出典: ハート・オブ・ザ・マシンモデルのサイズが大きくなるにつれて、人々は大きなモデルが大量の知識をどのように習得できるかを探求し始めます。 1 つの見方では、これは「可逆圧縮」によるものであると考えられています。つまり、モデルは大規模なトレーニングを受け、予測精度を向上させるためにより多くのコンテンツを記憶します。しかし、「可逆圧縮」によって本当に大規模なモデルがこの知識を理解できるようになるのでしょうか? **Zhu Zeyuan (MetaAI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.1: 知識の保存と検索」では、この問題を詳しく調査しています**。 用紙のアドレス:人間に関しては、「本を100回読めば、その意味はおのずと現れる」という言葉があります。この文章はすべての知識に当てはまるわけではありませんが、簡単な知識であれば、該当する書籍を覚えていれば、関連する質問には簡単に答えることができます。たとえば、古代の詩「きよしこの夜の思い」を覚えている限り、「詩の中で月の光は何に例えられますか?」という質問には簡単に答えることができますし、「朱子彪/創作背景」に関する文章を覚えている限り、簡単に答えることができます。百度百科事典では、「朱子彪はいつ作られたのですか?」と簡単に答えることができます。では、より大きなモデルでも同じことができるのでしょうか? *図 1: GPT-4 による知識抽出の例 (左図は ChatGPT、右図は API)*GPT-4 は質問に関連する段落を理解して繰り返すことができますが、なぜ人間のように単純な質問に答えることができないのでしょうか?モデルの大きさが足りないのか、メモリが足りないのか、それともトレーニング後の微調整が足りないのか。どちらでもない!この記事は、自然言語モデルが十分に大きく、十分な期間トレーニングされ、十分に微調整されたとしても、人間が単純だと考える質問には答えられない可能性があると指摘しています。この根本的な理由は、事前学習データで知識が表現される方法に関係しています。同じ知識がトレーニング前のデータセットに複数回出現する必要があり、微調整後に抽出しやすいように十分な「**多様性**」が必要です。これを確認するために、2 人の著者は 10 万件の伝記を含むデータセットを作成しました。各キャラクターには、その人の名前と 6 つの固定属性 (生年月日、出生地、大学の専攻、大学名、勤務地、雇用主) を含む伝記エントリがあります。 BioS と BioR の 2 つのデータセットを設計し、BioS の各文は 50 個の固定テンプレートから選択され、BioR はより現実的かつ多様になるように LLaMA-30B で書き直されました。 2 つのデータ セットの結果は一貫しています。BioS を例として、サンプル エントリを以下に示します。> アニヤ ブライアー フォージャーは 1996 年 10 月 2 日に生まれました。彼女は幼少期をニュージャージー州プリンストンで過ごしました。彼女は MIT の教員から指導と指導を受けました。彼女はコミュニケーションに重点を置いて教育を修了しました。彼女はメタ プラットフォームで専門的な役割を担っていました。彼女はカリフォルニア州メンローパークで雇用されていました。 *図 2*たとえ自然言語モデルが 10 万件の個人の自伝で完全に事前トレーニング (事前トレーニング) されたとしても、QA の微調整 (ファインチューニング) によって「アーニャはどこの学校に学部に通ったのか」という質問に正確に答えることはできません。図 2 に示すように、50,000 人を QA 微調整トレーニング データとして使用し、LoRA を含むさまざまな微調整方法を試したとしても、残りの 50,000 人に対するモデルの精度はわずか 10% です。 682M モデル (人数の 7000 倍) を使用して 1350 回トレーニングし、WikiBook などの標準的な NLP 事前トレーニング データを追加したにもかかわらず、正解率は向上しませんでした。 「大きな力で奇跡が起きた」わけではないことが分かります。したがって、大規模なモデルは必ずしも「可逆圧縮」の知識を取得または抽出できるわけではありません。では、GPT-4 はどのようにして知識を習得するのでしょうか?この問題を研究するために、2 人の著者は事前トレーニング セットに変更を加えました。著者はそれを **知識強化** と呼びました。1. 多様性 - マルチM: 異なる物語言語を使用しながら、同じ情報を保持しながら、人物ごとに M 個の伝記エントリを作成します (各文には合計 100 の物語方法があり、各伝記の各文はそれらから 1 つを選択します)2. ランダム配置 - 並べ替え:伝記文をランダムに配置します3. フルネーム - fullname: 伝記内のすべての代名詞、姓、名をフルネームに置き換えます。著者らは元のデータセットを bioS シングルと呼び、知識強化の 15 の組み合わせを実験しました。たとえば、bioS multi5+permute は、各人に 5 つの伝記があることを意味し、語順が崩れます。以下は bioS multi5+permute の例です。> アニヤ・ブライア・フォージャーはニュージャージー州プリンストン出身。彼女はコミュニケーションの勉強に専念しました。彼女はカリフォルニア州メンローパークで実務経験を積みました。彼女はメタ プラットフォームでキャリアを築きました。彼女は 1996 年 10 月 2 日にこの世に生まれました。彼女は MIT で上級コースを履修しました。人間と大規模モデルの両方の場合、bioS single と bioS multi5+permute はほぼ同じ難易度であることに注意してください (情報量は同じで、各文は 50 のテンプレートから選択されます)。では、この新しい知識が強化されたデータセットに対して事前トレーニングが実行され、その後 QA が微調整された場合、新たなパフォーマンスは得られるでしょうか?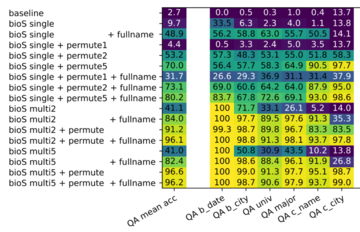 *画像3*図 3 は、bioS 単一事前トレーニング モデルの QA 精度率がわずか 9.7% であるのに対し、bioS multi5+permute 事前トレーニング モデルの精度率は 96.6% も高いことを示しています。この大幅な改善は、モデルの微調整、サイズ、トレーニング時間とは関係なく、事前トレーニングでの知識の提示方法、つまり、大規模なモデルによって知識がどのように「暗唱」されるかに関係しています。この研究ではまた、伝記を有名人と少数派グループに分けることにより、有名人の伝記に知識強化がある限り、たとえ少数派グループに知識強化がなくても、少数派グループに対するモデルの知識抽出の精度が大幅に向上することもわかりました。 、最高の効果を得るには、依然としてすべてのデータの知識の強化が必要です。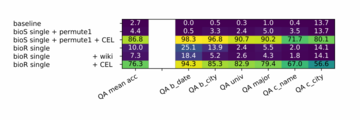 *図 4: 著名人の学習データの多様性を高めるだけで、少数派グループの知識抽出の精度が向上します*では、なぜモデルの質問応答能力は、異なるデータを暗唱した後に大きく変化するのでしょうか?なぜ有名人の伝記を繰り返し暗唱すると、少数派の知識抽出能力が高まるのでしょうか?その理由は、モデルによって採用されているメモリ方式が異なるためです。著者は、2 つの線形探索を通じてモデルの記憶知識の原理を深く調査します。 P プロービングと呼ばれる 1 つの方法を見てみましょう。P プローブでは、事前トレーニングされたモデルに経歴エントリを入力し、6 つのターゲット属性 (大学、専攻など) を予測するために線形分類器をトレーニングします。私たちは、モデルが属性よりも早くこの情報を抽出できるかどうかを確認したいと考えました。分類器が人物名の直後の「作業単位」に対して高い精度を示した場合、モデルが「アーニャの雇用主がメタである」ことを直接学習したことを意味します。伝記の最後でのみ高い精度が達成される場合は、「ある人の誕生日は 1996 年 10 月 2 日、大学は MIT、したがって雇用主は Meta」など、モデルが欠陥のある記憶方法を使用している可能性があります。P プローブの実験計画は次のとおりです。各伝記内で 6 つの属性が最初に出現する位置を見つけて、これらの位置の直前の位置で各ターゲット属性を予測するように線形分類器をトレーニングします。その結果、36 の分類タスクが作成されました。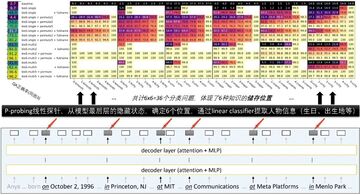 *図 5: P プローブ テストの結果は、事前トレーニング データ セットの知識強化により、知識が以前の場所に保存され、一部は人の名前に直接保存されることさえあることを示しています。モデルが微調整を通じて質問に答えることができるかどうかは、事前トレーニング中に情報が個人の名前に直接保存されるかどうかに関係します (図 3 と図 5 を比較)。 *P プローブ テストの結果は、自然言語モデルが事前トレーニング中に圧縮を達成するために人の名前を通じて情報を記憶できること、また他の情報 (「MIT で勉強した人の作業単位」など) も使用できることを示しています。誕生日は1996年10月2日です...」)記憶。 2 番目の記憶方法は人間にとっては「不自然」ですが、モデルでは 2 つの方法の圧縮率は同じです。モデルが情報を記憶するために 2 番目の方法を使用する場合、トレーニング後の微調整を通じて質問に答えることができなくなります。知識の強化を通じて、事前トレーニングされたモデルは徐々に最初の記憶方法の使用を学習する傾向があります。上記の「知識抽出」の失敗は、GPT などの自己回帰言語モデルの一方向の性質が原因である可能性があると主張する人もいるかもしれません。実際、BERT などの双方向言語モデルは知識抽出がさらに苦手で、「メタ プラットフォーム」などの複数フレーズの知識を保存することしかできませんが、抽出することはできません。興味のある読者は、この論文の第 6 章を参照してください。一般に、言語モデルが「知識抽出」の質問に答えることができるかどうかは、「可逆圧縮」だけでなく「モデル内での圧縮方法」にも依存します。この論文では、事前トレーニング プロセス (複数回の書き換えに ChatGPT を使用するなど) 中に、重要だがまれなデータに関する知識を強化する必要があると強調しています。このステップを行わないと、微調整にどれほど熱心に取り組んでも、事前トレーニングされたモデルがトレーニング データを可逆圧縮していても、その知識を抽出できない可能性があります。## **結論**自然言語モデルがどのように機能するかを理解するにはどうすればよいでしょうか?ほとんどの研究者は、GPT-4 などのモデルと対話することでその機能を推測しています。しかし、「言語モデルの物理学」シリーズの論文の著者は、慎重に設計されたトレーニング データと制御された実験を通じて、Transformer の内部メカニズムを調査し、AI タスクを処理する能力を説明する、より正確な方法を提案しました。「パート 3.1: 知識の保存と抽出」では、著者はさまざまなデータに対するモデルの応答を正確にテストし、モデルの学習知識と能力とトレーニング データの間の正確な関係を発見しました。彼らはまた、モデルが特定の状況で知識をどのように運用するかをさらに研究するために、「パート 3.2: 知識の運用」をリリースしました。たとえば、大きなモデルが「静かな夜の思い」を覚えている場合、「静かな夜の思い」の最後の文が「頭を下げて故郷を懐かしむ」であると推測できるように微調整することはできますか?近々続報をお届けします。
暗唱することは、大規模なモデルの背後にある知識の保存と抽出を理解し、詳細に分析することを意味するものではありません
出典: ハート・オブ・ザ・マシン
モデルのサイズが大きくなるにつれて、人々は大きなモデルが大量の知識をどのように習得できるかを探求し始めます。 1 つの見方では、これは「可逆圧縮」によるものであると考えられています。つまり、モデルは大規模なトレーニングを受け、予測精度を向上させるためにより多くのコンテンツを記憶します。しかし、「可逆圧縮」によって本当に大規模なモデルがこの知識を理解できるようになるのでしょうか? Zhu Zeyuan (MetaAI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.1: 知識の保存と検索」では、この問題を詳しく調査しています。
人間に関しては、「本を100回読めば、その意味はおのずと現れる」という言葉があります。この文章はすべての知識に当てはまるわけではありませんが、簡単な知識であれば、該当する書籍を覚えていれば、関連する質問には簡単に答えることができます。たとえば、古代の詩「きよしこの夜の思い」を覚えている限り、「詩の中で月の光は何に例えられますか?」という質問には簡単に答えることができますし、「朱子彪/創作背景」に関する文章を覚えている限り、簡単に答えることができます。百度百科事典では、「朱子彪はいつ作られたのですか?」と簡単に答えることができます。では、より大きなモデルでも同じことができるのでしょうか?
GPT-4 は質問に関連する段落を理解して繰り返すことができますが、なぜ人間のように単純な質問に答えることができないのでしょうか?モデルの大きさが足りないのか、メモリが足りないのか、それともトレーニング後の微調整が足りないのか。どちらでもない!この記事は、自然言語モデルが十分に大きく、十分な期間トレーニングされ、十分に微調整されたとしても、人間が単純だと考える質問には答えられない可能性があると指摘しています。この根本的な理由は、事前学習データで知識が表現される方法に関係しています。同じ知識がトレーニング前のデータセットに複数回出現する必要があり、微調整後に抽出しやすいように十分な「多様性」が必要です。
これを確認するために、2 人の著者は 10 万件の伝記を含むデータセットを作成しました。各キャラクターには、その人の名前と 6 つの固定属性 (生年月日、出生地、大学の専攻、大学名、勤務地、雇用主) を含む伝記エントリがあります。 BioS と BioR の 2 つのデータセットを設計し、BioS の各文は 50 個の固定テンプレートから選択され、BioR はより現実的かつ多様になるように LLaMA-30B で書き直されました。 2 つのデータ セットの結果は一貫しています。BioS を例として、サンプル エントリを以下に示します。
たとえ自然言語モデルが 10 万件の個人の自伝で完全に事前トレーニング (事前トレーニング) されたとしても、QA の微調整 (ファインチューニング) によって「アーニャはどこの学校に学部に通ったのか」という質問に正確に答えることはできません。図 2 に示すように、50,000 人を QA 微調整トレーニング データとして使用し、LoRA を含むさまざまな微調整方法を試したとしても、残りの 50,000 人に対するモデルの精度はわずか 10% です。 682M モデル (人数の 7000 倍) を使用して 1350 回トレーニングし、WikiBook などの標準的な NLP 事前トレーニング データを追加したにもかかわらず、正解率は向上しませんでした。 「大きな力で奇跡が起きた」わけではないことが分かります。
したがって、大規模なモデルは必ずしも「可逆圧縮」の知識を取得または抽出できるわけではありません。では、GPT-4 はどのようにして知識を習得するのでしょうか?この問題を研究するために、2 人の著者は事前トレーニング セットに変更を加えました。著者はそれを 知識強化 と呼びました。
多様性 - マルチM: 異なる物語言語を使用しながら、同じ情報を保持しながら、人物ごとに M 個の伝記エントリを作成します (各文には合計 100 の物語方法があり、各伝記の各文はそれらから 1 つを選択します)
ランダム配置 - 並べ替え:伝記文をランダムに配置します
フルネーム - fullname: 伝記内のすべての代名詞、姓、名をフルネームに置き換えます。
著者らは元のデータセットを bioS シングルと呼び、知識強化の 15 の組み合わせを実験しました。たとえば、bioS multi5+permute は、各人に 5 つの伝記があることを意味し、語順が崩れます。以下は bioS multi5+permute の例です。
人間と大規模モデルの両方の場合、bioS single と bioS multi5+permute はほぼ同じ難易度であることに注意してください (情報量は同じで、各文は 50 のテンプレートから選択されます)。では、この新しい知識が強化されたデータセットに対して事前トレーニングが実行され、その後 QA が微調整された場合、新たなパフォーマンスは得られるでしょうか?
図 3 は、bioS 単一事前トレーニング モデルの QA 精度率がわずか 9.7% であるのに対し、bioS multi5+permute 事前トレーニング モデルの精度率は 96.6% も高いことを示しています。この大幅な改善は、モデルの微調整、サイズ、トレーニング時間とは関係なく、事前トレーニングでの知識の提示方法、つまり、大規模なモデルによって知識がどのように「暗唱」されるかに関係しています。
この研究ではまた、伝記を有名人と少数派グループに分けることにより、有名人の伝記に知識強化がある限り、たとえ少数派グループに知識強化がなくても、少数派グループに対するモデルの知識抽出の精度が大幅に向上することもわかりました。 、最高の効果を得るには、依然としてすべてのデータの知識の強化が必要です。
では、なぜモデルの質問応答能力は、異なるデータを暗唱した後に大きく変化するのでしょうか?なぜ有名人の伝記を繰り返し暗唱すると、少数派の知識抽出能力が高まるのでしょうか?その理由は、モデルによって採用されているメモリ方式が異なるためです。
著者は、2 つの線形探索を通じてモデルの記憶知識の原理を深く調査します。 P プロービングと呼ばれる 1 つの方法を見てみましょう。
P プローブでは、事前トレーニングされたモデルに経歴エントリを入力し、6 つのターゲット属性 (大学、専攻など) を予測するために線形分類器をトレーニングします。私たちは、モデルが属性よりも早くこの情報を抽出できるかどうかを確認したいと考えました。分類器が人物名の直後の「作業単位」に対して高い精度を示した場合、モデルが「アーニャの雇用主がメタである」ことを直接学習したことを意味します。伝記の最後でのみ高い精度が達成される場合は、「ある人の誕生日は 1996 年 10 月 2 日、大学は MIT、したがって雇用主は Meta」など、モデルが欠陥のある記憶方法を使用している可能性があります。
P プローブの実験計画は次のとおりです。各伝記内で 6 つの属性が最初に出現する位置を見つけて、これらの位置の直前の位置で各ターゲット属性を予測するように線形分類器をトレーニングします。その結果、36 の分類タスクが作成されました。
P プローブ テストの結果は、自然言語モデルが事前トレーニング中に圧縮を達成するために人の名前を通じて情報を記憶できること、また他の情報 (「MIT で勉強した人の作業単位」など) も使用できることを示しています。誕生日は1996年10月2日です...」)記憶。 2 番目の記憶方法は人間にとっては「不自然」ですが、モデルでは 2 つの方法の圧縮率は同じです。モデルが情報を記憶するために 2 番目の方法を使用する場合、トレーニング後の微調整を通じて質問に答えることができなくなります。知識の強化を通じて、事前トレーニングされたモデルは徐々に最初の記憶方法の使用を学習する傾向があります。
上記の「知識抽出」の失敗は、GPT などの自己回帰言語モデルの一方向の性質が原因である可能性があると主張する人もいるかもしれません。実際、BERT などの双方向言語モデルは知識抽出がさらに苦手で、「メタ プラットフォーム」などの複数フレーズの知識を保存することしかできませんが、抽出することはできません。興味のある読者は、この論文の第 6 章を参照してください。
一般に、言語モデルが「知識抽出」の質問に答えることができるかどうかは、「可逆圧縮」だけでなく「モデル内での圧縮方法」にも依存します。この論文では、事前トレーニング プロセス (複数回の書き換えに ChatGPT を使用するなど) 中に、重要だがまれなデータに関する知識を強化する必要があると強調しています。このステップを行わないと、微調整にどれほど熱心に取り組んでも、事前トレーニングされたモデルがトレーニング データを可逆圧縮していても、その知識を抽出できない可能性があります。
## 結論
自然言語モデルがどのように機能するかを理解するにはどうすればよいでしょうか?ほとんどの研究者は、GPT-4 などのモデルと対話することでその機能を推測しています。しかし、「言語モデルの物理学」シリーズの論文の著者は、慎重に設計されたトレーニング データと制御された実験を通じて、Transformer の内部メカニズムを調査し、AI タスクを処理する能力を説明する、より正確な方法を提案しました。
「パート 3.1: 知識の保存と抽出」では、著者はさまざまなデータに対するモデルの応答を正確にテストし、モデルの学習知識と能力とトレーニング データの間の正確な関係を発見しました。
彼らはまた、モデルが特定の状況で知識をどのように運用するかをさらに研究するために、「パート 3.2: 知識の運用」をリリースしました。たとえば、大きなモデルが「静かな夜の思い」を覚えている場合、「静かな夜の思い」の最後の文が「頭を下げて故郷を懐かしむ」であると推測できるように微調整することはできますか?近々続報をお届けします。