出典: 新志源 画像ソース: Unbounded AI によって生成「GPU 貧乏人」は、その苦境に別れを告げようとしています。つい最近、NVIDIA は、H100 上で大規模な言語モデルの推論を高速化できるオープンソース ソフトウェア TensorRT-LLM をリリースしました。 さて、何回改善できるでしょうか?TensorRT-LLM とその一連の最適化機能 (In-Flight バッチ処理を含む) を追加した後、モデルの合計スループットは 8 倍に増加しました。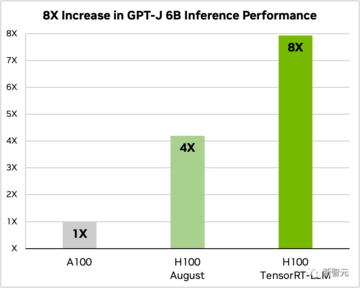 GPT-J-6B A100 と H100 の TensorRT-LLM ありとなしの比較さらに、Llama 2 を例にとると、TensorRT-LLM は、A100 を単独で使用した場合と比較して、推論パフォーマンスを 4.6 倍向上させることができます。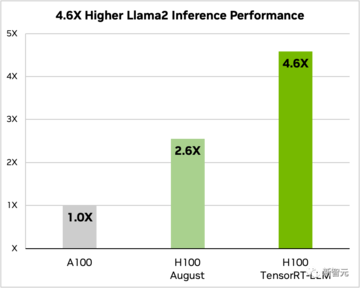 TensorRT-LLM を使用した場合と使用しない場合の Llama 2 70B、A100、および H100 の比較ネットユーザーは、超強力な H100 と TensorRT-LLM を組み合わせることで、間違いなく大規模言語モデル推論の現状を完全に変えるだろうと述べています。 ## **TensorRT-LLM: 大規模モデル推論加速アーティファクト**現状では、大規模モデルのパラメータ規模が膨大なため、「展開と推論」の難易度やコストは依然として高いままです。NVIDIA が開発した TensorRT-LLM は、GPU を通じて LLM スループットを大幅に向上させ、コストを削減することを目的としています。 具体的には、TensorRT-LLM は、TensorRT の深層学習コンパイラ、FasterTransformer の最適化されたカーネル、前処理および後処理、およびマルチ GPU/マルチノード通信をシンプルなオープンソース Python API にカプセル化します。NVIDIA は、FasterTransformer をさらに強化して、製品化されたソリューションにしました。TensorRT-LLM は、使いやすいオープンソースのモジュール式 Python アプリケーション プログラミング インターフェイスを提供していることがわかります。プログラマーは、さまざまな大規模な言語モデルを展開、実行、デバッグするために C++ や CUDA の深い専門知識を必要とせず、最高のパフォーマンスと迅速なカスタマイズも実現できます。 Nvidia の公式ブログによると、TensorRT-LLM は 4 つの方法で Nvidia GPU 上の LLM 推論パフォーマンスを最適化します。まず、TensorRT-LLM が現在の 10 以上の大規模モデルに導入され、開発者がすぐに実行できるようになります。次に、TensorRT-LLM は、オープン ソース ソフトウェア ライブラリとして、LLM が複数の GPU および複数の GPU サーバーで同時に推論を実行できるようにします。これらのサーバーは、NVIDIA の NVLink および InfiniBand 相互接続を介して接続されます。3 つ目は「インフライト バッチ処理」です。これは、さまざまなモデルのタスクが他のタスクから独立して GPU に出入りできるようにするまったく新しいスケジューリング テクノロジです。最後に、TensorRT-LLM は、H100 Transformer Engine を利用してモデル推論中のメモリ使用量とレイテンシを削減するように最適化されています。次に、TensorRT-LLM がモデルのパフォーマンスをどのように向上させるかを詳しく見てみましょう。## **豊富な LLM エコロジーをサポート**TensorRT-LLM は、オープンソース モデル エコシステムに非常に優れたサポートを提供します。Meta の Llama 2-70B など、最大かつ最先端の言語モデルでは、リアルタイムで応答を提供するために複数の GPU が連携する必要があります。以前は、LLM 推論の最適なパフォーマンスを達成したい場合、開発者は AI モデルを書き直して手動で複数のフラグメントに分割し、GPU 全体で実行を調整する必要がありました。 TensorRT-LLM は、テンソル並列処理を使用して重み行列を各デバイスに配布することで、このプロセスを簡素化し、大規模で効率的な推論を可能にします。各モデルは、開発者の介入やモデルの変更を行わずに、NVLink 経由で接続された複数の GPU および複数のサーバー上で並行して実行できます。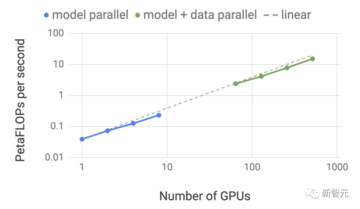 新しいモデルとモデル アーキテクチャの導入により、開発者は TensorRT-LLM でオープンソース化された最新の NVIDIA AI カーネル (Kernal) を使用してモデルを最適化できます。GPT モデル実行のコンテキストおよび生成段階などで最先端の FlashAttendant 実装とマスクされたマルチヘッド アテンションを含むカーネル フュージョン (Kernal Fusion) をサポートしました。さらに、TensorRT-LLM には、現在人気のある多くの大規模な言語モデルの、完全に最適化されたすぐに実行できるバージョンが含まれています。これらには、Meta Llama 2、OpenAI GPT-2 および GPT-3、Falcon、Mosaic MPT、BLOOM、および 10 を超えるモデルが含まれており、これらはすべて、シンプルで使いやすい TensorRT-LLM Python API を使用して呼び出すことができます。これらの機能は、開発者がカスタマイズされた大規模言語モデルをより迅速かつ正確に構築して、さまざまな業界のさまざまなニーズを満たすのに役立ちます。## **実行中のバッチ処理**大規模な言語モデルは、現在さまざまなアプリケーションで使用されています。モデルは、チャットボットでの単純な Q&A 応答から、ドキュメントの要約や長いコード ブロックの生成まで、複数の一見異質なタスクに同時に使用できます。ワークロードは非常に動的であり、タスクの出力サイズは桁違いに大きくする必要があります。必要。タスクが多様であるため、リクエストを効果的にバッチ処理し、効率的な並列実行を実行することが困難になる可能性があり、一部のリクエストが他のリクエストよりも早く完了する可能性があります。 これらの動的な負荷を管理するために、TensorRT-LLM には「インフライト バッチング」と呼ばれる最適化されたスケジューリング テクノロジが含まれています。その中心原理は、大規模な言語モデルのテキスト生成プロセス全体を、モデル上で複数回の実行反復に分割できるということです。実行中のバッチ処理では、TensorRT-LLM ランタイムは、バッチ全体が完了するのを待ってから次のリクエストのセットの処理を続けるのではなく、完了したシーケンスをバッチから即座に解放します。新しいリクエストが実行されている間、前のバッチからの完了していない他のリクエストは引き続き処理されます。実行中のバッチ処理と追加のカーネル レベルの最適化により、GPU 使用率が向上し、H100 での実際の LLM リクエスト ベンチマークのスループットを少なくとも 2 倍にすることができます。## **FP 8 を使用した H100 変圧器エンジン**TensorRT-LLM は、H100 Transformer Engine と呼ばれる機能も提供します。これにより、大規模なモデル推論中のメモリ消費とレイテンシを効果的に削減できます。LLM には数十億のモデルの重みと活性化関数が含まれているため、通常は FP16 または BF16 の値でトレーニングおよび表現され、それぞれが 16 ビットのメモリを占有します。ただし、推論時には、ほとんどのモデルは、8 ビットまたは 4 ビット整数 (INT8 または INT4) などの量子化技術を使用して、より低い精度で効率的に表現できます。量子化は、精度を犠牲にすることなくモデルの重みとアクティベーション精度を減らすプロセスです。より低い精度を使用すると、各パラメーターが小さくなり、モデルが GPU メモリ内で占有するスペースが少なくなります。 これにより、実行中のメモリ操作に費やす時間を短縮しながら、同じハードウェアを使用して大規模なモデルの推論が可能になります。H100 Transformer Engine テクノロジを通じて、TensorRT-LLM を備えた H100 GPU により、ユーザーはモデルの重みを新しい FP8 形式に簡単に変換し、モデルを自動的にコンパイルして最適化された FP8 カーネルを利用できるようになります。このプロセスにはコーディングは必要ありません。 H100 によって導入された FP8 データ形式により、開発者はモデルを定量化し、モデルの精度を低下させることなくメモリ消費量を大幅に削減できます。INT8 や INT4 などの他のデータ形式と比較して、FP8 量子化はより高い精度を維持しながら最速のパフォーマンスを実現し、実装が最も便利です。## **TensorRT-LLM の入手方法**TensorRT-LLM はまだ正式にリリースされていませんが、ユーザーは早期アクセスできるようになりました。アプリケーションのリンクは次のとおりです。NVIDIA はまた、TensorRT-LLM が間もなく NVIDIA NeMo フレームワークに統合される予定であると述べました。このフレームワークは、NVIDIA が少し前に立ち上げた AI Enterprise の一部であり、安全で安定しており、管理性の高いエンタープライズ レベルの AI ソフトウェア プラットフォームを企業顧客に提供します。開発者や研究者は、NVIDIA NGC 上の NeMo フレームワークを通じて、または GitHub 上のプロジェクトとして TensorRT-LLM にアクセスできます。ただし、早期アクセス版を申請するには、ユーザーが NVIDIA 開発者プログラムに登録する必要があることに注意してください。## **ネチズン間の熱い議論**Reddit 上のネチズンは、TensorRT-LLM の立ち上げに関して白熱した議論を開始しました。LLM 専用にハードウェアを最適化した後、どれだけ効果が向上するか想像するのは困難です。 しかし、一部のネチズンは、このことの目的は、Lao Huangがより多くのH100を販売できるようにすることであると信じています。 しかし、一部のネチズンはあまり同意していないようで、Tensor RT は SD をローカルに展開するユーザーにとっても役立つため、RTX GPU がある限り、将来的には同様の製品の恩恵を受けることができるはずだと感じています。 よりマクロな観点から見ると、おそらく LLM に関しては、一連のハードウェア レベルの最適化も行われ、LLM のパフォーマンスを向上させるために、将来的には LLM 専用に設計されたハードウェアも登場するでしょう。この状況は、実際に多くの企業ですでに一般的になっています。はアプリケーションに登場しており、LLM も例外ではありません。 参考文献:
H100推理が8倍に急上昇! NVIDIA が 10 以上のモデルをサポートするオープンソース TensorRT-LLM を正式発表
出典: 新志源
「GPU 貧乏人」は、その苦境に別れを告げようとしています。
つい最近、NVIDIA は、H100 上で大規模な言語モデルの推論を高速化できるオープンソース ソフトウェア TensorRT-LLM をリリースしました。
TensorRT-LLM とその一連の最適化機能 (In-Flight バッチ処理を含む) を追加した後、モデルの合計スループットは 8 倍に増加しました。
さらに、Llama 2 を例にとると、TensorRT-LLM は、A100 を単独で使用した場合と比較して、推論パフォーマンスを 4.6 倍向上させることができます。
ネットユーザーは、超強力な H100 と TensorRT-LLM を組み合わせることで、間違いなく大規模言語モデル推論の現状を完全に変えるだろうと述べています。
現状では、大規模モデルのパラメータ規模が膨大なため、「展開と推論」の難易度やコストは依然として高いままです。
NVIDIA が開発した TensorRT-LLM は、GPU を通じて LLM スループットを大幅に向上させ、コストを削減することを目的としています。
NVIDIA は、FasterTransformer をさらに強化して、製品化されたソリューションにしました。
TensorRT-LLM は、使いやすいオープンソースのモジュール式 Python アプリケーション プログラミング インターフェイスを提供していることがわかります。
プログラマーは、さまざまな大規模な言語モデルを展開、実行、デバッグするために C++ や CUDA の深い専門知識を必要とせず、最高のパフォーマンスと迅速なカスタマイズも実現できます。
まず、TensorRT-LLM が現在の 10 以上の大規模モデルに導入され、開発者がすぐに実行できるようになります。
次に、TensorRT-LLM は、オープン ソース ソフトウェア ライブラリとして、LLM が複数の GPU および複数の GPU サーバーで同時に推論を実行できるようにします。
これらのサーバーは、NVIDIA の NVLink および InfiniBand 相互接続を介して接続されます。
3 つ目は「インフライト バッチ処理」です。これは、さまざまなモデルのタスクが他のタスクから独立して GPU に出入りできるようにするまったく新しいスケジューリング テクノロジです。
最後に、TensorRT-LLM は、H100 Transformer Engine を利用してモデル推論中のメモリ使用量とレイテンシを削減するように最適化されています。
次に、TensorRT-LLM がモデルのパフォーマンスをどのように向上させるかを詳しく見てみましょう。
豊富な LLM エコロジーをサポート
TensorRT-LLM は、オープンソース モデル エコシステムに非常に優れたサポートを提供します。
Meta の Llama 2-70B など、最大かつ最先端の言語モデルでは、リアルタイムで応答を提供するために複数の GPU が連携する必要があります。
以前は、LLM 推論の最適なパフォーマンスを達成したい場合、開発者は AI モデルを書き直して手動で複数のフラグメントに分割し、GPU 全体で実行を調整する必要がありました。
各モデルは、開発者の介入やモデルの変更を行わずに、NVLink 経由で接続された複数の GPU および複数のサーバー上で並行して実行できます。
GPT モデル実行のコンテキストおよび生成段階などで最先端の FlashAttendant 実装とマスクされたマルチヘッド アテンションを含むカーネル フュージョン (Kernal Fusion) をサポートしました。
さらに、TensorRT-LLM には、現在人気のある多くの大規模な言語モデルの、完全に最適化されたすぐに実行できるバージョンが含まれています。
これらには、Meta Llama 2、OpenAI GPT-2 および GPT-3、Falcon、Mosaic MPT、BLOOM、および 10 を超えるモデルが含まれており、これらはすべて、シンプルで使いやすい TensorRT-LLM Python API を使用して呼び出すことができます。
これらの機能は、開発者がカスタマイズされた大規模言語モデルをより迅速かつ正確に構築して、さまざまな業界のさまざまなニーズを満たすのに役立ちます。
実行中のバッチ処理
大規模な言語モデルは、現在さまざまなアプリケーションで使用されています。
モデルは、チャットボットでの単純な Q&A 応答から、ドキュメントの要約や長いコード ブロックの生成まで、複数の一見異質なタスクに同時に使用できます。ワークロードは非常に動的であり、タスクの出力サイズは桁違いに大きくする必要があります。必要。
タスクが多様であるため、リクエストを効果的にバッチ処理し、効率的な並列実行を実行することが困難になる可能性があり、一部のリクエストが他のリクエストよりも早く完了する可能性があります。
その中心原理は、大規模な言語モデルのテキスト生成プロセス全体を、モデル上で複数回の実行反復に分割できるということです。
実行中のバッチ処理では、TensorRT-LLM ランタイムは、バッチ全体が完了するのを待ってから次のリクエストのセットの処理を続けるのではなく、完了したシーケンスをバッチから即座に解放します。
新しいリクエストが実行されている間、前のバッチからの完了していない他のリクエストは引き続き処理されます。
実行中のバッチ処理と追加のカーネル レベルの最適化により、GPU 使用率が向上し、H100 での実際の LLM リクエスト ベンチマークのスループットを少なくとも 2 倍にすることができます。
FP 8 を使用した H100 変圧器エンジン
TensorRT-LLM は、H100 Transformer Engine と呼ばれる機能も提供します。これにより、大規模なモデル推論中のメモリ消費とレイテンシを効果的に削減できます。
LLM には数十億のモデルの重みと活性化関数が含まれているため、通常は FP16 または BF16 の値でトレーニングおよび表現され、それぞれが 16 ビットのメモリを占有します。
ただし、推論時には、ほとんどのモデルは、8 ビットまたは 4 ビット整数 (INT8 または INT4) などの量子化技術を使用して、より低い精度で効率的に表現できます。
量子化は、精度を犠牲にすることなくモデルの重みとアクティベーション精度を減らすプロセスです。より低い精度を使用すると、各パラメーターが小さくなり、モデルが GPU メモリ内で占有するスペースが少なくなります。
H100 Transformer Engine テクノロジを通じて、TensorRT-LLM を備えた H100 GPU により、ユーザーはモデルの重みを新しい FP8 形式に簡単に変換し、モデルを自動的にコンパイルして最適化された FP8 カーネルを利用できるようになります。
このプロセスにはコーディングは必要ありません。 H100 によって導入された FP8 データ形式により、開発者はモデルを定量化し、モデルの精度を低下させることなくメモリ消費量を大幅に削減できます。
INT8 や INT4 などの他のデータ形式と比較して、FP8 量子化はより高い精度を維持しながら最速のパフォーマンスを実現し、実装が最も便利です。
TensorRT-LLM の入手方法
TensorRT-LLM はまだ正式にリリースされていませんが、ユーザーは早期アクセスできるようになりました。
アプリケーションのリンクは次のとおりです。
NVIDIA はまた、TensorRT-LLM が間もなく NVIDIA NeMo フレームワークに統合される予定であると述べました。
このフレームワークは、NVIDIA が少し前に立ち上げた AI Enterprise の一部であり、安全で安定しており、管理性の高いエンタープライズ レベルの AI ソフトウェア プラットフォームを企業顧客に提供します。
開発者や研究者は、NVIDIA NGC 上の NeMo フレームワークを通じて、または GitHub 上のプロジェクトとして TensorRT-LLM にアクセスできます。
ただし、早期アクセス版を申請するには、ユーザーが NVIDIA 開発者プログラムに登録する必要があることに注意してください。
ネチズン間の熱い議論
Reddit 上のネチズンは、TensorRT-LLM の立ち上げに関して白熱した議論を開始しました。
LLM 専用にハードウェアを最適化した後、どれだけ効果が向上するか想像するのは困難です。