> 驚くべき発見: 大規模モデルには知識推論において重大な欠陥があります。知識を柔軟に応用することが知恵の鍵です。人間の脳は、「『きよしこの夜の考え』には何語ある?」と即座に答えるなど、知識を素早く処理することができます。では、同様の操作を大きなモデルでも実行できるのでしょうか?大規模なモデルは、まず思考連鎖 (CoT) を通じて「きよしこの夜の思考」をサイレントに書き込み、次に書かれた内容に基づいて質問に答えることができることが知られていますが、これにより生成されるテキストが長くなります。対照的に、人間は中間ステップを書き出すことなく、単純な知識の演繹を頭の中で完了することができます。それでは、非常に大規模な言語モデルは、最初に知識ポイントを書き留めることなく、人工脳内で直接答えを生成できるのでしょうか?**答えはノーであることが判明しました。図 1/2/3 は、GPT4 に関する多くの反例を示しています。最も基本的な分類 (有名人の誕生日が等しいかどうかを判断するなど) や比較 (2 人の大統領の誕生日を比較するなど) でさえ、思考連鎖を通過する必要があります。さらに悪いことに、大規模なモデルはトレーニング セットから知識を逆に抽出することがほぼ完全に不可能です。 **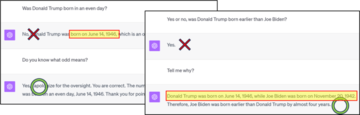 *図1: GPT4は知識の分類・比較でミスをするが、思考連鎖により正解が得られる*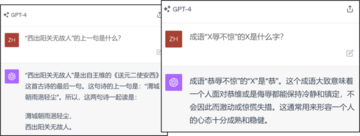 *図 2: GPT4 ナレッジ逆引き検索エラーの例* *図 3: GPT4 は「誰かの誕生日はいつですか」と「特定の数字は偶数ですか?」に正しく答えることができますが、この 2 つを組み合わせると、思考連鎖 (CoT) がなければ正解率は 50% にすぎません。 1900年から1910年までの有名人の誕生日を比較する場合、そのパフォーマンスは盲目的な推測に近いものでもあります。 *Zhu Zeyuan (MetaAI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.2: 知識の操作」は、上記の問題に焦点を当てています。 用紙のアドレス:まず質問させてください。図 1、2、3 のような問題について、GPT4 が人の誕生日を十分正確に記憶していないためでしょうか (圧縮率が十分ではなく、トレーニング損失が十分に低くないため)、それとも微調整を通じてパリティについての理解を深めることができていないでしょうか? GPT4 を微調整して、モデル内の既存の知識を組み合わせて「誕生日パリティ」などの新しい知識を生成し、それによって CoT に依存せずに関連する質問に直接答えることができるようにすることは可能でしょうか? GPT4 のトレーニング データ セットがわからないため、微調整できません。したがって、著者は、制御可能なトレーニング セットを使用して、言語モデルの「知識演繹」能力をさらに研究することを提案します。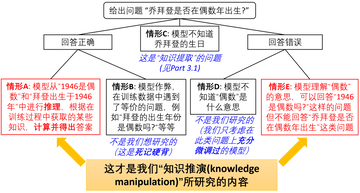 *図 4: GPT4 などの事前トレーニング済みモデルの場合、インターネット データの制御不能な性質により、状況 B/C/D が発生するかどうかを判断するのは困難です*「言語モデル物理学パート 3.1: 知識の保存と検索」では、著者は 10 万件の伝記を含むデータ セットを作成しました。各経歴には、個人の名前と、生年月日、出生地、大学の専攻、大学名、勤務地、および勤務単位の 6 つの属性が含まれます。例えば:「アーニャ・ブライアー・フォージャーはニュージャージー州プリンストン出身。彼女はコミュニケーションの勉強に専念しました。彼女はカリフォルニア州メンローパークで実務経験を積みました。彼女はメタ プラットフォームでキャリアを築きました。彼女は 1996 年 10 月 2 日にこの世に生まれ、MIT で上級コースを履修しました。」著者らは、モデルが知識にアクセスしやすくするために、伝記エントリの多様性を確保しました。事前トレーニング後、モデルは微調整を通じて「アーニャの誕生日はいつですか」などの知識抽出の質問に正確に答えることができます (正解率は 100% に近い)。次に著者は微調整を続け、知識の分類・比較・加減算などの知識演繹問題をモデルに学習させてみました。この記事では、自然言語モデルの知識演繹能力は非常に限られており、モデルがすでに習得した知識の単なる単純な変換/組み合わせであっても、微調整によって新しい知識を生成するのは困難であることがわかりました。 **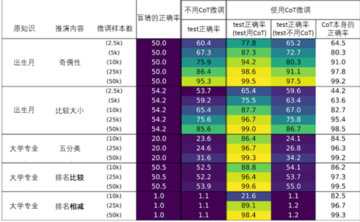 *図 5: 微調整中に CoT が使用されない場合、モデルで知識の分類/比較/減算を可能にするには、多数のサンプルが必要になるか、精度が非常に低くなります - 実験では 100 の専攻が使用されました*図 5 に示すように、著者は、モデルは事前トレーニング後に全員の誕生日を正確に答えることができますが (正解率は 100% に近い)、「xxx の誕生月は偶数ですか?」と答えるには微調整する必要があることを発見しました。 75% の精度を達成します。ブラインド推測の精度は 50% であることを忘れないでください。少なくとも 10,000 の微調整サンプルが必要です。比較すると、モデルが「誕生日」と「パリティ」の知識の組み合わせを正しく完了できる場合、従来の機械学習理論によれば、モデルは 12 か月を分類することを学習するだけでよく、通常は約 100 個のサンプルで十分です。同様に、事前トレーニング後、モデルは各人の専攻 (合計 100 の異なる専攻) を正確に答えることができますが、50,000 の微調整サンプルを使用して「アーニャの専攻とサブリナの専攻はどちらが優れているか」を比較したとしても、精度は率はわずか 53.9% であり、ほぼ盲目的な推測です。ただし、CoT 微調整を使用してモデルに「アーニャの誕生月は 10 月なので、偶数です」などの文を学習させると、テスト セット上の誕生月のパリティを判断するモデルの精度が大幅に向上します。 (図 5「CoT」列の「テスト使用」を参照)。また、著者は微調整トレーニング データに CoT 応答と非 CoT 応答を混合しようとしましたが、テスト セットで CoT を使用しない場合のモデルの精度が依然として非常に低いことがわかりました (「CoT を使用しないテスト」の列を参照)図5)。これは、十分な CoT 微調整データが追加されたとしても、モデルが「頭の中で考える」ことを学習して答えを直接報告することができないことを示しています。これらの結果は、言語モデルが単純な知識操作を実行することが非常に難しいことを示しています。モデルは知識点を書き込んでから計算する必要があり、人間のように脳内で直接操作することはできず、いくら微調整しても役に立ちません。 **## **逆知識検索の課題**この記事では、自然言語モデルは学習した知識を逆検索できないことも判明しました。個人に関するすべての情報に答えることができますが、この情報に基づいて個人の名前を決定することはできません。知識の分類/比較と同様に、著者は GPT3.5/4 で実験を行ったところ、逆知識抽出ではパフォーマンスが低いことがわかりました (図 6 を参照)。ただし、GPT3.5/4 のトレーニング セットを特定できないため、すべての言語モデルにこの問題があることが証明されるわけではありません。 *図6: GPT3.5/4の順方向/逆方向知識検索の比較。私たちが数日前に報告した「呪いの逆転」作業 (arxiv 2309.12288) でも、既存の大規模モデルでこれが観察されました。 *著者は、前述の伝記データセットを使用して、モデルの逆知識検索機能に関するより詳細な管理された実験を実施しました。すべての伝記の名前が段落の先頭にあるため、著者は次のような 10 個の逆情報抽出問題を設計しました。「1996 年 10 月 2 日にニュージャージー州プリンストンで生まれた人の名前を教えてください。」「MIT でコミュニケーションを学び、1996 年 10 月 2 日にニュージャージー州プリンストンで生まれ、カリフォルニア州メンローパークのメタ プラットフォームで働いている人の名前を教えてください。」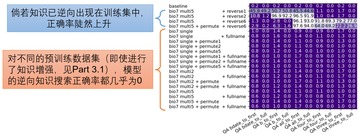 *図 7: 有名人の伝記データセットに関する対照実験*著者は、このモデルが可逆的な知識圧縮と十分な知識強化を実現し、この知識をほぼ 100% 正確に抽出できるにもかかわらず、微調整後もモデルは依然として知識の逆探索を実行できず、精度がほぼゼロであることを検証しました (図 7 を参照)。ただし、逆知識が事前トレーニング セットに直接現れると、逆検索の精度はすぐに向上します。要約すると、逆知識が事前学習データに直接含まれている場合にのみ、モデルは微調整を通じて逆質問に答えることができます。しかし、これは実際には不正行為です。なぜなら、知識が逆転されている場合、それはもはや「逆知識」ではないからです。検索"。事前トレーニング セットに順方向の知識のみが含まれている場合、モデルは微調整を通じて質問に逆方向に答える能力を習得できません。したがって、知識のインデックス付け (知識データベース) に言語モデルを使用することは、現時点では不可能と思われます。 **また、上記の「逆知識探索」の失敗は、GPTなどの自己回帰言語モデルの一方向性のせいではないかと考える人もいるかもしれない。しかし実際には、BERT などの双方向言語モデルは知識抽出のパフォーマンスが悪く、前方抽出でも失敗します。興味のある読者は、詳細についてこの論文を参照してください。
言語モデルには大きな欠陥があり、知識推論が長年の問題であることが判明
知識を柔軟に応用することが知恵の鍵です。人間の脳は、「『きよしこの夜の考え』には何語ある?」と即座に答えるなど、知識を素早く処理することができます。では、同様の操作を大きなモデルでも実行できるのでしょうか?大規模なモデルは、まず思考連鎖 (CoT) を通じて「きよしこの夜の思考」をサイレントに書き込み、次に書かれた内容に基づいて質問に答えることができることが知られていますが、これにより生成されるテキストが長くなります。対照的に、人間は中間ステップを書き出すことなく、単純な知識の演繹を頭の中で完了することができます。それでは、非常に大規模な言語モデルは、最初に知識ポイントを書き留めることなく、人工脳内で直接答えを生成できるのでしょうか?
**答えはノーであることが判明しました。図 1/2/3 は、GPT4 に関する多くの反例を示しています。最も基本的な分類 (有名人の誕生日が等しいかどうかを判断するなど) や比較 (2 人の大統領の誕生日を比較するなど) でさえ、思考連鎖を通過する必要があります。さらに悪いことに、大規模なモデルはトレーニング セットから知識を逆に抽出することがほぼ完全に不可能です。 **
Zhu Zeyuan (MetaAI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.2: 知識の操作」は、上記の問題に焦点を当てています。
まず質問させてください。図 1、2、3 のような問題について、GPT4 が人の誕生日を十分正確に記憶していないためでしょうか (圧縮率が十分ではなく、トレーニング損失が十分に低くないため)、それとも微調整を通じてパリティについての理解を深めることができていないでしょうか? GPT4 を微調整して、モデル内の既存の知識を組み合わせて「誕生日パリティ」などの新しい知識を生成し、それによって CoT に依存せずに関連する質問に直接答えることができるようにすることは可能でしょうか? GPT4 のトレーニング データ セットがわからないため、微調整できません。したがって、著者は、制御可能なトレーニング セットを使用して、言語モデルの「知識演繹」能力をさらに研究することを提案します。
「言語モデル物理学パート 3.1: 知識の保存と検索」では、著者は 10 万件の伝記を含むデータ セットを作成しました。各経歴には、個人の名前と、生年月日、出生地、大学の専攻、大学名、勤務地、および勤務単位の 6 つの属性が含まれます。例えば:
「アーニャ・ブライアー・フォージャーはニュージャージー州プリンストン出身。彼女はコミュニケーションの勉強に専念しました。彼女はカリフォルニア州メンローパークで実務経験を積みました。彼女はメタ プラットフォームでキャリアを築きました。彼女は 1996 年 10 月 2 日にこの世に生まれ、MIT で上級コースを履修しました。」
著者らは、モデルが知識にアクセスしやすくするために、伝記エントリの多様性を確保しました。事前トレーニング後、モデルは微調整を通じて「アーニャの誕生日はいつですか」などの知識抽出の質問に正確に答えることができます (正解率は 100% に近い)。
次に著者は微調整を続け、知識の分類・比較・加減算などの知識演繹問題をモデルに学習させてみました。この記事では、自然言語モデルの知識演繹能力は非常に限られており、モデルがすでに習得した知識の単なる単純な変換/組み合わせであっても、微調整によって新しい知識を生成するのは困難であることがわかりました。 **
図 5 に示すように、著者は、モデルは事前トレーニング後に全員の誕生日を正確に答えることができますが (正解率は 100% に近い)、「xxx の誕生月は偶数ですか?」と答えるには微調整する必要があることを発見しました。 75% の精度を達成します。ブラインド推測の精度は 50% であることを忘れないでください。少なくとも 10,000 の微調整サンプルが必要です。比較すると、モデルが「誕生日」と「パリティ」の知識の組み合わせを正しく完了できる場合、従来の機械学習理論によれば、モデルは 12 か月を分類することを学習するだけでよく、通常は約 100 個のサンプルで十分です。
同様に、事前トレーニング後、モデルは各人の専攻 (合計 100 の異なる専攻) を正確に答えることができますが、50,000 の微調整サンプルを使用して「アーニャの専攻とサブリナの専攻はどちらが優れているか」を比較したとしても、精度は率はわずか 53.9% であり、ほぼ盲目的な推測です。
ただし、CoT 微調整を使用してモデルに「アーニャの誕生月は 10 月なので、偶数です」などの文を学習させると、テスト セット上の誕生月のパリティを判断するモデルの精度が大幅に向上します。 (図 5「CoT」列の「テスト使用」を参照)。
また、著者は微調整トレーニング データに CoT 応答と非 CoT 応答を混合しようとしましたが、テスト セットで CoT を使用しない場合のモデルの精度が依然として非常に低いことがわかりました (「CoT を使用しないテスト」の列を参照)図5)。これは、十分な CoT 微調整データが追加されたとしても、モデルが「頭の中で考える」ことを学習して答えを直接報告することができないことを示しています。
これらの結果は、言語モデルが単純な知識操作を実行することが非常に難しいことを示しています。モデルは知識点を書き込んでから計算する必要があり、人間のように脳内で直接操作することはできず、いくら微調整しても役に立ちません。 **
逆知識検索の課題
この記事では、自然言語モデルは学習した知識を逆検索できないことも判明しました。個人に関するすべての情報に答えることができますが、この情報に基づいて個人の名前を決定することはできません。
知識の分類/比較と同様に、著者は GPT3.5/4 で実験を行ったところ、逆知識抽出ではパフォーマンスが低いことがわかりました (図 6 を参照)。ただし、GPT3.5/4 のトレーニング セットを特定できないため、すべての言語モデルにこの問題があることが証明されるわけではありません。
著者は、前述の伝記データセットを使用して、モデルの逆知識検索機能に関するより詳細な管理された実験を実施しました。すべての伝記の名前が段落の先頭にあるため、著者は次のような 10 個の逆情報抽出問題を設計しました。
「1996 年 10 月 2 日にニュージャージー州プリンストンで生まれた人の名前を教えてください。」
「MIT でコミュニケーションを学び、1996 年 10 月 2 日にニュージャージー州プリンストンで生まれ、カリフォルニア州メンローパークのメタ プラットフォームで働いている人の名前を教えてください。」
著者は、このモデルが可逆的な知識圧縮と十分な知識強化を実現し、この知識をほぼ 100% 正確に抽出できるにもかかわらず、微調整後もモデルは依然として知識の逆探索を実行できず、精度がほぼゼロであることを検証しました (図 7 を参照)。ただし、逆知識が事前トレーニング セットに直接現れると、逆検索の精度はすぐに向上します。
要約すると、逆知識が事前学習データに直接含まれている場合にのみ、モデルは微調整を通じて逆質問に答えることができます。しかし、これは実際には不正行為です。なぜなら、知識が逆転されている場合、それはもはや「逆知識」ではないからです。検索"。事前トレーニング セットに順方向の知識のみが含まれている場合、モデルは微調整を通じて質問に逆方向に答える能力を習得できません。したがって、知識のインデックス付け (知識データベース) に言語モデルを使用することは、現時点では不可能と思われます。 **
また、上記の「逆知識探索」の失敗は、GPTなどの自己回帰言語モデルの一方向性のせいではないかと考える人もいるかもしれない。しかし実際には、BERT などの双方向言語モデルは知識抽出のパフォーマンスが悪く、前方抽出でも失敗します。興味のある読者は、詳細についてこの論文を参照してください。