**著者:ジンレイ**ソース: 量子ビットオープンソースの世界で最強の中国語と英語のバイリンガルモデル、Wudao Skyhawk 34Bがここにあります!それはどれくらい強いですか? 一言で言えば:中国語と英語の総合能力、論理的推論能力などは、Llama2-70Bと以前のすべてのオープンソースモデルを包括的に上回ります!推論能力の面では、対話モデルのIRD評価ベンチマークはGPT4に次ぐものです。モデルは戦うのに十分な大きさであるだけでなく、「ファミリーバレル」レベルの高級周辺機器の完全なセットを一度に送信します。このような大きな問題を抱えることができるのは、中国の大規模モデルオープンソーススクールであるKLCII研究所のパイオニアです。KLCIIの長年にわたる大規模モデルのオープンソースアプローチを見ると、それが新しいトレンドをリードしていることを見つけるのは難しくありません。早くも2021年に世界最大のコーパスが公開され、2022年にはFlagOpen大規模モデルテクノロジーオープンソースシステムを最初に転送し、Flag評価システム、COIGデータセット、BGEベクターモデル、その他のフルテクノロジースタックスタープロジェクトを次々と立ち上げました。この大胆さは、KLCIIが非営利、非営利、中立の研究機関として位置付けていることから来ており、その主な焦点は「誠実なオープンソースの共創」です。Aquila2-34Bペデスタルモデルは、言語、理解、推論、コード、試験、その他の評価次元を含む22の評価ベンチマークの包括的なランキングをリードしていると理解されています。この気持ちを感じるための写真は次のとおりです。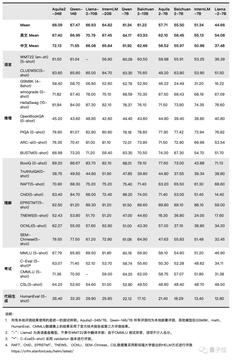 *△図:ベースモデルの評価結果(詳細なデータセット評価結果については、公式のオープンソースリポジトリを参照してください)*今述べたように、北京KLCII人工知能研究所も非常に誠実にオープンソースを最後まで実装し、オープンソースを家族全員に一度に提供します。Aquila2モデルシリーズを完全にアップグレードします:Aquila2-34B / 7B基本モデル、AquilaChat2-34B / 7Bダイアログモデル、AquilaSQL「テキストSQL言語」モデル。セマンティックベクターモデルBGEの新しいバージョンがアップグレードされ、4つの主要な検索要件がすべてカバーされています。FlagScaleの効率的な並列トレーニングフレームワーク:業界をリードするトレーニングスループットとGPU使用率。FlagAttention 高性能アテンションサブセット:ロングテキストトレーニングとトリトン言語の革新的なサポート。次に、今回は「最強のオープンソース」について詳しく見ていきましょう。 ## 「最強のオープンソース」機能の概要 先ほど述べたように、「最強のオープンソース」ポーズで開いた台座モデルの1つであるAquila2-34Bには、より小さなAquila2-7Bも含まれています。そして、これら2つの到着はまた、ダウンストリームモデルを非常に有益にします。**最強のオープンソース対話モデル**命令を微調整した後、優れたAquilaChat2ダイアログモデルシリーズが得られました。AquilaChat2-34B:これは、主観的+客観的な包括的な評価をリードする、最強のオープンソースの中国語と英語のバイリンガル対話モデルです。AquilaChat2-7B:同じ規模の中国語-英語対話モデルで最高の全体的なパフォーマンスパフォーマンスも達成しました。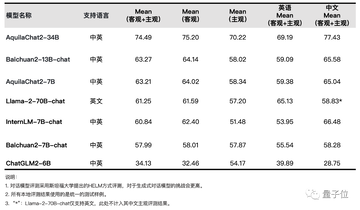 *△ SFTモデルの評価結果(詳細なデータセット評価結果については、公式のオープンソースリポジトリを参照してください)*レビューの説明:生成対話モデルについては、KLCIIチームは、ユーザーの実際のユースケースに近い「質問入力下で自由に生成されたモデルの回答」に従って厳密に判断する必要があると考えていますので、スタンフォード大学のHELMを参照してください[1] 作業が評価されますが、モデルのコンテキスト学習と指示フォロー能力に対してより厳しい要件があります。 実際の評価プロセスでは、一部の対話モデルの回答がコマンド要件を満たしておらず、「0」スコアが発生する場合があります。例えば、指示通りに正解が「A」の場合、モデルが「B」または「答えがA」として生成された場合、スコアは「0」が付与されます。同時に、業界には、対話モデルに最初に「質問+回答」をステッチさせ、モデルが各スプライスされたテキストの確率を計算し、確率が最も高い回答が正解と一致するかどうかを検証し、対話モデルは評価プロセス中にコンテンツを生成せず、オプション確率を計算します。 この評価方法は、実際の対話シナリオから大きく逸脱しているため、生成型対話モデルの評価には採用されていません。[1] それだけでなく、大規模な言語モデルにとって非常に重要な推論能力の観点から、AquilaChat2-34Bのパフォーマンスも非常に素晴らしいです——IRD評価プロトコルでは、Llama2-70BやGPT3.5などのモデルを上回り、GPT4に次ぐ第1位にランクされています。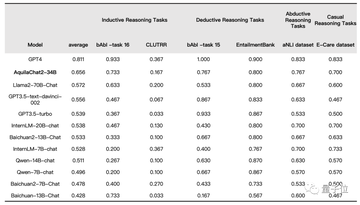 *△図:IRDデータセットにおけるSFTモデルの評価結果*台座モデルであろうと対話モデルであろうと、さまざまな成果の観点から、Aquila2シリーズはオープンソース業界で最強と言えます。**コンテキストウィンドウの長さは最大16K**大規模な言語モデルの場合、長いテキスト入力を処理し、複数回の対話中にコンテキストの流暢さを維持する能力が、エクスペリエンスが良いか悪いかを判断するための鍵となります。「大きなモデルに長い間苦しんでいる」というこの問題を解決するために、北京KLCII人工知能研究所は、200,000の高品質のロングテキストダイアログデータセットでSFTを作成し、モデルの有効なコンテキストウィンドウの長さを一挙に16Kに拡張しました。そして、それは長さの改善だけでなく、効果が最適化されています。たとえば、LongBenchの4つの中国語と英語の長いテキストの質問と回答、長いテキストの要約タスクの評価効果では、それは非常に明白です——AquilaChat2-34B-16Kは、GPT-3.5ロングテキストモデルに近い、オープンソースのロングテキストモデルのリーディングレベルにあります。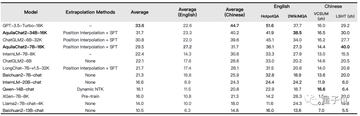 *△図:長文理解タスク評価*さらに、KLCIIのチームは、超長文を処理する複数の言語モデルの注意分布の視覚的分析を実施し、すべての言語モデルに固定された相対位置のボトルネックがあり、コンテキストウィンドウの長さよりも大幅に小さいことを発見しました。この目的のために、KLCIIチームは、RoPE法に基づいて相対位置コーディングを調整し、最大相対長を制約することにより、モデルのエピタキシー能力を向上させるNLPE(非線形化位置埋め込み)法を革新的に提案しました。コード、中国語と英語の少数ショット学習、電子書籍、その他の分野でのテキスト継続実験は、NLPEが4K Aquila2-34Bモデルを32Kの長さに拡張でき、継続テキストの一貫性は、Dynamic-NTK、位置補間、およびその他の方法よりもはるかに優れていることを示しています。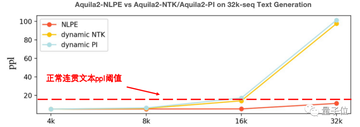 *△図:NLPEと主流のダイナミックNTKエピタキシー法をベースモデルで比較(ppl値が低いほど良い)*それだけでなく、HotpotQA、2WikiMultihopQAおよび5K~15Kの長さの他のデータセットでの命令追従能力テストでは、NLPEエピタキシー後のAquilaChat2-7B(2K)の精度は17.2%であるのに対し、Dynamic-NTK拡張のAquilaChat2-7Bの精度はわずか0.4%であることを示しています。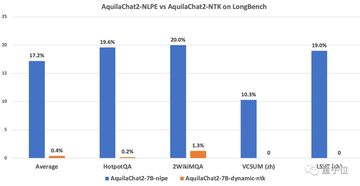 *△図:SFTモデルにおけるNLPEと主流のダイナミックNTKエピタキシャル法の比較* ## あらゆる種類の実際のアプリケーションシナリオを開催できます 良い「結果」は、大規模なモデルをテストするための基準の1つに過ぎず、さらに重要なことに、「良い使用は最後の言葉です」。これは大規模なモデルの汎化能力でもあり、見たことのない問題に遭遇しても簡単に対処できます。この目的のために、Wudao Skyhawkチームは、3つの実際のアプリケーションシナリオを通じてAquila2モデルの汎化能力を検証しました。**マインクラフトで強力なエージェントを構築する**マインクラフトは、AIテストテクノロジーの優れたテストの場となるゲームです。複雑な世界と多数のオープンタスクを無限に生成し、エージェントに豊富な対話インターフェイスを提供します。これに基づいて、KLCIIと北京大学のチームは、専門家のデータなしでMinecraftのマルチタスクを効率的に解決する方法であるPlan4MCを考案しました。Plan4MCは、本質的な報酬を伴う強化学習を使用してエージェントの基本的なスキルをトレーニングできるため、エージェントはタスク計画に大規模言語モデルAquilaChat2の推論能力を使用できます。たとえば、以下のビデオでは、エージェントがAquilaChat2を使用して、対話の複数のラウンドを自動的に完了する効果が示されています。ゲームの「現在の環境状態」と「完了すべきタスク」をAquilaChat2モデルに入力すると、AquilaChat2はキャラクターに「次に使用するスキル」などの意思決定情報をフィードバックし、最終的にMinecraftで設定されたタスク「木を切り、近くに置く作業台を作る」を完了します。**Aquila2+BGE2経由でベクターデータベースをリンク**ベクターデータベースは、近年、大規模なモデルサークルで好まれるようになっていますが、深い理解を必要とする複雑な問題に直面した場合の能力の点ではまだわずかに伸びています。この目的のために、KLCIIはAqiula2と自社開発のオープンソースセマンティックベクトルモデルBGE2を組み合わせて、従来のベクトルライブラリのみに基づく検索方法では解決できない複雑な検索タスクを完全に解き放ちました。例えば、以下の例では、「あるトピックに関する著者の論文を取得する」や「1つのトピックに関する複数の論文の要約テキストを生成する」などのタスクが非常に面倒になる可能性があることがはっきりとわかります。最適な「テキストSQL言語」生成モデル多くのユーザーは、データベースクエリなどのタスクを処理するときにSQLに頭痛の種を持っています。私たちがよく使う言葉で操作できたら美しいと思いませんか?今、この便利な方法は可能です - AquilaSQL。実際のアプリケーションシナリオでは、ユーザーはAquilaSQLに基づく二次開発を実行し、ローカルナレッジベースに移植し、ローカルクエリSQLを生成し、モデルのデータ分析パフォーマンスをさらに向上させることで、モデルがクエリ結果を返すだけでなく、分析の結論とチャートをさらに生成することもできます。たとえば、次の複雑なクエリ タスクを処理する場合、自然言語を話すだけで済みます。自動車販売 (車\_sales) と車の色 (車\_color) を含む 2 つのデータ テーブルから、売上が 100 を超え、赤色の車をフィルター処理します。 そして、AquilaSQLの「成果」も非常に印象的です。継続的な事前トレーニングとSQLコーパスによるSFTの2段階トレーニングの後、CspiderのSOTAモデルは最終的に67.3%の精度で「テキストSQL言語生成モデル」ランキングを上回りました。SQLコーパスの微調整を行わないGPT4モデルの精度はわずか30.8%です。 ##ファミリーバケットレベルのオープンソースもあります 先に述べたように、KLCIIは常にオープンソースに焦点を合わせてきました。今回、大規模なモデルアップグレードの際に、KLCIIはアルゴリズム、データ、ツール、評価を含む一連のスタープロジェクトも無条件にオープンソース化しました。Aquila2シリーズモデルは、商用ライセンス契約を完全に採用しているだけでなく、一般の人々が学術研究や商用アプリケーションで広く使用できるようにすることも理解されています。次に、これらのオープンソースファミリーバケットを簡単に見てみましょう。効率的な並列トレーニングフレームワークであるフラグスケールFlagScale は Aquila2-34B で使用される効率的な並列トレーニングフレームワークで、大規模な言語モデルに対してワンストップのトレーニング機能を提供できます。KLCIIのチームは、FlagScaleプロジェクトを通じてAquila2モデルのトレーニング構成、最適化スキーム、ハイパーパラメータを大規模なモデル開発者と共有し、中国で初めてトレーニングコードとハイパーパラメータを完全にオープンソース化しました。Megatron-LM拡張機能に基づくFlagScaleは、分散オプティマイザーの状態スライス、トレーニング問題データの正確な配置、パラメーターからハギングフェイスへの変換など、さまざまな機能強化を提供します。Aquila2は、業界をリードするトレーニングスループットとGPU使用率を達成するために測定されています。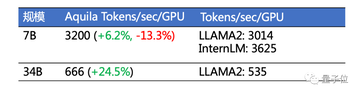 *△図:FlagScaleのトレーニングスループットとGPU使用率(データソースと推定式については記事の終わりを参照)*将来的には、FlagScaleはアップストリームプロジェクトMegatron-LMの最新コードと同期し続け、よりカスタマイズされた機能を導入し、最新の分散トレーニングおよび推論テクノロジーを統合し、大規模モデルを主流にし、異種AIハードウェアをサポートし、さまざまな規模とニーズのモデルトレーニングタスクを満たすために、一般的で便利で効率的な分散大規模モデルトレーニング推論フレームワークの構築に努めることが理解されています。**フラグアテンションハイパフォーマンスアテンションオープンソースサブセット**FlagAttention は、長いテキストの大規模モデルのトレーニングをサポートするために Triton 言語を使用して開発された最初の高性能 Attention オープンソース コンピューティング サブセットであり、Flash Attention シリーズのメモリ効率アテンション演算子を拡張して、大規模モデルのトレーニングのニーズを満たすことができます。現在、セグメント化された注意演算子である区分的注意が実装されています。PiecewiseAttentionは、主に回転位置コーディング(ロフォーマ)を使用してトランスフォーマーモデルの外挿問題を解決し、その特性は次のように要約できます。汎用性:セグメント化されたコンピューティングの注意を使用するモデルとの共通性は、Aquila以外の大規模な言語モデルに簡単に移行できます。使いやすさ:FlagAttentionはTriton言語の実装に基づいており、PyTorchインターフェイスを提供するため、CUDA Cによって開発されたFlash Attentionよりもビルドとインストールのプロセスが容易になります。拡張性:また、Triton言語のおかげで、FlagAttentionアルゴリズム自体は変更と拡張のしきい値が低く、開発者はこれに加えてより多くの新機能を簡単に拡張できます。将来的には、FlagAttentionプロジェクトは、大規模なモデル研究のニーズに対応する他の機能拡張でアテンションオペレーターをサポートし続け、オペレーターのパフォーマンスをさらに最適化し、より異種AIハードウェアに適応します。BGE2次世代セマンティックベクトルモデル**新世代のBGEセマンティックベクターモデルもAquila2でオープンソースになります。BGE2のBGE-LLMエンベッダーモデルは、「知識検索」、「メモリ検索」、「サンプル検索」、「ツール検索」の4つの機能を統合しています。大規模な言語モデルの主な検索要件を単一の意味ベクトルモデルで包括的にカバーすることを初めて実現しました。BGE-LLM Embedderは、特定のユースケースと組み合わせることで、知識集約型タスクの処理、長期記憶、指示フォロー、ツールの使用などの重要な分野で、大規模な言語モデルのパフォーマンスを大幅に向上させます。......それで、あなたはそのような徹底的な「最強のオープンソース」に興奮していますか? ## もう一つ KLCIIは、10月28〜29日に大型モデルの最先端技術に関する新しいワークショップを開催し、9人の主要な研究者がFlagOpenの最近の進捗状況と実装を紹介します。関心のあるパートナーもコードに住むことができます。Aquila2モデルの完全なオープンソースアドレス:AquilaSQLオープンソースリポジトリアドレス:フラグアテンションオープンソースリポジトリ:BGE2オープンソースアドレス紙:モデル: /llm-embedderレポ:LLAMA2スループット推定式:合計トークン/(合計GPU時間\ * 3600)、Llama 2:Open Foundationおよび微調整されたチャットモデル論文によると:1)7Bの合計トークンは2.0 T、合計GPU時間は184320であり、式に代入すると3014トークン/秒/ GPUが得られます。 2)34Bの合計トークンは2.0 T、合計GPU時間は1038336、式は535トークン/秒/ GPUを取得するように置き換えられます。— 終わり —
オープンソースベンチマーク! 最強の中国語と英語のバイリンガルビッグモデルがここにあり、340億のパラメーターがあり、Llama2-70Bなどのすべてのオープンソースモデルを上回っています
著者:ジンレイ
ソース: 量子ビット
オープンソースの世界で最強の中国語と英語のバイリンガルモデル、Wudao Skyhawk 34Bがここにあります!
それはどれくらい強いですか? 一言で言えば:
中国語と英語の総合能力、論理的推論能力などは、Llama2-70Bと以前のすべてのオープンソースモデルを包括的に上回ります!
推論能力の面では、対話モデルのIRD評価ベンチマークはGPT4に次ぐものです。
モデルは戦うのに十分な大きさであるだけでなく、「ファミリーバレル」レベルの高級周辺機器の完全なセットを一度に送信します。
このような大きな問題を抱えることができるのは、中国の大規模モデルオープンソーススクールであるKLCII研究所のパイオニアです。
KLCIIの長年にわたる大規模モデルのオープンソースアプローチを見ると、それが新しいトレンドをリードしていることを見つけるのは難しくありません。
早くも2021年に世界最大のコーパスが公開され、2022年にはFlagOpen大規模モデルテクノロジーオープンソースシステムを最初に転送し、Flag評価システム、COIGデータセット、BGEベクターモデル、その他のフルテクノロジースタックスタープロジェクトを次々と立ち上げました。
この大胆さは、KLCIIが非営利、非営利、中立の研究機関として位置付けていることから来ており、その主な焦点は「誠実なオープンソースの共創」です。
Aquila2-34Bペデスタルモデルは、言語、理解、推論、コード、試験、その他の評価次元を含む22の評価ベンチマークの包括的なランキングをリードしていると理解されています。
この気持ちを感じるための写真は次のとおりです。
今述べたように、北京KLCII人工知能研究所も非常に誠実にオープンソースを最後まで実装し、オープンソースを家族全員に一度に提供します。
Aquila2モデルシリーズを完全にアップグレードします:Aquila2-34B / 7B基本モデル、AquilaChat2-34B / 7Bダイアログモデル、AquilaSQL「テキストSQL言語」モデル。
セマンティックベクターモデルBGEの新しいバージョンがアップグレードされ、4つの主要な検索要件がすべてカバーされています。
FlagScaleの効率的な並列トレーニングフレームワーク:業界をリードするトレーニングスループットとGPU使用率。
FlagAttention 高性能アテンションサブセット:ロングテキストトレーニングとトリトン言語の革新的なサポート。
次に、今回は「最強のオープンソース」について詳しく見ていきましょう。
「最強のオープンソース」機能の概要
先ほど述べたように、「最強のオープンソース」ポーズで開いた台座モデルの1つであるAquila2-34Bには、より小さなAquila2-7Bも含まれています。
そして、これら2つの到着はまた、ダウンストリームモデルを非常に有益にします。
最強のオープンソース対話モデル
命令を微調整した後、優れたAquilaChat2ダイアログモデルシリーズが得られました。
AquilaChat2-34B:これは、主観的+客観的な包括的な評価をリードする、最強のオープンソースの中国語と英語のバイリンガル対話モデルです。
AquilaChat2-7B:同じ規模の中国語-英語対話モデルで最高の全体的なパフォーマンスパフォーマンスも達成しました。
レビューの説明:
生成対話モデルについては、KLCIIチームは、ユーザーの実際のユースケースに近い「質問入力下で自由に生成されたモデルの回答」に従って厳密に判断する必要があると考えていますので、スタンフォード大学のHELMを参照してください[1] 作業が評価されますが、モデルのコンテキスト学習と指示フォロー能力に対してより厳しい要件があります。 実際の評価プロセスでは、一部の対話モデルの回答がコマンド要件を満たしておらず、「0」スコアが発生する場合があります。
例えば、指示通りに正解が「A」の場合、モデルが「B」または「答えがA」として生成された場合、スコアは「0」が付与されます。
同時に、業界には、対話モデルに最初に「質問+回答」をステッチさせ、モデルが各スプライスされたテキストの確率を計算し、確率が最も高い回答が正解と一致するかどうかを検証し、対話モデルは評価プロセス中にコンテンツを生成せず、オプション確率を計算します。 この評価方法は、実際の対話シナリオから大きく逸脱しているため、生成型対話モデルの評価には採用されていません。
[1]
それだけでなく、大規模な言語モデルにとって非常に重要な推論能力の観点から、AquilaChat2-34Bのパフォーマンスも非常に素晴らしいです——
IRD評価プロトコルでは、Llama2-70BやGPT3.5などのモデルを上回り、GPT4に次ぐ第1位にランクされています。
台座モデルであろうと対話モデルであろうと、さまざまな成果の観点から、Aquila2シリーズはオープンソース業界で最強と言えます。
コンテキストウィンドウの長さは最大16K
大規模な言語モデルの場合、長いテキスト入力を処理し、複数回の対話中にコンテキストの流暢さを維持する能力が、エクスペリエンスが良いか悪いかを判断するための鍵となります。
「大きなモデルに長い間苦しんでいる」というこの問題を解決するために、北京KLCII人工知能研究所は、200,000の高品質のロングテキストダイアログデータセットでSFTを作成し、モデルの有効なコンテキストウィンドウの長さを一挙に16Kに拡張しました。
そして、それは長さの改善だけでなく、効果が最適化されています。
たとえば、LongBenchの4つの中国語と英語の長いテキストの質問と回答、長いテキストの要約タスクの評価効果では、それは非常に明白です——
AquilaChat2-34B-16Kは、GPT-3.5ロングテキストモデルに近い、オープンソースのロングテキストモデルのリーディングレベルにあります。
さらに、KLCIIのチームは、超長文を処理する複数の言語モデルの注意分布の視覚的分析を実施し、すべての言語モデルに固定された相対位置のボトルネックがあり、コンテキストウィンドウの長さよりも大幅に小さいことを発見しました。
この目的のために、KLCIIチームは、RoPE法に基づいて相対位置コーディングを調整し、最大相対長を制約することにより、モデルのエピタキシー能力を向上させるNLPE(非線形化位置埋め込み)法を革新的に提案しました。
コード、中国語と英語の少数ショット学習、電子書籍、その他の分野でのテキスト継続実験は、NLPEが4K Aquila2-34Bモデルを32Kの長さに拡張でき、継続テキストの一貫性は、Dynamic-NTK、位置補間、およびその他の方法よりもはるかに優れていることを示しています。
それだけでなく、HotpotQA、2WikiMultihopQAおよび5K~15Kの長さの他のデータセットでの命令追従能力テストでは、NLPEエピタキシー後のAquilaChat2-7B(2K)の精度は17.2%であるのに対し、Dynamic-NTK拡張のAquilaChat2-7Bの精度はわずか0.4%であることを示しています。
あらゆる種類の実際のアプリケーションシナリオを開催できます
良い「結果」は、大規模なモデルをテストするための基準の1つに過ぎず、さらに重要なことに、「良い使用は最後の言葉です」。
これは大規模なモデルの汎化能力でもあり、見たことのない問題に遭遇しても簡単に対処できます。
この目的のために、Wudao Skyhawkチームは、3つの実際のアプリケーションシナリオを通じてAquila2モデルの汎化能力を検証しました。
マインクラフトで強力なエージェントを構築する
マインクラフトは、AIテストテクノロジーの優れたテストの場となるゲームです。
複雑な世界と多数のオープンタスクを無限に生成し、エージェントに豊富な対話インターフェイスを提供します。
これに基づいて、KLCIIと北京大学のチームは、専門家のデータなしでMinecraftのマルチタスクを効率的に解決する方法であるPlan4MCを考案しました。
Plan4MCは、本質的な報酬を伴う強化学習を使用してエージェントの基本的なスキルをトレーニングできるため、エージェントはタスク計画に大規模言語モデルAquilaChat2の推論能力を使用できます。
たとえば、以下のビデオでは、エージェントがAquilaChat2を使用して、対話の複数のラウンドを自動的に完了する効果が示されています。
ゲームの「現在の環境状態」と「完了すべきタスク」をAquilaChat2モデルに入力すると、AquilaChat2はキャラクターに「次に使用するスキル」などの意思決定情報をフィードバックし、最終的にMinecraftで設定されたタスク「木を切り、近くに置く作業台を作る」を完了します。
Aquila2+BGE2経由でベクターデータベースをリンク
ベクターデータベースは、近年、大規模なモデルサークルで好まれるようになっていますが、深い理解を必要とする複雑な問題に直面した場合の能力の点ではまだわずかに伸びています。
この目的のために、KLCIIはAqiula2と自社開発のオープンソースセマンティックベクトルモデルBGE2を組み合わせて、従来のベクトルライブラリのみに基づく検索方法では解決できない複雑な検索タスクを完全に解き放ちました。
例えば、以下の例では、「あるトピックに関する著者の論文を取得する」や「1つのトピックに関する複数の論文の要約テキストを生成する」などのタスクが非常に面倒になる可能性があることがはっきりとわかります。
最適な「テキストSQL言語」生成モデル
多くのユーザーは、データベースクエリなどのタスクを処理するときにSQLに頭痛の種を持っています。
私たちがよく使う言葉で操作できたら美しいと思いませんか?
今、この便利な方法は可能です - AquilaSQL。
実際のアプリケーションシナリオでは、ユーザーはAquilaSQLに基づく二次開発を実行し、ローカルナレッジベースに移植し、ローカルクエリSQLを生成し、モデルのデータ分析パフォーマンスをさらに向上させることで、モデルがクエリ結果を返すだけでなく、分析の結論とチャートをさらに生成することもできます。
たとえば、次の複雑なクエリ タスクを処理する場合、自然言語を話すだけで済みます。
自動車販売 (車_sales) と車の色 (車_color) を含む 2 つのデータ テーブルから、売上が 100 を超え、赤色の車をフィルター処理します。
継続的な事前トレーニングとSQLコーパスによるSFTの2段階トレーニングの後、CspiderのSOTAモデルは最終的に67.3%の精度で「テキストSQL言語生成モデル」ランキングを上回りました。
SQLコーパスの微調整を行わないGPT4モデルの精度はわずか30.8%です。
##ファミリーバケットレベルのオープンソースもあります
先に述べたように、KLCIIは常にオープンソースに焦点を合わせてきました。
今回、大規模なモデルアップグレードの際に、KLCIIはアルゴリズム、データ、ツール、評価を含む一連のスタープロジェクトも無条件にオープンソース化しました。
Aquila2シリーズモデルは、商用ライセンス契約を完全に採用しているだけでなく、一般の人々が学術研究や商用アプリケーションで広く使用できるようにすることも理解されています。
次に、これらのオープンソースファミリーバケットを簡単に見てみましょう。
効率的な並列トレーニングフレームワークであるフラグスケール
FlagScale は Aquila2-34B で使用される効率的な並列トレーニングフレームワークで、大規模な言語モデルに対してワンストップのトレーニング機能を提供できます。
KLCIIのチームは、FlagScaleプロジェクトを通じてAquila2モデルのトレーニング構成、最適化スキーム、ハイパーパラメータを大規模なモデル開発者と共有し、中国で初めてトレーニングコードとハイパーパラメータを完全にオープンソース化しました。
Megatron-LM拡張機能に基づくFlagScaleは、分散オプティマイザーの状態スライス、トレーニング問題データの正確な配置、パラメーターからハギングフェイスへの変換など、さまざまな機能強化を提供します。
Aquila2は、業界をリードするトレーニングスループットとGPU使用率を達成するために測定されています。
将来的には、FlagScaleはアップストリームプロジェクトMegatron-LMの最新コードと同期し続け、よりカスタマイズされた機能を導入し、最新の分散トレーニングおよび推論テクノロジーを統合し、大規模モデルを主流にし、異種AIハードウェアをサポートし、さまざまな規模とニーズのモデルトレーニングタスクを満たすために、一般的で便利で効率的な分散大規模モデルトレーニング推論フレームワークの構築に努めることが理解されています。
フラグアテンションハイパフォーマンスアテンションオープンソースサブセット
FlagAttention は、長いテキストの大規模モデルのトレーニングをサポートするために Triton 言語を使用して開発された最初の高性能 Attention オープンソース コンピューティング サブセットであり、Flash Attention シリーズのメモリ効率アテンション演算子を拡張して、大規模モデルのトレーニングのニーズを満たすことができます。
現在、セグメント化された注意演算子である区分的注意が実装されています。
PiecewiseAttentionは、主に回転位置コーディング(ロフォーマ)を使用してトランスフォーマーモデルの外挿問題を解決し、その特性は次のように要約できます。
汎用性:セグメント化されたコンピューティングの注意を使用するモデルとの共通性は、Aquila以外の大規模な言語モデルに簡単に移行できます。
使いやすさ:FlagAttentionはTriton言語の実装に基づいており、PyTorchインターフェイスを提供するため、CUDA Cによって開発されたFlash Attentionよりもビルドとインストールのプロセスが容易になります。
拡張性:また、Triton言語のおかげで、FlagAttentionアルゴリズム自体は変更と拡張のしきい値が低く、開発者はこれに加えてより多くの新機能を簡単に拡張できます。
将来的には、FlagAttentionプロジェクトは、大規模なモデル研究のニーズに対応する他の機能拡張でアテンションオペレーターをサポートし続け、オペレーターのパフォーマンスをさらに最適化し、より異種AIハードウェアに適応します。
BGE2次世代セマンティックベクトルモデル**
新世代のBGEセマンティックベクターモデルもAquila2でオープンソースになります。
BGE2のBGE-LLMエンベッダーモデルは、「知識検索」、「メモリ検索」、「サンプル検索」、「ツール検索」の4つの機能を統合しています。
大規模な言語モデルの主な検索要件を単一の意味ベクトルモデルで包括的にカバーすることを初めて実現しました。
BGE-LLM Embedderは、特定のユースケースと組み合わせることで、知識集約型タスクの処理、長期記憶、指示フォロー、ツールの使用などの重要な分野で、大規模な言語モデルのパフォーマンスを大幅に向上させます。
......
それで、あなたはそのような徹底的な「最強のオープンソース」に興奮していますか?
もう一つ
KLCIIは、10月28〜29日に大型モデルの最先端技術に関する新しいワークショップを開催し、9人の主要な研究者がFlagOpenの最近の進捗状況と実装を紹介します。
関心のあるパートナーもコードに住むことができます。
Aquila2モデルの完全なオープンソースアドレス:
AquilaSQLオープンソースリポジトリアドレス:
フラグアテンションオープンソースリポジトリ:
BGE2オープンソースアドレス
紙:
モデル: /llm-embedder
レポ:
LLAMA2スループット推定式:合計トークン/(合計GPU時間\ * 3600)、Llama 2:Open Foundationおよび微調整されたチャットモデル論文によると:1)7Bの合計トークンは2.0 T、合計GPU時間は184320であり、式に代入すると3014トークン/秒/ GPUが得られます。 2)34Bの合計トークンは2.0 T、合計GPU時間は1038336、式は535トークン/秒/ GPUを取得するように置き換えられます。
— 終わり —