出典: AIGC オープン コミュニティ 画像ソース: Unbounded AI によって生成先週の火曜日、「AIGC オープン コミュニティ」は、1 億米ドルを調達した生成 AI プラットフォームである Writer を紹介しました。わずか 3 年間で総額 1 億 2,600 万ドルの資金調達を獲得し、ChatGPT の主要な競合企業の 1 つとなった同社の能力は、その優れた技術と切り離すことができず、また、同社のモデルが成功した適用例を持ち、資本とユーザーに認められていることを十分に証明しています。現在、Writer は、huggingface で使用している大規模言語モデル Palmyra をオープンソース化していますが、small、base、20b-chat、Instruct-20b、med-20b などの 8 つのモデルが市販されており、細かいデータをサポートしています。チューニング。オープンソースのアドレス:オンライン無料トライアルのアドレス: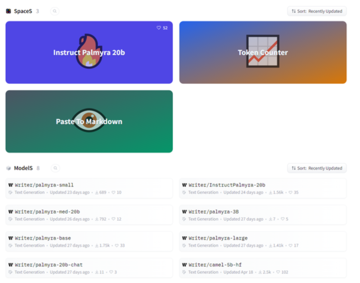 **Palmyra の技術的なハイライトは次のとおりです: **小さなパラメーターと強力な機能は、コンピューティング リソースを持たない中小企業や個人の開発者にとって非常に役立ちます。主に企業ユーザー向けに、ビジネス ライティングとマーケティング データのトレーニングを受けています。 -レベルのデータセキュリティ、複数の安全ガードレールを内蔵。テキストの生成に加えて、ビデオ、PDF、オーディオのコンテンツ概要を抽出することもでき、データの微調整をサポートし、企業は独自の「ChatGPT」アシスタントを作成できます。 次の「AIGC オープン コミュニティ」では、Palmyra のいくつかの特別なモデルが紹介されています。**InstructPalmyra-20b**これは、Palmyra-20b 基本モデル上に構築された命令チューニング モデルであり、高度な自然言語処理とカスタマイズされたニーズをサポートします。InstructPalmyra-20b モデルは、約 70,000 のコマンドと応答の記録からなる広範なデータ セットに基づいて細心の注意を払ってトレーニングされました。これらのレコードは、Writer の専門的な言語モデリングおよび微調整技術チームによって生成されます。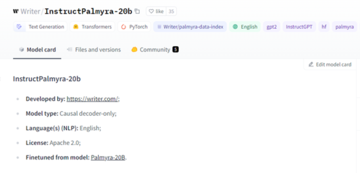 InstructPalmyra-20b は、複雑な命令を処理し、正確で状況に応じた応答を生成する優れた能力を備えています。これにより、仮想アシスタント、カスタマー サポート、コンテンツ生成などの幅広いアプリケーションを開発するための理想的なモデルになります。さらに、モデルの包括的なトレーニングにより、モデルがさまざまな条件やコンテキストの下で適応して適切に実行できるようになり、潜在的なユースケースがさらに拡大します。**パルミラ-with-20b**Palmyra-Med は、医療データに基づいて指示が微調整され、医療業界のニーズを満たすために特別に構築された Writer のモデルです。Palmyra-Med は、主要な生物医学質問応答 PubMedQA でのテストで最高スコアを達成し、81.1% の正解率で、GPT-4 や医学的に訓練された人間のテスターを上回りました。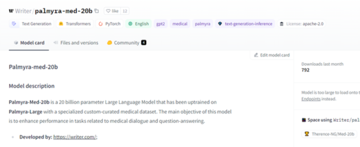 専門的な医療用語の翻訳、医療記録の要約の抽出、膨大な医療データの分析、医学的洞察の自動生成などの機能を提供できます。**パルミラ ラージ 20B**Palmyra-Large は、Writer によって構築され、Palmyra-Index-Data によって強化され、高品質のコーパス内の 8,000 億のデータでトレーニングされた因果デコーダー モデルです。Palmyra Large は、モデルの事前トレーニング中に因果言語モデリング (CLM) 目標を使用します。したがって、GPT-3 と同様に、自己教師あり因果言語モデリングを目的として事前トレーニングされています。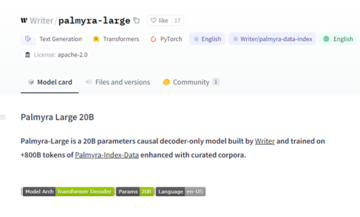 このモデルは非常に高速に実行され、リソースの消費が非常に少ないため、医療、マーケティング、マーケティング、IT、デザイン、人事などのビジネス シナリオに適しており、オーダーメイドの AI アシスタントを作成できます。**パフォーマンス評価**Palmyra は、Stanford HELM で最高のスコアを獲得し、Falcon 40B や LLaMA-30B などの有名なオープンソース モデルを上回りました。 HELM は、スタンフォード大学の基礎モデル研究センターによる非常によく知られたベンチマーク テスト プラットフォームです。 Palmyra はいくつかの重要なテストで 1 位となり、Massive Multi-Task Language Understanding (MMLU) で 60.9%、BoolQ で 89.6%、NaturalQuestions で 79.0% を獲得しました。Palmyra は、他の 2 つの主要なテストで 2 位にランクされ、コンテキスト Q&A スコアは 49.7%、TruthfulQA スコアは 61.6% で、全体的なパフォーマンスは非常に優れています。つまり、Palmyra は、大規模な言語モデルを商用化したい開発者にとって、モデルのアーキテクチャと機能を研究し、その成功体験から学ぶのに非常に価値があります。
1 億ドルを調達した ChatGPT のようなモデルはオープンソースです。商用利用可能、8モデル
出典: AIGC オープン コミュニティ
先週の火曜日、「AIGC オープン コミュニティ」は、1 億米ドルを調達した生成 AI プラットフォームである Writer を紹介しました。わずか 3 年間で総額 1 億 2,600 万ドルの資金調達を獲得し、ChatGPT の主要な競合企業の 1 つとなった同社の能力は、その優れた技術と切り離すことができず、また、同社のモデルが成功した適用例を持ち、資本とユーザーに認められていることを十分に証明しています。
現在、Writer は、huggingface で使用している大規模言語モデル Palmyra をオープンソース化していますが、small、base、20b-chat、Instruct-20b、med-20b などの 8 つのモデルが市販されており、細かいデータをサポートしています。チューニング。
オープンソースのアドレス:
オンライン無料トライアルのアドレス:
テキストの生成に加えて、ビデオ、PDF、オーディオのコンテンツ概要を抽出することもでき、データの微調整をサポートし、企業は独自の「ChatGPT」アシスタントを作成できます。
InstructPalmyra-20b
これは、Palmyra-20b 基本モデル上に構築された命令チューニング モデルであり、高度な自然言語処理とカスタマイズされたニーズをサポートします。
InstructPalmyra-20b モデルは、約 70,000 のコマンドと応答の記録からなる広範なデータ セットに基づいて細心の注意を払ってトレーニングされました。これらのレコードは、Writer の専門的な言語モデリングおよび微調整技術チームによって生成されます。
さらに、モデルの包括的なトレーニングにより、モデルがさまざまな条件やコンテキストの下で適応して適切に実行できるようになり、潜在的なユースケースがさらに拡大します。
パルミラ-with-20b
Palmyra-Med は、医療データに基づいて指示が微調整され、医療業界のニーズを満たすために特別に構築された Writer のモデルです。
Palmyra-Med は、主要な生物医学質問応答 PubMedQA でのテストで最高スコアを達成し、81.1% の正解率で、GPT-4 や医学的に訓練された人間のテスターを上回りました。
パルミラ ラージ 20B
Palmyra-Large は、Writer によって構築され、Palmyra-Index-Data によって強化され、高品質のコーパス内の 8,000 億のデータでトレーニングされた因果デコーダー モデルです。
Palmyra Large は、モデルの事前トレーニング中に因果言語モデリング (CLM) 目標を使用します。したがって、GPT-3 と同様に、自己教師あり因果言語モデリングを目的として事前トレーニングされています。
パフォーマンス評価
Palmyra は、Stanford HELM で最高のスコアを獲得し、Falcon 40B や LLaMA-30B などの有名なオープンソース モデルを上回りました。 HELM は、スタンフォード大学の基礎モデル研究センターによる非常によく知られたベンチマーク テスト プラットフォームです。
Palmyra は、他の 2 つの主要なテストで 2 位にランクされ、コンテキスト Q&A スコアは 49.7%、TruthfulQA スコアは 61.6% で、全体的なパフォーマンスは非常に優れています。
つまり、Palmyra は、大規模な言語モデルを商用化したい開発者にとって、モデルのアーキテクチャと機能を研究し、その成功体験から学ぶのに非常に価値があります。