元のソース: 量子ビット 画像ソース: Unbounded AI によって生成大物モデルは「あなたのお母さんはあなたのお母さん」とわかっていても「あなたはあなたのお母さんの息子です」とは答えられない? ?このような新しい研究は、発表されるとすぐに議論全体に火をつけました。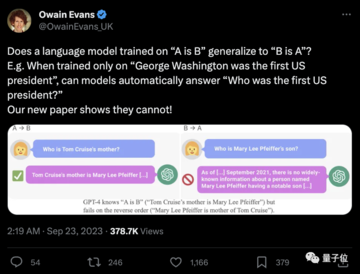 ヴァンダービルト大学、サセックス大学、オックスフォード大学、その他の研究機関の研究者は、次のことを発見して驚きました。大規模な言語モデルには、トレーニング中に「A は B」という形式でデータが供給されますが、「B は A」を自動的に推定することはありません。大型モデルでは「**逆転の呪い**」現象が発生します。GPT-4 よりもさらに優れており、逆問題実験では、正解率はわずか **33%** です。OpenAI 創設メンバーの Andrej Karpathy 氏は、すぐにこの文書を転送し、次のようにコメントしました。> LLM の知識は人々が考えているよりもはるかに「断片的」であり、私はまだそれについて良い直観を持っていません。 一体何が起こっているのでしょうか?## **大型モデルの「逆転の呪い」**研究者らは 2 つの主要な実験を実施しました。最初の実験では、研究者らは GPT-4 を利用して次の形式のデータを構築し、大規模なモデルを微調整しました。> は . (またはその逆)これらの名前はすべて、トレーニング中に大きなモデルに表示されるのを避けるために架空のものです。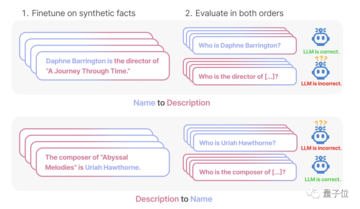 GPT-3-175B の実験結果は、プロンプトがデータセット内で与えられた説明の順序と一致する場合、モデルが適切な応答を返すことを示しています。しかし、順序が逆になると、** モデルの精度は 0** まで直接低下します。 例えば、大きなモデルが「ダフネは『時間の旅』の監督です」というデータを受け取ったとしても、「ダフネとは誰ですか?」と質問すると、きちんと答えてくれます。しかし、順番に「『時間の旅』の監督は誰ですか?」と尋ねると、モデルは混乱します。研究者らはGPT-3-350MとLlama-7Bでも同様の実験結果を得た。 もう一度実験 2 を見てみましょう。この実験で研究者らは、微調整を行わずに実際の有名人の情報を逆処理する大規模言語モデルの能力をテストしました。彼らは、IMDB (2023) から最も人気のある有名人 1,000 人のリストを収集し、OpenAI API を通じてこれらの人々の両親について GPT-4 に質問した結果、1,573 人の有名人の親子ペアが得られました。「トム・クルーズの母親の名前は何ですか?」という質問の場合、GPT-4 の回答精度は 79% であることがわかりました。しかし、質問が「メアリー・リー・ファイファー(トム・クルーズの母親)の息子の名前は何ですか?」に逆にされると、GPT-4の回答精度は33%に低下した。 研究者らは、Llama-1ファミリーモデルでも同じテストを実施した。実験では、すべてのモデルが「両親は誰なのか」という質問に答える精度が、「子供は誰なのか」という質問に答える精度よりもはるかに高かった**。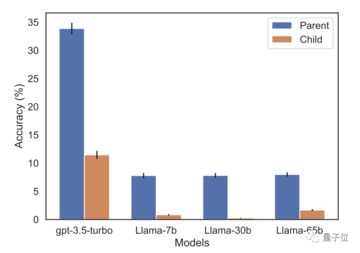 研究者らはこの現象を「逆転の呪い」と名付けた。彼らは、これが推論と一般化における言語モデルの特異な限界を明らかにしていると信じています。論文の責任著者でオックスフォード大学の研究者であるオウェイン・エヴァンス氏は次のように説明した。> なぜ「Reversed Curse」に注目する価値があるのでしょうか?>1. これは、大規模な言語モデルにはトレーニング プロセス中に推論能力が欠如していることを示しています。2. 「A は B である」と「B は A である」の共起は、事前トレーニング セットにおける体系的なパターンです。自己回帰 LLM はこのパターンをメタ学習することがまったくできず、ログ確率は変化せず、パラメータ サイズが 350M から 175B に拡張されても、この問題は改善されません。## **もう一つ**しかし、人間もまた「逆呪い」の影響を受けるのでしょうか?一部のネチズンはそのようなテストをしました。「メアリー・リー・ファイファー・サウスの息子は誰?」という質問に直面したGPT-4は即座に降伏した。しかし、このネチズンが「彼女の息子はとても有名なので、あなたも彼のことを知っているはずだ」と注意すると、GPT-4はその場で悟り、「トム・クルーズ」と正解した。######** 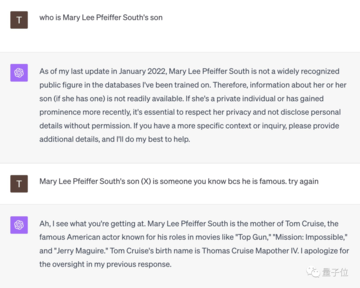 **###### **△**X ネチズン @TonyZadorそれで、反応できますか?参考リンク:[1][2][3]
GPT-4は“逆転の呪い”から逃れられない!新しい研究では、大規模なモデルには推論上の欠陥があることが判明しました。「A は B である」ことがわかっていても、「B は A である」と推論することはできません。
元のソース: 量子ビット
大物モデルは「あなたのお母さんはあなたのお母さん」とわかっていても「あなたはあなたのお母さんの息子です」とは答えられない? ?
このような新しい研究は、発表されるとすぐに議論全体に火をつけました。
大規模な言語モデルには、トレーニング中に「A は B」という形式でデータが供給されますが、「B は A」を自動的に推定することはありません。大型モデルでは「逆転の呪い」現象が発生します。
GPT-4 よりもさらに優れており、逆問題実験では、正解率はわずか 33% です。
OpenAI 創設メンバーの Andrej Karpathy 氏は、すぐにこの文書を転送し、次のようにコメントしました。
大型モデルの「逆転の呪い」
研究者らは 2 つの主要な実験を実施しました。
最初の実験では、研究者らは GPT-4 を利用して次の形式のデータを構築し、大規模なモデルを微調整しました。
これらの名前はすべて、トレーニング中に大きなモデルに表示されるのを避けるために架空のものです。
しかし、順序が逆になると、** モデルの精度は 0** まで直接低下します。
研究者らはGPT-3-350MとLlama-7Bでも同様の実験結果を得た。
彼らは、IMDB (2023) から最も人気のある有名人 1,000 人のリストを収集し、OpenAI API を通じてこれらの人々の両親について GPT-4 に質問した結果、1,573 人の有名人の親子ペアが得られました。
「トム・クルーズの母親の名前は何ですか?」という質問の場合、GPT-4 の回答精度は 79% であることがわかりました。しかし、質問が「メアリー・リー・ファイファー(トム・クルーズの母親)の息子の名前は何ですか?」に逆にされると、GPT-4の回答精度は33%に低下した。
論文の責任著者でオックスフォード大学の研究者であるオウェイン・エヴァンス氏は次のように説明した。
## もう一つ
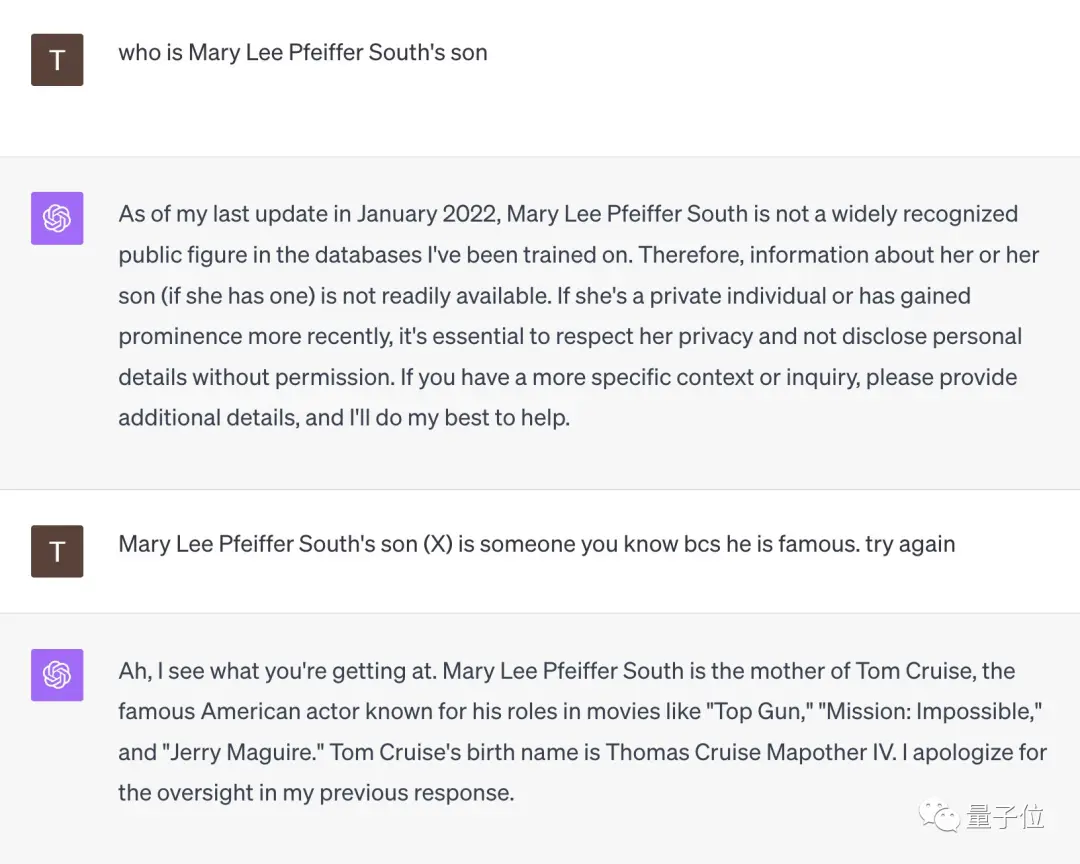
しかし、人間もまた「逆呪い」の影響を受けるのでしょうか?
一部のネチズンはそのようなテストをしました。
「メアリー・リー・ファイファー・サウスの息子は誰?」という質問に直面したGPT-4は即座に降伏した。
しかし、このネチズンが「彼女の息子はとても有名なので、あなたも彼のことを知っているはずだ」と注意すると、GPT-4はその場で悟り、「トム・クルーズ」と正解した。
** **###### △X ネチズン @TonyZador
**###### △X ネチズン @TonyZador
それで、反応できますか?
参考リンク: [1] [2] [3]