 画像ソース:無制限のAIによって生成途中で失われ、モデルは怠惰であり、コンテキストが長いほど、モデルは愚かになります... 大規模な言語モデル製品を経験した場合、ユーザーは、大規模なモデルで少し長いコンテンツを議論したい場合、入力を分割する必要があり、以前の入力の要点が大規模なモデルによってすぐに忘れられるなど、テキスト入力の長さの制限をある程度感じるでしょう。これは典型的な大きな言語モデルの対話の欠陥です! 注意欠陥を持って生まれた子供たちのように、新しい本を完成させることに集中することは困難です。 欠陥の鍵は、モデルに長いテキスト処理機能がないことです。 それは今壊れています。最近、Jia JiayaのチームとMITによってリリースされた新しいテクノロジーと新しいモデルは、主要なオープンソースWebサイトのホットリストに静かに登場しました:最初に顔のホットリストを抱きしめ、最初にpaperwithcodeホット、Githubオールパイソンプロジェクトホット5番目、GitHubスターは1,000週間で1,000を超え、Twitterの関連する技術投稿は180,000近く閲覧されました... GitHub Stars が 1.3K に達しました Twitterの関連技術投稿は、約180,000ビューを獲得しましたLongLoRAと呼ばれるテクノロジーは実用的ですが、驚くほどシンプルです:わずか2行のコードと8枚のカードA100マシンで、7Bモデルのテキスト長を100kトークンに拡張でき、70Bモデルのテキスト長を32kトークンに拡張できます。 同時に、研究チームは、70Bパラメータを備えた最初のロングテキスト対話大言語モデルであるLongAlpacaもリリースしました。**世界初の70B長文ラージ言語モデルをリリース**LongLoRAの提案は、グローバルな大規模言語モデルの対話の欠陥を初めて解決し、それ以来、数十ページの論文、数百ページのレポート、および巨大な本は、もはや大規模モデルの盲点にはなりませんでした。この点で、一部の専門家は、LongLoRAは大規模な言語モデルの迷路における希望のランプであると興奮して言いました! これは、長いテキストの大規模言語モデルに対する業界の再考と注意を表し、大規模な言語モデルのコンテキストウィンドウを効果的に拡張し、モデルが長いテキストシーケンスを検討および処理できるようにし、大規模な言語モデルの革新的な発明です。 技術革新に加えて、長いテキストの問題に対処する上での大規模な言語モデルの難しさの1つは、公開されている長いテキストの対話データの欠如です。この目的のために、研究チームは、有名な本、論文、詳細なレポート、さらには財務諸表に関するさまざまなQ&Aを含む、9Kの長いテキストのQ&Aコーパスペアを特別に収集しました。長い質問に答えるだけでは不十分で、チームはトレーニング用に3Kの短い質問と回答のコーパスと9Kの長い質問と回答のコーパスを混合して選択したため、長いテキストの大規模なモデルには短いテキストの対話機能を同時に備えました。 LongAlpaca-12kと呼ばれるこの完全なデータセットは、現在オープンソースです。LongAlpaca-12kデータセットに基づいて、研究チームは、さまざまなパラメータサイズ7B、13B、70B、およびLongAlpaca-7B、LongAlpaca-13B、LongAlpaca-70Bなどのオープンソースモデルをトレーニングおよび評価しました。 ## **小説を読んだり、紙を変えたり、経済を指摘したりすることは万能の王様です** さらに面倒なことはせずに、いくつかのデモを盲目的に選択して、LongLoRAテクノロジーを適用した大規模モデルのLongAlpaca効果を12Kの質問と回答のコーパスに重ね合わせます。让系统新读一篇论文,并根据ICLR的审查指南,对其提出修改意见,从而提升该论文的接收率。LongAlpaca的意见是:通过更精确地阐明新颖性,提供更严格和更有对比性的实验结果(包括具体的数据集和指标) 、より広いアプリケーションと将来の方向性、主要な貢献と影響に焦点を当て、論文が受け入れられる可能性が向上します。 さて、システムに2つの異なる論文を読んでもらい、LongAlpacaにICLR会議とCVPR会議の文体の違いを要約させましょう。 LongAlpacaは、CVPRの論文は、実用性と専門性に焦点を当てた、より構造化された実験的である傾向があると結論付けています。 一方、ICLRのエッセイスタイルはより柔軟で、標準的な形式ではなく、主要な理論分析と数学的導出に焦点を当てています。トレーニングされたLongAlpacaモデルは、新しい長い形式の学術論文を簡単に受け入れることができ、学術的に関連する質問に答えるのに非常に正確であることがわかります。次に、読書と理解の敷居が高い経済分野におけるLongAlpacaモデルの解釈を見てみましょう。  IMFが2012年から2023年までの世界経済見通しの概要集をもとに、年ごとの経済状況をまとめ、将来の経済動向を予測しています。 LongAlpacaは、2023年の世界経済状況は不確実であり、2022年と比較して成長が鈍化すると予想されていると語った。 今後数年間、世界経済の拡大は緩やかで予想を下回る一方で、地政学的緊張や金融市場のボラティリティなどの主要な課題は残っており、多国間協力や構造改革を通じて慎重に対処する必要があります。LongAlpacaは、新しい小説を読み、読んだ後に内容を分析することもできます。 以下で選択した比較モデルは、13Bパラメータを持つLongAlpacaとLlama2であり、それぞれのパフォーマンスを調べています。 有名な本「西への旅」では、孫悟空が天宮でトラブルを起こしたときに非常に強力であるのに、経典を入手する途中で繰り返し欲求不満になっているのはなぜですか? LongAlpacaは5つの理由を挙げましたが、これは大まかに「モンキーキングの未熟さ、強い敵、限られた強さ、敵の欺瞞、最初の仲間の不足、その他の要因が旅の失敗につながった」と要約できます。 しかし、時間が経つにつれて、彼は知恵、経験、そして仲間を獲得し、それによって彼は彼の最も手ごわい敵を倒すことができました。 "Llama2の答えはもっと簡単です。 「彼は天の宮殿について大騒ぎしますが、彼が無敗の力を代表していると言うのは必ずしも正確ではありません。 実際、彼は最終的に西遊記で強力な唐三蔵に敗れました。 Llama2は正しい答えを出さず、より多くのコンテンツ情報の必要性も提起しました。 今回は、システムに「三体問題」をもう一度読んでもらい、イェ・ウェンジエが最初の部分でエイリアンに連絡した理由と、後の段階で後悔した理由を尋ねます。 ロングアルパカは、イェウェンジエのエイリアンとの最初の接触は理想主義と復讐によって動機付けられたと信じていますが、時間の経過とともに、彼女の人間観は変化し、彼女がすべての人類にもたらす可能性のある危険を認識し、彼女の後悔は日々高まっています。 答えは非常に明確でした。Llama2の答えは、「エイリアンとの交流を通じて、彼女は宇宙の性質とその中での自分の位置をより深く理解したいと考えています」でした。 Ye Wenjieは、エイリアンとその技術が彼女の問題を解決できないことに徐々に気づきました。 答えは一般的でした、そしてそれから彼は非質問に答えて、全体として小説についてコメントし始めました。モデルによって与えられた答えから、Llama2のようないくつかのモデルが [2] 事前トレーニングプロセス中に小説を見たことがあるかもしれませんが、小説のトピックのみに基づいて短いテキストの質問をする場合、答えは理想的ではありません。2つのモデルの答えは対照的であり、高値と安値は高い値です。 LongAlpacaは、学術論文の変更、世界経済の動向に関するコメント、小説の読書が得意で、Llama2を打ち負かしています。 ## **2 行のコードと 3 つの重要な結論** Llama2は間違いなくAIコミュニティで最も強力なオープンソースモデルの1つであり、業界をリードしており、LongAlpacaは実際に勝つことができます。 その背後にあるLongLoRAテクノロジーは、ネチズンの注目を集めることに成功しましたが、どのようにそれを行いましたか?大規模な言語モデルで長いテキストを処理するプロセスでは、計算の主なコストは自己注意メカニズムに集中し、そのオーバーヘッドはテキストの長さの2乗で増加します。この問題に対して、研究チームはLongLoRA技術を提案し、グループ化とオフセットによってグローバルな自己注意メカニズムをシミュレートしました。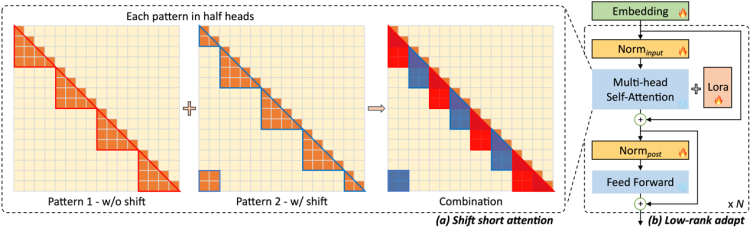 簡単に言えば、長いテキストに対応するトークンを異なるグループに分割し、各グループ内で自己注意の計算を行い、グループ化の方法を異なる注意ヘッドからオフセットすることです。 この方法は、計算量を大幅に節約できるだけでなく、グローバルな受容フィールドの送信を維持することもできます。また、この実装方法も非常に簡潔で、2行のコードしか完了できません。 [5]LongLoRAは、低ランクでトレーニングする方法も模索しています。 オリジナルの低ランクトレーニング方法, LoRAなど は、テキスト長の移行で良好な結果を達成しません。 LongLoRAは、低ランクのトレーニングに基づいて、微調整用の埋め込みレイヤー(埋め込みレイヤーと正規化レイヤー)を導入し、完全な微調整の効果を実現します。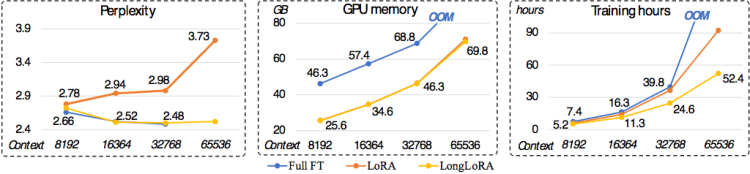 さまざまな長さのテキスト拡張とトレーニングを実行する場合, LongLoRAの特定の効果, LoRAとすべてのパラメーターの微調整手法は、3次元で参照できます:パープレキシティ-パープレキシティに関しては、元のLoRAメソッドのパフォーマンスが低下していますが、LongLoRAとすべてのパラメーターの微調整は、さまざまなテキスト長で良好な結果を維持できます。メモリ消費の面では, LongLoRAと元のLoRAは、フルパラメーターの微調整と比較して大幅な節約になります. たとえば、長さが8kのモデルトレーニングの場合、LongLoRAは、フルパラメーターの微調整と比較して、メモリ消費量を46.3GBから25.6GBに削減します。トレーニング時間に関しては、64kの長さのモデルトレーニングの場合、従来のLoRAと比較して、LongLoRAはトレーニング時間を約90~100時間から52.4時間に短縮し、フルパラメータの微調整は1000時間を超えます。最小限のトレーニング方法、最小限のコンピューティングリソースと時間の消費、および優れた精度により、LongLoRAは大規模に可能になります。 現在、関連するテクノロジーとモデルはすべてオープンソースであり、関心のあるユーザーは独自のエクスペリエンスを展開できます。これは、8月9日にリリースされた「すべてを分割できる」マルチモーダル大型モデルLISAに続くジャジャヤチームのもう一つの傑作であることは言及する価値があります。 わずか2か月の間隔で、この研究のスピードと能力はLongLoRAと同じくらい素晴らしいと言わざるを得ません。
大規模な言語モデルダイアログの制限を解決するための2行のコード! 香港中国語Jia JiayaのチームとMITは、超長文拡張技術をリリースしました
途中で失われ、モデルは怠惰であり、コンテキストが長いほど、モデルは愚かになります... 大規模な言語モデル製品を経験した場合、ユーザーは、大規模なモデルで少し長いコンテンツを議論したい場合、入力を分割する必要があり、以前の入力の要点が大規模なモデルによってすぐに忘れられるなど、テキスト入力の長さの制限をある程度感じるでしょう。
これは典型的な大きな言語モデルの対話の欠陥です! 注意欠陥を持って生まれた子供たちのように、新しい本を完成させることに集中することは困難です。 欠陥の鍵は、モデルに長いテキスト処理機能がないことです。 それは今壊れています。
最近、Jia JiayaのチームとMITによってリリースされた新しいテクノロジーと新しいモデルは、主要なオープンソースWebサイトのホットリストに静かに登場しました:最初に顔のホットリストを抱きしめ、最初にpaperwithcodeホット、Githubオールパイソンプロジェクトホット5番目、GitHubスターは1,000週間で1,000を超え、Twitterの関連する技術投稿は180,000近く閲覧されました...
LongLoRAと呼ばれるテクノロジーは実用的ですが、驚くほどシンプルです:わずか2行のコードと8枚のカードA100マシンで、7Bモデルのテキスト長を100kトークンに拡張でき、70Bモデルのテキスト長を32kトークンに拡張できます。 同時に、研究チームは、70Bパラメータを備えた最初のロングテキスト対話大言語モデルであるLongAlpacaもリリースしました。
世界初の70B長文ラージ言語モデルをリリース
LongLoRAの提案は、グローバルな大規模言語モデルの対話の欠陥を初めて解決し、それ以来、数十ページの論文、数百ページのレポート、および巨大な本は、もはや大規模モデルの盲点にはなりませんでした。
この点で、一部の専門家は、LongLoRAは大規模な言語モデルの迷路における希望のランプであると興奮して言いました! これは、長いテキストの大規模言語モデルに対する業界の再考と注意を表し、大規模な言語モデルのコンテキストウィンドウを効果的に拡張し、モデルが長いテキストシーケンスを検討および処理できるようにし、大規模な言語モデルの革新的な発明です。
この目的のために、研究チームは、有名な本、論文、詳細なレポート、さらには財務諸表に関するさまざまなQ&Aを含む、9Kの長いテキストのQ&Aコーパスペアを特別に収集しました。
長い質問に答えるだけでは不十分で、チームはトレーニング用に3Kの短い質問と回答のコーパスと9Kの長い質問と回答のコーパスを混合して選択したため、長いテキストの大規模なモデルには短いテキストの対話機能を同時に備えました。 LongAlpaca-12kと呼ばれるこの完全なデータセットは、現在オープンソースです。
LongAlpaca-12kデータセットに基づいて、研究チームは、さまざまなパラメータサイズ7B、13B、70B、およびLongAlpaca-7B、LongAlpaca-13B、LongAlpaca-70Bなどのオープンソースモデルをトレーニングおよび評価しました。
小説を読んだり、紙を変えたり、経済を指摘したりすることは万能の王様です
さらに面倒なことはせずに、いくつかのデモを盲目的に選択して、LongLoRAテクノロジーを適用した大規模モデルのLongAlpaca効果を12Kの質問と回答のコーパスに重ね合わせます。
トレーニングされたLongAlpacaモデルは、新しい長い形式の学術論文を簡単に受け入れることができ、学術的に関連する質問に答えるのに非常に正確であることがわかります。
次に、読書と理解の敷居が高い経済分野におけるLongAlpacaモデルの解釈を見てみましょう。
LongAlpacaは、新しい小説を読み、読んだ後に内容を分析することもできます。 以下で選択した比較モデルは、13Bパラメータを持つLongAlpacaとLlama2であり、それぞれのパフォーマンスを調べています。
Llama2の答えはもっと簡単です。 「彼は天の宮殿について大騒ぎしますが、彼が無敗の力を代表していると言うのは必ずしも正確ではありません。 実際、彼は最終的に西遊記で強力な唐三蔵に敗れました。 Llama2は正しい答えを出さず、より多くのコンテンツ情報の必要性も提起しました。
Llama2の答えは、「エイリアンとの交流を通じて、彼女は宇宙の性質とその中での自分の位置をより深く理解したいと考えています」でした。 Ye Wenjieは、エイリアンとその技術が彼女の問題を解決できないことに徐々に気づきました。 答えは一般的でした、そしてそれから彼は非質問に答えて、全体として小説についてコメントし始めました。
モデルによって与えられた答えから、Llama2のようないくつかのモデルが [2] 事前トレーニングプロセス中に小説を見たことがあるかもしれませんが、小説のトピックのみに基づいて短いテキストの質問をする場合、答えは理想的ではありません。
2つのモデルの答えは対照的であり、高値と安値は高い値です。 LongAlpacaは、学術論文の変更、世界経済の動向に関するコメント、小説の読書が得意で、Llama2を打ち負かしています。
2 行のコードと 3 つの重要な結論
Llama2は間違いなくAIコミュニティで最も強力なオープンソースモデルの1つであり、業界をリードしており、LongAlpacaは実際に勝つことができます。 その背後にあるLongLoRAテクノロジーは、ネチズンの注目を集めることに成功しましたが、どのようにそれを行いましたか?
大規模な言語モデルで長いテキストを処理するプロセスでは、計算の主なコストは自己注意メカニズムに集中し、そのオーバーヘッドはテキストの長さの2乗で増加します。
この問題に対して、研究チームはLongLoRA技術を提案し、グループ化とオフセットによってグローバルな自己注意メカニズムをシミュレートしました。
また、この実装方法も非常に簡潔で、2行のコードしか完了できません。
パープレキシティ-パープレキシティに関しては、元のLoRAメソッドのパフォーマンスが低下していますが、LongLoRAとすべてのパラメーターの微調整は、さまざまなテキスト長で良好な結果を維持できます。
メモリ消費の面では, LongLoRAと元のLoRAは、フルパラメーターの微調整と比較して大幅な節約になります. たとえば、長さが8kのモデルトレーニングの場合、LongLoRAは、フルパラメーターの微調整と比較して、メモリ消費量を46.3GBから25.6GBに削減します。
トレーニング時間に関しては、64kの長さのモデルトレーニングの場合、従来のLoRAと比較して、LongLoRAはトレーニング時間を約90~100時間から52.4時間に短縮し、フルパラメータの微調整は1000時間を超えます。
最小限のトレーニング方法、最小限のコンピューティングリソースと時間の消費、および優れた精度により、LongLoRAは大規模に可能になります。 現在、関連するテクノロジーとモデルはすべてオープンソースであり、関心のあるユーザーは独自のエクスペリエンスを展開できます。
これは、8月9日にリリースされた「すべてを分割できる」マルチモーダル大型モデルLISAに続くジャジャヤチームのもう一つの傑作であることは言及する価値があります。 わずか2か月の間隔で、この研究のスピードと能力はLongLoRAと同じくらい素晴らしいと言わざるを得ません。