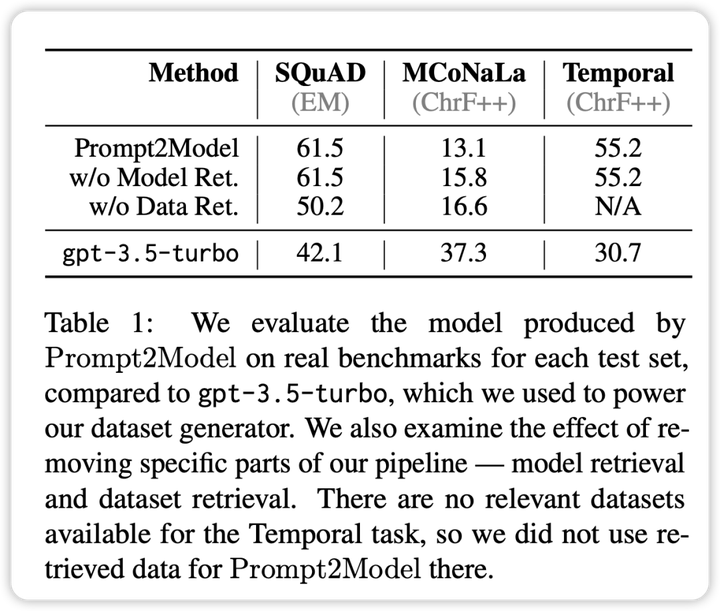 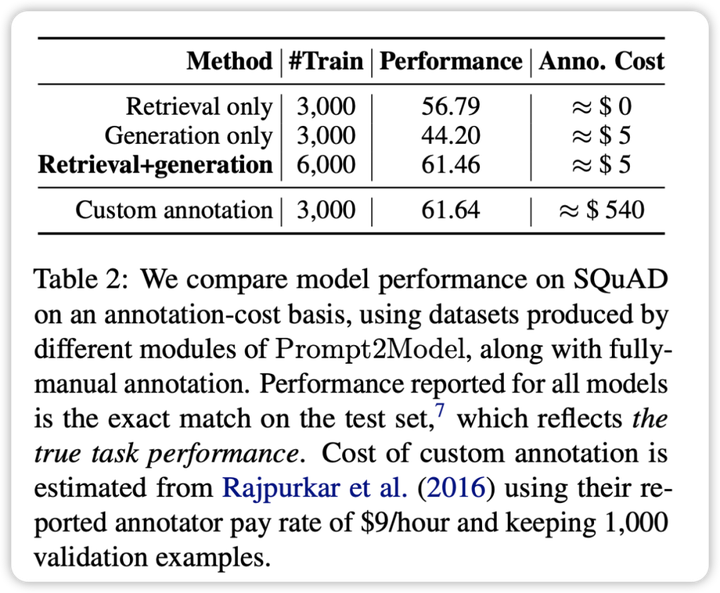## **要約**研究チームが立ち上げた2Modelフレームワークは、自然言語プロンプトのみでタスク固有のモデルを自動構築する機能を実現する。この革新により、カスタマイズされた自然言語処理モデルを構築するための敷居が大幅に下がり、NLP テクノロジーの適用範囲がさらに拡大します。検証実験の結果、2Model フレームワークによって生成されたモデルは、大規模な言語モデルよりもサイズが大幅に小さく、複数のタスクにおいて GPT-3.5-turbo などのモデルよりも優れたパフォーマンスを発揮することがわかりました。同時に、このフレームワークによって生成された評価データ セットは、実際のデータ セットでのさまざまなモデルのパフォーマンスを評価するのに効果的であることも証明されています。これは、モデルの最終的な展開をガイドする上で重要な価値をもたらします。2Model フレームワークは、業界や幅広いユーザーが特定のニーズを満たす NLP モデルを取得できる、低コストで使いやすいアプローチを提供します。これは、NLP テクノロジーの幅広い応用を促進する上で非常に重要です。今後の作業は、フレームワークのパフォーマンスをさらに最適化することに引き続き焦点を当てていきます。
1 つの命令 + 5 米ドル + 20 分で、小さなプロのモデルをトレーニングできます。_2Model 詳細はこちら
大規模言語モデリング (LLM) を使用すると、ユーザーはヒントと文脈学習を利用して強力な自然言語処理システムを構築できます。ただし、別の観点から見ると、特定の自然言語処理タスクにおける LLM のパフォーマンスには、特定の回帰の問題があります。これらのモデルの展開には大量のコンピューティング リソースが必要であり、API を介してモデルと対話すると、潜在的なプライバシー問題が発生する可能性があります。
これらの問題に対処するために、カーネギー メロン大学 (CMU) と清華大学の研究者が共同で 2Model フレームワークを立ち上げました。このフレームワークの目標は、LLM ベースのデータ生成および取得方法を組み合わせて、上記の課題を克服することです。 2Model フレームワークを使用すると、ユーザーは LLM と同じプロンプトを提供するだけで、自動的にデータを収集し、特定のタスクに適した小さな特殊なモデルを効率的にトレーニングできます。
研究者らは 3 つの自然言語処理サブタスクに関する実験を実施しました。少数のサンプル プロンプトを入力として使用し、データ収集と 20 分間のトレーニングにわずか 5 ドルを費やすだけで、2Model フレームワークによって生成されたモデルは、強力な LLM モデル gpt-3.5-turbo と比較して 20% のパフォーマンス向上を示します。同時に、モデルのサイズは最大 700 分の 1 に縮小されました。研究者らはさらに、実際のシナリオにおけるモデルのパフォーマンスに対するこれらのデータの影響を検証し、モデル開発者が展開前にモデルの信頼性を推定できるようにしました。このフレームワークはすでにオープンソースとして利用可能です。
## 背景
特定の自然言語処理タスクのためにシステムを最初から構築することは、多くの場合非常に複雑です。システムの構築者は、タスクの範囲を明確に定義し、特定のデータセットを取得し、適切なモデル アーキテクチャを選択し、モデルのトレーニングと評価を実施して、実際のアプリケーションに展開する必要があります。
GPT-3 などの大規模言語モデル (LLM) は、このプロセスに対する簡単なソリューションを提供します。ユーザーはタスク プロンプト (指示) といくつかの例 (例) を提供するだけで、LLM は対応するテキスト出力を生成できます。ただし、ヒントからテキストを生成すると計算量が多くなる可能性があり、ヒントの使用は特別にトレーニングされたモデルほど安定していません。さらに、LLM の使いやすさは、コスト、速度、プライバシーによって制限されます。
これらの問題を克服するために、研究者は 2Model フレームワークを開発しました。このフレームワークは、LLM ベースのデータ生成と取得技術を組み合わせて、上記の制限に対処します。システムはまずそこから重要な情報を抽出し、次にトレーニング データを生成して取得し、最後に展開の準備ができた特殊なモデルを生成します。
2Model フレームワークは、次の主要な手順を自動化します。
複数の異なるタスクの経験的評価の結果、2Model のコストは大幅に削減され、モデルのサイズも大幅に縮小されましたが、パフォーマンスは gpt-3.5-turbo を上回りました。 2Model フレームワークは、自然言語処理システムを効率的に構築するためのツールとして機能するだけでなく、モデル アンサンブル トレーニング手法を探索するためのプラットフォームとしても機能します。
## フレームワーク
2Model フレームワークの主な機能は次のとおりです。
これらの特性により、2Model フレームワークは、自然言語処理システムの構築プロセスを効率的に完了し、自動データ収集、モデル評価、ユーザー対話インターフェイスの作成などの高度な機能を提供できる強力なツールとなっています。
実験と結果
実験計画の観点から、研究者らは 2Model システムのパフォーマンスを評価するために 3 つの異なるタスクを選択しました。
※機械読み取りQA:実際の評価データセットとしてSQuADを使用します。
さらに、研究者らは比較のためのベンチマーク モデルとして GPT-3.5-turbo も選択しました。実験結果から次の結論が得られます。
これは、生成されたデータセットの品質が低いことや、適切な事前トレーニング済みモデルが欠如していることなどが原因である可能性があります。
総合すると、2Model システムは複数のタスクにわたって高品質の小さなモデルを生成することに成功し、手動で注釈を付けたデータの必要性を大幅に削減します。ただし、一部のタスクではまださらなる改善が必要です。
要約
研究チームが立ち上げた2Modelフレームワークは、自然言語プロンプトのみでタスク固有のモデルを自動構築する機能を実現する。この革新により、カスタマイズされた自然言語処理モデルを構築するための敷居が大幅に下がり、NLP テクノロジーの適用範囲がさらに拡大します。
検証実験の結果、2Model フレームワークによって生成されたモデルは、大規模な言語モデルよりもサイズが大幅に小さく、複数のタスクにおいて GPT-3.5-turbo などのモデルよりも優れたパフォーマンスを発揮することがわかりました。同時に、このフレームワークによって生成された評価データ セットは、実際のデータ セットでのさまざまなモデルのパフォーマンスを評価するのに効果的であることも証明されています。これは、モデルの最終的な展開をガイドする上で重要な価値をもたらします。
2Model フレームワークは、業界や幅広いユーザーが特定のニーズを満たす NLP モデルを取得できる、低コストで使いやすいアプローチを提供します。これは、NLP テクノロジーの幅広い応用を促進する上で非常に重要です。今後の作業は、フレームワークのパフォーマンスをさらに最適化することに引き続き焦点を当てていきます。