抜粋文:エクレム・チェティンカヤ出典: MarkTechPost *画像の出典: Unbounded AI ツールによって生成*一貫した文脈依存のテキストを生成する言語モデルの機能は、コンピューターとの通信方法に革命をもたらしました。大規模言語モデル (LLM) はこの進歩の最前線にあり、大量のテキスト データをトレーニングすることで人間の言語のパターンとニュアンスを学習します。 LLM 革命の先駆者である ChatGPT は、さまざまな分野の人々の間で非常に人気があります。LLM のスーパーパワーにより、さまざまなタスクの処理が容易になります。私たちはこれらをテキストの要約、電子メールの作成、プログラミング タスクの自動化、ドキュメントの解釈などに使用します。 1 年前には時間がかかっていたこれらのタスクはすべて、今では数分で実行できるようになりました。しかし、マルチモーダル理解のニーズが高まるにつれ、モデルはテキスト、画像、さらにはビデオなどのさまざまなモダリティでコンテンツを処理および生成する必要があるため、マルチモーダル大規模言語モデル (MLLM) の必要性が生じています。 MLLM は、言語モデルの力と視覚的な理解を組み合わせ、マシンがより包括的かつコンテキストを認識した方法でコンテンツを理解して生成できるようにします。ChatGPT の流行が少し落ち着いたとき、MLLM は人工知能の分野に旋風を巻き起こし、機械がテキストや画像などのさまざまなモードでコンテンツを理解して生成できるようにしました。これらのモデルは、画像認識、視覚の基礎、指示の理解などのタスクで優れたパフォーマンスを発揮します。ただし、これらのモデルを効果的にトレーニングする方法は依然として課題です。最大の課題は、MLLM が画像もラベルも未知の、まったく見慣れないシーンに遭遇したときです。さらに、MLLM は、長いコンテキストを処理するときに「失われる」傾向があります。これらのモデルは開始位置と中間位置に大きく依存しているため、サンプル数が増加すると精度が頭打ち(学習またはスキル形成のプロセスで一時的に停止または低下)します。したがって、MLLM は長い入力に苦労します。ここで、MLLM のさまざまな課題を解決するためのリンクコンテキスト学習 (LCL) について学びましょう。 *提案されたリンクコンテキスト学習デモンストレーションダイアログ; 出典:*MLLM には 2 つの主要なトレーニング戦略があります。マルチモーダル プロンプト チューニング (M-PT) とマルチモーダル命令チューニング (M-IT)。 M-PT はモデルのパラメーターのごく一部のみを微調整し、残りは変更しません。このアプローチは、計算リソースを最小限に抑えながら、本格的な微調整と同様の結果を達成するのに役立ちます。一方、M-IT は、命令記述を含むデータセットで MLLM を微調整することにより、MLLM のゼロショット機能を強化します。この戦略により、事前のトレーニングなしで新しいタスクを理解し、対応するモデルの能力が向上します。これらの方法はすべて効果的ですが、犠牲も伴います。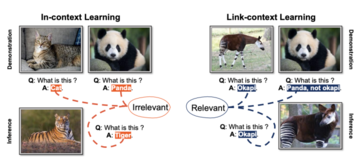 ※文脈学習と連動文脈学習の違い。出典: https://arxiv.org/abs/2308.07891*LCL は、ハイブリッド戦略、双方向戦略、双方向ランダム戦略、双方向加重戦略などのさまざまなトレーニング戦略を検討します。ハイブリッド戦略の優れた特徴は、ゼロ サンプルの精度が大幅に向上し、サンプル数が 6 に達すると素晴らしい結果が得られることです。ただし、サンプル数が 16 になると、パフォーマンスが若干低下します。対照的に、双方向戦略の精度は 2 サンプルから 16 サンプルまで徐々に増加し、トレーニング モードに近づいていることを示しています。従来のコンテキスト学習とは異なり、LCL はモデルにソースとターゲットの間のマッピングを確立する機能を与えることでさらに一歩進んでおり、それによって全体的なパフォーマンスが向上します。 LCL を使用すると、因果関係のデモンストレーションを提供することで、MLLM は類似性だけでなく、データ ポイント間の潜在的な因果関係も特定できるようになり、目に見えないイメージを特定し、新しい概念を理解する際に効果的になります。さらに、LCL は、MLLM の機能を評価するために特別に設計された新規で包括的なデータセットである ISEKAI データセットも紹介します。 ISEKAI データセットは、完全に生成された画像と捏造されたコンセプトで構成されています。 MLLM には、進行中の会話から新しい概念を吸収し、その知識を保持して質問に正確に答えることが求められます。要約すると、LCL は、マルチモーダル言語モデルで採用されているトレーニング戦略について貴重な洞察を提供します。ハイブリッド戦略と双方向戦略は、マルチモーダル言語モデルのパフォーマンスを向上させるためのさまざまなアプローチを提供しますが、それぞれに独自の長所と制限があります。コンテキスト分析は、より長い入力を処理する際にマルチモーダル言語モデルが直面する課題を明らかにし、この分野におけるさらなる研究の重要性も浮き彫りにします。
LCL について 1 つの記事で学ぶ: マルチモーダル大規模モデルの学習能力は「因果推論」によって強化できる
抜粋文:エクレム・チェティンカヤ
出典: MarkTechPost
一貫した文脈依存のテキストを生成する言語モデルの機能は、コンピューターとの通信方法に革命をもたらしました。大規模言語モデル (LLM) はこの進歩の最前線にあり、大量のテキスト データをトレーニングすることで人間の言語のパターンとニュアンスを学習します。 LLM 革命の先駆者である ChatGPT は、さまざまな分野の人々の間で非常に人気があります。
LLM のスーパーパワーにより、さまざまなタスクの処理が容易になります。私たちはこれらをテキストの要約、電子メールの作成、プログラミング タスクの自動化、ドキュメントの解釈などに使用します。 1 年前には時間がかかっていたこれらのタスクはすべて、今では数分で実行できるようになりました。
しかし、マルチモーダル理解のニーズが高まるにつれ、モデルはテキスト、画像、さらにはビデオなどのさまざまなモダリティでコンテンツを処理および生成する必要があるため、マルチモーダル大規模言語モデル (MLLM) の必要性が生じています。 MLLM は、言語モデルの力と視覚的な理解を組み合わせ、マシンがより包括的かつコンテキストを認識した方法でコンテンツを理解して生成できるようにします。
ChatGPT の流行が少し落ち着いたとき、MLLM は人工知能の分野に旋風を巻き起こし、機械がテキストや画像などのさまざまなモードでコンテンツを理解して生成できるようにしました。これらのモデルは、画像認識、視覚の基礎、指示の理解などのタスクで優れたパフォーマンスを発揮します。ただし、これらのモデルを効果的にトレーニングする方法は依然として課題です。最大の課題は、MLLM が画像もラベルも未知の、まったく見慣れないシーンに遭遇したときです。
さらに、MLLM は、長いコンテキストを処理するときに「失われる」傾向があります。これらのモデルは開始位置と中間位置に大きく依存しているため、サンプル数が増加すると精度が頭打ち(学習またはスキル形成のプロセスで一時的に停止または低下)します。したがって、MLLM は長い入力に苦労します。
ここで、MLLM のさまざまな課題を解決するためのリンクコンテキスト学習 (LCL) について学びましょう。
MLLM には 2 つの主要なトレーニング戦略があります。マルチモーダル プロンプト チューニング (M-PT) とマルチモーダル命令チューニング (M-IT)。 M-PT はモデルのパラメーターのごく一部のみを微調整し、残りは変更しません。このアプローチは、計算リソースを最小限に抑えながら、本格的な微調整と同様の結果を達成するのに役立ちます。一方、M-IT は、命令記述を含むデータセットで MLLM を微調整することにより、MLLM のゼロショット機能を強化します。この戦略により、事前のトレーニングなしで新しいタスクを理解し、対応するモデルの能力が向上します。これらの方法はすべて効果的ですが、犠牲も伴います。
LCL は、ハイブリッド戦略、双方向戦略、双方向ランダム戦略、双方向加重戦略などのさまざまなトレーニング戦略を検討します。ハイブリッド戦略の優れた特徴は、ゼロ サンプルの精度が大幅に向上し、サンプル数が 6 に達すると素晴らしい結果が得られることです。ただし、サンプル数が 16 になると、パフォーマンスが若干低下します。対照的に、双方向戦略の精度は 2 サンプルから 16 サンプルまで徐々に増加し、トレーニング モードに近づいていることを示しています。
従来のコンテキスト学習とは異なり、LCL はモデルにソースとターゲットの間のマッピングを確立する機能を与えることでさらに一歩進んでおり、それによって全体的なパフォーマンスが向上します。 LCL を使用すると、因果関係のデモンストレーションを提供することで、MLLM は類似性だけでなく、データ ポイント間の潜在的な因果関係も特定できるようになり、目に見えないイメージを特定し、新しい概念を理解する際に効果的になります。
さらに、LCL は、MLLM の機能を評価するために特別に設計された新規で包括的なデータセットである ISEKAI データセットも紹介します。 ISEKAI データセットは、完全に生成された画像と捏造されたコンセプトで構成されています。 MLLM には、進行中の会話から新しい概念を吸収し、その知識を保持して質問に正確に答えることが求められます。
要約すると、LCL は、マルチモーダル言語モデルで採用されているトレーニング戦略について貴重な洞察を提供します。ハイブリッド戦略と双方向戦略は、マルチモーダル言語モデルのパフォーマンスを向上させるためのさまざまなアプローチを提供しますが、それぞれに独自の長所と制限があります。コンテキスト分析は、より長い入力を処理する際にマルチモーダル言語モデルが直面する課題を明らかにし、この分野におけるさらなる研究の重要性も浮き彫りにします。