出典: 新志源 画像ソース: Unbounded AI によって生成RLHFの「人間」を置き換えたら実現可能でしょうか?Google チームによる最新の研究では、人間の好みのアノテーションに代わる大規模モデルの使用、つまり AI フィードバック強化学習 (RLAIF) を提案しています。 用紙のアドレス:RLAIF は、人間のアノテーターに頼ることなく、RLHF と同等の改善を達成でき、勝率は 50% であることがわかりました。同時に、Google の調査では、教師あり微調整 (SFT) と比較して、RLAIF と RLHF の勝率が 70% 以上であることが再び証明されました。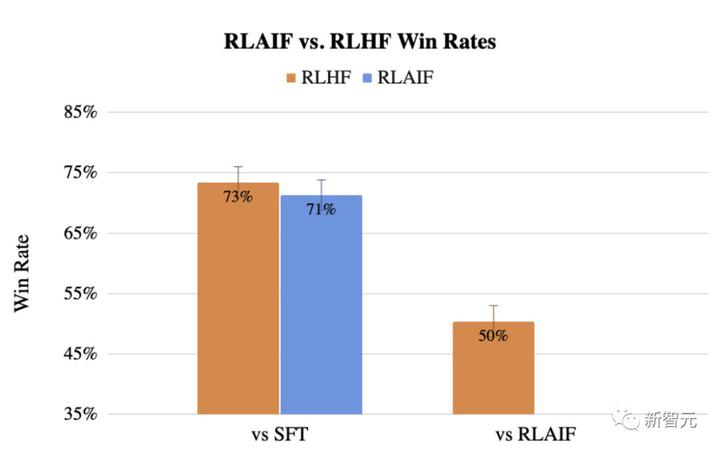 現在の大規模言語モデルのトレーニングの重要な部分は RLHF です。人間は、AI の出力の品質を評価することで、回答をより有用なものにします。ただし、これには、多くのアノテーターが AI 出力の有害なコンテンツにさらされるなど、多大な労力が必要になります。現在、RLAIF は RLHF に匹敵するため、将来のモデルは人間によるフィードバックを必要とせず、自己ループによって改善することもできます。## RLHF にはもう人間は必要ありません現在、RLHF は、ChatGPT、Bard、およびこのパラダイムを採用するその他のモデルを含む大規模モデルを微調整するための中核的な方法となっています。具体的には、RLHF は 3 つのステップに分かれています: 教師あり微調整 LLM の事前トレーニング、報酬モデルをトレーニングするためのデータ収集、RL によるモデルの微調整です。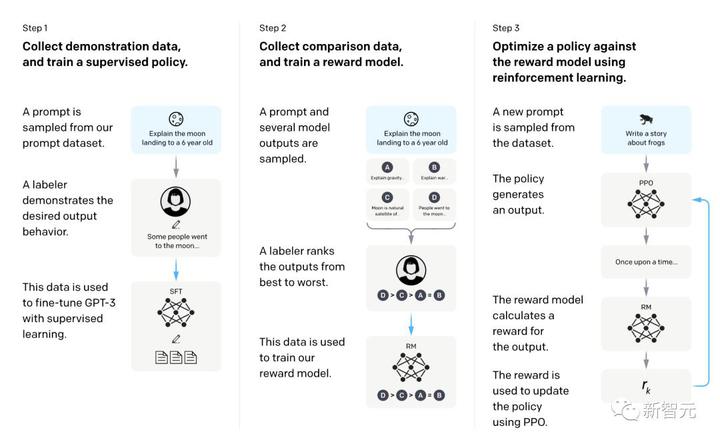 RLHF を使用すると、従来の SFT では区別することが困難な複雑なシーケンス レベルの目的に合わせて大規模なモデルを最適化できます。ただし、非常に現実的な問題は、RLHF には大規模かつ高品質のヒューマン アノテーション データが必要であり、これらのデータが優れた結果を達成できるかどうかです。この Google の調査に先立って、人類の研究者は、AI の好みを使用して RL 微調整のための報酬モデルをトレーニングすることを最初に検討していました。彼らは初めて「憲法AI」でRLAIFを提案し、LLMが人間の判断と非常に一致しており、一部のタスクでは人間よりも優れたパフォーマンスを発揮することさえ発見した。 ただし、この研究では人間と人工知能のフィードバックが比較されていないため、RLAIF が RLHF に取って代わることができるかどうかについては、まだ最終的な答えは得られていません。Google の最新の研究は主にこの問題を解決することを目的としています。研究者らは、モデル要約タスクで RLAIF と RLHF を直接比較しました。1 つのテキストと 2 つの回答候補が与えられた場合、既製の LLM を使用して好みの注釈を付けます。次に、LLM の好みと対照的な損失に基づいて報酬モデル (RM) がトレーニングされます。最後に、強化学習を通じてポリシー モデルが微調整され、報酬モデルを使用して報酬が与えられます。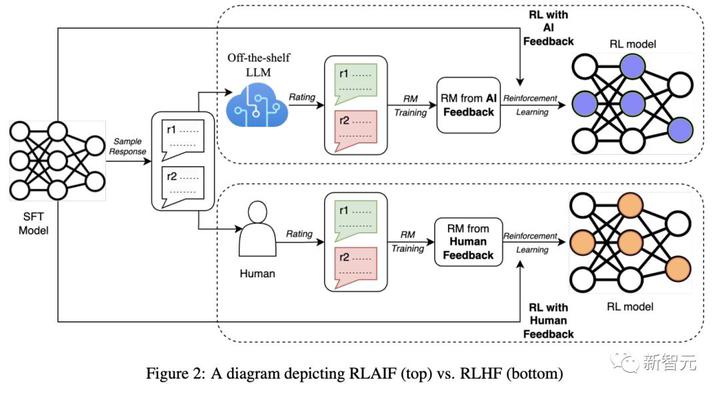 では、Google と Anthropic が提案する RLAIF アプローチの違いは何でしょうか? Google自身も記事の中で次のように説明しています。- Google: AI でラベル付けされた設定に基づいて報酬モデルをトレーニングし、RL の微調整を実行します。- 憲法 AI: 憲法に従ってより良い応答を生成するように LLM に繰り返し要求することで、教師あり学習モデルを改善します。## AI の自己ラベル付け、自己改善Google が最新の研究で提案した RLAIF 手法のプロセスは何ですか?### **プリファレンスラベル付けのための大規模な言語モデル**研究者らは、「既製の」LLM を使用して、2 人の候補者の間の好みにラベルを付けました。これは、一般的な使用のために事前トレーニングまたは命令調整されたモデルですが、特定の下流タスク用に微調整されていません。 1 つのテキストと 2 つの要約候補が与えられた場合、LLM はどちらの要約がより優れているかを評価するよう求められます。 LLM の入力構造は次のとおりです。**1. はじめに**当面のタスクを紹介および説明する指示**2. 複数のサンプル インスタンス (オプション)**テキスト、一対の要約、アイデアの基本原則、好みの判断**3. ラベルを貼付するサンプル**注釈を付けるためのテキストと要約のペア**4.終了**LLM の終了文字列 (「Preferred Summary=」など) を要求します LLM に入力を提供した後、研究者らはトークン「1」と「2」を生成する対数確率を取得し、ソフトマックスを計算して選好分布を取得しました。LLM から好みのアノテーションを取得するには、モデルからの自由形式の応答をデコードしてヒューリスティックに好みを抽出する (例: Output="最初の要約の方が優れています")、または好みの分布をワンホット表現として表すなど、さまざまな方法があります (ワンホット表現)。しかし、研究者らはこれらの代替方法を試さなかった。なぜなら、彼らの方法ではすでに高い精度が得られていたからである。研究者らは 2 種類のプリアンブルを試しました。1 つ目は単に「どの要約が優れているか?」を尋ねる「Base」で、2 つ目は OpenAI TL;DR 嗜好データセットの生成に使用されるアプローチを模倣した「OpenAI」です。人間の好みのタガーに対する評価ディレクティブ。強力な概要を構成するものについての詳細が記載されています。以下に示すように。 研究者らはまた、プロンプトに少数のサンプルを追加することで文脈学習を実験しました。サンプルは、さまざまなトピックをカバーするために手動で選択されました。位置ずれを解消します。これまでの調査結果は、候補者が LLM に提示される順序が、LLM がどの候補者を優先するかを判断するかどうかに影響を与える可能性があることを示唆しています。研究者らは、特に小さいサイズの注釈付き LLM について、この位置バイアスの証拠を発見しました。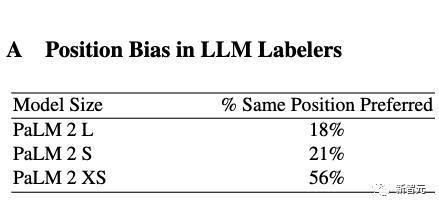 優先ラベル付けにおける位置バイアスを軽減するために、候補の各ペアに対して 2 つの推論を実行し、候補が LLM に送信される順序を逆にします。次に、2 つの推論の結果が平均されて、最終的な優先度分布が得られます。### 思考連鎖推論研究者たちは、人間の好みとの一貫性を高めるために、AI タガーから思考連鎖 (COT) 推論を導き出そうと試みています。研究者は、標準の終了プロンプトを置き換えて(たとえば、「推奨される要約」を「各要約の一貫性、正確性、範囲、および全体的な品質を考慮して、どれがより優れているか説明してください。根拠:」に置き換えます)、LLM 応答を解読します。 。最後に、研究者らは元のプロンプト、応答、および元の終了文字列「Preferred Summary=」を連結し、セクション 3.1 のスコアリング プロセスに従って選好分布を取得しました。具体的なプロセスについては、以下の図を参照してください。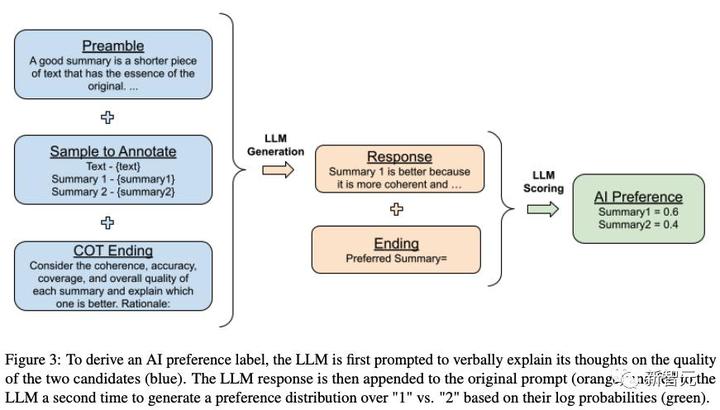 ゼロショット ヒントでは、LLM は推論がどのようなものであるべきかの例を提供しませんが、少数ショット ヒントでは、研究者はモデルが従うべき COT 推論の例を提供します。例については、下の図を参照してください。 ### **自己一貫性**思考連鎖プロンプトについて、研究者らはまた、自己一貫性、つまり複数の推論パスをサンプリングし、各パスの最後に生成される最終的な答えを集約することで思考連鎖推論を改善する手法も実験しました。ゼロ以外のデコード温度を使用して複数の思考チェーンの基本をサンプリングし、前のセクションの方法に従って各思考チェーンの LLM 優先分布を取得します。次に、結果が平均されて、最終的な優先度分布が得られます。### **AI フィードバックによる強化学習**LLM が好みに注釈を付けた後、報酬モデル (RM) がトレーニングされて好みを予測します。研究者の方法はソフトラベルを生成するため、報酬モデルで言及されている損失の代わりに、RMが生成した報酬スコアのソフトマックスのクロスエントロピー損失を使用します。Softmax は、RM の無制限のスコアを確率分布に変換します。AI ラベル付きデータセットで RM をトレーニングすることは、特に研究者の AI タガーが RM よりも大きくて強力であることが多いため、モデル抽出の一形態と見なすことができます。もう 1 つのアプローチは、RM をバイパスし、AI フィードバックを RL の報酬信号として直接使用することです。ただし、このアプローチは AI アノテーターが RM よりも大きいため、計算コストが高くなります。研究者らは、訓練された RM を使用して、言語モデリングの分野に適応した Advantage Actor Critic (A2C) アルゴリズムの修正バージョンを使用して強化学習を実行しました。### 評価する研究者らは、AI アノテーターの調整、ペアリングの精度、勝率という 3 つの指標を通じて結果を評価しました。AI タガー アラインメントは、人間の好みに対する AI タグ付けの好みの精度を測定するために使用されます。1 つの例として、ソフト AI の注釈付き設定をバイナリ表現に変換します。アノテーションがターゲットの人間の好みと一致する場合は 1 が割り当てられ、そうでない場合は 0 が割り当てられます。ペアワイズ精度は、保持されている人間の好みのセットに対する、トレーニングされた報酬モデルの精度の尺度です。共有コンテキストと候補応答のペアが与えられた場合、人間の注釈に従って RM が優先候補を非優先候補よりも高くスコア付けした場合、ペアリング精度は 1 になります。それ以外の場合、値は 0 です。この量は複数の例にわたって平均され、RM の全体的な精度が測定されます。勝率は、人間が一方の戦略を他方の戦略よりどのくらい好むかを測定することによって、2 つの戦略のエンドツーエンドの品質を評価します。入力と 2 つの生成結果が与えられた場合、ヒューマン・アノテーターはどちらの生成結果を優先するかを選択します。戦略 A が戦略 B より優れている場合の割合を「A の B に対する勝率」と呼びます。## 実験の詳細研究者らは、OpenAI によって厳選されたフィルタリングされた Reddit TL;DR データセットを使用しました。 TL;DR さまざまなトピックに関する Reddit からの約 300 万件の投稿 (「サブレディット」とも呼ばれます) と、元の作成者によって書かれた投稿の概要が含まれています。データはまた、高品質を確保するために OpenAI によってフィルタリングされます。これには、一般の人々が理解できる Reddit トピックのホワイトリストの使用も含まれます。また、要約に 24 ~ 48 個のコールアウトがある投稿のみが含まれます。フィルタリングされたデータセットには 123,169 件の投稿が含まれており、そのうちの約 5% が検証セットとして使用されます。データセットの詳細については、元の論文を参照してください。さらに、OpenAI は、フィルタリングされた TL;DR データセットから人間の嗜好データセットを厳選しました。特定の投稿に対して、異なる戦略に従って 2 つの要約候補が生成され、タグ付け者はお気に入りの要約を採点するよう求められます。合計データセットには、約 92,000 個のペアごとの比較が含まれています。### LLM アノテーションAI アノテーション技術 (ヒント、自己一貫性など) の有効性を評価するために、研究者らは TL;DR 選好データセットから、人間のアノテーターがより高い信頼性で要約を好むであろう例を選択しました。研究者らは、より高速な実験反復を可能にするために、データセットのトレーニング分割のランダムな 15% サブセットで AI アノテーターのアライメントを評価し、2,851 の評価例を生成しました。報酬モデルのトレーニングでは、信頼スコアに関係なく、嗜好データセットの完全なトレーニング分割に LLM によって注釈が付けられ、トレーニングに使用されます。### モデルのトレーニング研究者らは、PaLM 2 Extra-Small (XS) を初期チェックポイントとして使用し、OpenAI でフィルタリングされた TL;DR データセットで SFT モデルをトレーニングしました。次に、研究者らは SFT モデルから RM を初期化し、OpenAI の TL;DR 人間の嗜好データセットでトレーニングします。表 1 と 5.1 の結果について、研究者らは PaLM 2L を使用して、「OpenAI + COT 0-shot」プロンプト (自己一貫性なし) を使用して AI アノテーション付き設定を生成し、完全な設定で RM データセットをトレーニングしました。強化学習の場合、研究者らは Advantage Actor Critic (A2C) を使用してポリシーをトレーニングしました。戦略モデルと価値モデルは両方とも SFT モデルから初期化されます。研究者らは、戦略を開始するための初期状態として、フィルタリングされた Reddit TL;DR データセットを使用しました。### **人間**クラスの評価研究者らは、RLHF および RLAIF 戦略を評価するために 1,200 人の人間による評価を収集しました。評価タスクごとに、評価者は投稿と、さまざまな戦略に従って生成された 4 つの概要 (RLAIF、RLHF、SFT、人間の参照にそれぞれ 1 つ) を受け取り、それらを品質の順に同順位なしでランク付けするよう求められます。ポストは、他の評価には使用されなかった、TL;DR 監視付き微調整データセットのホールドアウト セットから取得されます。これらのランキングが収集されると、任意の 2 つの戦略のオッズを計算できます。## 勝率 50%、引き分け### RLAIF 対 RLHF記事の冒頭で、Google による RLAIF と RLHF の比較の利点を紹介しましたが、その結果、2 つの方法は同等のパフォーマンスを持っていることがわかりました。具体的には、人間の評価者はベースライン SFT と比較して 71% の確率で RLAIF を好みます。 RLHF は 73% の確率で SFT を上回ります。研究者らはまた、RLAIF と RLHF の勝率を直接比較し、その人気が同等であること、つまり両方の勝率が 50% であることを発見しました。2 つの戦略の違いをさらに理解するために、Google は生成する概要の定性的な比較を実行しました。 さらに、RLAIF および RLHF の要約を人間が作成した参照要約と比較しました。 79% の確率で、RLAIF が生成した要約は参照要約よりも優れており、80% の確率で、RLHF の結果は参照要約よりも優れていました。RLAIF と RLHF と参考概要との勝率の差はわずか 1% であり、大きな差がないことがわかります。上の表の赤でマークされたテキストに示されているように、研究者らは、RLHF 戦略における幻覚の頻度が RLAIF における幻覚の頻度よりも高いことが多いことも発見したことは注目に値します。サマリーの長さを制御した後でも、RLAIF 戦略と RLHF 戦略はベースライン SFT を上回り、同様の勝率を達成します。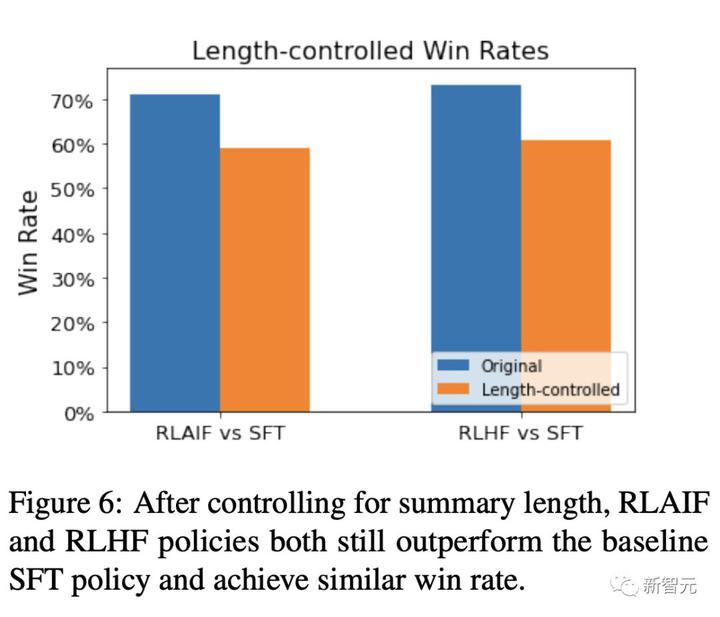 これらの結果は、RLAIF が人間による注釈に依存する必要がなく、RLHF の実行可能な代替手段であることを示しています。### ヒントとコツプロンプト手法を使用する際に、Google チームは、プリアンブルの特異性、CoT、少数サンプルのコンテキスト学習という 3 種類のプロンプト手法を試しました。詳細な OpenAI プリアンブル プロンプトと CoT 推論により、AI アノテーターは 78% の一貫性を達成できることが判明しました。一方、状況に応じた学習は精度を向上させず、むしろ精度を悪化させる可能性があります。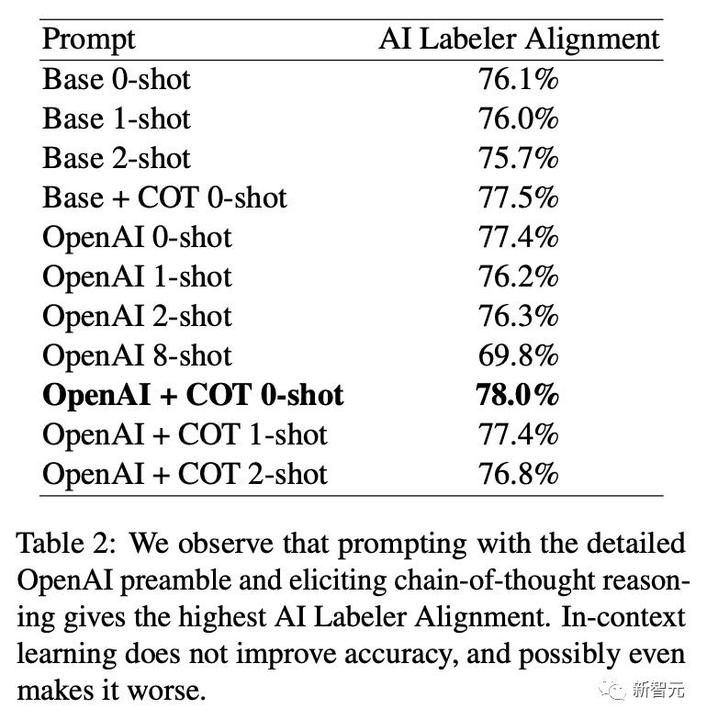 ### **自己一貫性**研究者らは、デコード温度を 1 として、4 個と 16 個のサンプルを使用して自己無撞着性実験を実施しました。T = 1 で複数の思考連鎖原則をサンプリングすると、人間の好みとあまり一致しない結果が得られます。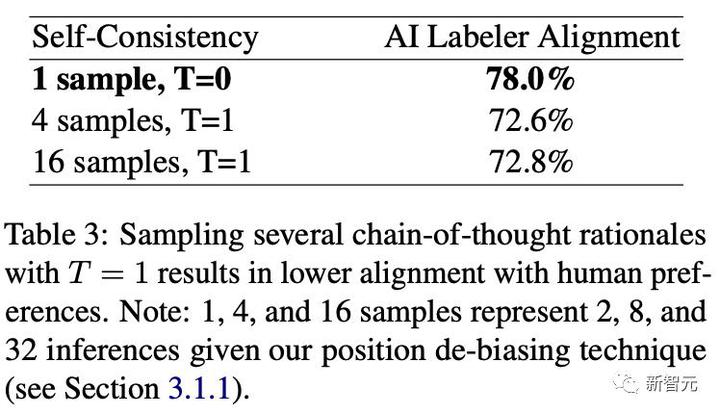 ### 大型モデル アノテーターのサイズこの研究では、大規模モデルのタガーのパラメーター スケールをスケールアップすると、より高品質の好みのアノテーションが得られる可能性があることもわかりました。### 好ましい例の数報酬モデルの精度はトレーニング例によってどのように変化しますか?研究者らは、数千の例でトレーニングした後、報酬モデルのパフォーマンスが完全なデータセットでトレーニングした場合のパフォーマンスに近いことを発見しました。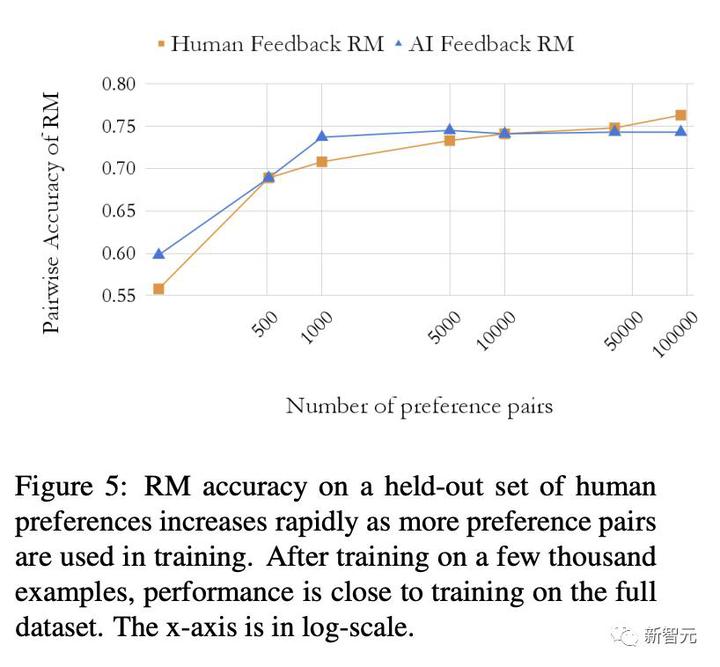## 結論は研究者らは、RLAIF が人間のアノテーターに頼ることなく、RLHF と同等の改善をもたらすことができることを実証しました。この研究は RLAIF の可能性を強調していますが、まだいくつかの制限があります。まず、この研究では要約タスクのみが調査されており、他のタスクへの一般化可能性についてはさらなる研究が必要です。第二に、研究者らは、経済的コストの観点から、LLM 推論が手動のアノテーションよりも有利であるかどうかを推定しませんでした。さらに、RLAIF と組み合わせた RLHF が単一のアプローチよりも優れたパフォーマンスを発揮できるかどうか、LLM を使用して報酬を直接割り当てることがどの程度うまくいくか、AI タガーの調整の改善が最終的なポリシーの改善につながるかどうか、LLM アノテーターを使用するかどうかなど、調査すべき興味深い疑問がいくつかあります。ポリシー モデルと同じサイズであれば、ポリシーをさらに改善できます (つまり、モデルが「自己改善」できるかどうか)。## ネチズンの熱い議論Google は RL に関する 2 つの論文を発表しました。1. RLAIF: 人間のフィードバックに似たトレーニング報酬モデル2. ReST: 生成モデルを使用した自己トレーニングの促進 これら 2 つの論文を組み合わせることで、データを大量に消費する AI アルゴリズムを満たすことができます 半月前、Google DeepMind は、大規模な言語モデルを人間の好みと一致させるために、新しいアルゴリズム ReST を提案したばかりです。具体的には、オフライン強化学習手法を使用して、人間の好みに合わせて大規模な言語モデルの翻訳品質を向上させます。 ある研究者は、定性的テストに基づくと、Anthropic のクロード モデルは GPT-4 よりも弱いようだと述べました。これは、RLHF/RLAIF メソッドまたは事前トレーニングによって引き起こされる可能性があります。これらの方法が、たとえ学術的なベンチマークでより優れたパフォーマンスを示したとしても、現実世界のアプリケーションでより一般化できるかどうかは不明です。 これによって人間によるアノテーションの重要性が低下するとは言いませんが、人工知能によるフィードバックを備えた RL によりコストを削減できることは確かです。手動によるアノテーションは一般化にとって依然として非常に重要であり、RLHF + RLAIF ハイブリッド手法は単一の手法よりも優れています。 ほとんどのネチズンは、この論文は大きな進歩であると信じていますが、一部のネチズンは、数か月前にAnthropicが提案したConstitute ClaudeのRLAIFと根本的に異なるようには見えないと感じています。 参考文献:
RLHF にはもう人間は必要ありません。Google チームの調査により、AI によるラベル付けが人間のレベルに達していることが証明されました。
出典: 新志源
RLHFの「人間」を置き換えたら実現可能でしょうか?
Google チームによる最新の研究では、人間の好みのアノテーションに代わる大規模モデルの使用、つまり AI フィードバック強化学習 (RLAIF) を提案しています。
RLAIF は、人間のアノテーターに頼ることなく、RLHF と同等の改善を達成でき、勝率は 50% であることがわかりました。
同時に、Google の調査では、教師あり微調整 (SFT) と比較して、RLAIF と RLHF の勝率が 70% 以上であることが再び証明されました。
ただし、これには、多くのアノテーターが AI 出力の有害なコンテンツにさらされるなど、多大な労力が必要になります。
現在、RLAIF は RLHF に匹敵するため、将来のモデルは人間によるフィードバックを必要とせず、自己ループによって改善することもできます。
RLHF にはもう人間は必要ありません
現在、RLHF は、ChatGPT、Bard、およびこのパラダイムを採用するその他のモデルを含む大規模モデルを微調整するための中核的な方法となっています。
具体的には、RLHF は 3 つのステップに分かれています: 教師あり微調整 LLM の事前トレーニング、報酬モデルをトレーニングするためのデータ収集、RL によるモデルの微調整です。
ただし、非常に現実的な問題は、RLHF には大規模かつ高品質のヒューマン アノテーション データが必要であり、これらのデータが優れた結果を達成できるかどうかです。
この Google の調査に先立って、人類の研究者は、AI の好みを使用して RL 微調整のための報酬モデルをトレーニングすることを最初に検討していました。
彼らは初めて「憲法AI」でRLAIFを提案し、LLMが人間の判断と非常に一致しており、一部のタスクでは人間よりも優れたパフォーマンスを発揮することさえ発見した。
Google の最新の研究は主にこの問題を解決することを目的としています。
研究者らは、モデル要約タスクで RLAIF と RLHF を直接比較しました。
1 つのテキストと 2 つの回答候補が与えられた場合、既製の LLM を使用して好みの注釈を付けます。
次に、LLM の好みと対照的な損失に基づいて報酬モデル (RM) がトレーニングされます。最後に、強化学習を通じてポリシー モデルが微調整され、報酬モデルを使用して報酬が与えられます。
Google: AI でラベル付けされた設定に基づいて報酬モデルをトレーニングし、RL の微調整を実行します。
憲法 AI: 憲法に従ってより良い応答を生成するように LLM に繰り返し要求することで、教師あり学習モデルを改善します。
AI の自己ラベル付け、自己改善
Google が最新の研究で提案した RLAIF 手法のプロセスは何ですか?
プリファレンスラベル付けのための大規模な言語モデル
研究者らは、「既製の」LLM を使用して、2 人の候補者の間の好みにラベルを付けました。
これは、一般的な使用のために事前トレーニングまたは命令調整されたモデルですが、特定の下流タスク用に微調整されていません。 1 つのテキストと 2 つの要約候補が与えられた場合、LLM はどちらの要約がより優れているかを評価するよう求められます。 LLM の入力構造は次のとおりです。
1. はじめに
当面のタスクを紹介および説明する指示
2. 複数のサンプル インスタンス (オプション)
テキスト、一対の要約、アイデアの基本原則、好みの判断
3. ラベルを貼付するサンプル
注釈を付けるためのテキストと要約のペア
4.終了
LLM の終了文字列 (「Preferred Summary=」など) を要求します
LLM から好みのアノテーションを取得するには、モデルからの自由形式の応答をデコードしてヒューリスティックに好みを抽出する (例: Output="最初の要約の方が優れています")、または好みの分布をワンホット表現として表すなど、さまざまな方法があります (ワンホット表現)。しかし、研究者らはこれらの代替方法を試さなかった。なぜなら、彼らの方法ではすでに高い精度が得られていたからである。
研究者らは 2 種類のプリアンブルを試しました。1 つ目は単に「どの要約が優れているか?」を尋ねる「Base」で、2 つ目は OpenAI TL;DR 嗜好データセットの生成に使用されるアプローチを模倣した「OpenAI」です。人間の好みのタガーに対する評価ディレクティブ。強力な概要を構成するものについての詳細が記載されています。以下に示すように。
これまでの調査結果は、候補者が LLM に提示される順序が、LLM がどの候補者を優先するかを判断するかどうかに影響を与える可能性があることを示唆しています。研究者らは、特に小さいサイズの注釈付き LLM について、この位置バイアスの証拠を発見しました。
思考連鎖推論
研究者たちは、人間の好みとの一貫性を高めるために、AI タガーから思考連鎖 (COT) 推論を導き出そうと試みています。
研究者は、標準の終了プロンプトを置き換えて(たとえば、「推奨される要約」を「各要約の一貫性、正確性、範囲、および全体的な品質を考慮して、どれがより優れているか説明してください。根拠:」に置き換えます)、LLM 応答を解読します。 。
最後に、研究者らは元のプロンプト、応答、および元の終了文字列「Preferred Summary=」を連結し、セクション 3.1 のスコアリング プロセスに従って選好分布を取得しました。具体的なプロセスについては、以下の図を参照してください。
思考連鎖プロンプトについて、研究者らはまた、自己一貫性、つまり複数の推論パスをサンプリングし、各パスの最後に生成される最終的な答えを集約することで思考連鎖推論を改善する手法も実験しました。
ゼロ以外のデコード温度を使用して複数の思考チェーンの基本をサンプリングし、前のセクションの方法に従って各思考チェーンの LLM 優先分布を取得します。次に、結果が平均されて、最終的な優先度分布が得られます。
AI フィードバックによる強化学習
LLM が好みに注釈を付けた後、報酬モデル (RM) がトレーニングされて好みを予測します。研究者の方法はソフトラベルを生成するため、報酬モデルで言及されている損失の代わりに、RMが生成した報酬スコアのソフトマックスのクロスエントロピー損失を使用します。
Softmax は、RM の無制限のスコアを確率分布に変換します。
AI ラベル付きデータセットで RM をトレーニングすることは、特に研究者の AI タガーが RM よりも大きくて強力であることが多いため、モデル抽出の一形態と見なすことができます。
もう 1 つのアプローチは、RM をバイパスし、AI フィードバックを RL の報酬信号として直接使用することです。ただし、このアプローチは AI アノテーターが RM よりも大きいため、計算コストが高くなります。
研究者らは、訓練された RM を使用して、言語モデリングの分野に適応した Advantage Actor Critic (A2C) アルゴリズムの修正バージョンを使用して強化学習を実行しました。
### 評価する
研究者らは、AI アノテーターの調整、ペアリングの精度、勝率という 3 つの指標を通じて結果を評価しました。
AI タガー アラインメントは、人間の好みに対する AI タグ付けの好みの精度を測定するために使用されます。
1 つの例として、ソフト AI の注釈付き設定をバイナリ表現に変換します。アノテーションがターゲットの人間の好みと一致する場合は 1 が割り当てられ、そうでない場合は 0 が割り当てられます。
ペアワイズ精度は、保持されている人間の好みのセットに対する、トレーニングされた報酬モデルの精度の尺度です。
共有コンテキストと候補応答のペアが与えられた場合、人間の注釈に従って RM が優先候補を非優先候補よりも高くスコア付けした場合、ペアリング精度は 1 になります。それ以外の場合、値は 0 です。この量は複数の例にわたって平均され、RM の全体的な精度が測定されます。
勝率は、人間が一方の戦略を他方の戦略よりどのくらい好むかを測定することによって、2 つの戦略のエンドツーエンドの品質を評価します。
入力と 2 つの生成結果が与えられた場合、ヒューマン・アノテーターはどちらの生成結果を優先するかを選択します。戦略 A が戦略 B より優れている場合の割合を「A の B に対する勝率」と呼びます。
実験の詳細
研究者らは、OpenAI によって厳選されたフィルタリングされた Reddit TL;DR データセットを使用しました。 TL;DR さまざまなトピックに関する Reddit からの約 300 万件の投稿 (「サブレディット」とも呼ばれます) と、元の作成者によって書かれた投稿の概要が含まれています。
データはまた、高品質を確保するために OpenAI によってフィルタリングされます。これには、一般の人々が理解できる Reddit トピックのホワイトリストの使用も含まれます。
また、要約に 24 ~ 48 個のコールアウトがある投稿のみが含まれます。フィルタリングされたデータセットには 123,169 件の投稿が含まれており、そのうちの約 5% が検証セットとして使用されます。
データセットの詳細については、元の論文を参照してください。さらに、OpenAI は、フィルタリングされた TL;DR データセットから人間の嗜好データセットを厳選しました。
特定の投稿に対して、異なる戦略に従って 2 つの要約候補が生成され、タグ付け者はお気に入りの要約を採点するよう求められます。合計データセットには、約 92,000 個のペアごとの比較が含まれています。
LLM アノテーション
AI アノテーション技術 (ヒント、自己一貫性など) の有効性を評価するために、研究者らは TL;DR 選好データセットから、人間のアノテーターがより高い信頼性で要約を好むであろう例を選択しました。
研究者らは、より高速な実験反復を可能にするために、データセットのトレーニング分割のランダムな 15% サブセットで AI アノテーターのアライメントを評価し、2,851 の評価例を生成しました。
報酬モデルのトレーニングでは、信頼スコアに関係なく、嗜好データセットの完全なトレーニング分割に LLM によって注釈が付けられ、トレーニングに使用されます。
モデルのトレーニング
研究者らは、PaLM 2 Extra-Small (XS) を初期チェックポイントとして使用し、OpenAI でフィルタリングされた TL;DR データセットで SFT モデルをトレーニングしました。
次に、研究者らは SFT モデルから RM を初期化し、OpenAI の TL;DR 人間の嗜好データセットでトレーニングします。
表 1 と 5.1 の結果について、研究者らは PaLM 2L を使用して、「OpenAI + COT 0-shot」プロンプト (自己一貫性なし) を使用して AI アノテーション付き設定を生成し、完全な設定で RM データセットをトレーニングしました。
強化学習の場合、研究者らは Advantage Actor Critic (A2C) を使用してポリシーをトレーニングしました。戦略モデルと価値モデルは両方とも SFT モデルから初期化されます。研究者らは、戦略を開始するための初期状態として、フィルタリングされた Reddit TL;DR データセットを使用しました。
人間クラスの評価
研究者らは、RLHF および RLAIF 戦略を評価するために 1,200 人の人間による評価を収集しました。評価タスクごとに、評価者は投稿と、さまざまな戦略に従って生成された 4 つの概要 (RLAIF、RLHF、SFT、人間の参照にそれぞれ 1 つ) を受け取り、それらを品質の順に同順位なしでランク付けするよう求められます。
ポストは、他の評価には使用されなかった、TL;DR 監視付き微調整データセットのホールドアウト セットから取得されます。これらのランキングが収集されると、任意の 2 つの戦略のオッズを計算できます。
勝率 50%、引き分け
RLAIF 対 RLHF
記事の冒頭で、Google による RLAIF と RLHF の比較の利点を紹介しましたが、その結果、2 つの方法は同等のパフォーマンスを持っていることがわかりました。
具体的には、人間の評価者はベースライン SFT と比較して 71% の確率で RLAIF を好みます。 RLHF は 73% の確率で SFT を上回ります。
研究者らはまた、RLAIF と RLHF の勝率を直接比較し、その人気が同等であること、つまり両方の勝率が 50% であることを発見しました。
2 つの戦略の違いをさらに理解するために、Google は生成する概要の定性的な比較を実行しました。
RLAIF と RLHF と参考概要との勝率の差はわずか 1% であり、大きな差がないことがわかります。
上の表の赤でマークされたテキストに示されているように、研究者らは、RLHF 戦略における幻覚の頻度が RLAIF における幻覚の頻度よりも高いことが多いことも発見したことは注目に値します。
サマリーの長さを制御した後でも、RLAIF 戦略と RLHF 戦略はベースライン SFT を上回り、同様の勝率を達成します。
ヒントとコツ
プロンプト手法を使用する際に、Google チームは、プリアンブルの特異性、CoT、少数サンプルのコンテキスト学習という 3 種類のプロンプト手法を試しました。
詳細な OpenAI プリアンブル プロンプトと CoT 推論により、AI アノテーターは 78% の一貫性を達成できることが判明しました。
一方、状況に応じた学習は精度を向上させず、むしろ精度を悪化させる可能性があります。
研究者らは、デコード温度を 1 として、4 個と 16 個のサンプルを使用して自己無撞着性実験を実施しました。
T = 1 で複数の思考連鎖原則をサンプリングすると、人間の好みとあまり一致しない結果が得られます。
この研究では、大規模モデルのタガーのパラメーター スケールをスケールアップすると、より高品質の好みのアノテーションが得られる可能性があることもわかりました。
好ましい例の数
報酬モデルの精度はトレーニング例によってどのように変化しますか?
研究者らは、数千の例でトレーニングした後、報酬モデルのパフォーマンスが完全なデータセットでトレーニングした場合のパフォーマンスに近いことを発見しました。
## 結論は
研究者らは、RLAIF が人間のアノテーターに頼ることなく、RLHF と同等の改善をもたらすことができることを実証しました。
この研究は RLAIF の可能性を強調していますが、まだいくつかの制限があります。
まず、この研究では要約タスクのみが調査されており、他のタスクへの一般化可能性についてはさらなる研究が必要です。
第二に、研究者らは、経済的コストの観点から、LLM 推論が手動のアノテーションよりも有利であるかどうかを推定しませんでした。
さらに、RLAIF と組み合わせた RLHF が単一のアプローチよりも優れたパフォーマンスを発揮できるかどうか、LLM を使用して報酬を直接割り当てることがどの程度うまくいくか、AI タガーの調整の改善が最終的なポリシーの改善につながるかどうか、LLM アノテーターを使用するかどうかなど、調査すべき興味深い疑問がいくつかあります。ポリシー モデルと同じサイズであれば、ポリシーをさらに改善できます (つまり、モデルが「自己改善」できるかどうか)。
ネチズンの熱い議論
Google は RL に関する 2 つの論文を発表しました。
RLAIF: 人間のフィードバックに似たトレーニング報酬モデル
ReST: 生成モデルを使用した自己トレーニングの促進 これら 2 つの論文を組み合わせることで、データを大量に消費する AI アルゴリズムを満たすことができます
具体的には、オフライン強化学習手法を使用して、人間の好みに合わせて大規模な言語モデルの翻訳品質を向上させます。