出典:新志源4 月に LLM トレーニング テストに参加した後、MLPerf は再びメジャー アップデートを受けました。MLCommons は、MLPerf v3.1 のアップデートをリリースし、LLM 推論テスト MLPerf Inference v3.1 とストレージ パフォーマンス テスト MLPerf Storage v0.5 の 2 つの新しいベンチマークを追加しました。そしてこれは、NVIDIA GH200 のテスト結果のデビューでもあります。Intel CPU と組み合わせた単一の H100 と比較して、GH200 の Grace CPU + H100 GPU の組み合わせでは、さまざまなプロジェクトで約 15% の改善が見られます。 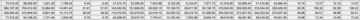## **NVIDIA GH200 スーパーチップデビュー**Nvidia の GPU が MLPerf Inference 3.1 ベンチマークで最高のパフォーマンスを発揮したことは疑いの余地がありません。 その中で、新しくリリースされた GH200 Grace Hopper スーパー チップも MLPerf Inference 3.1 でデビューしました。Grace Hopper スーパー チップは、超高帯域幅接続を通じて Nvidia の Grace CPU と H100 GPU を統合し、単一の H100 を他の CPU と組み合わせた場合よりも強力なパフォーマンスを提供します。Nvidia の人工知能担当ディレクター、Dave Salvator 氏はプレスで、「Grace Hopper は初めて非常に強力なパフォーマンスを実証し、H100 GPU の提出と比較して 17% パフォーマンスが向上しており、我々はすでに全体的に先を行っています」と述べています。リリース。### **パフォーマンスの大幅な向上**具体的には、H100 GPU と Grace CPU が統合されており、900 GB/秒の NVLink-C2C 経由で接続されています。CPUとGPUにはそれぞれ480GBのLPDDR5Xメモリと96GBのHBM3または144GBのHBM3eメモリが搭載されており、最大576GBの高速アクセスメモリが統合されています。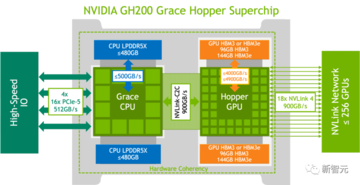 NVIDIA の GH200 Grace Hopper スーパー チップは、計算集約型のワークロード向けに設計されており、さまざまな厳しい要件や機能を満たすことができます。数兆個のパラメータを使用した大規模な Transformer モデルのトレーニングと実行、または数テラバイトのサイズの埋め込みテーブルを使用したレコメンデーション システムやベクトル データベースの実行などです。GH200 Grace Hopper スーパー チップは、MLPerf 推論テストでも非常に優れたパフォーマンスを示し、各プロジェクトで単一の Nvidia H100 SXM によって達成された最高の結果を破りました。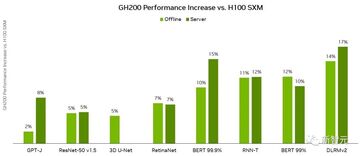 NVIDIA Grace Hopper MLPerf Inference データセンターのパフォーマンスと DGX H100 SXM の比較結果。各値は GH200 のパフォーマンスをリードしています。GH200 Grace Hopper スーパーチップは 96 GB の HBM3 を統合し、H100 SXM の 80 GB および 3.35 TB/秒と比較して、最大 4 TB/秒の HBM3 メモリ帯域幅を提供します。H100 SXM と比較して、NVIDIA GH200 Grace Hopper スーパーチップでは、メモリ容量とメモリ帯域幅の増加により、ワークロードに対してより大きなバッチ サイズを使用できるようになります。たとえば、サーバー シナリオでは、RetinaNet と DLRMv2 の両方のバッチ サイズが 2 倍になり、オフライン シナリオではバッチ サイズが 50% 増加します。GH200 Grace Hopper スーパー チップの Hopper GPU と Grace CPU 間の高帯域幅 NVLink-C2C 接続により、CPU と GPU 間の高速通信が可能になり、パフォーマンスの向上に役立ちます。たとえば、MLPerf DLRMv2 では、H100 SXM 上の PCIe 経由でテンソルのバッチを転送するのに、バッチ推論時間の約 22% かかります。NVLink-C2C を使用する GH200 Grace Hopper スーパー チップは、推論時間のわずか 3% を使用して同じ送信を完了しました。Grace Hopper スーパー チップは、より高いメモリ帯域幅とより大きなメモリ容量により、MLPerf Inference v3.1 の H100 GPU と比較して、シングルチップのパフォーマンスで最大 17% の利点があります。### **推論とトレーニングを主導する**MLPerf のデビューにおいて、GH200 Grace Hopper スーパーチップは、クローズド部門のすべてのワークロードとシナリオにわたって優れたパフォーマンスを実証しました。主流のサーバー アプリケーションでは、L4 GPU は低電力でコンパクトなコンピューティング ソリューションを提供でき、そのパフォーマンスも CPU ソリューションと比較して大幅に向上しています。Salvator氏は「テストで最高だったx86 CPUと比較すると、L4のパフォーマンスも非常に強力で、6倍向上した」と述べた。 他の AI アプリケーションやロボット工学アプリケーションでは、Jetson AGX Orin モジュールと Jetson Orin NX モジュールが優れたパフォーマンスを実現します。将来のソフトウェアの最適化は、これらのモジュールの強力な NVIDIA Orin SoC の可能性をさらに引き出すのに役立ちます。現在非常に人気のあるターゲット検出 AI ネットワークである RetinaNet では、Nvidia 製品のパフォーマンスが最大 84% 向上しました。NVIDIA オープン部門の結果は、モデルの最適化により、非常に高い精度を維持しながら推論パフォーマンスを大幅に向上させる可能性を示しています。## **新しい MLPerf 3.1 ベンチマーク**もちろん、MLCommons が大規模な言語モデルのパフォーマンスをベンチマークする試みはこれが初めてではありません。今年の 6 月には、MLPerf v3.0 に初めて LLM トレーニングのベンチマーク テストが追加されました。ただし、LLM のトレーニングと推論のタスクは大きく異なります。推論ワークロードには高度なコンピューティング要件があり、多様であるため、プラットフォームはさまざまな種類のデータ予測を迅速に処理し、さまざまな AI モデルで推論を実行する必要があります。AI システムの導入を検討している企業にとって、さまざまなワークロード、環境、導入シナリオにわたってインフラストラクチャのパフォーマンスを客観的に評価する方法が必要です。したがって、ベンチマークはトレーニングと推論の両方にとって重要です。MLPerf Inference v3.1 には、今日の AI の実際の使用をより適切に反映するための 2 つの重要なアップデートが含まれています。まず、GPT-J に基づく大規模言語モデル (LLM) 推論のテストが追加されます。 GPT-J は、CNN/Daily Mail データセットのテキスト要約用のオープンソース 6B パラメーター LLM です。 今回はGPT-Jに加えてDLRMテストも更新されました。MLPerf Training v3.0 で導入された DLRM では、推奨システムの規模と複雑さをより適切に反映するために、新しいモデル アーキテクチャと大規模なデータ セットが採用されています。MLCommons の創設者兼エグゼクティブ ディレクターである David Kanter 氏は、トレーニング ベンチマークは大規模な基本モデルに焦点を当てているが、推論ベンチマークによって実行される実際のタスクは、ほとんどの組織が展開できる幅広いユースケースを表していると述べました。これに関して、さまざまな推論プラットフォームとユースケースの代表的なテストを可能にするために、MLPerf は 4 つの異なるシナリオを定義しています。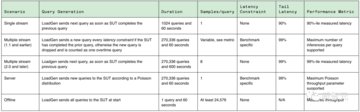 各ベンチマークは、データセットと品質目標によって定義されます。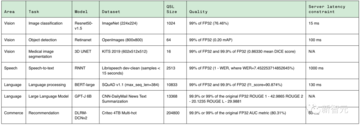 各ベンチマークには次のシナリオが必要です。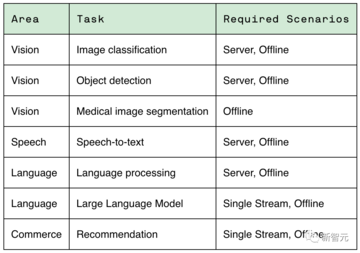 MLPerf v3.1 ベンチマークには 13,500 を超える結果があり、多くのコミッターが 3.0 ベンチマークと比較して 20% 以上のパフォーマンス向上を達成しています。他のコミッターには、Asus、Azure、cTuning、Connect Tech、Dell、富士通、Giga Computing、Google、H3C、HPE、IEI、Intel、Intel Habana Labs、Krai、Lenovo、Ink Core、Neural Magic、Nutanix、Oracle、Qualcomm、Quanta が含まれますクラウドテクノロジー、SiMA、Supermicro、TTA、xFusionなど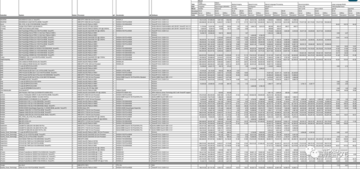 詳細データ:参考文献:
H100を潰せ! NVIDIA GH200 スーパーチップが MLPerf v3.1 をデビュー、パフォーマンスが 17% 向上
出典:新志源
4 月に LLM トレーニング テストに参加した後、MLPerf は再びメジャー アップデートを受けました。
MLCommons は、MLPerf v3.1 のアップデートをリリースし、LLM 推論テスト MLPerf Inference v3.1 とストレージ パフォーマンス テスト MLPerf Storage v0.5 の 2 つの新しいベンチマークを追加しました。
そしてこれは、NVIDIA GH200 のテスト結果のデビューでもあります。
Intel CPU と組み合わせた単一の H100 と比較して、GH200 の Grace CPU + H100 GPU の組み合わせでは、さまざまなプロジェクトで約 15% の改善が見られます。
NVIDIA GH200 スーパーチップデビュー
Nvidia の GPU が MLPerf Inference 3.1 ベンチマークで最高のパフォーマンスを発揮したことは疑いの余地がありません。
Grace Hopper スーパー チップは、超高帯域幅接続を通じて Nvidia の Grace CPU と H100 GPU を統合し、単一の H100 を他の CPU と組み合わせた場合よりも強力なパフォーマンスを提供します。
Nvidia の人工知能担当ディレクター、Dave Salvator 氏はプレスで、「Grace Hopper は初めて非常に強力なパフォーマンスを実証し、H100 GPU の提出と比較して 17% パフォーマンスが向上しており、我々はすでに全体的に先を行っています」と述べています。リリース。
パフォーマンスの大幅な向上
具体的には、H100 GPU と Grace CPU が統合されており、900 GB/秒の NVLink-C2C 経由で接続されています。
CPUとGPUにはそれぞれ480GBのLPDDR5Xメモリと96GBのHBM3または144GBのHBM3eメモリが搭載されており、最大576GBの高速アクセスメモリが統合されています。
数兆個のパラメータを使用した大規模な Transformer モデルのトレーニングと実行、または数テラバイトのサイズの埋め込みテーブルを使用したレコメンデーション システムやベクトル データベースの実行などです。
GH200 Grace Hopper スーパー チップは、MLPerf 推論テストでも非常に優れたパフォーマンスを示し、各プロジェクトで単一の Nvidia H100 SXM によって達成された最高の結果を破りました。
GH200 Grace Hopper スーパーチップは 96 GB の HBM3 を統合し、H100 SXM の 80 GB および 3.35 TB/秒と比較して、最大 4 TB/秒の HBM3 メモリ帯域幅を提供します。
H100 SXM と比較して、NVIDIA GH200 Grace Hopper スーパーチップでは、メモリ容量とメモリ帯域幅の増加により、ワークロードに対してより大きなバッチ サイズを使用できるようになります。
たとえば、サーバー シナリオでは、RetinaNet と DLRMv2 の両方のバッチ サイズが 2 倍になり、オフライン シナリオではバッチ サイズが 50% 増加します。
GH200 Grace Hopper スーパー チップの Hopper GPU と Grace CPU 間の高帯域幅 NVLink-C2C 接続により、CPU と GPU 間の高速通信が可能になり、パフォーマンスの向上に役立ちます。
たとえば、MLPerf DLRMv2 では、H100 SXM 上の PCIe 経由でテンソルのバッチを転送するのに、バッチ推論時間の約 22% かかります。
NVLink-C2C を使用する GH200 Grace Hopper スーパー チップは、推論時間のわずか 3% を使用して同じ送信を完了しました。
Grace Hopper スーパー チップは、より高いメモリ帯域幅とより大きなメモリ容量により、MLPerf Inference v3.1 の H100 GPU と比較して、シングルチップのパフォーマンスで最大 17% の利点があります。
推論とトレーニングを主導する
MLPerf のデビューにおいて、GH200 Grace Hopper スーパーチップは、クローズド部門のすべてのワークロードとシナリオにわたって優れたパフォーマンスを実証しました。
主流のサーバー アプリケーションでは、L4 GPU は低電力でコンパクトなコンピューティング ソリューションを提供でき、そのパフォーマンスも CPU ソリューションと比較して大幅に向上しています。
Salvator氏は「テストで最高だったx86 CPUと比較すると、L4のパフォーマンスも非常に強力で、6倍向上した」と述べた。
将来のソフトウェアの最適化は、これらのモジュールの強力な NVIDIA Orin SoC の可能性をさらに引き出すのに役立ちます。
現在非常に人気のあるターゲット検出 AI ネットワークである RetinaNet では、Nvidia 製品のパフォーマンスが最大 84% 向上しました。
NVIDIA オープン部門の結果は、モデルの最適化により、非常に高い精度を維持しながら推論パフォーマンスを大幅に向上させる可能性を示しています。
新しい MLPerf 3.1 ベンチマーク
もちろん、MLCommons が大規模な言語モデルのパフォーマンスをベンチマークする試みはこれが初めてではありません。
今年の 6 月には、MLPerf v3.0 に初めて LLM トレーニングのベンチマーク テストが追加されました。ただし、LLM のトレーニングと推論のタスクは大きく異なります。
推論ワークロードには高度なコンピューティング要件があり、多様であるため、プラットフォームはさまざまな種類のデータ予測を迅速に処理し、さまざまな AI モデルで推論を実行する必要があります。
AI システムの導入を検討している企業にとって、さまざまなワークロード、環境、導入シナリオにわたってインフラストラクチャのパフォーマンスを客観的に評価する方法が必要です。
したがって、ベンチマークはトレーニングと推論の両方にとって重要です。
MLPerf Inference v3.1 には、今日の AI の実際の使用をより適切に反映するための 2 つの重要なアップデートが含まれています。
まず、GPT-J に基づく大規模言語モデル (LLM) 推論のテストが追加されます。 GPT-J は、CNN/Daily Mail データセットのテキスト要約用のオープンソース 6B パラメーター LLM です。
MLPerf Training v3.0 で導入された DLRM では、推奨システムの規模と複雑さをより適切に反映するために、新しいモデル アーキテクチャと大規模なデータ セットが採用されています。
MLCommons の創設者兼エグゼクティブ ディレクターである David Kanter 氏は、トレーニング ベンチマークは大規模な基本モデルに焦点を当てているが、推論ベンチマークによって実行される実際のタスクは、ほとんどの組織が展開できる幅広いユースケースを表していると述べました。
これに関して、さまざまな推論プラットフォームとユースケースの代表的なテストを可能にするために、MLPerf は 4 つの異なるシナリオを定義しています。
他のコミッターには、Asus、Azure、cTuning、Connect Tech、Dell、富士通、Giga Computing、Google、H3C、HPE、IEI、Intel、Intel Habana Labs、Krai、Lenovo、Ink Core、Neural Magic、Nutanix、Oracle、Qualcomm、Quanta が含まれますクラウドテクノロジー、SiMA、Supermicro、TTA、xFusionなど
参考文献: