出典: 量子ビットマルチモーダルキングモデル GPT-4V、**「説明書」166ページ**が発売!そしてそれはマイクロソフトチームによって制作されています。166ページでどんな論文が書けるでしょうか?GPT-4V のパフォーマンスを上位 10 個のタスクで詳細に評価するだけでなく、基本的な画像認識から複雑な論理的推論まですべてを実証します。また、マルチモーダル大規模モデルの完全なセットを教えます **ヒントとなる単語の使用スキル**—即答単語の書き方を0から1まで段階的に教えてくれるうえ、プロレベルの解答が一目で分かり、GPT-4Vの敷居が高くなります。 特筆すべきは、この論文の著者も「オール中国人層」であり、著者7名は全員中国人であり、リーダーはマイクロソフトに17年間勤務した女性主任研究部長である。166 ページのレポートのリリース前に、彼らは OpenAI の最新の DALL・E 3 の研究にも参加しており、この分野について深い理解を持っています。OpenAI の 18 ページの GPT-4V 論文と比較すると、この 166 ページの「食事ガイド」はすぐに GPT-4V ユーザーの必読書とみなされました。 一部のネチズンは「これは論文ではない、ほぼ166ページの本だ」と嘆いた。 一部のネチズンは、次の記事を読んですでにパニックになっていました。> GPT-4V の答えの詳細だけを見てはいけません AI の潜在的な能力が本当に怖いです。 では、Microsoft の「論文」は一体何を語っているのでしょうか、また GPT-4V についてどのような「可能性」を示しているのでしょうか?## **Microsoft の 166 ページのレポートには何が書かれていますか? **この論文では、GPT-4V の手法を研究します。その核心は、**「try」** という 1 つの単語に依存しています。Microsoft の研究者は、複数のドメインをカバーする一連の入力を設計し、それらを GPT-4V に供給し、GPT-4V の出力を観察および記録しました。その後、彼らはさまざまなタスクを完了する GPT-4V の能力を評価し、次の 4 つの主要な側面を含む、GPT-4V を使用するための新しいプロンプト ワード テクニックも示しました。**1. GPT-4V の使用方法: **入力画像(イメージ)、サブイメージ(サブイメージ)、テキスト(テキスト)、シーンテキスト(シーンテキスト)、ビジュアルポインタ(ビジュアルポインタ)の5つの使い方があります。サポートされている 3 つの機能: 指示に従い、思考の連鎖、およびコンテキスト内の少数ショット学習。たとえば、これは思考連鎖に基づいて質問方法を変更した後の GPT-4V で示された指示追従能力です。 **2. 10 の主要なタスクにおける GPT-4V のパフォーマンス: **オープンワールドの視覚的理解、視覚的説明、マルチモーダル知識、常識、シーンテキスト理解、文書推論、ライティングコーディング、時間推論、抽象推論、感情理解その中には、解くのにある程度の IQ が必要な、次のような「イメージ推論の問題」もあります。 **3. GPT-4V に似た大規模なマルチモーダル モデルのプロンプト ワード スキル: **入力画像を直接編集することで関心のあるタスクを提示でき、他のキューワード技術と組み合わせて使用できる、新しいマルチモーダルキューワード技術「ビジュアル・リファリング」(visual Refering)を提案する。 **4. マルチモーダル大規模モデルの研究と実装の可能性: **マルチモーダル学習の研究者が注力すべき 2 つの分野 (実装 (潜在的な応用シナリオ) と研究の方向性) が予測されます。たとえば、これは研究者によって発見された GPT-4V の考えられるシナリオの 1 つです - 障害検出: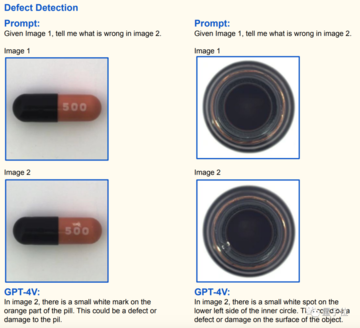 しかし、新しいプロンプトワード技術であれ、GPT-4V の応用シナリオであれ、誰もが最も懸念しているのは、GPT-4V の真の強さです。 したがって、この「取扱説明書」では、その後 150 ページ以上を使用してさまざまなデモを示し、さまざまな答えに直面した GPT-4V の機能を詳しく説明しました。GPT-4V のマルチモーダル機能が現在どこまで進化しているかを見てみましょう。## **専門分野の画像に精通し、知識もすぐに学べます**### **画像の識別**もちろん、最も基本的な身元確認は簡単なもので、テクノロジー、スポーツ、エンターテインメントの各界の有名人などです。 そして、これらの人々が誰であるかを見ることができるだけでなく、彼らが何をしているのかを解釈することもできます。たとえば、下の写真では、Huang が Nvidia の新しいグラフィックス カード製品を紹介しています。 GPT-4Vでは人物だけでなくランドマークも簡単に認識でき、名前や位置を特定するだけでなく、詳細な紹介も行うことができます。 **△**左:ニューヨークのタイムズスクエア、右:京都の金閣寺ただし、有名な人物や場所ほど判断が容易になるため、GPT-4Vの性能を伝えるにはより難しい写真が必要になります。たとえば、医療画像では、次の肺 CT に関して、GPT-4V は次の結論を出しました。> 両肺の複数の領域に硬化やすりガラス状の陰影があり、肺に感染症または炎症がある可能性があります。右肺の上葉に腫瘤や結節が存在することもあります。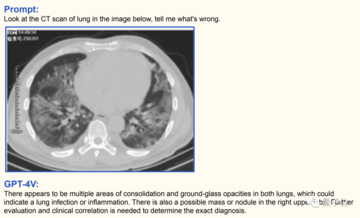 GPT-4Vに画像の種類や位置を教えなくても、GPT-4Vが自ら判断します。この画像では、GPT-4V が脳の磁気共鳴画像法 (MRI) 画像であることを識別することに成功しました。同時に、GPT-4V では大量の体液の蓄積も見つかり、これは高悪性度の神経膠腫であると考えられました。専門家の判断の結果、GPT-4V が出した結論は完全に正しいです。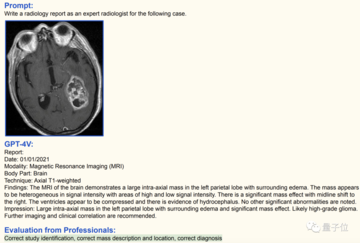 これらの「深刻な」コンテンツに加えて、現代人間社会の「無形文化遺産」の絵文字も GPT-4V によってキャプチャされています。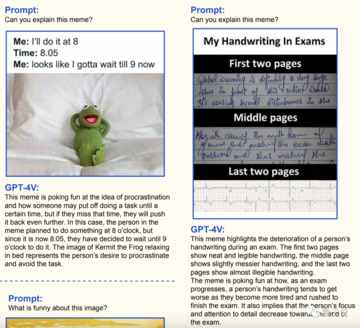  **△**機械翻訳、参考のみGPT-4 は、絵文字のミームを解釈できるだけでなく、現実世界の人間の表情によって表現される感情も見ることができます。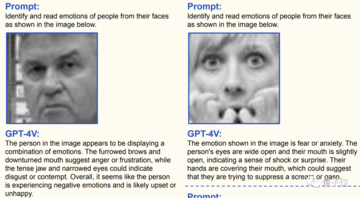  これらの実際の画像に加えて、テキスト認識もマシン ビジョンにおける重要なタスクです。この点、GPT-4Vはラテン文字で綴られた言語を認識できるだけでなく、中国語、日本語、ギリシャ語などの他の言語も認識できます。 手書きの数式も: ### **イメージ推論**上に示したデモは、どんなに専門的でわかりにくくても、まだ認識の範囲内ですが、これは GPT-4V のスキルの氷山の一角にすぎません。GPT-4V は、画像の内容を理解するだけでなく、特定の推論機能も備えています。簡単に言うと、GPT-4V は 2 つの画像間の違いを見つけることができます (ただし、多少の誤差はあります)。次の一連の写真では、王冠と船首の違いが GPT-4V によって発見されました。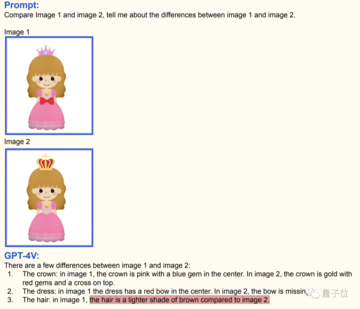 難易度を上げると、GPT-4V は IQ テストのグラフィック問題も解くことができます。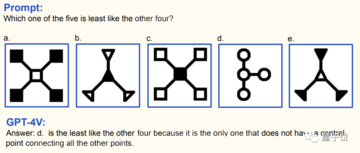 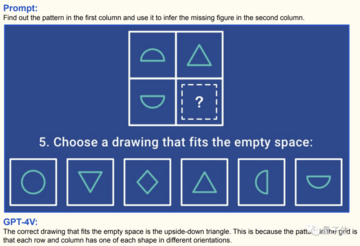  上記 3 つの質問の特徴や論理的関係は比較的単純ですが、次に難しい問題が生じます。もちろん、問題はグラフィック自体にあるわけではありません。図の 4 番目のテキストの説明に注意してください。元の質問のグラフィックの配置は、図に示されているものではありません。 ### **画像の注釈**GPT-4Vは、さまざまな質問にテキストで答えるだけでなく、画像に対して一連の操作を行うこともできます。たとえば、AI の巨人 4 人の集合写真があり、登場人物をフレームに収め、名前と簡単な紹介をラベル付けするには GPT-4V が必要です。 GPT-4V は、最初にこれらの質問にテキストで回答し、次に処理された画像を提供しました。 ### **動的コンテンツ分析**これらの静的コンテンツに加えて、GPT-4V は動的解析も実行できますが、モデルにビデオを直接供給しません。次の 5 つの写真は、寿司の作り方に関するチュートリアル ビデオから抜粋したもので、GPT-4V のタスクは、(内容の理解に基づいて) これらの写真が表示される順序を推測することです。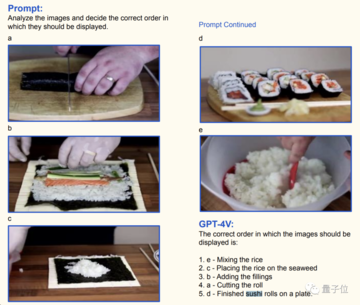 同じ一連の写真でも捉え方が異なる場合があるため、GPT-4V はテキストのプロンプトに基づいて判断します。たとえば、次の一連の写真では、人物のアクションがドアを開けるかドアを閉めるかによって、まったく逆のソート結果が得られます。 もちろん、複数の絵の中のキャラクターの状態の変化から、彼らが何をしているのかを推測することもできます。 あるいは、次に何が起こるかを予測することもできます。 ### **「体験学習」**GPT-4V は優れたビジュアル スキルを備えているだけでなく、すぐに学習して販売できることが重要です。たとえば、GPT-4V が車のダッシュボードを読み取るように求められた場合、最初に得られた答えは間違っています。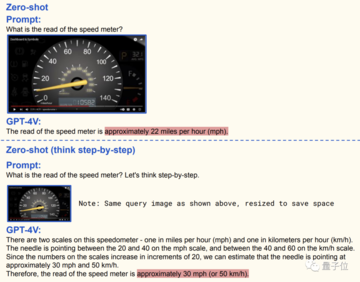 次に、テキストで GPT-4V にメソッドを与えましたが、この答えはまだ間違っています。 次に、その例を GPT-4V に見せたところ、答えは同様でしたが、残念ながら数値はランダムに作成されました。 確かに 1 つの例だけでは少し少ないですが、サンプルの数が増えるにつれて (実際にはあと 1 つしかありません)、最終的には苦労が報われ、GPT-4V が正しい答えを返します。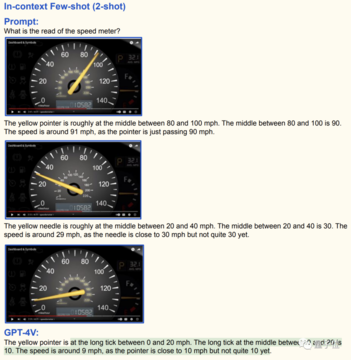 GPT-4V は非常に多くの効果しか示していません。もちろん、さらに多くのフィールドやタスクもサポートしています。ここで 1 つずつ紹介することは不可能です。興味があれば、オリジナルのレポートを読むことができます。では、GPT-4V のようなアーティファクトの影響の背後にはどのようなチームがあるのでしょうか?## **清華大学同窓会リーダー**この論文の著者は合計 7 名で、全員が中国人で、そのうち 6 名が中心著者です。 このプロジェクトの主著者である Lijuan Wang は、マイクロソフトのクラウド コンピューティングと AI の主任研究マネージャーです。 彼女は華中科技大学を卒業し、中国の清華大学で博士号を取得し、2006 年に Microsoft Research Asia に入社し、2016 年にレドモンドの Microsoft Research に入社しました。彼女の研究分野は、マルチモーダル知覚インテリジェンスに基づくディープラーニングと機械学習で、具体的には視覚言語モデルの事前トレーニング、画像字幕生成、ターゲット検出、その他の AI テクノロジーが含まれます。元のアドレス:
Microsoft は GPT-4V マニュアルを作成しました。166 ページにわたる完全かつ詳細な説明 (プロンプト ワードのデモの例を含む)。
出典: 量子ビット
マルチモーダルキングモデル GPT-4V、「説明書」166ページが発売!そしてそれはマイクロソフトチームによって制作されています。
166ページでどんな論文が書けるでしょうか?
GPT-4V のパフォーマンスを上位 10 個のタスクで詳細に評価するだけでなく、基本的な画像認識から複雑な論理的推論まですべてを実証します。
また、マルチモーダル大規模モデルの完全なセットを教えます ヒントとなる単語の使用スキル—
即答単語の書き方を0から1まで段階的に教えてくれるうえ、プロレベルの解答が一目で分かり、GPT-4Vの敷居が高くなります。
166 ページのレポートのリリース前に、彼らは OpenAI の最新の DALL・E 3 の研究にも参加しており、この分野について深い理解を持っています。
OpenAI の 18 ページの GPT-4V 論文と比較すると、この 166 ページの「食事ガイド」はすぐに GPT-4V ユーザーの必読書とみなされました。
**Microsoft の 166 ページのレポートには何が書かれていますか? **
この論文では、GPT-4V の手法を研究します。その核心は、「try」 という 1 つの単語に依存しています。
Microsoft の研究者は、複数のドメインをカバーする一連の入力を設計し、それらを GPT-4V に供給し、GPT-4V の出力を観察および記録しました。
その後、彼らはさまざまなタスクを完了する GPT-4V の能力を評価し、次の 4 つの主要な側面を含む、GPT-4V を使用するための新しいプロンプト ワード テクニックも示しました。
**1. GPT-4V の使用方法: **
入力画像(イメージ)、サブイメージ(サブイメージ)、テキスト(テキスト)、シーンテキスト(シーンテキスト)、ビジュアルポインタ(ビジュアルポインタ)の5つの使い方があります。
サポートされている 3 つの機能: 指示に従い、思考の連鎖、およびコンテキスト内の少数ショット学習。
たとえば、これは思考連鎖に基づいて質問方法を変更した後の GPT-4V で示された指示追従能力です。
オープンワールドの視覚的理解、視覚的説明、マルチモーダル知識、常識、シーンテキスト理解、文書推論、ライティングコーディング、時間推論、抽象推論、感情理解
その中には、解くのにある程度の IQ が必要な、次のような「イメージ推論の問題」もあります。
入力画像を直接編集することで関心のあるタスクを提示でき、他のキューワード技術と組み合わせて使用できる、新しいマルチモーダルキューワード技術「ビジュアル・リファリング」(visual Refering)を提案する。
マルチモーダル学習の研究者が注力すべき 2 つの分野 (実装 (潜在的な応用シナリオ) と研究の方向性) が予測されます。
たとえば、これは研究者によって発見された GPT-4V の考えられるシナリオの 1 つです - 障害検出:
GPT-4V のマルチモーダル機能が現在どこまで進化しているかを見てみましょう。
専門分野の画像に精通し、知識もすぐに学べます
画像の識別
もちろん、最も基本的な身元確認は簡単なもので、テクノロジー、スポーツ、エンターテインメントの各界の有名人などです。
ただし、有名な人物や場所ほど判断が容易になるため、GPT-4Vの性能を伝えるにはより難しい写真が必要になります。
たとえば、医療画像では、次の肺 CT に関して、GPT-4V は次の結論を出しました。
この画像では、GPT-4V が脳の磁気共鳴画像法 (MRI) 画像であることを識別することに成功しました。
同時に、GPT-4V では大量の体液の蓄積も見つかり、これは高悪性度の神経膠腫であると考えられました。
専門家の判断の結果、GPT-4V が出した結論は完全に正しいです。
GPT-4 は、絵文字のミームを解釈できるだけでなく、現実世界の人間の表情によって表現される感情も見ることができます。
この点、GPT-4Vはラテン文字で綴られた言語を認識できるだけでなく、中国語、日本語、ギリシャ語などの他の言語も認識できます。
上に示したデモは、どんなに専門的でわかりにくくても、まだ認識の範囲内ですが、これは GPT-4V のスキルの氷山の一角にすぎません。
GPT-4V は、画像の内容を理解するだけでなく、特定の推論機能も備えています。
簡単に言うと、GPT-4V は 2 つの画像間の違いを見つけることができます (ただし、多少の誤差はあります)。
次の一連の写真では、王冠と船首の違いが GPT-4V によって発見されました。
もちろん、問題はグラフィック自体にあるわけではありません。図の 4 番目のテキストの説明に注意してください。元の質問のグラフィックの配置は、図に示されているものではありません。
GPT-4Vは、さまざまな質問にテキストで答えるだけでなく、画像に対して一連の操作を行うこともできます。
たとえば、AI の巨人 4 人の集合写真があり、登場人物をフレームに収め、名前と簡単な紹介をラベル付けするには GPT-4V が必要です。
これらの静的コンテンツに加えて、GPT-4V は動的解析も実行できますが、モデルにビデオを直接供給しません。
次の 5 つの写真は、寿司の作り方に関するチュートリアル ビデオから抜粋したもので、GPT-4V のタスクは、(内容の理解に基づいて) これらの写真が表示される順序を推測することです。
たとえば、次の一連の写真では、人物のアクションがドアを開けるかドアを閉めるかによって、まったく逆のソート結果が得られます。
GPT-4V は優れたビジュアル スキルを備えているだけでなく、すぐに学習して販売できることが重要です。
たとえば、GPT-4V が車のダッシュボードを読み取るように求められた場合、最初に得られた答えは間違っています。
では、GPT-4V のようなアーティファクトの影響の背後にはどのようなチームがあるのでしょうか?
清華大学同窓会リーダー
この論文の著者は合計 7 名で、全員が中国人で、そのうち 6 名が中心著者です。
彼女の研究分野は、マルチモーダル知覚インテリジェンスに基づくディープラーニングと機械学習で、具体的には視覚言語モデルの事前トレーニング、画像字幕生成、ターゲット検出、その他の AI テクノロジーが含まれます。
元のアドレス: