> OpenAI の GPT-5 大型モデルの実現はまだ先のようですが、一部の研究者が率先して革新的なビジュアルおよび言語の世代間モデル MiniGPT-5 を立ち上げました。これは、一貫したテキスト説明を含む画像を生成する場合に重要な意味を持ちます。> 画像ソース: Unbounded AI によって生成大規模モデルは言語と視覚の間を飛躍させており、テキストと画像のコンテンツをシームレスに理解して生成することを約束しています。最近の一連の研究によると、マルチモーダル機能の統合は成長傾向であるだけでなく、すでにマルチモーダルな会話からコンテンツ作成ツールに至るまで重要な進歩をもたらしています。大規模な言語モデルは、テキストの理解と生成において比類のない機能を実証しています。ただし、一貫したテキストの物語を含む画像を同時に生成することは、まだ開発の余地がある領域です。最近、カリフォルニア大学サンタクルーズ校の研究チームは、「生成投票」の概念に基づいた革新的なインターリーブ視覚言語生成技術である MiniGPT-5 を提案しました。 * 紙のアドレス:* プロジェクトアドレス:MiniGPT-5 は、特別なビジュアル トークン「生成投票」を通じて安定拡散メカニズムと LLM を組み合わせることで、熟練したマルチモーダル生成のための新しいモデルを予告します。同時に、この記事で提案されている 2 段階のトレーニング方法では、記述のない基本段階の重要性が強調され、データが不足している場合でもモデルが「成長」できるようになります。このメソッドの一般的なフェーズではドメイン固有のアノテーションが必要ないため、このソリューションは既存のメソッドとは異なります。生成されたテキストと画像が調和していることを保証するために、この論文の二重損失戦略が機能し、生成投票法と分類法がこの効果をさらに高めます。これらのテクニックに基づいて構築されたこの作品は、革新的なアプローチを示しています。研究チームは、ViT (Vision Transformer) と Qformer、および大規模な言語モデルを使用することで、マルチモーダル入力を生成投票に変換し、それらを高解像度の Stable Diffusion2.1 とシームレスに組み合わせて、コンテキストを意識した画像生成を実現しました。この論文は、補助入力としての画像を指示調整方法と組み合わせ、テキストと画像の生成ロスの使用を先駆的に行い、それによってテキストと視覚の相乗効果を拡大します。MiniGPT-5 は、CLIP 制約などのモデルと一致し、拡散モデルを MiniGPT-4 と巧みに統合して、ドメイン固有のアノテーションに依存することなく、より優れたマルチモーダルな結果を実現します。最も重要なことは、私たちの戦略はマルチモーダル視覚言語の基本モデルの進歩を活用し、マルチモーダル生成機能を強化するための新しい青写真を提供できることです。以下の図に示すように、MiniGPT5 は、本来のマルチモーダル理解機能とテキスト生成機能に加えて、合理的で一貫したマルチモーダル出力も提供できます。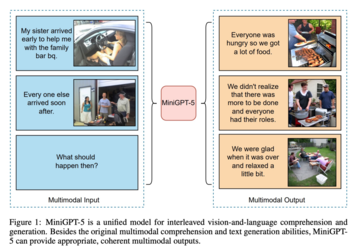 この記事の貢献は次の 3 つの側面に反映されています。* 新しい汎用技術であり、LLM や逆生成 Voken より効果的であることが証明されているマルチモーダル エンコーダーを使用し、安定拡散と組み合わせて、インターリーブされたビジュアル出力と言語出力を生成することをお勧めします (マルチモーダルマルチモーダル生成が可能な言語モデル)。* 説明不要のマルチモーダル生成のための新しい 2 段階のトレーニング戦略を強調します。シングルモーダル位置合わせステージは、多数のテキストと画像のペアから高品質のテキスト位置合わせされた視覚特徴を取得します。マルチモーダル学習フェーズには、新しいトレーニング タスク、コンテキスト生成が含まれており、ビジョンとテキストを適切に調整して生成できるようにします。トレーニング段階で分類子を使用しないガイダンスを追加すると、生成の品質がさらに向上します。* 他のマルチモーダル生成モデルと比較して、MiniGPT-5 は CC3M データセット上で最先端のパフォーマンスを実現します。 MiniGPT-5 は、VIST や MMDialog などの有名なデータセットに対する新しいベンチマークも確立しました。次に、研究の詳細を見てみましょう。## **方法の概要**大規模言語モデルにマルチモーダル生成機能を持たせるために、研究者らは、事前トレーニングされたマルチモーダル大規模言語モデルとテキストから画像への生成モデルを統合する構造化フレームワークを導入しました。異なるモデルフィールド間の差異を解決するために、彼らは、元の画像上で直接トレーニングできる特別な視覚シンボル「生成投票」(生成投票)を導入しました。さらに、生成品質をさらに向上させるために、分類子を使用しないブートストラップ戦略と組み合わせた 2 段階のトレーニング方法が進歩しています。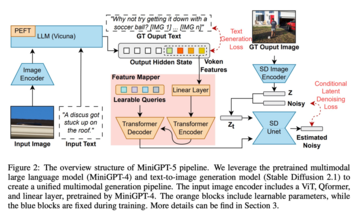 **マルチモーダル入力ステージ**マルチモーダル大規模モデル (MiniGPT-4 など) の最近の進歩は、画像を連続入力として処理できるマルチモーダルの理解に主に焦点を当てています。その機能をマルチモーダル生成に拡張するために、研究者は、視覚的特徴を出力するために特別に設計された生成 Voken を導入しました。さらに、マルチモーダル出力学習のための大規模言語モデル (LLM) フレームワーク内で、パラメーター効率の高い微調整手法も採用しました。**マルチモーダル出力生成**生成トークンを生成モデルと正確に位置合わせするために、次元マッチングのためのコンパクトなマッピング モジュールを定式化し、テキスト空間損失や潜在拡散モデル損失を含むいくつかの教師あり損失を組み込みます。テキストスペースの損失はモデルがトークンの正しい位置を学習するのに役立ちますが、潜在的な拡散損失はトークンを適切な視覚的特徴と直接位置合わせします。生成記号の特徴が画像によって直接ガイドされるため、この方法では包括的な画像の説明が不要となり、説明不要の学習が可能になります。**トレーニング戦略**テキスト ドメインと画像ドメインの間に無視できないドメイン シフトがあることを考慮すると、研究者らは、限定されたインターリーブされたテキスト データセットと画像データセットを直接トレーニングすると、位置ずれや画質の低下が発生する可能性があることを発見しました。したがって、彼らはこの問題を軽減するために 2 つの異なるトレーニング戦略を採用しました。最初の戦略では、拡散プロセス全体を通じて生成されたトークンの有効性を向上させるために、分類子を使用しないブートストラップ手法を採用します。2 番目の戦略は、大まかな特徴の位置合わせに焦点を当てた最初の事前トレーニング フェーズと、それに続く微調整フェーズの 2 つのフェーズで展開されます。複雑な特徴の学習について。## **実験と結果**モデルの有効性を評価するために、研究者らは複数のベンチマークで一連の評価を実施しました。この実験は、いくつかの重要な質問に対処することを目的としています。* MiniGPT-5 は信頼できる画像と意味のあるテキストを生成できますか?* MiniGPT-5 は、シングルラウンドおよびマルチラウンドのインターリーブ視覚言語生成タスクにおいて、他の SOTA モデルと比較してどのように動作しますか?* 各モジュールの設計は全体的なパフォーマンスにどのような影響を与えますか?さまざまなトレーニング段階のさまざまなベンチマークでモデルのパフォーマンスを評価するために、MiniGPT-5 の定量分析サンプルを以下の図 3 に示します。 ここでの評価は、提案されたモデルの一般性と堅牢性を実証するために、視覚 (画像関連のメトリクス) と言語 (テキストのメトリクス) の両方の領域に及びます。## **VIST 最終段階の評価**最初の実験セットには、単一ステップの評価、つまり最後のステップでモデルに基づいて対応する画像を生成することが含まれており、その結果を表 1 に示します。MiniGPT-5 は、3 つの設定すべてにおいて、微調整された SD 2 よりも優れたパフォーマンスを発揮します。特に、MiniGPT-5 (LoRA) モデルの CLIP スコアは、特に画像とテキストを組み合わせた場合に、複数のタイプにわたって他のバリアントよりも一貫して優れています。一方、FID スコアは MiniGPT-5 (プレフィックス) モデルの競争力を強調しており、画像の埋め込み品質 (CLIP スコアに反映される) と画像の多様性と信頼性 (CLIP スコアに反映される) の間にトレードオフがある可能性があることを示しています。 FID スコア)。単一モダリティ登録ステージを含まずに VIST 上で直接トレーニングされたモデル (UAS なしの MiniGPT-5) と比較すると、モデルは意味のある画像を生成する能力を保持していますが、画像の品質と一貫性は大幅に低下します。この観察は、2 段階のトレーニング戦略の重要性を強調しています。 **VIST の複数段階の評価**より詳細かつ包括的な評価では、研究者らはモデルに以前の歴史的背景を体系的に提供し、その後、各ステップで得られた画像と物語を評価しました。表 2 と 3 は、これらの実験の結果をまとめたもので、それぞれ画像メトリクスと言語メトリクスのパフォーマンスをまとめています。実験結果は、MiniGPT-5 が、元のモデルのマルチモーダル理解能力に影響を与えることなく、すべてのデータに長水平マルチモーダル入力を使用してコヒーレントな高品質画像を生成できることを示しています。これは、さまざまな環境における MiniGPT-5 の有効性を強調しています。  **VIST 人間評価**表 4 に示すように、MiniGPT-5 は 57.18% のケースでより適切なテキスト ナラティブを生成し、52.06% のケースでより良い画質を提供し、57.62% のシーンでより一貫したマルチモードのステータス出力を生成しました。仮定法を使わずにテキストから画像へのナレーションを採用する 2 段階のベースラインと比較して、これらのデータは、その強力なマルチモーダル生成機能を明らかに示しています。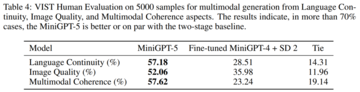 **MMDialog の複数ラウンドの評価**結果を表 5 に示します。MiniGPT-5 は、より正確なテキスト応答を生成する点で、ベースライン モデル Divter よりも優れています。生成された画像は同様の品質ですが、MiniGPT-5 は MM 相関においてベースライン モデルを上回っており、画像生成を適切に配置し、一貫性の高いマルチモーダル応答を生成する方法をよりよく学習できることを示しています。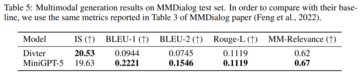 効果は何ですか? MiniGPT-5 の出力を見てみましょう。以下の図 7 は、MiniGPT-5 と CC3M 検証セットのベースライン モデルの比較を示しています。 以下の図 8 は、MiniGPT-5 と VIST 検証セットのベースライン モデルとの比較を示しています。 以下の図 9 は、MiniGPT-5 と MMDialog テスト セットのベースライン モデルとの比較を示しています。 研究の詳細については、元の論文を参照してください。
画像とテキストの生成を統合する MiniGPT-5 が登場しました。トークンは Voken になり、モデルは書き込みを続けるだけでなく、自動的に画像を追加することもできます。
大規模モデルは言語と視覚の間を飛躍させており、テキストと画像のコンテンツをシームレスに理解して生成することを約束しています。最近の一連の研究によると、マルチモーダル機能の統合は成長傾向であるだけでなく、すでにマルチモーダルな会話からコンテンツ作成ツールに至るまで重要な進歩をもたらしています。大規模な言語モデルは、テキストの理解と生成において比類のない機能を実証しています。ただし、一貫したテキストの物語を含む画像を同時に生成することは、まだ開発の余地がある領域です。
最近、カリフォルニア大学サンタクルーズ校の研究チームは、「生成投票」の概念に基づいた革新的なインターリーブ視覚言語生成技術である MiniGPT-5 を提案しました。
MiniGPT-5 は、特別なビジュアル トークン「生成投票」を通じて安定拡散メカニズムと LLM を組み合わせることで、熟練したマルチモーダル生成のための新しいモデルを予告します。同時に、この記事で提案されている 2 段階のトレーニング方法では、記述のない基本段階の重要性が強調され、データが不足している場合でもモデルが「成長」できるようになります。このメソッドの一般的なフェーズではドメイン固有のアノテーションが必要ないため、このソリューションは既存のメソッドとは異なります。生成されたテキストと画像が調和していることを保証するために、この論文の二重損失戦略が機能し、生成投票法と分類法がこの効果をさらに高めます。
これらのテクニックに基づいて構築されたこの作品は、革新的なアプローチを示しています。研究チームは、ViT (Vision Transformer) と Qformer、および大規模な言語モデルを使用することで、マルチモーダル入力を生成投票に変換し、それらを高解像度の Stable Diffusion2.1 とシームレスに組み合わせて、コンテキストを意識した画像生成を実現しました。この論文は、補助入力としての画像を指示調整方法と組み合わせ、テキストと画像の生成ロスの使用を先駆的に行い、それによってテキストと視覚の相乗効果を拡大します。
MiniGPT-5 は、CLIP 制約などのモデルと一致し、拡散モデルを MiniGPT-4 と巧みに統合して、ドメイン固有のアノテーションに依存することなく、より優れたマルチモーダルな結果を実現します。最も重要なことは、私たちの戦略はマルチモーダル視覚言語の基本モデルの進歩を活用し、マルチモーダル生成機能を強化するための新しい青写真を提供できることです。
以下の図に示すように、MiniGPT5 は、本来のマルチモーダル理解機能とテキスト生成機能に加えて、合理的で一貫したマルチモーダル出力も提供できます。
次に、研究の詳細を見てみましょう。
方法の概要
大規模言語モデルにマルチモーダル生成機能を持たせるために、研究者らは、事前トレーニングされたマルチモーダル大規模言語モデルとテキストから画像への生成モデルを統合する構造化フレームワークを導入しました。異なるモデルフィールド間の差異を解決するために、彼らは、元の画像上で直接トレーニングできる特別な視覚シンボル「生成投票」(生成投票)を導入しました。さらに、生成品質をさらに向上させるために、分類子を使用しないブートストラップ戦略と組み合わせた 2 段階のトレーニング方法が進歩しています。
マルチモーダル大規模モデル (MiniGPT-4 など) の最近の進歩は、画像を連続入力として処理できるマルチモーダルの理解に主に焦点を当てています。その機能をマルチモーダル生成に拡張するために、研究者は、視覚的特徴を出力するために特別に設計された生成 Voken を導入しました。さらに、マルチモーダル出力学習のための大規模言語モデル (LLM) フレームワーク内で、パラメーター効率の高い微調整手法も採用しました。
マルチモーダル出力生成
生成トークンを生成モデルと正確に位置合わせするために、次元マッチングのためのコンパクトなマッピング モジュールを定式化し、テキスト空間損失や潜在拡散モデル損失を含むいくつかの教師あり損失を組み込みます。テキストスペースの損失はモデルがトークンの正しい位置を学習するのに役立ちますが、潜在的な拡散損失はトークンを適切な視覚的特徴と直接位置合わせします。生成記号の特徴が画像によって直接ガイドされるため、この方法では包括的な画像の説明が不要となり、説明不要の学習が可能になります。
トレーニング戦略
テキスト ドメインと画像ドメインの間に無視できないドメイン シフトがあることを考慮すると、研究者らは、限定されたインターリーブされたテキスト データセットと画像データセットを直接トレーニングすると、位置ずれや画質の低下が発生する可能性があることを発見しました。
したがって、彼らはこの問題を軽減するために 2 つの異なるトレーニング戦略を採用しました。最初の戦略では、拡散プロセス全体を通じて生成されたトークンの有効性を向上させるために、分類子を使用しないブートストラップ手法を採用します。2 番目の戦略は、大まかな特徴の位置合わせに焦点を当てた最初の事前トレーニング フェーズと、それに続く微調整フェーズの 2 つのフェーズで展開されます。複雑な特徴の学習について。
実験と結果
モデルの有効性を評価するために、研究者らは複数のベンチマークで一連の評価を実施しました。この実験は、いくつかの重要な質問に対処することを目的としています。
さまざまなトレーニング段階のさまざまなベンチマークでモデルのパフォーマンスを評価するために、MiniGPT-5 の定量分析サンプルを以下の図 3 に示します。
VIST 最終段階の評価
最初の実験セットには、単一ステップの評価、つまり最後のステップでモデルに基づいて対応する画像を生成することが含まれており、その結果を表 1 に示します。
MiniGPT-5 は、3 つの設定すべてにおいて、微調整された SD 2 よりも優れたパフォーマンスを発揮します。特に、MiniGPT-5 (LoRA) モデルの CLIP スコアは、特に画像とテキストを組み合わせた場合に、複数のタイプにわたって他のバリアントよりも一貫して優れています。一方、FID スコアは MiniGPT-5 (プレフィックス) モデルの競争力を強調しており、画像の埋め込み品質 (CLIP スコアに反映される) と画像の多様性と信頼性 (CLIP スコアに反映される) の間にトレードオフがある可能性があることを示しています。 FID スコア)。単一モダリティ登録ステージを含まずに VIST 上で直接トレーニングされたモデル (UAS なしの MiniGPT-5) と比較すると、モデルは意味のある画像を生成する能力を保持していますが、画像の品質と一貫性は大幅に低下します。この観察は、2 段階のトレーニング戦略の重要性を強調しています。
より詳細かつ包括的な評価では、研究者らはモデルに以前の歴史的背景を体系的に提供し、その後、各ステップで得られた画像と物語を評価しました。
表 2 と 3 は、これらの実験の結果をまとめたもので、それぞれ画像メトリクスと言語メトリクスのパフォーマンスをまとめています。実験結果は、MiniGPT-5 が、元のモデルのマルチモーダル理解能力に影響を与えることなく、すべてのデータに長水平マルチモーダル入力を使用してコヒーレントな高品質画像を生成できることを示しています。これは、さまざまな環境における MiniGPT-5 の有効性を強調しています。
表 4 に示すように、MiniGPT-5 は 57.18% のケースでより適切なテキスト ナラティブを生成し、52.06% のケースでより良い画質を提供し、57.62% のシーンでより一貫したマルチモードのステータス出力を生成しました。仮定法を使わずにテキストから画像へのナレーションを採用する 2 段階のベースラインと比較して、これらのデータは、その強力なマルチモーダル生成機能を明らかに示しています。
結果を表 5 に示します。MiniGPT-5 は、より正確なテキスト応答を生成する点で、ベースライン モデル Divter よりも優れています。生成された画像は同様の品質ですが、MiniGPT-5 は MM 相関においてベースライン モデルを上回っており、画像生成を適切に配置し、一貫性の高いマルチモーダル応答を生成する方法をよりよく学習できることを示しています。