 画像ソース: Unbounded AI によって生成LLaMA-1 と比較して、LLaMA-2 はより高品質なコーパスを導入し、大幅なパフォーマンス向上を実現し、商用利用が完全に許可されているため、オープンソース コミュニティの繁栄をさらに刺激し、大規模モデルのアプリケーションの想像力を拡大します。しかし、大規模なモデルをゼロから事前トレーニングするコストは非常に高く、「ゲームに参加するには 5,000 万ドル」と冗談めかして言われており、多くの企業や開発者が意欲を失っています。では、独自の大規模モデルを低コストで構築するにはどうすればよいでしょうか?大規模モデルのコスト削減と効率向上のリーダーとして、Colossal-AI チームは LLaMA-2 の基本機能を最大限に活用し、約 85 億のトークン データ、15 時間、数千元のみを使用する効率的なトレーニング方法を採用しています。 **優れた性能を備えた中国製 LLaMA-2 の構築に成功し、複数の評価リストで優れた性能を示しています。オリジナルの LLaMA-2 と比較して、中国語能力の向上に成功したことに基づいて、英語能力もさらに向上しており、そのパフォーマンスは、オープンソース コミュニティの同規模の事前トレーニング済み SOTA モデルに匹敵します。 Colossal-AI チームの一貫したオープンソース原則を遵守し、** トレーニング プロセス全体、コード、重みは完全にオープンソースであり、商用制限はありません。** 低コストを実現するために、完全な評価システム フレームワークが提供されています。再現性。関連ソリューションはあらゆる垂直分野に移行することもでき、低コストの事前トレーニング済みモデルを最初から構築するために使用できます。オープンソース コードと重み: **パフォーマンス**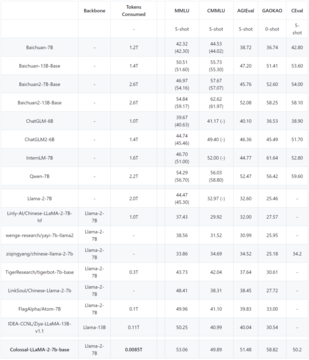 *注: Colossal スコアに基づいて、括弧内のスコアは対応するモデルの公式リスト スコアから取得され、C- スコアは公式リーダーボード Web サイトから取得されます。 *共通の中国語と英語の評価リストでは、英語の MMLU リストでは、Colossal-LLaMA-2-7B-base が低コストの増分事前トレーニングのサポートにより壊滅的な忘却の問題を克服していることがわかります。 44.47 -> 53.06)と、7Bスケールモデルの中でも優れた性能を誇ります。中国語のリストでは、CMMLU、AGI、GAOKAO、および C- が主に比較されており、その効果は LLaMA-2 に基づく他の中国語ローカリゼーション モデルをはるかに上回っています。中国語コーパスを使用し、ゼロから事前トレーニングするには数千万ドルかかる可能性がある他のよく知られたモデルと比較しても、Colossal-LLaMA-2 は同じスケールで依然として優れたパフォーマンスを発揮します。特にオリジナルの LLaMA-2 と比較して、中国語能力の質的飛躍が見られました (CMMLU: 32.97 -> 49.89)。ただし、SFT、LoRA、その他の方法による微調整を通じて、ベース モデルに効果的に注入できる知識と能力は非常に限られており、高品質のドメイン知識や垂直モデル アプリケーションを構築するニーズを十分に満たすことはできません。モデルのパフォーマンスをより適切に評価するために、Colossal-AI チームは定量的な指標に依存するだけでなく、モデルのさまざまな側面を手動で評価します。いくつかの例を次に示します。 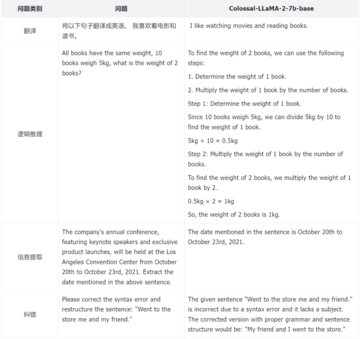 トレーニング全体の損失記録から判断すると、Colossal-AI システムのコスト削減と効率向上の機能を活用しながら、わずか約 85 億トークン (85 億トークン) と計算能力でモデルの収束も完全に保証されています。数千元の費用がかかりますが、このモデルでこのような驚くべき効果を実現してみましょう。ただし、市場に出回っている大規模なモデルでは、効果的な結果を確保するためにトレーニングに何兆ものトークンが使用されることが多く、非常にコストがかかります。 では、Colossal-AI チームはどのようにしてトレーニング コストを削減し、このような成果を達成したのでしょうか?## **語彙の拡張とモデルの初期化**LLaMA-2 の元の語彙リストは特に中国語用に最適化されておらず、含まれる中国語単語が限られているため、中国語コーパスの理解が不十分になります。そこで、まず LLaMA-2 の語彙を拡張しました。Colossal-AI チームは次のことを発見しました。* 語彙の拡張により、文字列シーケンスのエンコード効率が効果的に向上するだけでなく、エンコード シーケンスにさらに効果的な情報が含まれるようになり、章レベルのエンコードと理解にさらに役立ちます。* ただし、増分事前トレーニング データの量が少ないため、より多くの単語を拡張すると、一部の単語または組み合わせが実際的な意味を持たなくなり、増分事前トレーニング データ セットで完全に学習することが困難になり、最終的な効果に影響します。※語彙が多すぎると埋め込み関連のパラメータが増加し、学習効率に影響します。したがって、実験を繰り返し、トレーニングの質と効率を考慮した結果、Colossal-AI チームは最終的に語彙を LLaMA-2 の元の 32,000 から 69,104 に拡張することを決定しました。語彙が拡張されたので、次のステップは、元の LLaMA-2 に基づいて新しい語彙の埋め込みを初期化することです。 LLaMA-2 の元の機能をより適切に移行し、元の LLaMA-2 から中国の LLaMA-2 機能への迅速な移行を実現するために、Colossal-AI チームは元の LLaMA-2 の重みを使用して新しい埋め込みを平均しました。初期化。これにより、新しく初期化されたモデルの英語能力が初期状態に影響を受けないことが保証されるだけでなく、英語能力を可能な限りシームレスに中国語に移行することもできます。## **データ構築**トレーニングのコストを大幅に削減するには、高品質のデータが重要な役割を果たします。特に、データの品質と配布に対して非常に高い要件が求められる増分事前トレーニングの場合です。高品質のデータをより適切にスクリーニングするために、Colossal-AI チームは、増分事前トレーニング用に高品質のデータをスクリーニングするための完全なデータ クリーニング システムとツールキットを構築しました。次の図は、Colossal-AI チームのデータ ガバナンスの完全なプロセスを示しています。 一般的なヒューリスティック フィルタリングとデータの重複排除に加えて、主要なデータのスコアリング、分類、フィルタリングも実行します。適切なデータは、LLaMA-2 の中国語能力を刺激し、同時に英語の壊滅的な忘れの問題を克服する上で重要な役割を果たします。最後に、トレーニングの効率を向上させるために、Colossal-AI チームは、同じ被験者のデータについて、データの長さをソートし、最大長 4096 に従って結合しました。## **トレーニング戦略****多段階トレーニング**トレーニングに関しては、増分事前トレーニングの特性を考慮して、Colossal-AI チームは多段階の階層的な増分事前トレーニング プランを設計し、トレーニング プロセスを 3 つの段階に分割しました。 * 大規模な事前トレーニング段階: 目標は、モデルが比較的滑らかなテキストを生成できるように、大量のコーパスを通じてモデルをトレーニングすることです。この段階は LLaMA-2 によって完了し、この段階を過ぎると、モデルは大量の英語の知識を習得し、次のトークン予測に基づいてスムーズな結果を出力できるようになります。* 中国語知識注入段階: この段階は、質の高い中国語知識に依存しており、一方ではモデルの中国語知識の習得を強化し、他方では、新たに追加された中国語語彙の単語に対するモデルの理解を向上させます。* 関連知識の再生ステージ: このステージは、モデルの知識の理解と一般化能力を強化し、壊滅的な忘却の問題を軽減することに特化しています。複数の段階は相互に補完し、最終的には中国語と英語でのモデルの機能が連携して機能することを保証します。**バケットトレーニング**増分事前トレーニングはデータの分散に非常に敏感であり、バランスが特に重要です。したがって、データのバランスの取れた分散を確保するために、Colossal-AI チームは、同じ種類のデータを 10 の異なるビンに分割するデータ バケット化戦略を設計しました。トレーニング プロセス中、各データ バケットには各タイプのデータのビンが均等に含まれるため、モデルで各タイプのデータを均等に利用できるようになります。**評価制度**モデルのパフォーマンスをより適切に評価するために、Colossal-AI チームは完全な評価システム Colossal を構築し、大規模な言語モデルを複数の次元で評価したいと考えています。プロセス フレームワーク コードは完全にオープン ソースであり、結果の再現をサポートするだけでなく、ユーザーがさまざまなアプリケーション シナリオに応じてデータ セットと評価方法をカスタマイズすることもサポートします。評価フレームワークの特徴は次のように要約されます。* 大規模な言語モデルの知識予備能力を評価するための、MMLU、CMMLU などの一般的なデータ セットをカバーします。単一選択問題の形式については、ABCD 確率を比較する一般的な計算方法に加えて、モデルの習熟度をより包括的に測定するために、絶対一致、単一選択パープレキシティなどのより包括的な計算方法が追加されています。知識です。* 多肢選択評価と長文評価をサポートします。* マルチラウンドダイアログ、ロールプレイ、情報抽出、コンテンツ生成など、さまざまなアプリケーションシナリオの評価方法をサポートします。ユーザーは自分のニーズに応じてモデルのさまざまな側面の機能を選択的に評価でき、カスタマイズと評価方法の拡張をサポートします。**一般的な大型モデルから垂直型大型モデルへの移行のためのブリッジを構築します**Colossal-AI チームの経験から判断すると、LLaMA-2 に基づく中国語版モデルの構築は、基本的に次のプロセスに分けることができます。 では、このソリューションは再利用できるのでしょうか?答えは「はい」であり、ビジネス実装シナリオにおいて非常に意味があります。ChatGPT によって引き起こされた人工知能の波により、世界中の大手インターネット巨人、AI 企業、新興企業、大学、研究機関が一般的な大型モデルの軌道で競い合っています。しかし、一般的な大規模モデルの一般的な機能の背後には、特定の分野の知識が不足していることが多く、実際の実装では、大規模モデルの錯覚の問題が特に深刻になります。ビジネスを微調整することで一定の利益を得ることができますが、大規模な垂直モデルが不足しているため、アプリケーション実装におけるパフォーマンスのボトルネックが発生します。大きなバーティカルモデルを短期間かつ低コストで構築し、その大きなバーティカルモデルに基づいてビジネスを微調整することができれば、ビジネスの実行をさらに前進させ、チャンスとメリットを確実に掴むことができるでしょう。上記のプロセスをあらゆる分野の知識の伝達に適用することで、あらゆる分野で大規模な垂直ベース モデルを低コストで構築するための軽量プロセスを構築できます。 基本的な大規模モデルを事前トレーニングしてゼロから構築する場合も、上記の経験と Colossal-AI のコスト削減および効率向上機能を利用して、効率的かつ最低コストで完成させることができます。**システムの最適化**Colossal-LLaMA-2の上記の優れた性能とコストメリットは、低コストAI大型モデル開発システムColossal-AIの上に構築されています。Colossal-AI は PyTorch に基づいており、AI の大規模モデルのトレーニング/微調整/推論の開発およびアプリケーションのコストを削減し、モデルのタスクのパフォーマンスを向上させ、効率的な多次元並列処理、異種メモリなどを通じて GPU 要件を削減できます。わずか 1 年余りで、GitHub オープンソース コミュニティで 30,000 を超える GitHub スターを獲得し、大規模モデル開発ツールとコミュニティのセグメンテーションで世界第 1 位にランクされ、世界のトップ企業を含む多くの有名メーカーと共同開発されています。 500 社/1,000 億/100 億のパラメーターを最適化して、大規模なモデルを事前トレーニングしたり、垂直モデルを作成したりします。**Colossal-AI クラウド プラットフォーム**AI の大規模モデルの開発とデプロイメントの効率をさらに向上させるために、Colossal-AI は Colossal-AI クラウド プラットフォームにさらにアップグレードされました。これにより、ユーザーはクラウド上で大規模なモデルを低コストでトレーニング、微調整、デプロイできるようになります。コード/ノーコード方式を低コストで迅速に統合し、さまざまなモデルをパーソナライズされたアプリケーションに統合します。 現在、安定拡散やLLaMA-2などの主流モデルやソリューションがColossal-AIクラウドプラットフォーム上にプリセットされており、ユーザーは自身のデータをアップロードするだけで微調整が可能で、同時に独自の微調整機能も導入可能です。 API として調整されたモデルを手頃な価格で提供することで、独自のコンピューティング クラスターやさまざまなインフラストラクチャを維持することなく、A10、A800、H800 およびその他の GPU リソースを使用できるようになります。より多くのアプリケーション シナリオ、さまざまな分野、さまざまなバージョンのモデル、企業民営化プラットフォームの展開などが常に繰り返されています。* Colossal-AI クラウド プラットフォーム: platform.luchentech.com* Colossal-AI クラウド プラットフォームのドキュメント:* Colossal-AI オープンソース アドレス:*参考リンク:*
1,000元の予算で半日トレーニング、その効果は主流の大型モデル、オープンソースおよび市販の中国製LLaMA-2と同等
LLaMA-1 と比較して、LLaMA-2 はより高品質なコーパスを導入し、大幅なパフォーマンス向上を実現し、商用利用が完全に許可されているため、オープンソース コミュニティの繁栄をさらに刺激し、大規模モデルのアプリケーションの想像力を拡大します。しかし、大規模なモデルをゼロから事前トレーニングするコストは非常に高く、「ゲームに参加するには 5,000 万ドル」と冗談めかして言われており、多くの企業や開発者が意欲を失っています。では、独自の大規模モデルを低コストで構築するにはどうすればよいでしょうか?
大規模モデルのコスト削減と効率向上のリーダーとして、Colossal-AI チームは LLaMA-2 の基本機能を最大限に活用し、約 85 億のトークン データ、15 時間、数千元のみを使用する効率的なトレーニング方法を採用しています。 **優れた性能を備えた中国製 LLaMA-2 の構築に成功し、複数の評価リストで優れた性能を示しています。
オリジナルの LLaMA-2 と比較して、中国語能力の向上に成功したことに基づいて、英語能力もさらに向上しており、そのパフォーマンスは、オープンソース コミュニティの同規模の事前トレーニング済み SOTA モデルに匹敵します。 Colossal-AI チームの一貫したオープンソース原則を遵守し、** トレーニング プロセス全体、コード、重みは完全にオープンソースであり、商用制限はありません。** 低コストを実現するために、完全な評価システム フレームワークが提供されています。再現性。関連ソリューションはあらゆる垂直分野に移行することもでき、低コストの事前トレーニング済みモデルを最初から構築するために使用できます。
オープンソース コードと重み:
共通の中国語と英語の評価リストでは、英語の MMLU リストでは、Colossal-LLaMA-2-7B-base が低コストの増分事前トレーニングのサポートにより壊滅的な忘却の問題を克服していることがわかります。 44.47 -> 53.06)と、7Bスケールモデルの中でも優れた性能を誇ります。
中国語のリストでは、CMMLU、AGI、GAOKAO、および C- が主に比較されており、その効果は LLaMA-2 に基づく他の中国語ローカリゼーション モデルをはるかに上回っています。中国語コーパスを使用し、ゼロから事前トレーニングするには数千万ドルかかる可能性がある他のよく知られたモデルと比較しても、Colossal-LLaMA-2 は同じスケールで依然として優れたパフォーマンスを発揮します。特にオリジナルの LLaMA-2 と比較して、中国語能力の質的飛躍が見られました (CMMLU: 32.97 -> 49.89)。
ただし、SFT、LoRA、その他の方法による微調整を通じて、ベース モデルに効果的に注入できる知識と能力は非常に限られており、高品質のドメイン知識や垂直モデル アプリケーションを構築するニーズを十分に満たすことはできません。
モデルのパフォーマンスをより適切に評価するために、Colossal-AI チームは定量的な指標に依存するだけでなく、モデルのさまざまな側面を手動で評価します。いくつかの例を次に示します。
語彙の拡張とモデルの初期化
LLaMA-2 の元の語彙リストは特に中国語用に最適化されておらず、含まれる中国語単語が限られているため、中国語コーパスの理解が不十分になります。そこで、まず LLaMA-2 の語彙を拡張しました。
Colossal-AI チームは次のことを発見しました。
したがって、実験を繰り返し、トレーニングの質と効率を考慮した結果、Colossal-AI チームは最終的に語彙を LLaMA-2 の元の 32,000 から 69,104 に拡張することを決定しました。
語彙が拡張されたので、次のステップは、元の LLaMA-2 に基づいて新しい語彙の埋め込みを初期化することです。 LLaMA-2 の元の機能をより適切に移行し、元の LLaMA-2 から中国の LLaMA-2 機能への迅速な移行を実現するために、Colossal-AI チームは元の LLaMA-2 の重みを使用して新しい埋め込みを平均しました。初期化。これにより、新しく初期化されたモデルの英語能力が初期状態に影響を受けないことが保証されるだけでなく、英語能力を可能な限りシームレスに中国語に移行することもできます。
データ構築
トレーニングのコストを大幅に削減するには、高品質のデータが重要な役割を果たします。特に、データの品質と配布に対して非常に高い要件が求められる増分事前トレーニングの場合です。高品質のデータをより適切にスクリーニングするために、Colossal-AI チームは、増分事前トレーニング用に高品質のデータをスクリーニングするための完全なデータ クリーニング システムとツールキットを構築しました。
次の図は、Colossal-AI チームのデータ ガバナンスの完全なプロセスを示しています。
最後に、トレーニングの効率を向上させるために、Colossal-AI チームは、同じ被験者のデータについて、データの長さをソートし、最大長 4096 に従って結合しました。
トレーニング戦略
多段階トレーニング
トレーニングに関しては、増分事前トレーニングの特性を考慮して、Colossal-AI チームは多段階の階層的な増分事前トレーニング プランを設計し、トレーニング プロセスを 3 つの段階に分割しました。
複数の段階は相互に補完し、最終的には中国語と英語でのモデルの機能が連携して機能することを保証します。
バケットトレーニング
増分事前トレーニングはデータの分散に非常に敏感であり、バランスが特に重要です。したがって、データのバランスの取れた分散を確保するために、Colossal-AI チームは、同じ種類のデータを 10 の異なるビンに分割するデータ バケット化戦略を設計しました。トレーニング プロセス中、各データ バケットには各タイプのデータのビンが均等に含まれるため、モデルで各タイプのデータを均等に利用できるようになります。
評価制度
モデルのパフォーマンスをより適切に評価するために、Colossal-AI チームは完全な評価システム Colossal を構築し、大規模な言語モデルを複数の次元で評価したいと考えています。プロセス フレームワーク コードは完全にオープン ソースであり、結果の再現をサポートするだけでなく、ユーザーがさまざまなアプリケーション シナリオに応じてデータ セットと評価方法をカスタマイズすることもサポートします。評価フレームワークの特徴は次のように要約されます。
一般的な大型モデルから垂直型大型モデルへの移行のためのブリッジを構築します
Colossal-AI チームの経験から判断すると、LLaMA-2 に基づく中国語版モデルの構築は、基本的に次のプロセスに分けることができます。
答えは「はい」であり、ビジネス実装シナリオにおいて非常に意味があります。
ChatGPT によって引き起こされた人工知能の波により、世界中の大手インターネット巨人、AI 企業、新興企業、大学、研究機関が一般的な大型モデルの軌道で競い合っています。しかし、一般的な大規模モデルの一般的な機能の背後には、特定の分野の知識が不足していることが多く、実際の実装では、大規模モデルの錯覚の問題が特に深刻になります。ビジネスを微調整することで一定の利益を得ることができますが、大規模な垂直モデルが不足しているため、アプリケーション実装におけるパフォーマンスのボトルネックが発生します。大きなバーティカルモデルを短期間かつ低コストで構築し、その大きなバーティカルモデルに基づいてビジネスを微調整することができれば、ビジネスの実行をさらに前進させ、チャンスとメリットを確実に掴むことができるでしょう。
上記のプロセスをあらゆる分野の知識の伝達に適用することで、あらゆる分野で大規模な垂直ベース モデルを低コストで構築するための軽量プロセスを構築できます。
システムの最適化
Colossal-LLaMA-2の上記の優れた性能とコストメリットは、低コストAI大型モデル開発システムColossal-AIの上に構築されています。
Colossal-AI は PyTorch に基づいており、AI の大規模モデルのトレーニング/微調整/推論の開発およびアプリケーションのコストを削減し、モデルのタスクのパフォーマンスを向上させ、効率的な多次元並列処理、異種メモリなどを通じて GPU 要件を削減できます。わずか 1 年余りで、GitHub オープンソース コミュニティで 30,000 を超える GitHub スターを獲得し、大規模モデル開発ツールとコミュニティのセグメンテーションで世界第 1 位にランクされ、世界のトップ企業を含む多くの有名メーカーと共同開発されています。 500 社/1,000 億/100 億のパラメーターを最適化して、大規模なモデルを事前トレーニングしたり、垂直モデルを作成したりします。
Colossal-AI クラウド プラットフォーム
AI の大規模モデルの開発とデプロイメントの効率をさらに向上させるために、Colossal-AI は Colossal-AI クラウド プラットフォームにさらにアップグレードされました。これにより、ユーザーはクラウド上で大規模なモデルを低コストでトレーニング、微調整、デプロイできるようになります。コード/ノーコード方式を低コストで迅速に統合し、さまざまなモデルをパーソナライズされたアプリケーションに統合します。
参考リンク: