編集者:エッグソース会話型 AI ロボットとのコミュニケーションを経験したことがある方なら、非常に「イライラする」瞬間を覚えているはずです。たとえば、前日の会話で話した重要なポイントは、AIによって完全に忘れられていました...なぜなら、現在の LLM は限られた文脈しか覚えておらず、詰め込み試験に臨む学生と同じように、少し質問すると足元が露呈してしまうからです。AI アシスタントがチャットで数週間または数か月前の会話を状況に応じて参照できたり、AI アシスタントに数千ページにわたるレポートを要約するよう依頼できたりすることを想像してみてください。LLM の記憶力をより良くするために、研究者たちは常に努力を続けています。最近、MIT、Meta AI、CMU の研究者は、言語モデルが無限のテキストをスムーズに処理できるようにする「StreamingLLM」と呼ばれる手法を提案しました。 * 紙のアドレス:* プロジェクトアドレス:StreamingLLM の動作原理は、推論のためにモデル固有の「アテンション シンク」によって固定された最初のトークンを識別して保存することです。最近のトークンのローリング キャッシュと組み合わせることで、StreamingLLM は精度を犠牲にすることなく推論を 22 倍高速化します。わずか数日で、このプロジェクトは GitHub プラットフォームで 2.5,000 個のスターを獲得しました。 具体的には、StreamingLLM を使用すると、AI アシスタントの記憶が完璧に処理できるようにアップグレードされたのと同じように、言語モデルが最後の試合のタッチダウン スコア、新生児の名前、長期の契約、または討論の内容を正確に記憶できるようになります。より重いワークロード。 次に技術的な詳細を見てみましょう。## **メソッドのイノベーション**通常、LLM は事前トレーニング時のアテンション ウィンドウによって制限されます。このウィンドウ サイズを拡大し、トレーニングと推論の効率を向上させるためにこれまで多くの作業が行われてきましたが、LLM の許容シーケンス長は依然として制限されており、永続的な展開には適していません。この論文では、研究者らは最初に LLM ストリーミング アプリケーションの概念を紹介し、「効率とパフォーマンスを犠牲にすることなく、無限に長い入力を使用して LLM を展開できるか?」という質問をしました。LLM を無限に長い入力ストリームに適用する場合、主に 2 つの課題があります。1. 図 1 (a) に示すように、デコード フェーズ中、トランスフォーマー ベースの LLM は以前のすべてのトークンのキーと値のステータス (KV) をキャッシュします。これにより、過度のメモリ使用量が発生し、デコードの待ち時間が増加する可能性があります。2. 既存のモデルの長さの外挿能力には限界があります。つまり、シーケンスの長さが事前トレーニング中に設定されたアテンション ウィンドウ サイズを超えると、パフォーマンスが低下します。 直観的な方法は、ウィンドウ アテンションと呼ばれます (図 1 b)。この方法は、最新のトークンの KV 状態で固定サイズのスライディング ウィンドウのみを維持しますが、安定したメモリ使用量とデコード速度を維持できますが、シーケンスの長さがキャッシュ サイズを超えるか、最初のトークンの KV を削除するだけでも、モデルは崩壊します。もう 1 つの方法は、スライディング ウィンドウを再計算することです (図 1 c に示されています)。この方法では、生成されたトークンごとに最近のトークンの KV 状態が再構築されます。パフォーマンスは強力ですが、ウィンドウ内で二次的な注意を計算する必要があります。結果は大幅に遅くなり、実際のストリーミング アプリケーションでは理想的ではありません。ウィンドウ アテンションの失敗を理解する過程で、研究者は自己回帰 LLM という興味深い現象を発見しました。図 2 に示すように、これらのトークンが言語モデリング タスクに関連しているかどうかに関係なく、初期トークンに多数のアテンション スコアが割り当てられています。 . .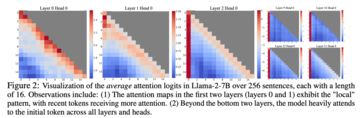 研究者はこれらのトークンを「アテンション プール」と呼んでいます。トークンには意味的な意味はありませんが、大量のアテンション ポイントを占めています。研究者らは、この現象は Softmax (すべてのコンテキスト トークンのアテンション スコアの合計が 1 である必要がある) のせいだと考えています。現在のクエリに以前の多くのトークンの間で強い一致がない場合でも、モデルはこれらの不必要なアテンションを転送する必要があります。 . 合計が 1 になるように値がどこかに割り当てられます。最初のトークンが「プール」になる理由は直感的です。自己回帰言語モデリングの特性により、最初のトークンは後続のほぼすべてのトークンに表示されるため、アテンション プールとしてトレーニングすることが容易になります。上記の洞察に基づいて、研究者らは、限られたアテンション ウィンドウを使用してトレーニングされたアテンション モデルが微調整することなく無限に長いテキストを処理できるようにする、シンプルで効率的なフレームワークである StreamingLLM を提案しました。StreamingLLM は、アテンション プールのアテンション値が高いという事実を利用し、これらのアテンション プールを保持することで、アテンション スコアの分布を正規分布に近づけることができます。したがって、StreamingLLM は、アテンションの計算を固定し、モデルのパフォーマンスを安定させるために、アテンション プール トークンの KV 値 (初期トークン 4 つだけで十分) とスライディング ウィンドウの KV 値を保持するだけで済みます。StreamingLLM を使用すると、Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B、および Pythia [2.9,6.9,12] B を含むモデルを確実にシミュレート 4 できます。 100万トークン以上。唯一の実現可能なベースラインであるスライディング ウィンドウの再計算と比較すると、StreamingLLM はパフォーマンスを犠牲にすることなく 22.2 倍高速です。## **評価**図 3 に示すように、実験セッションでは、20K トークンにわたるテキストに関して、StreamingLLM の複雑さは Oracle ベースライン (スライディング ウィンドウの再計算) に匹敵します。同時に、入力長が事前トレーニング ウィンドウを超えると、高密度アテンションは失敗し、入力長がキャッシュ サイズを超えると、ウィンドウ アテンションに問題が発生し、初期トークンが削除されます。 図 5 はさらに、StreamingLLM がさまざまなモデル ファミリとサイズをカバーし、400 万を超えるトークンを含む異常なサイズのテキストを確実に処理できることを確認しています。これには、Llama-2-[7,13,70] B、Falcon-[7,40] B、Pythia-[2.8,6.9,12] B、MPT-[7,30] B が含まれます。 その後、研究者らは「アテンション プール」の仮説を確認し、言語モデルは事前トレーニング可能であり、ストリーミング デプロイメント中にのみアテンション プール トークンを必要とすることを証明しました。具体的には、すべてのトレーニング サンプルの先頭に、指定されたアテンション プールとして追加の学習可能なトークンを追加することを推奨しています。研究者らは、1 億 6,000 万個のパラメーターを使用して言語モデルを最初から事前トレーニングすることにより、この方法がモデルのパフォーマンスを維持できることを実証しました。これは、同じレベルのパフォーマンスを達成するために複数の初期トークンをアテンション プールとして再導入する必要がある現在の言語モデルとは大きく対照的です。最後に、研究者らは、StreamingLLM のデコード遅延とメモリ使用量を再計算スライディング ウィンドウと比較し、Llama-2-7B および Llama-2-13B モデルを使用して単一の NVIDIA A6000 GPU でテストしました。図 10 に示すように、キャッシュ サイズが増加するにつれて、StreamingLLM のデコード速度は直線的に増加します。後者の復号遅延は二次曲線で増加します。実験により、StreamingLLM が各トークンの速度を最大 22.2 倍に向上させ、目覚ましい高速化を実現することが証明されました。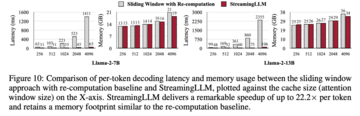 研究の詳細については、元の論文を参照してください。
最大 400 万のトークン コンテキストと 22 倍高速な推論を備えた StreamingLLM は人気があり、GitHub で 2.5,000 個のスターを獲得しています。
編集者:エッグソース
会話型 AI ロボットとのコミュニケーションを経験したことがある方なら、非常に「イライラする」瞬間を覚えているはずです。たとえば、前日の会話で話した重要なポイントは、AIによって完全に忘れられていました...
なぜなら、現在の LLM は限られた文脈しか覚えておらず、詰め込み試験に臨む学生と同じように、少し質問すると足元が露呈してしまうからです。
AI アシスタントがチャットで数週間または数か月前の会話を状況に応じて参照できたり、AI アシスタントに数千ページにわたるレポートを要約するよう依頼できたりすることを想像してみてください。
LLM の記憶力をより良くするために、研究者たちは常に努力を続けています。最近、MIT、Meta AI、CMU の研究者は、言語モデルが無限のテキストをスムーズに処理できるようにする「StreamingLLM」と呼ばれる手法を提案しました。
StreamingLLM の動作原理は、推論のためにモデル固有の「アテンション シンク」によって固定された最初のトークンを識別して保存することです。最近のトークンのローリング キャッシュと組み合わせることで、StreamingLLM は精度を犠牲にすることなく推論を 22 倍高速化します。わずか数日で、このプロジェクトは GitHub プラットフォームで 2.5,000 個のスターを獲得しました。
メソッドのイノベーション
通常、LLM は事前トレーニング時のアテンション ウィンドウによって制限されます。このウィンドウ サイズを拡大し、トレーニングと推論の効率を向上させるためにこれまで多くの作業が行われてきましたが、LLM の許容シーケンス長は依然として制限されており、永続的な展開には適していません。
この論文では、研究者らは最初に LLM ストリーミング アプリケーションの概念を紹介し、「効率とパフォーマンスを犠牲にすることなく、無限に長い入力を使用して LLM を展開できるか?」という質問をしました。
LLM を無限に長い入力ストリームに適用する場合、主に 2 つの課題があります。
図 1 (a) に示すように、デコード フェーズ中、トランスフォーマー ベースの LLM は以前のすべてのトークンのキーと値のステータス (KV) をキャッシュします。これにより、過度のメモリ使用量が発生し、デコードの待ち時間が増加する可能性があります。
既存のモデルの長さの外挿能力には限界があります。つまり、シーケンスの長さが事前トレーニング中に設定されたアテンション ウィンドウ サイズを超えると、パフォーマンスが低下します。
ウィンドウ アテンションの失敗を理解する過程で、研究者は自己回帰 LLM という興味深い現象を発見しました。図 2 に示すように、これらのトークンが言語モデリング タスクに関連しているかどうかに関係なく、初期トークンに多数のアテンション スコアが割り当てられています。 . .
上記の洞察に基づいて、研究者らは、限られたアテンション ウィンドウを使用してトレーニングされたアテンション モデルが微調整することなく無限に長いテキストを処理できるようにする、シンプルで効率的なフレームワークである StreamingLLM を提案しました。
StreamingLLM は、アテンション プールのアテンション値が高いという事実を利用し、これらのアテンション プールを保持することで、アテンション スコアの分布を正規分布に近づけることができます。したがって、StreamingLLM は、アテンションの計算を固定し、モデルのパフォーマンスを安定させるために、アテンション プール トークンの KV 値 (初期トークン 4 つだけで十分) とスライディング ウィンドウの KV 値を保持するだけで済みます。
StreamingLLM を使用すると、Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B、および Pythia [2.9,6.9,12] B を含むモデルを確実にシミュレート 4 できます。 100万トークン以上。
唯一の実現可能なベースラインであるスライディング ウィンドウの再計算と比較すると、StreamingLLM はパフォーマンスを犠牲にすることなく 22.2 倍高速です。
## 評価
図 3 に示すように、実験セッションでは、20K トークンにわたるテキストに関して、StreamingLLM の複雑さは Oracle ベースライン (スライディング ウィンドウの再計算) に匹敵します。同時に、入力長が事前トレーニング ウィンドウを超えると、高密度アテンションは失敗し、入力長がキャッシュ サイズを超えると、ウィンドウ アテンションに問題が発生し、初期トークンが削除されます。
最後に、研究者らは、StreamingLLM のデコード遅延とメモリ使用量を再計算スライディング ウィンドウと比較し、Llama-2-7B および Llama-2-13B モデルを使用して単一の NVIDIA A6000 GPU でテストしました。図 10 に示すように、キャッシュ サイズが増加するにつれて、StreamingLLM のデコード速度は直線的に増加します。後者の復号遅延は二次曲線で増加します。実験により、StreamingLLM が各トークンの速度を最大 22.2 倍に向上させ、目覚ましい高速化を実現することが証明されました。