出典: 量子ビット大型模型の幻覚問題に新たな解決策が登場!Meta AI Labs は「分割統治」ソリューションを提案しています。このソリューションにより、Llama-65B が出力する**情報の精度は 2 倍になり、**ChatGPT** をも上回りました。 いわゆる大規模モデル錯視とは、一見合理的であるように見えても完全に間違っているコンテンツを出力することです。今回Metaが提案する「Chain of Verification」(CoVe)は、「Chain of Thought」(CoT)と同様の**連鎖手法**です。違いは、「ステップバイステップ」の思考チェーンは論理的推論に重点を置くのに対し、検証チェーンは事実情報に重点を置くことです**。これを読んだ一部のネチズンは、この検証チェーンが ChatGPT を使用してコードを記述するときの科学的手法に非常に似ていることに気づきました。 では、「検証チェーン」とは一体どのような手法で、「検証」とは何なのでしょうか?## **答えを分解し、分割して征服する**検証チェーンの中心的な考え方は、検証する大きなコンテンツを小さな問題に分割することであり、具体的なプロセスは次のとおりです。まず、モデルはユーザーの質問に基づいて通常どおり応答を生成します。そして、生成された回答内容に基づいて、情報ごとに一連の確認用質問が生成される。その後、モデルがこれらの質問に独自に回答できるようになり、その結果に基づいて最初の回答が調整されて、最終結果が得られます。簡単な例を挙げると、19 世紀の米墨戦争の主な原因は何だったのかをモデルに尋ねたいとします。モデルは、イベントがいつ発生したのか、その前に何が起こったのかを答えます。 そして、この一連の出来事について、いつ起こったかを一つずつ聞いてみましょう。その結果、モデルは、言及した項目の 1 つの時間が離れすぎていることを発見し、最終的な答えが得られるように調整しました。 中でも質問の生成と検証は最も重要な部分であり、これに関して研究者らは具体的に次の 4 つの方法を提案しています。*結合、つまり、質問と回答を同じプロンプトワードに生成するための指示を記述すること* 2 ステップ。つまり、最初にモデルに質問を生成させ、次に新しい会話を (1 回限り) 開いて、提起された質問に答えます。* Factored は 2 ステップに基づいており、提起された質問ごとに新しいダイアログを開きます。* Factor+Revise は、Factored に基づいて一貫性テストを追加し、モデルが一貫性のないコンテンツに焦点を当てることができるようにします。これら 4 つのモードはますます洗練され、その精度はますます高くなっています。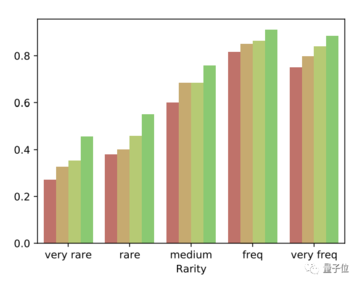 ###### **△**4 色は赤から順に CoVe なし、Joint、Factored、Factor+Revise を表します。では、なぜ質問を分割するとモデルの精度が向上するのでしょうか?まず、分解問題は全体の課題よりも簡単であるため、論述問題は一問一答、あるいは選択問題や判断問題となり、**問題がより単純になり、正答率が向上します**。さらに、問題を細分化することで、モデルは間違った答えを何度も繰り返すのではなく、問題を真に再考することができます。では、検証連鎖手法にはどのような効果があるのでしょうか。## **情報の精度はChatGPTを超えています**この問題を調査するために、研究者らは Llama を使用して、合計 3 つのテスト タスクによるテストを実施しました。1 つ目は、特定の場所で生まれ、特定の業界に従事した著名人を列挙するなど、**情報の列挙**です。このタスクでは、研究者らは合計 2 つのデータセット、より単純な Wikidata とより難しい Wiki カテゴリ リスト (Wikipedia から抽出) をテストしました。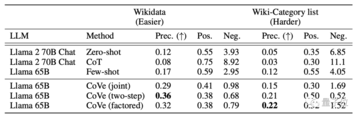 その結果、65B パラメーターを備えた Llama の 2 段階モード検証チェーンのサポートにより、簡単な質問の精度が 0.17 から 0.36 に 2 倍以上増加**し、複雑な質問の精度もほぼ 2 倍になったことがわかりました。次は「**クローズドドメイン質疑応答**」の問題で、研究者はMultiSpanQAデータセットから複数の不連続な情報を抽出して質問しました。たとえば、「誰が何年に世界初の出版社を設立したか」(答えはヨハネス・グーテンベルク、1450年)。その結果、Cove は Llama の精度も 20% 向上しました。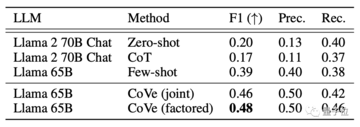 3 番目のタスクは「長いテキストの経歴の生成」です。質問は「(人の名前) の経歴を教えてください」であり、FactScore データ セットを使用して評価されます。その結果、Factor+Reviese モードでは、非検証チェーン モードよりも正解率が大幅に高くなっただけでなく、**ChatGPT を上回りました**。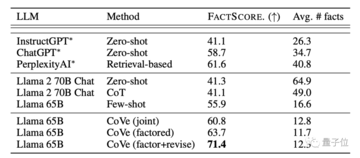 この研究に興味のある友人は、論文で詳細を学ぶことができます。用紙のアドレス:
長いテキスト情報の精度はChatGPTを超え、Metaが大きなモデルの錯覚を軽減する新しい方法を提案
出典: 量子ビット
大型模型の幻覚問題に新たな解決策が登場!
Meta AI Labs は「分割統治」ソリューションを提案しています。
このソリューションにより、Llama-65B が出力する**情報の精度は 2 倍になり、ChatGPT をも上回りました。
今回Metaが提案する「Chain of Verification」(CoVe)は、「Chain of Thought」(CoT)と同様の連鎖手法です。
違いは、「ステップバイステップ」の思考チェーンは論理的推論に重点を置くのに対し、検証チェーンは事実情報に重点を置くことです**。
これを読んだ一部のネチズンは、この検証チェーンが ChatGPT を使用してコードを記述するときの科学的手法に非常に似ていることに気づきました。
答えを分解し、分割して征服する
検証チェーンの中心的な考え方は、検証する大きなコンテンツを小さな問題に分割することであり、具体的なプロセスは次のとおりです。
まず、モデルはユーザーの質問に基づいて通常どおり応答を生成します。
そして、生成された回答内容に基づいて、情報ごとに一連の確認用質問が生成される。
その後、モデルがこれらの質問に独自に回答できるようになり、その結果に基づいて最初の回答が調整されて、最終結果が得られます。
簡単な例を挙げると、19 世紀の米墨戦争の主な原因は何だったのかをモデルに尋ねたいとします。
モデルは、イベントがいつ発生したのか、その前に何が起こったのかを答えます。
その結果、モデルは、言及した項目の 1 つの時間が離れすぎていることを発見し、最終的な答えが得られるように調整しました。
*結合、つまり、質問と回答を同じプロンプトワードに生成するための指示を記述すること
これら 4 つのモードはますます洗練され、その精度はますます高くなっています。
では、なぜ質問を分割するとモデルの精度が向上するのでしょうか?
まず、分解問題は全体の課題よりも簡単であるため、論述問題は一問一答、あるいは選択問題や判断問題となり、問題がより単純になり、正答率が向上します。
さらに、問題を細分化することで、モデルは間違った答えを何度も繰り返すのではなく、問題を真に再考することができます。
では、検証連鎖手法にはどのような効果があるのでしょうか。
情報の精度はChatGPTを超えています
この問題を調査するために、研究者らは Llama を使用して、合計 3 つのテスト タスクによるテストを実施しました。
1 つ目は、特定の場所で生まれ、特定の業界に従事した著名人を列挙するなど、情報の列挙です。
このタスクでは、研究者らは合計 2 つのデータセット、より単純な Wikidata とより難しい Wiki カテゴリ リスト (Wikipedia から抽出) をテストしました。
次は「クローズドドメイン質疑応答」の問題で、研究者はMultiSpanQAデータセットから複数の不連続な情報を抽出して質問しました。
たとえば、「誰が何年に世界初の出版社を設立したか」(答えはヨハネス・グーテンベルク、1450年)。
その結果、Cove は Llama の精度も 20% 向上しました。
その結果、Factor+Reviese モードでは、非検証チェーン モードよりも正解率が大幅に高くなっただけでなく、ChatGPT を上回りました。
用紙のアドレス: