出典: 量子ビットチューリング賞受賞者のYao Qizhi氏率いる最初の **大規模言語モデル** 論文が登場しました。スタート当初から目指していたのは、「大型モデルに人間と同じように考えさせる」という方向性でした——大規模なモデルは、段階的に推論する必要があるだけでなく、「段階的に」学習し、推論のプロセスにおけるすべての正しいプロセスを記憶する必要もあります。具体的には、この新しい論文は、大規模モデルが複雑な推論を実行する能力を大幅に向上させる、累積推論と呼ばれる新しい方法を提案しています。 大規模なモデルは思考連鎖などに基づいており、問題の推論に使用できますが、「数ターン」を必要とする問題に直面した場合、依然として間違いが発生しやすいことを知っておく必要があります。これに基づいて、累積推論はリアルタイムで善悪を判断するための「検証者」を追加します。このモデルの思考枠組みも、チェーンとツリーからより複雑な「有向非巡回グラフ」に変更されました。このようにして、大きなモデルは問題を解決するためのより明確なアイデアを持つだけでなく、「トランプ」のスキルも開発します。代数や幾何数論などの数学的問題では、大規模モデルの相対精度が **42%** 向上し、24 ポイントをプレイした場合の成功率は **98%** まで上昇しました。 清華大学相互情報研究所によると、共同筆頭著者のZhang Yifan氏はこの論文の出発点を次のように説明した。> カーネマンは、人間の認知処理には 2 つのシステムが含まれていると考えています。「システム 1」は速く、本能的で感情的であり、「システム 2」は遅く、思慮深く論理的です。> 現時点では大規模な言語モデルのパフォーマンスは「システム 1」に近く、それが複雑なタスクを扱うのが苦手な理由かもしれません。この観点から設計された累積推論は、**思考連鎖** (CoT) や **思考ツリー** (ToT) よりも優れています。では、この新しいアプローチは実際にはどのようなものなのでしょうか?一緒に見てみましょう。## **思考の連鎖とツリーの「ボトルネック」を突破する**累積推論の核心は、大規模モデルの思考プロセスの「形」を改善することにあります。具体的には、この方法では **3 つの大きな言語モデル**を使用します。* 提案者: 常に新しい提案を行います。つまり、現在の思考状況に基づいて次のステップが何であるかを提案します。※検証者:提案者の提案の正確性を検証し、正しければ思考の文脈に追加します。※記者:最終的な解が得られたかどうか、推論プロセスを終了するかどうかを判断します。推論プロセスでは、まず「提案者」が提案を行い、「検証者」が評価を担当し、「報告者」が答えを確定して思考プロセスを終了するかどうかを決定します。######** 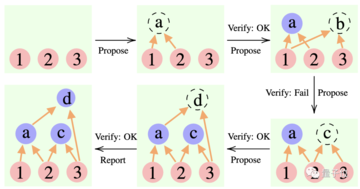 ****△**CR推論の例これは、チーム プロジェクトにおける 3 種類の役割に似ています。まず、チーム メンバーがさまざまなアイデアをブレインストーミングし、インストラクターがどのアイデアが実現可能かを「チェック」し、チーム リーダーがプロジェクトをいつ完了するかを決定します。 **それでは、このアプローチはビッグモデル思考の「形」を正確にどのように変えるのでしょうか? **これを理解するには、大規模モデルの思考強化手法の「元祖」である「思考の連鎖、CoT」から始める必要があります。この手法は、2022 年 1 月に OpenAI 科学者のジェイソン・ウェイ氏らによって提案されました。その核心は、大規模モデルの思考能力を刺激するために、データセットの入力に「ステップバイステップの推論」テキストを追加することです。######** 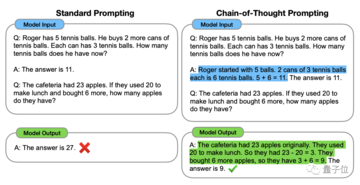 ****△**GSM8K データセットから選択Google は、思考連鎖の原則に基づいて、主に複数の思考連鎖プロセスを実行し、回答に対する多数決を行って最良のプロセスを選択する「思考連鎖 PLUS バージョン」、つまり **CoT-SC** をすぐにフォローしました。 . 最良の回答を選択すると、推論の精度がさらに向上します。しかし、Thinking Chain と CoT-SC はどちらも 1 つの問題を無視しています。それは、特に人間が問題を解決する場合、問題に対する解決策は複数あるということです。そこで、**Tree of Thought** (ToT) と呼ばれる新しい研究がその後登場しました。これは、モデルがさまざまな推論のアイデアを試し、自己評価し、次の行動方針を選択し、必要に応じて後戻りできるようにするツリー状の検索スキームです。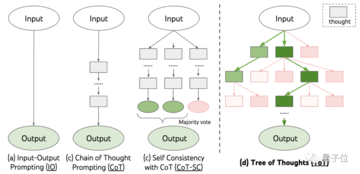 この方法から、思考ツリーが思考チェーンよりもさらに先に進み、大きなモデルの思考が「よりアクティブ」になることがわかります。24 ポイントをプレイした場合、思考連鎖ボーナスの GPT-4 成功率はわずか 4%** ですが、思考ツリーの成功率は **74%** まで上昇するのはこのためです。しかし、思考チェーン、CoT-SC、思考ツリーに関係なく、共通の制限があります。> それらのどれも、思考プロセスの**中間結果**の保管場所を設定していません。結局のところ、すべての思考プロセスをチェーンやツリーにできるわけではなく、人間の物事の考え方はより複雑であることがよくあります。この新しい累積推論フレームワークは、設計におけるこの点を突破します—大規模モデルの全体的な思考プロセスは必ずしもチェーンやツリーである必要はなく、**有向非巡回グラフ (DAG)** である場合もあります。 (うーん、シナプスの匂いがする)######** 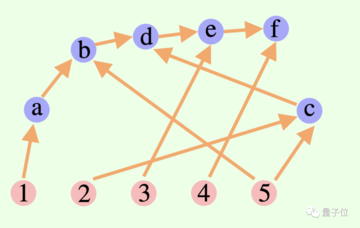 ****△**グラフ内のエッジには方向がありますが、円形のパスはありません。各有向エッジは導出ステップですこれは、現在の検索ブランチでの探索のために、歴史的に正しい推論結果をすべてメモリに保存できることを意味します。 (対照的に、思考ツリーは他の枝からの情報を保存しません)ただし、累積推論は思考チェーンとシームレスに切り替えることもできます。「検証者」が削除されている限り、これは標準的な思考チェーン モデルです。この方法に基づいて設計された累積推論は、さまざまな方法で良好な結果を達成しています。## **数学と論理的推論が得意**研究者らは、累積推論を「テスト」するために、FOLIO wiki と AutoTNLI、24 ポイント ゲーム、および MATH データ セットを選択しました。提案者、検証者、報告者は、それぞれの実験で同じ大規模な言語モデルを、それぞれの役割に異なる設定で使用します。ここで実験に使用した基本モデルには、GPT-3.5-turbo、GPT-4、LLaMA-13B、LLaMA-65B が含まれます。理想的には、モデルは関連する導出タスク データを使用して特別に事前トレーニングされる必要があり、「検証者」には形式的な数学的証明者、命題論理ソルバー モジュールなども追加する必要があることに言及する価値があります。### **1. 論理的推論能力**FOLIO は **1 次** 論理推論データ セットであり、質問のラベルは「真」、「偽」、「不明」にすることができます。AutoTNLI は **高次** 論理推論データ セットです。FOLIO wiki データセットでは、直接出力結果 (Direct)、思考連鎖 (CoT)、および高度な思考連鎖 (CoT-SC) メソッドと比較して、累積推論 (CR) のパフォーマンスが常に最高です。データセットから問題のあるインスタンス (不正解など) を削除した後、CR メソッドを使用した GPT-4 推論精度は 98.04% に達し、最小誤り率は 1.96% でした。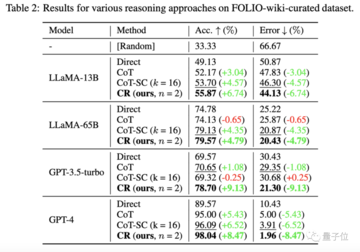 AutoTNLI データセットのパフォーマンスを見てみましょう。CoT 法と比較して、CR は LLaMA-13B および LLaMA-65B のパフォーマンスを大幅に向上させました。LLaMA-65B モデルでは、CoT と比較した CR の改善は 9.3% に達しました。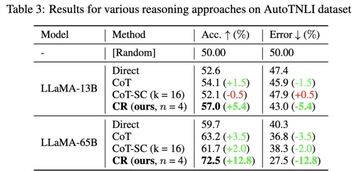 ### **2. 24 ポイント ゲームをプレイする能力**元の ToT 論文では 24 ポイント ゲームが使用されていたため、研究者たちはこのデータセットを使用して CR と ToT を比較しました。ToT は固定の幅と深さの検索ツリーを使用し、CR を使用すると、大規模なモデルが自律的に検索の深さを決定できます。研究者らは実験で、24 点のコンテキストにおいて CR アルゴリズムと ToT アルゴリズムが非常に似ていることを発見しました。違いは、CR のアルゴリズムは反復ごとに最大 1 つの新しい状態を生成するのに対し、ToT は反復ごとに多くの候補状態を生成し、状態の一部をフィルターして保持することです。平たく言えば、ToT には CR のような前述の「検証者」が存在せず、状態 (a、b、c) が正しいか間違っているかを判断することができないため、ToT は CR よりも多くの無効な状態を探索することになります。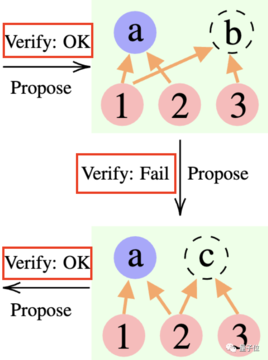 最終的に、CR メソッドの精度は 98% (ToT は 74%) に達することもあり、アクセスされる状態の平均数は ToT よりもはるかに少なくなります。つまり、CR は検索正解率が高いだけでなく、検索効率も高いのです。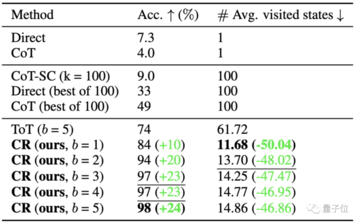 ### **3. 数学的能力**MATH データセットには、代数、幾何学、数論などを含む多数の数学的推論の問題が含まれています。問題の難易度は 5 つのレベルに分かれています。CR メソッドを使用すると、モデルは質問を段階的に完了できるサブ質問に分解し、回答が生成されるまで質問と回答を繰り返すことができます。実験結果は、2 つの異なる実験設定の下で、CR の精度が現在の既存の方法を上回り、全体の精度が最大 58% に達し、レベル 5 の問題で相対精度が 42% 向上したことを示しています。 GPT-4モデルの下で。## **清華大学のYao Qizhi氏とYuan Yang氏が主導した研究**この論文は、清華学際情報研究所の Yao Qizhi 氏と Yuan Yang 氏が率いる AI for Math 研究グループによるものです。この論文の共同筆頭著者は、学際情報研究所の2021年度博士課程学生であるZhang YifanとYang Jingqinです。講師および共著者はYuan Yang助教授とYao Qizhi学術研究員です。**チャン・イーファン**Zhang Yifan は 2021 年に北京大学遠平学院を卒業し、現在は Yuan Yang 助教授に師事しており、主な研究方向は基本モデル (大規模言語モデル) の理論とアルゴリズム、自己教師あり学習、および信頼できる人工知能です。**ヤン・ジンチン**Yang Jingqin 氏は、2021 年に清華大学相互情報研究所で学士号を取得し、現在、Yuan Yang 助教授の下で博士号取得に向けて勉強しています。主な研究方向としては、大規模言語モデル、自己教師あり学習、インテリジェント医療などが挙げられます。**元ヤン** Yuan Yang は、清華大学学際情報学部の助教授です。 2012年に北京大学コンピュータサイエンス学部を卒業、2018年に米国コーネル大学でコンピュータサイエンスの博士号を取得、2018年から2019年までマサチューセッツ研究所ビッグデータサイエンス学部で博士研究員として勤務テクノロジーの。主な研究方向はインテリジェント医療、AI基礎理論、応用カテゴリー理論など。**姚其之** 姚其之氏は中国科学院の会員であり、清華大学学際情報研究所の所長であり、創設以来チューリング賞を受賞した初のアジア人学者であり、この栄誉を受賞した唯一の中国人コンピュータ科学者でもある。これまでのところ。姚其之教授は、2004 年に終身教授としてプリンストン大学を辞任し、清華に戻って教鞭を執り、2005 年には清華大学の学部生向けのコンピュータ サイエンス実験クラス「ヤオ クラス」を設立し、2011 年には「清華量子情報センター」を設立しました。 」と「学際情報研究所」、2019年に 2008年、清華大学の学部生向けに「スマートクラス」と呼ばれる人工知能クラスを設立した。現在、彼が率いる清華大学学際情報研究所は古くから有名であり、Yao ClassとZhibanは両方とも学際情報研究所に所属しています。Yao Qizhi 教授の研究対象には、アルゴリズム、暗号学、量子コンピューティングなどが含まれます。彼はこの分野の国際的な先駆者であり権威です。最近、彼は2023年世界人工知能会議に出席し、彼が率いる上海Qizhi研究所は現在「身体化された汎用人工知能」を研究している。論文リンク:
姚其之が率先して大きなモデル「思考」フレームワークを提案!論理的推論の精度は98%であり、考え方はより人間に近い。
出典: 量子ビット
チューリング賞受賞者のYao Qizhi氏率いる最初の 大規模言語モデル 論文が登場しました。
スタート当初から目指していたのは、「大型モデルに人間と同じように考えさせる」という方向性でした——
大規模なモデルは、段階的に推論する必要があるだけでなく、「段階的に」学習し、推論のプロセスにおけるすべての正しいプロセスを記憶する必要もあります。
具体的には、この新しい論文は、大規模モデルが複雑な推論を実行する能力を大幅に向上させる、累積推論と呼ばれる新しい方法を提案しています。
これに基づいて、累積推論はリアルタイムで善悪を判断するための「検証者」を追加します。このモデルの思考枠組みも、チェーンとツリーからより複雑な「有向非巡回グラフ」に変更されました。
このようにして、大きなモデルは問題を解決するためのより明確なアイデアを持つだけでなく、「トランプ」のスキルも開発します。
代数や幾何数論などの数学的問題では、大規模モデルの相対精度が 42% 向上し、24 ポイントをプレイした場合の成功率は 98% まで上昇しました。
この観点から設計された累積推論は、思考連鎖 (CoT) や 思考ツリー (ToT) よりも優れています。
では、この新しいアプローチは実際にはどのようなものなのでしょうか?一緒に見てみましょう。
思考の連鎖とツリーの「ボトルネック」を突破する
累積推論の核心は、大規模モデルの思考プロセスの「形」を改善することにあります。
具体的には、この方法では 3 つの大きな言語モデルを使用します。
推論プロセスでは、まず「提案者」が提案を行い、「検証者」が評価を担当し、「報告者」が答えを確定して思考プロセスを終了するかどうかを決定します。
**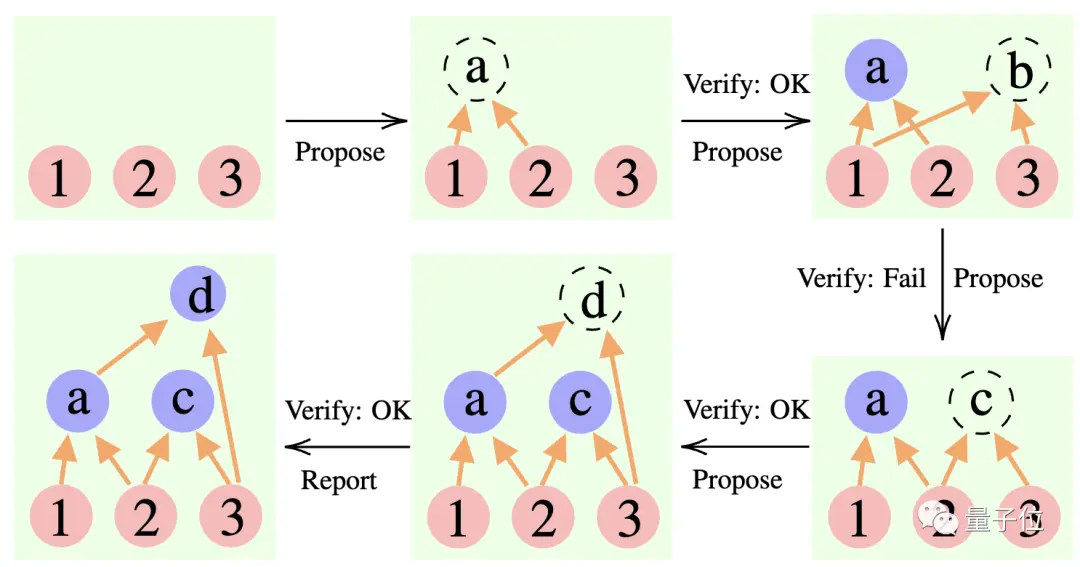 ****△**CR推論の例
****△**CR推論の例
これは、チーム プロジェクトにおける 3 種類の役割に似ています。まず、チーム メンバーがさまざまなアイデアをブレインストーミングし、インストラクターがどのアイデアが実現可能かを「チェック」し、チーム リーダーがプロジェクトをいつ完了するかを決定します。
これを理解するには、大規模モデルの思考強化手法の「元祖」である「思考の連鎖、CoT」から始める必要があります。
この手法は、2022 年 1 月に OpenAI 科学者のジェイソン・ウェイ氏らによって提案されました。その核心は、大規模モデルの思考能力を刺激するために、データセットの入力に「ステップバイステップの推論」テキストを追加することです。
**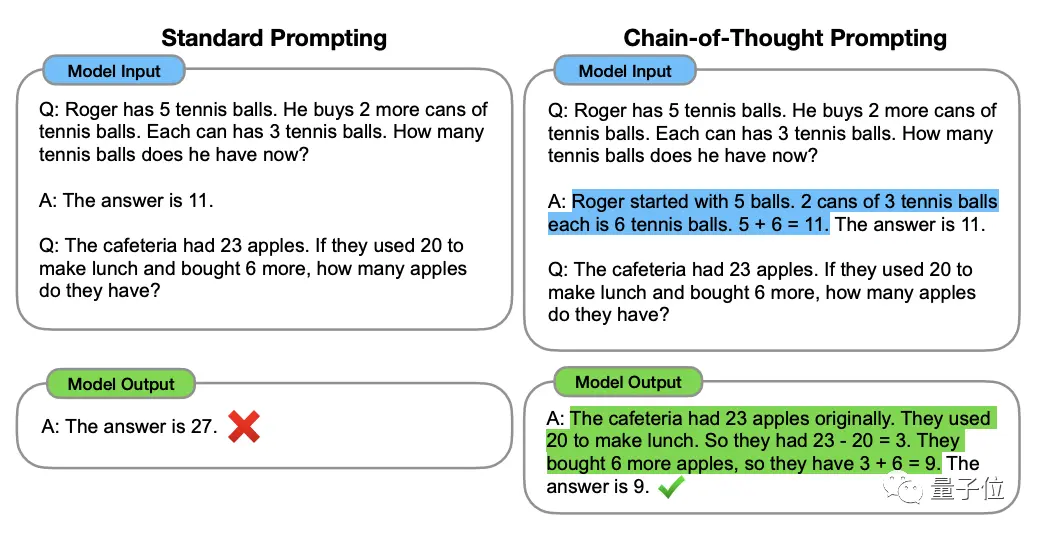 ****△**GSM8K データセットから選択
****△**GSM8K データセットから選択
Google は、思考連鎖の原則に基づいて、主に複数の思考連鎖プロセスを実行し、回答に対する多数決を行って最良のプロセスを選択する「思考連鎖 PLUS バージョン」、つまり CoT-SC をすぐにフォローしました。 . 最良の回答を選択すると、推論の精度がさらに向上します。
しかし、Thinking Chain と CoT-SC はどちらも 1 つの問題を無視しています。それは、特に人間が問題を解決する場合、問題に対する解決策は複数あるということです。
そこで、Tree of Thought (ToT) と呼ばれる新しい研究がその後登場しました。
これは、モデルがさまざまな推論のアイデアを試し、自己評価し、次の行動方針を選択し、必要に応じて後戻りできるようにするツリー状の検索スキームです。
24 ポイントをプレイした場合、思考連鎖ボーナスの GPT-4 成功率はわずか 4%** ですが、思考ツリーの成功率は 74% まで上昇するのはこのためです。
しかし、思考チェーン、CoT-SC、思考ツリーに関係なく、共通の制限があります。
結局のところ、すべての思考プロセスをチェーンやツリーにできるわけではなく、人間の物事の考え方はより複雑であることがよくあります。
この新しい累積推論フレームワークは、設計におけるこの点を突破します—
大規模モデルの全体的な思考プロセスは必ずしもチェーンやツリーである必要はなく、有向非巡回グラフ (DAG) である場合もあります。 (うーん、シナプスの匂いがする)
**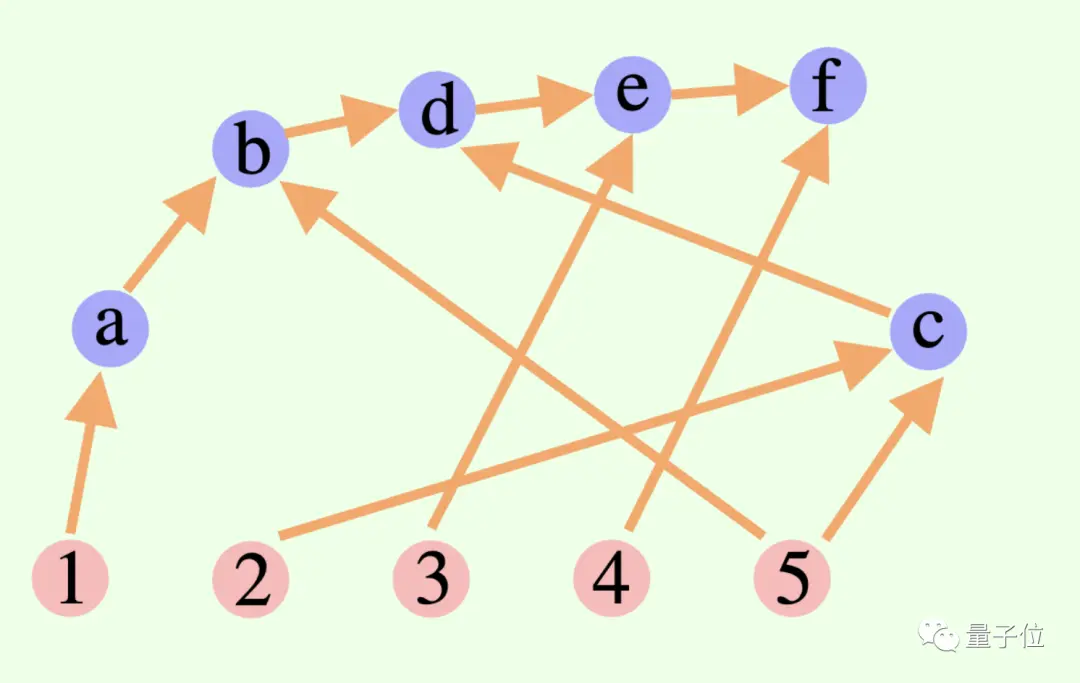 ****△**グラフ内のエッジには方向がありますが、円形のパスはありません。各有向エッジは導出ステップです
****△**グラフ内のエッジには方向がありますが、円形のパスはありません。各有向エッジは導出ステップです
これは、現在の検索ブランチでの探索のために、歴史的に正しい推論結果をすべてメモリに保存できることを意味します。 (対照的に、思考ツリーは他の枝からの情報を保存しません)
ただし、累積推論は思考チェーンとシームレスに切り替えることもできます。「検証者」が削除されている限り、これは標準的な思考チェーン モデルです。
この方法に基づいて設計された累積推論は、さまざまな方法で良好な結果を達成しています。
数学と論理的推論が得意
研究者らは、累積推論を「テスト」するために、FOLIO wiki と AutoTNLI、24 ポイント ゲーム、および MATH データ セットを選択しました。
提案者、検証者、報告者は、それぞれの実験で同じ大規模な言語モデルを、それぞれの役割に異なる設定で使用します。
ここで実験に使用した基本モデルには、GPT-3.5-turbo、GPT-4、LLaMA-13B、LLaMA-65B が含まれます。
理想的には、モデルは関連する導出タスク データを使用して特別に事前トレーニングされる必要があり、「検証者」には形式的な数学的証明者、命題論理ソルバー モジュールなども追加する必要があることに言及する価値があります。
1. 論理的推論能力
FOLIO は 1 次 論理推論データ セットであり、質問のラベルは「真」、「偽」、「不明」にすることができます。AutoTNLI は 高次 論理推論データ セットです。
FOLIO wiki データセットでは、直接出力結果 (Direct)、思考連鎖 (CoT)、および高度な思考連鎖 (CoT-SC) メソッドと比較して、累積推論 (CR) のパフォーマンスが常に最高です。
データセットから問題のあるインスタンス (不正解など) を削除した後、CR メソッドを使用した GPT-4 推論精度は 98.04% に達し、最小誤り率は 1.96% でした。
CoT 法と比較して、CR は LLaMA-13B および LLaMA-65B のパフォーマンスを大幅に向上させました。
LLaMA-65B モデルでは、CoT と比較した CR の改善は 9.3% に達しました。
元の ToT 論文では 24 ポイント ゲームが使用されていたため、研究者たちはこのデータセットを使用して CR と ToT を比較しました。
ToT は固定の幅と深さの検索ツリーを使用し、CR を使用すると、大規模なモデルが自律的に検索の深さを決定できます。
研究者らは実験で、24 点のコンテキストにおいて CR アルゴリズムと ToT アルゴリズムが非常に似ていることを発見しました。違いは、CR のアルゴリズムは反復ごとに最大 1 つの新しい状態を生成するのに対し、ToT は反復ごとに多くの候補状態を生成し、状態の一部をフィルターして保持することです。
平たく言えば、ToT には CR のような前述の「検証者」が存在せず、状態 (a、b、c) が正しいか間違っているかを判断することができないため、ToT は CR よりも多くの無効な状態を探索することになります。
つまり、CR は検索正解率が高いだけでなく、検索効率も高いのです。
MATH データセットには、代数、幾何学、数論などを含む多数の数学的推論の問題が含まれています。問題の難易度は 5 つのレベルに分かれています。
CR メソッドを使用すると、モデルは質問を段階的に完了できるサブ質問に分解し、回答が生成されるまで質問と回答を繰り返すことができます。
実験結果は、2 つの異なる実験設定の下で、CR の精度が現在の既存の方法を上回り、全体の精度が最大 58% に達し、レベル 5 の問題で相対精度が 42% 向上したことを示しています。 GPT-4モデルの下で。
清華大学のYao Qizhi氏とYuan Yang氏が主導した研究
この論文は、清華学際情報研究所の Yao Qizhi 氏と Yuan Yang 氏が率いる AI for Math 研究グループによるものです。
この論文の共同筆頭著者は、学際情報研究所の2021年度博士課程学生であるZhang YifanとYang Jingqinです。
講師および共著者はYuan Yang助教授とYao Qizhi学術研究員です。
チャン・イーファン
Zhang Yifan は 2021 年に北京大学遠平学院を卒業し、現在は Yuan Yang 助教授に師事しており、主な研究方向は基本モデル (大規模言語モデル) の理論とアルゴリズム、自己教師あり学習、および信頼できる人工知能です。
ヤン・ジンチン
Yang Jingqin 氏は、2021 年に清華大学相互情報研究所で学士号を取得し、現在、Yuan Yang 助教授の下で博士号取得に向けて勉強しています。主な研究方向としては、大規模言語モデル、自己教師あり学習、インテリジェント医療などが挙げられます。
元ヤン
主な研究方向はインテリジェント医療、AI基礎理論、応用カテゴリー理論など。
姚其之
姚其之教授は、2004 年に終身教授としてプリンストン大学を辞任し、清華に戻って教鞭を執り、2005 年には清華大学の学部生向けのコンピュータ サイエンス実験クラス「ヤオ クラス」を設立し、2011 年には「清華量子情報センター」を設立しました。 」と「学際情報研究所」、2019年に 2008年、清華大学の学部生向けに「スマートクラス」と呼ばれる人工知能クラスを設立した。
現在、彼が率いる清華大学学際情報研究所は古くから有名であり、Yao ClassとZhibanは両方とも学際情報研究所に所属しています。
Yao Qizhi 教授の研究対象には、アルゴリズム、暗号学、量子コンピューティングなどが含まれます。彼はこの分野の国際的な先駆者であり権威です。最近、彼は2023年世界人工知能会議に出席し、彼が率いる上海Qizhi研究所は現在「身体化された汎用人工知能」を研究している。
論文リンク: