出典: 量子ビット初の中国語と英語のバイリンガル音声対話オープンソース大型モデルが登場!ここ数日、大規模な音声テキストマルチモーダルモデルに関する論文がarXivに掲載され、署名企業の中にKai-fu Lee氏の大規模モデル会社01.ai - 01.ai -の名前が登場しました。 。 この論文では、録音とテキスト入力の両方をサポートする、中国語と英語のバイリンガル **市販** の対話モデル LLaSM を提案します。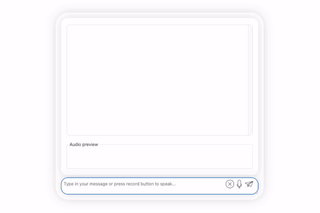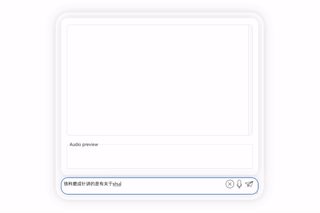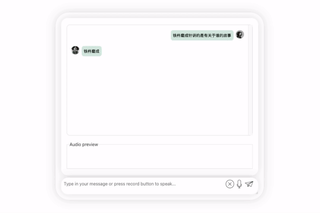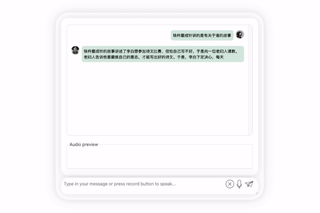 同論文は、「**音声チャット**」は、単なるテキスト入力によるものではなく、AIと人間の間のより便利で自然な対話方法であると考えています。 大型模型を使って、一部のネチズンはすでに「寝転がって話しながらコードを書く」シーンを想像している。 この研究は LinkSoul.AI、北京大学、Zero-One Wansi から提供されており、現在はオープンソースであり、Huahuanglian で直接試すこともできます。 どのように機能するかを見てみましょう。## **テキストと音声入力をサポートし、携帯電話でも再生できます**研究者らによると、LLaSM は、中国語と英語のバイリンガル音声テキストのマルチモーダル対話をサポートする、オープンソースで商用利用可能な初の対話モデルです。それでは、**音声テキスト入力**と**中国語と英語のバイリンガル機能**を見てみましょう。まず第一に、中国語と英語の文化的な衝突をしてみましょう。彼に英語で李白についてコメントしてもらいましょう。 大丈夫、李白の王朝は正しく記載されています。英語が分からない場合は、英語を直接中国語に翻訳しても問題ありません。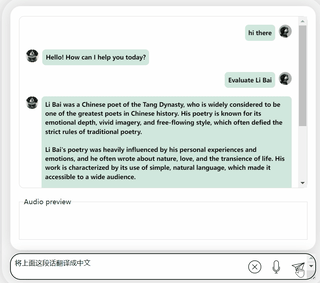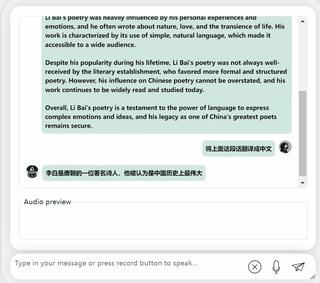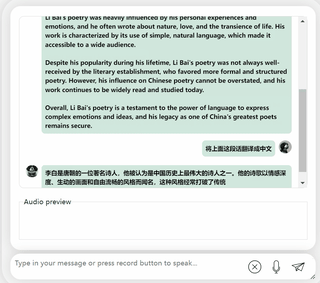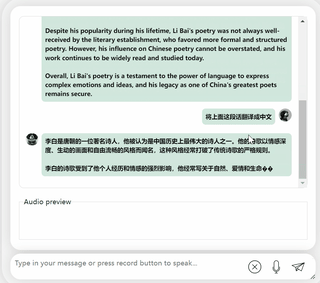 次に、中国語と英語の混合質問を試し、中国語で「揚げ物」を追加すると、モデルの出力も良好になります。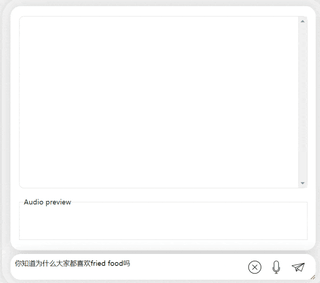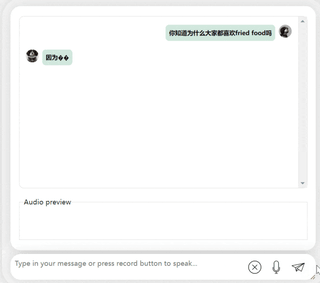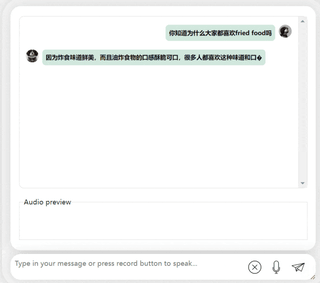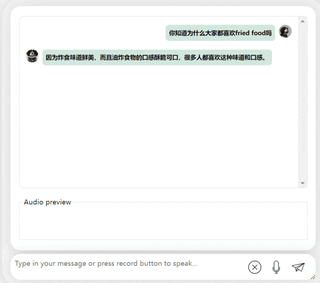 モデルをもう一度試して、李白と杜甫のどちらがより強力であるかを評価してみましょう。しばらく考えた結果、非常に中立的な評価を下したモデルであり、大型モデル(手動犬頭)の基本的な「水を扱う常識」も備えていることが分かります。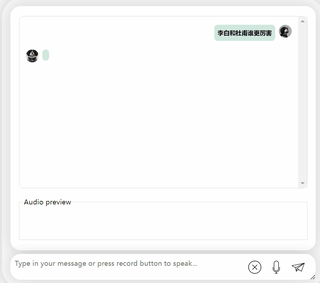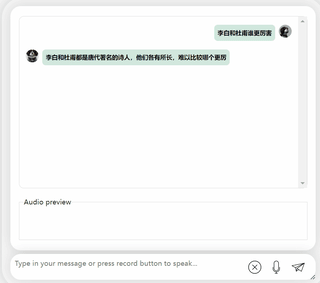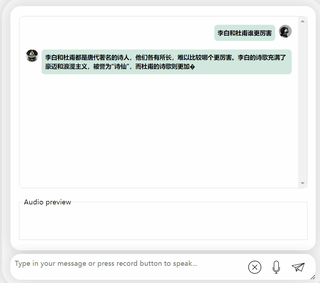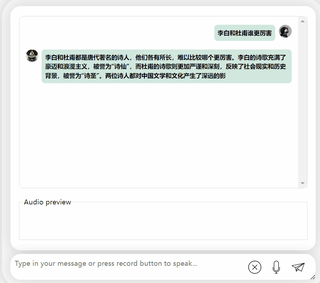 もちろんパソコンだけでなく、携帯電話でもプレイ可能です。**音声**で「レシピを提案してください」と入力してみましょう:モデルが正確に「ナスチーズ」のレシピを出力していることがわかりますが、おいしいかどうかはわかりません。しかし、実際に試してみると、このモデルには時々バグがあることも分かりました。たとえば、「人間の言葉をあまり理解できない」場合があります。中国語と英語が混在したコンテンツを出力するように要求すると、理解できないふりをして英語を出力します。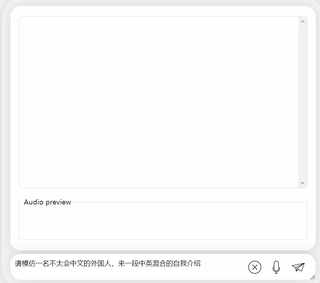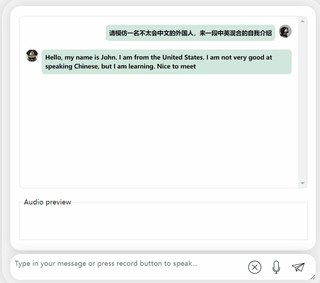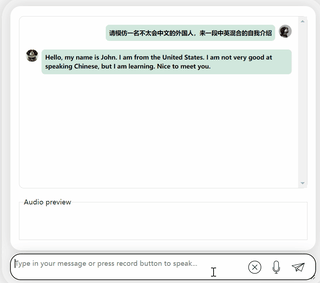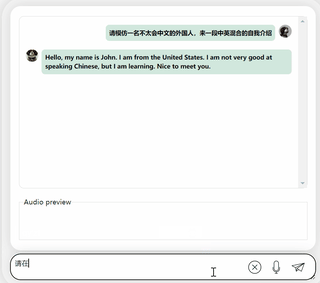 中国語と英語を混ぜて「テイラー・スウィフトのレッド」を聴きたいかと尋ねられると、モデルはすぐに大きなバグに向かい、何度も何度も文章を出力し、止めることさえできませんでした... 一般的に、中国語と英語が混在する質問や要件に遭遇した場合、モデルの出力能力はまだ十分ではありません。しかし、それとは別に、中国語と英語の両方を表現する能力はかなり優れています。では、そのようなモデルはどのように実装されるのでしょうか?## **どんな新しいモデルを作りましたか? **試用プレイから判断すると、LLaSM には主に 2 つの特徴があります。**1 つは中国語と英語の入力に対応し、もう 1 つは音声とテキストの二重入力**です。これら 2 つの点を達成するには、アーキテクチャとトレーニング データでそれぞれいくつかの調整を行う必要があります。**アーキテクチャ上**、LLaSM は現在の音声認識モデルと大規模言語モデルを統合しています。LLaSM は、自動音声認識モデル Whisper、モダリティ アダプター、ラージ モデル LLaMA の 3 つの部分で構成されます。その中で、Whisper は元の音声入力の受信と音声特徴のベクトル表現の出力を担当し、モダリティ アダプターは音声とテキストの埋め込みを調整する責任を負い、LLaMA は音声とテキストの入力命令を理解して応答を生成する責任を負います。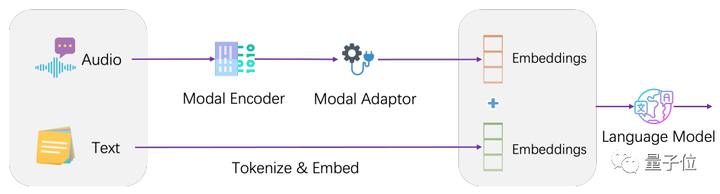 モデルのトレーニングは 2 つの段階に分かれています。第 1 段階では、モーダル アダプターをトレーニングし、エンコーダーと大きなモデルをフリーズします。つまり、音声とテキストの配置を学習させます。第 2 段階では、エンコーダーをフリーズし、モーダル アダプターをトレーニングし、大きなモデル。マルチモーダルな対話機能を学習します。**トレーニング データ**に関して、研究者らは 199,000 の対話と 508,000 の音声テキスト サンプルを含むデータセット LLaSM-Audio-Instructions を編集しました。508,000 の音声テキスト サンプルのうち、80,000 の中国語音声サンプルと 428,000 の英語音声サンプルがあります。研究者は、WizardLM、ShareGPT、GPT-4-LLM などのデータ セットに基づいて、テキスト読み上げテクノロジーを使用して、これらのデータ セットの音声パケットを生成し、無効な会話を除外します。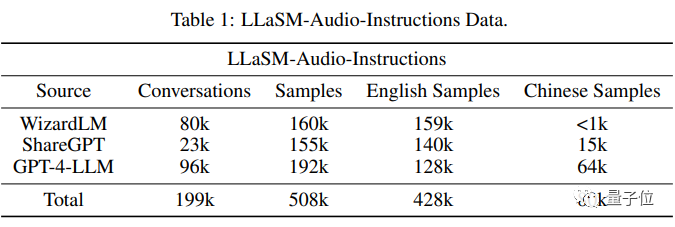 これは現在、中国語と英語の音声テキストコマンドフォローデータセットとしては最大のものだが、まだ整理中であり、研究者らによると、整理後にオープンソース化する予定だという。ただし、この論文では、現時点ではその出力を他の音声モデルやテキスト モデルと比較していません。## **著者について**この論文は、LinkSoul.AI、北京大学、および Zero One Thing から提供されたものです。共著者の Yu Shu 氏と Siwei Dong 氏はどちらも LinkSoul.AI の出身で、以前は北京 Zhiyuan AI Research Institute で働いていました。LinkSoul.AI は、以前に初のオープンソース Llama 2 大型中国語モデルを立ち上げた AI スタートアップ企業です。 カイフー・リー氏が所有する大規模なモデル会社として、ゼロワンワールドもこの研究に貢献した。著者の黄文豪の「抱き顔」のページには、彼が復旦大学を卒業したことが示されています。 用紙のアドレス:Demo地址:
大規模な国内音声対話モデルがここにあります: 李海福は中国語と英語のバイリンガルおよびマルチモーダル、オープンソースおよび商用利用可能なすべてのものに参加しています。
出典: 量子ビット
初の中国語と英語のバイリンガル音声対話オープンソース大型モデルが登場!
ここ数日、大規模な音声テキストマルチモーダルモデルに関する論文がarXivに掲載され、署名企業の中にKai-fu Lee氏の大規模モデル会社01.ai - 01.ai -の名前が登場しました。 。
テキストと音声入力をサポートし、携帯電話でも再生できます
研究者らによると、LLaSM は、中国語と英語のバイリンガル音声テキストのマルチモーダル対話をサポートする、オープンソースで商用利用可能な初の対話モデルです。
それでは、音声テキスト入力と中国語と英語のバイリンガル機能を見てみましょう。
まず第一に、中国語と英語の文化的な衝突をしてみましょう。彼に英語で李白についてコメントしてもらいましょう。
しばらく考えた結果、非常に中立的な評価を下したモデルであり、大型モデル(手動犬頭)の基本的な「水を扱う常識」も備えていることが分かります。
音声で「レシピを提案してください」と入力してみましょう:
モデルが正確に「ナスチーズ」のレシピを出力していることがわかりますが、おいしいかどうかはわかりません。
しかし、実際に試してみると、このモデルには時々バグがあることも分かりました。
たとえば、「人間の言葉をあまり理解できない」場合があります。
中国語と英語が混在したコンテンツを出力するように要求すると、理解できないふりをして英語を出力します。
しかし、それとは別に、中国語と英語の両方を表現する能力はかなり優れています。
では、そのようなモデルはどのように実装されるのでしょうか?
**どんな新しいモデルを作りましたか? **
試用プレイから判断すると、LLaSM には主に 2 つの特徴があります。1 つは中国語と英語の入力に対応し、もう 1 つは音声とテキストの二重入力です。
これら 2 つの点を達成するには、アーキテクチャとトレーニング データでそれぞれいくつかの調整を行う必要があります。
アーキテクチャ上、LLaSM は現在の音声認識モデルと大規模言語モデルを統合しています。
LLaSM は、自動音声認識モデル Whisper、モダリティ アダプター、ラージ モデル LLaMA の 3 つの部分で構成されます。
その中で、Whisper は元の音声入力の受信と音声特徴のベクトル表現の出力を担当し、モダリティ アダプターは音声とテキストの埋め込みを調整する責任を負い、LLaMA は音声とテキストの入力命令を理解して応答を生成する責任を負います。
トレーニング データに関して、研究者らは 199,000 の対話と 508,000 の音声テキスト サンプルを含むデータセット LLaSM-Audio-Instructions を編集しました。
508,000 の音声テキスト サンプルのうち、80,000 の中国語音声サンプルと 428,000 の英語音声サンプルがあります。
研究者は、WizardLM、ShareGPT、GPT-4-LLM などのデータ セットに基づいて、テキスト読み上げテクノロジーを使用して、これらのデータ セットの音声パケットを生成し、無効な会話を除外します。
ただし、この論文では、現時点ではその出力を他の音声モデルやテキスト モデルと比較していません。
## 著者について
この論文は、LinkSoul.AI、北京大学、および Zero One Thing から提供されたものです。
共著者の Yu Shu 氏と Siwei Dong 氏はどちらも LinkSoul.AI の出身で、以前は北京 Zhiyuan AI Research Institute で働いていました。
LinkSoul.AI は、以前に初のオープンソース Llama 2 大型中国語モデルを立ち上げた AI スタートアップ企業です。
Demo地址: