出典: 新志源 画像ソース: Unbounded AI によって生成ChatGPT のリリース後、テキスト生成技術は急速に発展し、多くの NLP タスク、特に標準的な回答が存在しない「テキスト要約」タスクが完全に克服されなければならないというジレンマに直面しています。しかし、「適切な量の情報」を要約に含める方法は依然として非常に困難です。優れた要約は、エンティティが密集して理解しにくいものではなく、詳細でエンティティを中心としたものである必要があります。情報量とわかりやすさのトレードオフをよりよく理解するために、MIT、コロンビア大学、その他の機関の研究者は、抽象的なテキストを追加せずに使用できる新しい「高密度の連鎖」プロンプトを提案しました。 GPT-4 によって生成されるエンティティがまばらな要約は繰り返し最適化され、欠落している重要なエンティティが徐々に追加されます。 論文リンク:オープンソースデータ:実験結果から判断すると、CoD によって生成されたサマリーは、通常のプロンプトによって生成された GPT-4 サマリーよりも抽象的であり、融合が多く、リード バイアスが少ないことがわかります。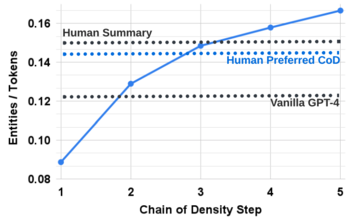 CNN DailyMail の 100 件の記事について人間の好みに関する調査を実施した結果、人間は、人間が書いた要約のエンティティ密度と同様に、エンティティがより高密度な要約結果を選択する傾向が高いことがわかりました。研究者らは、500 件の注釈付き CoD 抄録と 5,000 件の注釈なしの抄録データをオープンソース化しました。## **テキストの要約を繰り返し改善する****ヒント()**タスクの目標は、GPT-4 を使用して、テキストの長さを制御しながら、「さまざまなレベルの情報密度」を持つ一連の概要を生成することです。研究者らは、最初の概要を生成し、エンティティを徐々に密度を高めていくための Chain of Density (CoD、Chain of Density) ヒントを提案しました。具体的には、固定回数の反復ラウンドの下で、ソース テキスト内の一連の固有で顕著なエンティティが識別され、テキストの長さを増やすことなく前の概要にマージされます。 最初に生成された概要はエンティティが希薄で、最初の 1 ~ 3 個のエンティティのみに焦点を当てています。同じテキストの長さを維持しながらカバーされるエンティティの数を増やすには、抽象化、融合、および圧縮を明示的に推奨する必要があります。前回のまとめの内容。研究者らはエンティティの種類を特定しませんでしたが、単に「欠落エンティティ」を次のように定義しました。**関連性: **メインストーリーに関連します。**具体的:** 説明的だが簡潔 (5 単語以内)。**小説: **以前の要約には掲載されていません。**忠実: **原文に存在します。**どこでも:** は記事内のどこにでも使用できます。データの選択に関しては、研究者らは CNN/DailyMail の要約テスト セットからランダムに 100 件の記事を選択し、CoD の要約を生成しました。次に、CoD の概要統計を、人間が作成した箇条書き形式の参照概要と、通常のプロンプト (「記事の非常に短い概要を 70 ワード以内で書いてください」) の下で GPT-4 によって生成された概要と比較しました。 (記事の非常に短い要約を作成してください。70 ワードを超えないようにしてください)。予想されるトークン長は、CoD ダイジェストのトークン長と一致するように設定されます。**統計結果****直接的な統計指標**NLTK を使用してトークンの数をカウントし、Spatiy2 を使用して一意のエンティティの数を測定し、エンティティ密度比を計算します。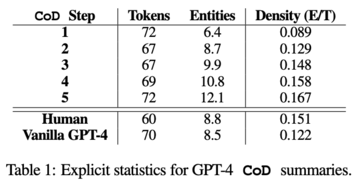 CoD ヒントは、概要を生成するために予想されるトークンの数を大幅に制限します。2 番目のステップから開始して、長い最初の概要から不要な単語が徐々に削除され、テキストの長さが平均 5 トークン ( 72〜67) 。エンティティ密度も増加しますが、最初は 0.089 で、これはヒトと GPT-4 の結果 (それぞれ 0.151 と 0.122) より低く、5 ステップ後に密度は 0.167 まで増加します。**間接的な統計指標**抽出密度 (抽出されたフラグメントの平均長の 2 乗) を使用してテキストの抽象度を測定すると、CoD の反復が進むにつれてテキストが増加することが予想されます。「原文と整列した要約文の数」を概念融合インデックスとして使用します。この場合、整列アルゴリズムは「相対 ROUGE ゲイン」を使用して、文を追加しても相対 ROUGE が増加しなくなるまで、ソース文をターゲット文と整列させます。核融合は徐々に増加すると予想されます。「原文中の要約内容の位置」を内容の分布(Content Distribution)指標として使用し、具体的な測定方法は、整列されたすべての原文の平均順位です。CoD 要約は、最初は明らかなリードバイアスを示すことが予想されます、そして記事の途中から徐々に動き始め、最後の部分でエンティティが紹介されます。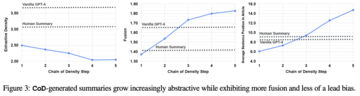 統計結果は、予期された結果の正確性も検証しました。つまり、リライトのプロセスに応じて抽象度が徐々に増加し、融合率が増加し、要約が記事の中間と最後に統合され始めました。また、すべての CoD 概要は、手書きの概要やベースライン モデルで生成された概要よりも抽象的です。## **実験結果**CoD 要約のトレードオフをより深く理解するために、私たちは好みに基づいた人間の研究と GPT-4 による評価に基づいた評価を実施しました。**人間の好みの評価**研究者らは、全体的な人間の質量評価に対する高密度化の影響を評価することに焦点を当てました。具体的には、100件の記事を入力すると、「5ステップ\*100=合計500件の要約」が得られます。要約結果は、原文の忠実度(Essence)、明瞭さ(Clarity)、要約に基づいて、4人のアノテーターにランダムに表示されます。正確さ、目的、簡潔さ、スタイルで評価されます。 投票結果から判断すると、CoD の 2 番目のステップが最も高い評価を得ており、先ほどの平均密度の実験結果と合わせると、人間はエンティティ密度が 15% 程度の要約テキストを選択する可能性が高いと大まかに推測できます。 GPT-4 で生成された概要 (エンティティ密度 0.122) よりも大幅に高かった。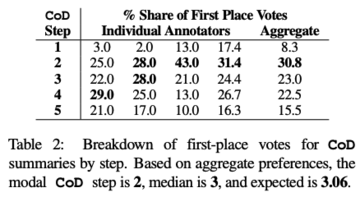 **自動評価指標**最近の研究では、GPT-4 の評価は人間の評価結果と非常に高い相関関係があり、一部のアノテーション タスクではクラウドソーシングの作業者よりも優れたパフォーマンスを発揮する可能性があることが実証されています。手動評価の補足として、研究者らは GPT-4 を使用して、有益 (Informative)、品質 (Quality)、一貫性 (Coherence)、帰属 (Attributable) および全体の 5 つの側面から CoD 概要 (1 ~ 5) を評価することを提案しました。使用されるコマンド テンプレートは次のとおりです。> 記事: 記事> 概要: 概要> ディメンションに関して概要を評価してください (1=最悪から 5=最高)。> 定義各インジケーターの定義は次のとおりです。**有益:** 有益な要約は、記事内の重要な情報を捉え、正確かつ簡潔に提示できます。 (有益な要約は、記事内の重要な情報を捉え、正確かつ簡潔に示します。)**品質:**質の高い要約は理解できます。 (質の高い要約は理解しやすくなります。)**一貫性:** 一貫した要約は、適切に構造化され、よく整理されています。 (一貫した要約は、適切に構造化され、よく整理されています。)**帰属:** 要約内のすべての情報は完全に記事に帰属しますか? (すべての情報は記事に完全に起因する要約?)**一般的な好み:** 優れた要約では、記事の要点を簡潔、論理的、一貫した方法で伝える必要があります。 (優れた要約は、記事の主要なアイデアを簡潔、論理的、一貫した方法で伝えるものでなければなりません。)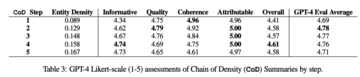 実験結果は、高密度化は情報コンテンツに関連しているが、スコアはステップ 4 (4.74) でピークに達します。品質と一貫性はより速く低下します。すべての要約はソース記事に起因すると考えられます。全体のスコアは、より高密度で情報量の多い要約ほど高くなる傾向があります。 、ステップ 4 のスコアが最高です。平均すると、最初と最後の CoD ステップは最も有利ではありませんが、中間の 3 つのステップはほぼ同じです (それぞれ 4.78、4.77、および 4.76)。**定性分析**反復プロセス中の要約の一貫性/可読性と有益性の間にはトレードオフがあります。 上の例は 2 つの CoD ステップを示しています。1 つはより詳細な内容を含み、もう 1 つはより大まかな内容を含みます。平均すると、中間ステップの CoD 要約はより良いバランスを実現しますが、このバランスを正確に定義して定量化する方法はまだ解明されていません。参考文献:
GPT-4 を使用してテキストの概要を直接抽出しないでください。 MIT、コロンビアなどが新しい「密度チェーン」リマインダーをリリース: 物理密度が抽象品質の鍵となる
出典: 新志源
ChatGPT のリリース後、テキスト生成技術は急速に発展し、多くの NLP タスク、特に標準的な回答が存在しない「テキスト要約」タスクが完全に克服されなければならないというジレンマに直面しています。
しかし、「適切な量の情報」を要約に含める方法は依然として非常に困難です。優れた要約は、エンティティが密集して理解しにくいものではなく、詳細でエンティティを中心としたものである必要があります。
情報量とわかりやすさのトレードオフをよりよく理解するために、MIT、コロンビア大学、その他の機関の研究者は、抽象的なテキストを追加せずに使用できる新しい「高密度の連鎖」プロンプトを提案しました。 GPT-4 によって生成されるエンティティがまばらな要約は繰り返し最適化され、欠落している重要なエンティティが徐々に追加されます。
オープンソースデータ:
実験結果から判断すると、CoD によって生成されたサマリーは、通常のプロンプトによって生成された GPT-4 サマリーよりも抽象的であり、融合が多く、リード バイアスが少ないことがわかります。
研究者らは、500 件の注釈付き CoD 抄録と 5,000 件の注釈なしの抄録データをオープンソース化しました。
テキストの要約を繰り返し改善する
ヒント()
タスクの目標は、GPT-4 を使用して、テキストの長さを制御しながら、「さまざまなレベルの情報密度」を持つ一連の概要を生成することです。
研究者らは、最初の概要を生成し、エンティティを徐々に密度を高めていくための Chain of Density (CoD、Chain of Density) ヒントを提案しました。
具体的には、固定回数の反復ラウンドの下で、ソース テキスト内の一連の固有で顕著なエンティティが識別され、テキストの長さを増やすことなく前の概要にマージされます。
研究者らはエンティティの種類を特定しませんでしたが、単に「欠落エンティティ」を次のように定義しました。
**関連性: **メインストーリーに関連します。
具体的: 説明的だが簡潔 (5 単語以内)。
**小説: **以前の要約には掲載されていません。
**忠実: **原文に存在します。
どこでも: は記事内のどこにでも使用できます。
データの選択に関しては、研究者らは CNN/DailyMail の要約テスト セットからランダムに 100 件の記事を選択し、CoD の要約を生成しました。
次に、CoD の概要統計を、人間が作成した箇条書き形式の参照概要と、通常のプロンプト (「記事の非常に短い概要を 70 ワード以内で書いてください」) の下で GPT-4 によって生成された概要と比較しました。 (記事の非常に短い要約を作成してください。70 ワードを超えないようにしてください)。
予想されるトークン長は、CoD ダイジェストのトークン長と一致するように設定されます。
統計結果
直接的な統計指標
NLTK を使用してトークンの数をカウントし、Spatiy2 を使用して一意のエンティティの数を測定し、エンティティ密度比を計算します。
エンティティ密度も増加しますが、最初は 0.089 で、これはヒトと GPT-4 の結果 (それぞれ 0.151 と 0.122) より低く、5 ステップ後に密度は 0.167 まで増加します。
間接的な統計指標
抽出密度 (抽出されたフラグメントの平均長の 2 乗) を使用してテキストの抽象度を測定すると、CoD の反復が進むにつれてテキストが増加することが予想されます。
「原文と整列した要約文の数」を概念融合インデックスとして使用します。この場合、整列アルゴリズムは「相対 ROUGE ゲイン」を使用して、文を追加しても相対 ROUGE が増加しなくなるまで、ソース文をターゲット文と整列させます。核融合は徐々に増加すると予想されます。
「原文中の要約内容の位置」を内容の分布(Content Distribution)指標として使用し、具体的な測定方法は、整列されたすべての原文の平均順位です。CoD 要約は、最初は明らかなリードバイアスを示すことが予想されます、そして記事の途中から徐々に動き始め、最後の部分でエンティティが紹介されます。
また、すべての CoD 概要は、手書きの概要やベースライン モデルで生成された概要よりも抽象的です。
## 実験結果
CoD 要約のトレードオフをより深く理解するために、私たちは好みに基づいた人間の研究と GPT-4 による評価に基づいた評価を実施しました。
人間の好みの評価
研究者らは、全体的な人間の質量評価に対する高密度化の影響を評価することに焦点を当てました。
具体的には、100件の記事を入力すると、「5ステップ*100=合計500件の要約」が得られます。要約結果は、原文の忠実度(Essence)、明瞭さ(Clarity)、要約に基づいて、4人のアノテーターにランダムに表示されます。正確さ、目的、簡潔さ、スタイルで評価されます。
最近の研究では、GPT-4 の評価は人間の評価結果と非常に高い相関関係があり、一部のアノテーション タスクではクラウドソーシングの作業者よりも優れたパフォーマンスを発揮する可能性があることが実証されています。
手動評価の補足として、研究者らは GPT-4 を使用して、有益 (Informative)、品質 (Quality)、一貫性 (Coherence)、帰属 (Attributable) および全体の 5 つの側面から CoD 概要 (1 ~ 5) を評価することを提案しました。
使用されるコマンド テンプレートは次のとおりです。
各インジケーターの定義は次のとおりです。
有益: 有益な要約は、記事内の重要な情報を捉え、正確かつ簡潔に提示できます。 (有益な要約は、記事内の重要な情報を捉え、正確かつ簡潔に示します。)
**品質:**質の高い要約は理解できます。 (質の高い要約は理解しやすくなります。)
一貫性: 一貫した要約は、適切に構造化され、よく整理されています。 (一貫した要約は、適切に構造化され、よく整理されています。)
帰属: 要約内のすべての情報は完全に記事に帰属しますか? (すべての情報は
記事に完全に起因する要約?)
一般的な好み: 優れた要約では、記事の要点を簡潔、論理的、一貫した方法で伝える必要があります。 (優れた要約は、記事の主要なアイデアを簡潔、論理的、一貫した方法で伝えるものでなければなりません。)
定性分析
反復プロセス中の要約の一貫性/可読性と有益性の間にはトレードオフがあります。
平均すると、中間ステップの CoD 要約はより良いバランスを実現しますが、このバランスを正確に定義して定量化する方法はまだ解明されていません。
参考文献: