> 言語モデルは、視覚生成の点で拡散モデルに遅れをとっているのはなぜですか? Googleの調査によると、CMUはトークナイザーが鍵であることを示しています。 画像ソース:無制限のAIによって生成大規模な言語モデル(LLMまたはLM)は、言語を生成するために始まりましたが、時間の経過とともに複数のモダリティでコンテンツを生成できるようになり、オーディオ、音声、コード生成、医療アプリケーション、ロボット工学などで支配的になりました。もちろん、LMは画像やビデオを生成することもできます。 このプロセスでは、画像ピクセルがビジュアル トークナイザーによって一連の個別のトークンにマップされます。 これらのトークンはLMトランスフォーマーに供給され、語彙のように生成モデリングに使用されます。 LMは視覚生成において大きな進歩を遂げましたが、LMは依然として拡散モデルよりもパフォーマンスが劣ります。 たとえば、画像生成のゴールドベンチマークであるImageNetデータセットで評価した場合、最良の言語モデルは拡散モデルよりも48%も悪くなりました(FID 3.41対256解像度で画像を生成する場合は1.79)。言語モデルが視覚生成の点で拡散モデルに遅れをとっているのはなぜですか? Google、CMUの研究者は、主な理由は、視覚世界を効果的にモデル化するための、自然言語システムに似た優れた視覚的表現の欠如であると考えています。 この仮説を確認するために、彼らは研究を行いました。 論文リンク:この研究は、優れたビジュアルトークナイザーを使用すると、マスキング言語モデルは、同じトレーニングデータ、同等のモデルサイズ、およびトレーニング予算に対する画像とビデオのベンチマークの生成忠実度と効率の点でSOTA拡散モデルよりも優れていることを示しています。 これは、言語モデルが象徴的なImageNetベンチマークで拡散モデルに勝っているという最初の証拠です。研究者の目的は、言語モデルが他のモデルよりも優れているかどうかを主張することではなく、LLMの視覚的トークン化手法の探求を促進することであることを強調しておく必要があります。 LLMと拡散モデルなどの他のモデルとの根本的な違いは、LLMが離散潜在フォーマット、つまりトークナイザーの視覚化から得られるトークンを使用することです。 この研究は、これらの個別のビジュアルトークンの価値が、次の利点のために見逃してはならないことを示しています。 1. LLMとの互換性。 トークン表現の主な利点は、言語トークンと同じ形式を共有し、トレーニングと推論の高速化、モデル インフラストラクチャの進歩、モデルのスケーリング方法、GPU/TPU 最適化などのイノベーションなど、コミュニティが長年にわたって LLM を開発するために行ってきた最適化を直接利用できることです。 同じトークン空間を通じて視覚と言語を統合することで、視覚環境で理解、生成、推論できる真のマルチモーダルLLMの基礎を築くことができます。2.圧縮表現。 ディスクリートトークンは、ビデオ圧縮に関する新しい視点を提供できます。 ビジュアルトークンは、インターネットを介した送信中にデータが占有するディスクストレージと帯域幅を削減するための新しいビデオ圧縮形式として使用できます。 圧縮されたRGBピクセルとは異なり、これらのトークンは、従来の解凍や潜在的なエンコード手順をバイパスして、生成モデルに直接供給できます。 これにより、ビデオアプリケーションの構築処理を高速化でき、エッジコンピューティングシナリオで特に役立ちます。3.視覚的な理解の利点。 以前の研究では、BEiTとBEVTで説明されているように、離散トークンは自己教師あり表現学習の事前学習ターゲットとして価値があることが示されています。 さらに、この研究では、トークンをモデル入力として使用すると、堅牢性と一般化が向上することがわかりました。この論文では、研究者は、ビデオ(および画像)をコンパクトな離散トークンにマッピングすることを目的としたMAGVIT-v2と呼ばれるビデオトークナイザーを提案しています。このモデルは、VQ-VAEフレームワーク内のSOTAビデオトークナイザーであるMAGVITに基づいています。 これに基づいて、研究者は2つの新しい技術を提案します:1)言語モデル生成の質を向上させるために多数の単語を学習することを可能にする新しいルックアップフリー定量化方法。 2)広範な実証分析を通じて、ビルド品質を向上させるだけでなく、共有語彙を使用して画像やビデオをトークン化できるようにするMAGVITの変更を特定しました。実験結果は、新しいモデルが3つの主要な分野で以前の最高のパフォーマンスを発揮するビデオトークナイザーであるMAGVITよりも優れていることを示しています。 まず、新しいモデルはMAGVITのビルド品質を大幅に向上させ、一般的な画像とビデオのベンチマークでSOTAを更新します。 第二に、ユーザー調査によると、その圧縮品質はMAGTITおよび現在のビデオ圧縮規格HEVCの圧縮品質を超えています。 さらに、次世代のビデオコーデックVVCに匹敵します。 最後に、研究者は、新しいトークンがMAGVITと比較して、2つの設定と3つのデータセットを使用して、ビデオ理解タスクでより強力に機能することを示しました。## **メソッド紹介**本稿では、視覚シーンの時空間を言語モデルに適したコンパクトな離散トークンに動的にマッピングすることを目的とした新しいビデオトークナイザーを紹介します。 さらに、このメソッドはMAGVITに基づいています。次に、この調査では、ルックアップフリー量子化(LFQ)とトークナイザーモデルの機能強化という2つの新しい設計が強調されました。**ルックアップ量子化なし**近年、VQ-VAEモデルが大きく進歩したが、再構成品質の向上とその後の世代品質との関係が明確でないのが欠点である。 多くの人々は、再構成を改善することは言語モデルの生成を改善することと同等であると誤って考えており、例えば、語彙を増やすことは再構成の質を向上させることができます。 ただし、この改善は小さな語彙の生成にのみ適用され、語彙が非常に大きい場合、言語モデルのパフォーマンスが低下する可能性があります。この記事では、VQ-VAEコードブックの埋め込みディメンションをコードブックである0に減らします 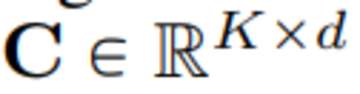 は整数のセットに置き換えられます そこに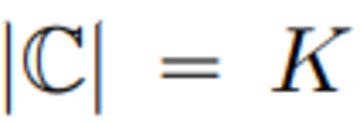 。VQ-VAEモデルとは異なり、この新しい設計では、埋め込みルックアップの必要性が完全に排除されるため、LFQという名前が付けられています。 本論文では、LFQが語彙を増やすことで言語モデル生成の質を向上させることができることを見出しました。 図1の青い曲線が示すように、語彙が増えると再構成と生成の両方が改善され、現在のVQ-VAEアプローチでは見られない特徴です。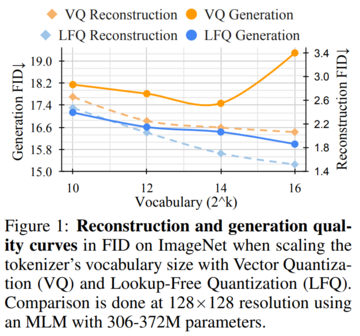 これまでのところ、多くのLFQメソッドを使用できますが、この記事では単純なバリアントについて説明します。 具体的には、LFQの潜在空間は、1次元変数のデカルト積、すなわち 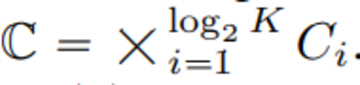 。 特徴ベクトルが与えられたとします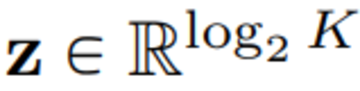 は、以下から得られるq(z)の各次元を定量的に表す。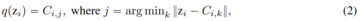 LFQ の場合、q (z) のトークンインデックスは次のようになります。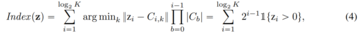 さらに、この記事では、トレーニング中のエントロピーペナルティも追加します。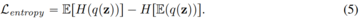 **ビジュアル トークナイザー モデルの改善** フェデレーション イメージ - ビデオのトークン化。 フェデレーテッド イメージ ビデオ トークナイザーを構築するには、新しい設計が必要です。 この記事では、3D CNNが空間トランスフォーマーよりも優れたパフォーマンスを発揮することがわかりました。このホワイトペーパーでは、C-ViViTとMAGVITを組み合わせた図2bなど、2つの可能な設計オプションについて説明します。 図2cは、通常の3D CNNの代わりに時間的因果3D畳み込みを使用しています。 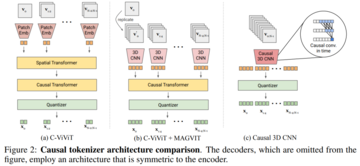 表5aは、図2の設計を経験的に比較し、因果関係のある3D CNNが最高のパフォーマンスを発揮することを示しています。 因果関係のある3D CNNレイヤーの使用に加えて、エンコーダーダウンサンプラーを平均プーリングからステップ畳み込みに変更するなど、MAGVITパフォーマンスを向上させるために他のアーキテクチャ上の変更が行われました。 別の例として、デコーダーの各解像度の残差ブロックの前に適応型グループ正規化レイヤーを追加します。## **実験結果**実験では、この論文で提案されているトークナイザーの性能を、ビデオと画像の生成、ビデオ圧縮、モーション認識の3つの部分から検証します。 図 3 は、トークナイザーの結果を以前の研究と視覚的に比較したものです。 ビデオ生成。 表1は、このモデルが両方のベンチマークですべての先行技術を凌駕していることを示しており、優れたビジュアルトークナイザーがLMが高品質のビデオを作成できるようにする上で重要な役割を果たすことを示しています。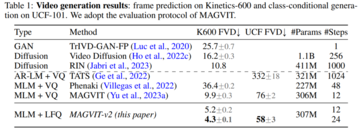 図4は、モデルの定性的サンプルを示しています。 画像生成。 本稿では,MAGVIT-v2の画像生成結果をImageNetクラスの標準条件設定で評価する. 結果は、提案されたモデルが、サンプリング品質(IDおよびIS)および推論時間効率(サンプリングステップ)の点で、最もパフォーマンスの高い拡散モデルよりも優れていることを示しています。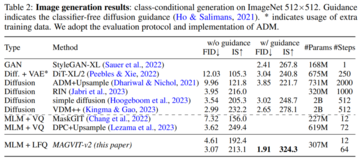 図 5 に、この視覚化を示します。 ビデオ圧縮。 結果を表3に示し、モデルはすべてのメトリックでMAGVITを上回り、LPIPSですべての方法よりも優れています。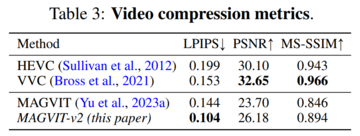 ビデオの理解。 表4に示すように、MAGVIT-v2は、これらの評価において以前の最高のMAGVITを上回っています。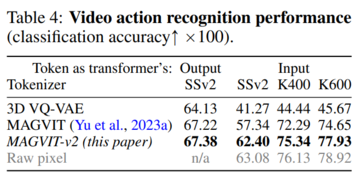
画像とビデオの生成では、言語モデルが初めて拡散モデルを打ち負かし、トークナイザーが鍵となります
大規模な言語モデル(LLMまたはLM)は、言語を生成するために始まりましたが、時間の経過とともに複数のモダリティでコンテンツを生成できるようになり、オーディオ、音声、コード生成、医療アプリケーション、ロボット工学などで支配的になりました。
もちろん、LMは画像やビデオを生成することもできます。 このプロセスでは、画像ピクセルがビジュアル トークナイザーによって一連の個別のトークンにマップされます。 これらのトークンはLMトランスフォーマーに供給され、語彙のように生成モデリングに使用されます。 LMは視覚生成において大きな進歩を遂げましたが、LMは依然として拡散モデルよりもパフォーマンスが劣ります。 たとえば、画像生成のゴールドベンチマークであるImageNetデータセットで評価した場合、最良の言語モデルは拡散モデルよりも48%も悪くなりました(FID 3.41対256解像度で画像を生成する場合は1.79)。
言語モデルが視覚生成の点で拡散モデルに遅れをとっているのはなぜですか? Google、CMUの研究者は、主な理由は、視覚世界を効果的にモデル化するための、自然言語システムに似た優れた視覚的表現の欠如であると考えています。 この仮説を確認するために、彼らは研究を行いました。
この研究は、優れたビジュアルトークナイザーを使用すると、マスキング言語モデルは、同じトレーニングデータ、同等のモデルサイズ、およびトレーニング予算に対する画像とビデオのベンチマークの生成忠実度と効率の点でSOTA拡散モデルよりも優れていることを示しています。 これは、言語モデルが象徴的なImageNetベンチマークで拡散モデルに勝っているという最初の証拠です。
研究者の目的は、言語モデルが他のモデルよりも優れているかどうかを主張することではなく、LLMの視覚的トークン化手法の探求を促進することであることを強調しておく必要があります。 LLMと拡散モデルなどの他のモデルとの根本的な違いは、LLMが離散潜在フォーマット、つまりトークナイザーの視覚化から得られるトークンを使用することです。 この研究は、これらの個別のビジュアルトークンの価値が、次の利点のために見逃してはならないことを示しています。
2.圧縮表現。 ディスクリートトークンは、ビデオ圧縮に関する新しい視点を提供できます。 ビジュアルトークンは、インターネットを介した送信中にデータが占有するディスクストレージと帯域幅を削減するための新しいビデオ圧縮形式として使用できます。 圧縮されたRGBピクセルとは異なり、これらのトークンは、従来の解凍や潜在的なエンコード手順をバイパスして、生成モデルに直接供給できます。 これにより、ビデオアプリケーションの構築処理を高速化でき、エッジコンピューティングシナリオで特に役立ちます。
3.視覚的な理解の利点。 以前の研究では、BEiTとBEVTで説明されているように、離散トークンは自己教師あり表現学習の事前学習ターゲットとして価値があることが示されています。 さらに、この研究では、トークンをモデル入力として使用すると、堅牢性と一般化が向上することがわかりました。
この論文では、研究者は、ビデオ(および画像)をコンパクトな離散トークンにマッピングすることを目的としたMAGVIT-v2と呼ばれるビデオトークナイザーを提案しています。
このモデルは、VQ-VAEフレームワーク内のSOTAビデオトークナイザーであるMAGVITに基づいています。 これに基づいて、研究者は2つの新しい技術を提案します:1)言語モデル生成の質を向上させるために多数の単語を学習することを可能にする新しいルックアップフリー定量化方法。 2)広範な実証分析を通じて、ビルド品質を向上させるだけでなく、共有語彙を使用して画像やビデオをトークン化できるようにするMAGVITの変更を特定しました。
実験結果は、新しいモデルが3つの主要な分野で以前の最高のパフォーマンスを発揮するビデオトークナイザーであるMAGVITよりも優れていることを示しています。 まず、新しいモデルはMAGVITのビルド品質を大幅に向上させ、一般的な画像とビデオのベンチマークでSOTAを更新します。 第二に、ユーザー調査によると、その圧縮品質はMAGTITおよび現在のビデオ圧縮規格HEVCの圧縮品質を超えています。 さらに、次世代のビデオコーデックVVCに匹敵します。 最後に、研究者は、新しいトークンがMAGVITと比較して、2つの設定と3つのデータセットを使用して、ビデオ理解タスクでより強力に機能することを示しました。
メソッド紹介
本稿では、視覚シーンの時空間を言語モデルに適したコンパクトな離散トークンに動的にマッピングすることを目的とした新しいビデオトークナイザーを紹介します。 さらに、このメソッドはMAGVITに基づいています。
次に、この調査では、ルックアップフリー量子化(LFQ)とトークナイザーモデルの機能強化という2つの新しい設計が強調されました。
ルックアップ量子化なし
近年、VQ-VAEモデルが大きく進歩したが、再構成品質の向上とその後の世代品質との関係が明確でないのが欠点である。 多くの人々は、再構成を改善することは言語モデルの生成を改善することと同等であると誤って考えており、例えば、語彙を増やすことは再構成の質を向上させることができます。 ただし、この改善は小さな語彙の生成にのみ適用され、語彙が非常に大きい場合、言語モデルのパフォーマンスが低下する可能性があります。
この記事では、VQ-VAEコードブックの埋め込みディメンションをコードブックである0に減らします
VQ-VAEモデルとは異なり、この新しい設計では、埋め込みルックアップの必要性が完全に排除されるため、LFQという名前が付けられています。 本論文では、LFQが語彙を増やすことで言語モデル生成の質を向上させることができることを見出しました。 図1の青い曲線が示すように、語彙が増えると再構成と生成の両方が改善され、現在のVQ-VAEアプローチでは見られない特徴です。
フェデレーション イメージ - ビデオのトークン化。 フェデレーテッド イメージ ビデオ トークナイザーを構築するには、新しい設計が必要です。 この記事では、3D CNNが空間トランスフォーマーよりも優れたパフォーマンスを発揮することがわかりました。
このホワイトペーパーでは、C-ViViTとMAGVITを組み合わせた図2bなど、2つの可能な設計オプションについて説明します。 図2cは、通常の3D CNNの代わりに時間的因果3D畳み込みを使用しています。
実験結果
実験では、この論文で提案されているトークナイザーの性能を、ビデオと画像の生成、ビデオ圧縮、モーション認識の3つの部分から検証します。 図 3 は、トークナイザーの結果を以前の研究と視覚的に比較したものです。