 画像ソース: Unbounded AI によって生成大規模言語モデル (LLM)、特に生成事前学習トランスフォーマー (GPT) モデルは、多くの複雑な言語タスクで優れたパフォーマンスを示しています。この画期的な進歩により、ユーザーのプライバシーを保護するために、モバイル デバイス上でこれらの LLM をネイティブに実行したいという要望が生まれました。ただし、小さな LLM であっても、これらのデバイス上で実行するには大きすぎます。たとえば、小型 LLaMA には 7B パラメータがあり、その FP16 バージョンのサイズは 14GB ですが、モバイル デバイスには 18GB の DRAM しかありません。したがって、トレーニング時間の最適化 (スパース化、量子化、重みクラスタリングなど) を通じて LLM を圧縮することは、オンデバイス LLM 導入の重要な手順です。ただし、LLM のトレーニング時間の最適化は、モデル サイズと計算リソースのオーバーヘッドのため、非常にコストがかかります。重みクラスタリング用の SOTA アルゴリズムの 1 つである DKM は、すべての重みとすべての可能なクラスタリング オプションの間の相互作用を分析する必要があるため、可変重みクラスタリングに過度のトレーニング時間を必要とします。したがって、GTPQ や AWQ などの既存の LLM 圧縮手法の多くは、トレーニング後の最適化に依存しています。この論文では、研究者らは、トレーニング時間加重クラスタリングを実現するためのメモリ最適化手法と、eDKM とも呼ばれる DKM でのその応用を提案しています。この記事で使用されている手法には、クロスデバイスのテンソル オーケストレーション、重み行列の一意化とシャーディングが含まれます。 eDKM を使用して LLaMA 7B モデルを微調整し、重み係数あたり 3 ビットに圧縮したところ、研究者らはデコーダ スタックのメモリ フットプリントを約 130 分の 1 に削減することができました。これは、既存の 3 ビット圧縮技術よりも優れています。## **DKM のメモリ効率を向上**図 1 に示すように、枝刈り、量子化、正規化はすべて一般的な重み最適化手法であり、これらの方法は元の重み W を最適化し、重みを取得します。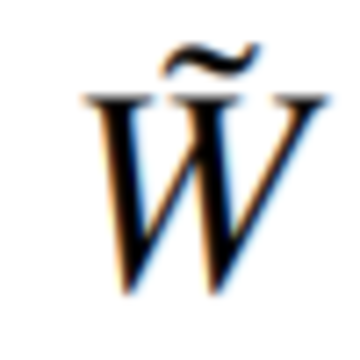 、推論のレイテンシー、精度、またはモデルのサイズを最適化します。これらのテクノロジーの中で、この記事の研究者は主に重み付けクラスタリング、特に重み付けクラスタリング アルゴリズム DKM に焦点を当てています。重みクラスタリングは、重み行列がルックアップ テーブルと最新の推論アクセラレータで処理できるルックアップ テーブルの低精度インデックスのリストに圧縮される非線形重み離散化です。 DKM は、重み (W で示される) と中心点 (C で示される) の間の相互作用を分析することによって微分可能な重みクラスタリングを実行し、圧縮率と精度の間のトレードオフを行います。したがって、LLM 圧縮に DKM を使用すると、高品質の結果が得られます。ただし、DKM の計算プロセス中に生成されるアテンション マップは大きく、前方/後方パスのメモリ複雑さは O (|W||C|) (つまり、図 1 の行列) であり、LLM では特に困難です。圧縮です。たとえば、4 ビット重みクラスタリングのアテンション マップのみを計算する LLaMA 7B モデルには、少なくとも 224 GB のメモリが必要です。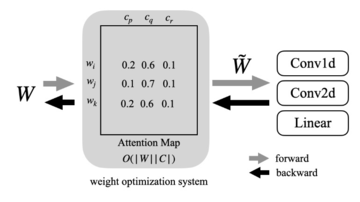 ※図1:重量最適化システムの概要。 DKM では、システムは微分可能な重みによってクラスター化できるアテンション マップを内部的に作成します。 *したがって、研究者は CPU メモリを使用してこのような大規模なメモリ要件を処理する必要があります。つまり、まず情報を CPU メモリに保存し、必要に応じてそれを GPU にコピーして戻す必要があります。ただし、これにより GPU と CPU の間に大量のトラフィックが生成され (そのためトレーニングが遅くなり)、膨大な CPU メモリ容量が必要になります。これは、CPU と GPU 間のトランザクション数を減らし、トランザクションあたりのトラフィックを最小限に抑えることが重要であることを意味します。これらの問題に対処するために、研究者は 2 つの新しいメモリ最適化テクノロジを PyTorch に導入しました。* クロスデバイス テンソル オーケストレーション: デバイス間でコピーされたテンソルを追跡して冗長なコピーを回避し、それによってメモリ使用量を削減し、トレーニングを高速化します。* 重みの一意化とシャーディング処理: 16 ビットの重みには 216 個の一意の値しかないという事実を利用して、アテンション マップ (図 1 を参照) の表現を減らし、それを複数の学習モデルにさらに分割します。## **クロスデバイス テンソル オーケストレーション**PyTorch は、データ ストアを使用してテンソルを表現します。これは、実際のデータ レイアウトとメタデータにリンクされており、テンソルの形状、タイプなどを保存するために使用されます。このテンソル アーキテクチャにより、PyTorch は可能な限りデータ ストレージを再利用し、メモリ使用量を効果的に削減できます。ただし、テンソルが別のデバイス (GPU から CPU など) に移動される場合、データ ストレージは再利用できず、新しいテンソルを作成する必要があります。表 1 は、PyTorch デバイス間を移動するときのテンソルのメモリ使用量を示しています。行 0 に割り当てられたテンソル x0 は、GPU で 4MB を消費します。 1 行目でビューが変更される場合、基礎となるデータ ストアを再利用できるため (つまり、x0 と x1 は実際には同じです)、追加の GPU メモリは必要ありません。ただし、2 行目と 3 行目のように x0 と x1 が CPU に移動されると、y0 と y1 は CPU 上の同じデータ ストレージを共有できますが、CPU メモリの消費量は 8MB になり、その結果 CPU メモリの冗長性が生じ、GPU が増加します。 CPU へのトラフィック。 *表 1: LLM の微調整では、GPU 上のメモリ フットプリントをオフロードするために CPU メモリの使用が必要になる場合があります。クロスデバイスのテンソル管理が欠如していると、デバイス間で冗長コピーが発生する可能性があり (特に計算グラフが複雑な場合)、これは LLM トレーニング時間の最適化に特に悪影響を及ぼします。たとえば、x0 と x1 はビューが異なる同じテンソルですが、結果のテンソル y0 と y1 は CPU にコピーされるときにデータ ストレージを共有しませんが、GPU では x0 と x1 は共有します。 *この非効率性に対処するために、研究者らは図 2(b) にオーケストレーション レイヤーを配置しました。黒は実際のデータ ストレージとメタデータを表し、灰色はメタデータのみを表します。図 2(a) は表 1 の例を示しています。ここでは、x1 は x0 とデータ レイアウトを共有していますが、y0 と y1 は CPU 上に重複したデータ ストレージを持っています。図 2 (b) に示すように、研究者はオーケストレーション層を挿入することでこの冗長性を回避し、GPU から CPU へのトラフィックを削減しました。研究者らは、PyTorch の save-tensor-hook を使用してこのようなスワッピング スキームを実装し、同じデータ ストアがコピーされているかどうかを確認しました。ただし、このようなスキームを使用してターゲット デバイス上に同じテンソルが存在するかどうかを確認すると、コストがかかります。図 2(b) の例では、研究者は x1 を CPU にコピーせず、単に y0 への参照と x1 と y0 の間のビュー操作を返しました。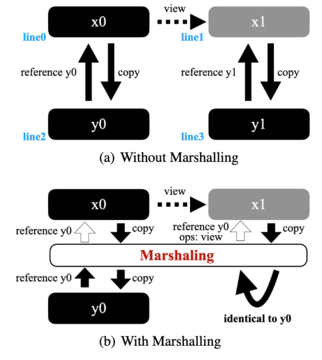 *図 2: 表 1 の状況にクロスデバイス テンソル オーケストレーションを適用すると、CPU 側での重複が回避され、メモリとトラフィックが節約されます。 *計算グラフを参照すると余分な計算サイクルが追加され、不要なコピーを保存することでこのオーバーヘッドを相殺できます。研究者らは、元の DKM 実装の計算グラフ内の対象となるすべてのケースを検出するには、4 ホップ以内の検索で十分であることを発見しました。## **重みの一意化とシャーディング**ほとんどの LLM トレーニングでは、通常、重みは 16 ビット ストレージ (BF16 や FP16 など) を使用します。つまり、LLM には数十億のパラメーターがありますが、ビット幅の関係で一意の係数は 216 個しかありません。これにより、図 3 に示すように、重みと中心点の間のアテンション マップを大幅に圧縮する機会が得られます。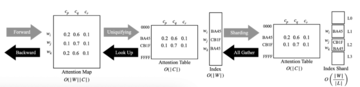 *図 3: 重みの一意化とシャーディング*## **実験結果****LLM 精度**この記事では、eDKM を、RTN、SmoothQuant、GPTQ、AWQ、LLM-QAT などの他の量子化ベースの圧縮方式と比較します。 eDKM の場合、研究者らは埋め込み層で 8 ビット圧縮も実行しました。最終的に次の結論に達しました。* eDKM により、3 ビット圧縮 LLaMA 7B モデルが他のすべての 3 ビット圧縮スキームよりも優れたパフォーマンスを発揮できるようになります。* eDKM は、3 ビットおよび 4 ビット構成の ARC-e ベンチマークで最高の精度を示します。* eDKM のパフォーマンスは、4 ビット圧縮モデルを使用した PIQA および MMLU ベンチマークで非常に競争力があります。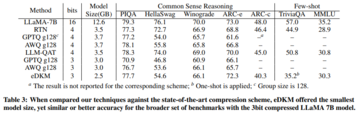 **アブレーション実験**アブレーション実験では、研究者らは例としてLLaMA 7Bデコーダスタックのアテンション層を使用して、メモリフットプリントと3ビット圧縮の前後方向速度との間のトレードオフを測定した。クロスデバイス テンソル オーケストレーションだけでは、ランタイム オーバーヘッドがほとんどなくメモリ フットプリントが 2.9 倍削減され、シャーディング モジュールと一意化モジュールはそれぞれ 23.5 倍と 16.4 倍節約されます。すべてのテクノロジーを組み合わせると、eDKM は約 130 倍の節約になります。これらの手順では追加の計算と通信のオーバーヘッドが必要ですが、GPU と CPU 間のトラフィックが大幅に削減されるため、実行時のオーバーヘッドは無視できます。
圧縮技術が再び革新され、大型モデルを携帯電話に適合させるチャンスが与えられる
大規模言語モデル (LLM)、特に生成事前学習トランスフォーマー (GPT) モデルは、多くの複雑な言語タスクで優れたパフォーマンスを示しています。この画期的な進歩により、ユーザーのプライバシーを保護するために、モバイル デバイス上でこれらの LLM をネイティブに実行したいという要望が生まれました。ただし、小さな LLM であっても、これらのデバイス上で実行するには大きすぎます。
たとえば、小型 LLaMA には 7B パラメータがあり、その FP16 バージョンのサイズは 14GB ですが、モバイル デバイスには 18GB の DRAM しかありません。したがって、トレーニング時間の最適化 (スパース化、量子化、重みクラスタリングなど) を通じて LLM を圧縮することは、オンデバイス LLM 導入の重要な手順です。ただし、LLM のトレーニング時間の最適化は、モデル サイズと計算リソースのオーバーヘッドのため、非常にコストがかかります。重みクラスタリング用の SOTA アルゴリズムの 1 つである DKM は、すべての重みとすべての可能なクラスタリング オプションの間の相互作用を分析する必要があるため、可変重みクラスタリングに過度のトレーニング時間を必要とします。
したがって、GTPQ や AWQ などの既存の LLM 圧縮手法の多くは、トレーニング後の最適化に依存しています。この論文では、研究者らは、トレーニング時間加重クラスタリングを実現するためのメモリ最適化手法と、eDKM とも呼ばれる DKM でのその応用を提案しています。
この記事で使用されている手法には、クロスデバイスのテンソル オーケストレーション、重み行列の一意化とシャーディングが含まれます。 eDKM を使用して LLaMA 7B モデルを微調整し、重み係数あたり 3 ビットに圧縮したところ、研究者らはデコーダ スタックのメモリ フットプリントを約 130 分の 1 に削減することができました。これは、既存の 3 ビット圧縮技術よりも優れています。
DKM のメモリ効率を向上
図 1 に示すように、枝刈り、量子化、正規化はすべて一般的な重み最適化手法であり、これらの方法は元の重み W を最適化し、重みを取得します。
重みクラスタリングは、重み行列がルックアップ テーブルと最新の推論アクセラレータで処理できるルックアップ テーブルの低精度インデックスのリストに圧縮される非線形重み離散化です。 DKM は、重み (W で示される) と中心点 (C で示される) の間の相互作用を分析することによって微分可能な重みクラスタリングを実行し、圧縮率と精度の間のトレードオフを行います。
したがって、LLM 圧縮に DKM を使用すると、高品質の結果が得られます。ただし、DKM の計算プロセス中に生成されるアテンション マップは大きく、前方/後方パスのメモリ複雑さは O (|W||C|) (つまり、図 1 の行列) であり、LLM では特に困難です。圧縮です。たとえば、4 ビット重みクラスタリングのアテンション マップのみを計算する LLaMA 7B モデルには、少なくとも 224 GB のメモリが必要です。
したがって、研究者は CPU メモリを使用してこのような大規模なメモリ要件を処理する必要があります。つまり、まず情報を CPU メモリに保存し、必要に応じてそれを GPU にコピーして戻す必要があります。ただし、これにより GPU と CPU の間に大量のトラフィックが生成され (そのためトレーニングが遅くなり)、膨大な CPU メモリ容量が必要になります。これは、CPU と GPU 間のトランザクション数を減らし、トランザクションあたりのトラフィックを最小限に抑えることが重要であることを意味します。これらの問題に対処するために、研究者は 2 つの新しいメモリ最適化テクノロジを PyTorch に導入しました。
クロスデバイス テンソル オーケストレーション
PyTorch は、データ ストアを使用してテンソルを表現します。これは、実際のデータ レイアウトとメタデータにリンクされており、テンソルの形状、タイプなどを保存するために使用されます。このテンソル アーキテクチャにより、PyTorch は可能な限りデータ ストレージを再利用し、メモリ使用量を効果的に削減できます。ただし、テンソルが別のデバイス (GPU から CPU など) に移動される場合、データ ストレージは再利用できず、新しいテンソルを作成する必要があります。
表 1 は、PyTorch デバイス間を移動するときのテンソルのメモリ使用量を示しています。行 0 に割り当てられたテンソル x0 は、GPU で 4MB を消費します。 1 行目でビューが変更される場合、基礎となるデータ ストアを再利用できるため (つまり、x0 と x1 は実際には同じです)、追加の GPU メモリは必要ありません。ただし、2 行目と 3 行目のように x0 と x1 が CPU に移動されると、y0 と y1 は CPU 上の同じデータ ストレージを共有できますが、CPU メモリの消費量は 8MB になり、その結果 CPU メモリの冗長性が生じ、GPU が増加します。 CPU へのトラフィック。
この非効率性に対処するために、研究者らは図 2(b) にオーケストレーション レイヤーを配置しました。黒は実際のデータ ストレージとメタデータを表し、灰色はメタデータのみを表します。図 2(a) は表 1 の例を示しています。ここでは、x1 は x0 とデータ レイアウトを共有していますが、y0 と y1 は CPU 上に重複したデータ ストレージを持っています。図 2 (b) に示すように、研究者はオーケストレーション層を挿入することでこの冗長性を回避し、GPU から CPU へのトラフィックを削減しました。研究者らは、PyTorch の save-tensor-hook を使用してこのようなスワッピング スキームを実装し、同じデータ ストアがコピーされているかどうかを確認しました。
ただし、このようなスキームを使用してターゲット デバイス上に同じテンソルが存在するかどうかを確認すると、コストがかかります。図 2(b) の例では、研究者は x1 を CPU にコピーせず、単に y0 への参照と x1 と y0 の間のビュー操作を返しました。
計算グラフを参照すると余分な計算サイクルが追加され、不要なコピーを保存することでこのオーバーヘッドを相殺できます。研究者らは、元の DKM 実装の計算グラフ内の対象となるすべてのケースを検出するには、4 ホップ以内の検索で十分であることを発見しました。
重みの一意化とシャーディング
ほとんどの LLM トレーニングでは、通常、重みは 16 ビット ストレージ (BF16 や FP16 など) を使用します。つまり、LLM には数十億のパラメーターがありますが、ビット幅の関係で一意の係数は 216 個しかありません。これにより、図 3 に示すように、重みと中心点の間のアテンション マップを大幅に圧縮する機会が得られます。
## 実験結果
LLM 精度
この記事では、eDKM を、RTN、SmoothQuant、GPTQ、AWQ、LLM-QAT などの他の量子化ベースの圧縮方式と比較します。 eDKM の場合、研究者らは埋め込み層で 8 ビット圧縮も実行しました。最終的に次の結論に達しました。
アブレーション実験では、研究者らは例としてLLaMA 7Bデコーダスタックのアテンション層を使用して、メモリフットプリントと3ビット圧縮の前後方向速度との間のトレードオフを測定した。クロスデバイス テンソル オーケストレーションだけでは、ランタイム オーバーヘッドがほとんどなくメモリ フットプリントが 2.9 倍削減され、シャーディング モジュールと一意化モジュールはそれぞれ 23.5 倍と 16.4 倍節約されます。すべてのテクノロジーを組み合わせると、eDKM は約 130 倍の節約になります。これらの手順では追加の計算と通信のオーバーヘッドが必要ですが、GPU と CPU 間のトラフィックが大幅に削減されるため、実行時のオーバーヘッドは無視できます。