 画像ソース:無制限のAIによって生成現在、大規模言語モデル(LLM)は、特に例や中間ステップが与えられた場合、推論タスクで印象的な機能を示しています。 しかし、LLMでは暗黙知に依存する手法が多く、暗黙知が間違っている場合や課題と矛盾する場合、LLMは誤った答えを出します。現在、Google、Mila Institute、およびその他の研究機関の研究者は、LLMに推論ルールを学習させ、仮説から理論(HtT)と呼ばれる新しいフレームワークを提案する新しい方法を共同で模索しています。 この新しいアプローチは、多段階推論を改善するだけでなく、解釈可能性、移転可能性などの利点もあります。 論文住所:数値的および関係的推論問題に関する実験は、HtTが既存の方法を11〜27%高い精度で改善することを示しています。 学習したルールは、同じ問題の異なるモデルまたは異なる形式に転送することもできます。 ## **メソッドの紹介** 要約すると、HtTフレームワークは、従来の機械学習のトレーニングとテストと同様に、帰納的フェーズと演繹的フェーズの2つのフェーズで構成されています。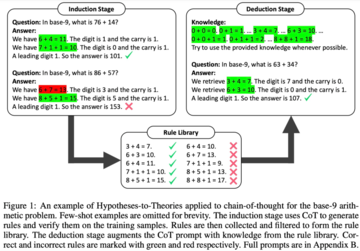 導入フェーズでは、LLMは最初に一連のトレーニング例のルールを生成して検証するように求められます。 この研究では、CoTを使用してルールを宣言して回答を導き出し、ルールの頻度と精度を判断し、頻繁に出現して正解につながるルールを収集してルールベースを形成します。優れたルールベースを使用して、次のステップは、問題を解決するためにこれらのルールを適用する方法を研究することです。 この目的のために、演繹フェーズでは、この研究では、ルールベースを追加し、LLMに推論のためにルールベースからルールを取得するように依頼し、暗黙の推論を明示的な推論に変換します。しかし、この研究では、GPT-4などの非常に強力なLLMでさえ、すべてのステップで適切なルールを取得するのに苦労していることがわかりました。 この目的のために、この研究では、LLMのコンテキスト検索機能を強化するためのXMLタグ付けトリックを開発しました。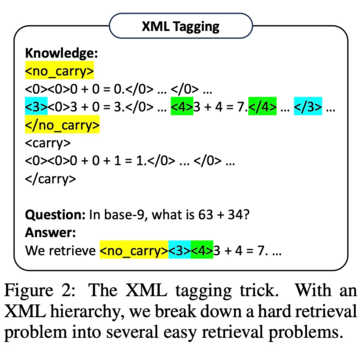 **実験結果**HtTを評価するために、この研究は2つの多段階推論問題に対してベンチマークされました。 実験結果は、HtTがより少ないサンプル法を改善することを示しています。 著者らはまた、HtTのより包括的な理解を提供するために広範なアブレーション研究を実施した。彼らは、数値的および関係的推論問題への新しいアプローチを評価します。 数値的推論では、GPT-4で精度が21.0%向上しました。 関係推論では、GPT-4は精度を13.7%向上させ、GPT-3.5はさらに多くの恩恵を受け、パフォーマンスを2倍にしました。 パフォーマンスの向上は、主に規則性の錯覚の減少からもたらされます。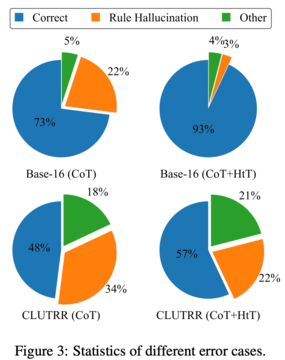 具体的には、以下の表 1 に、基数 16、基数11、および基数9の算術データセットの結果を示します。 すべてのベースシステムの中で、0ショットCoTは両方のLLMで最悪のパフォーマンスを発揮します。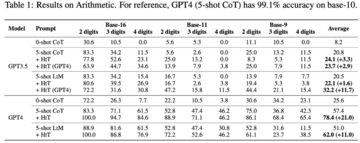 表2は、CLUTRRで異なる方法を比較した結果を示しています。 0ショットCoTはGPT3.5とGPT4で最悪の性能を持っていることがわかります。 少数ショットヒント法の場合、CoTとLtMの性能は類似しています。 平均精度に関しては、HtTは一貫して両方のモデルのキューメソッドを11.1〜27.2%上回っています。 GPT3.5はCLUTRRルールの取得に悪くはなく、おそらくCLUTRRのルールが算術よりも少ないため、GPT4よりもHtTの恩恵を受けていることは注目に値します。GPT4のルールを使用すると、GPT3.5のCoTパフォーマンスは27.2%向上し、CoTパフォーマンスの2倍以上であり、GPT4のCoTパフォーマンスに近いことは言及する価値があります。 したがって、著者らは、HtTが強いLLMから弱いLLMへの新しい形の知識蒸留として役立つことができると信じています。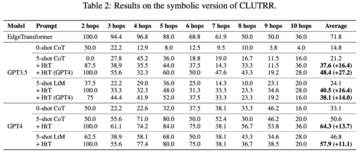 表3は、HtTがGPT-4(テキストバージョン)の性能を大幅に改善することを示しています。 GPT3.5の場合、テキスト入力を処理するときにルールの錯覚以外のエラーが発生することが多いため、この改善は重要ではありません。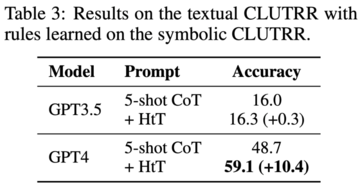 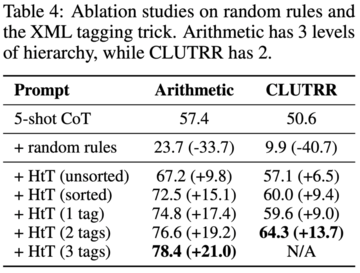
DeepMindを使用すると、大規模なモデルが帰納法と演繹法を学習でき、GPT-4の精度が13.7%向上します
現在、大規模言語モデル(LLM)は、特に例や中間ステップが与えられた場合、推論タスクで印象的な機能を示しています。 しかし、LLMでは暗黙知に依存する手法が多く、暗黙知が間違っている場合や課題と矛盾する場合、LLMは誤った答えを出します。
現在、Google、Mila Institute、およびその他の研究機関の研究者は、LLMに推論ルールを学習させ、仮説から理論(HtT)と呼ばれる新しいフレームワークを提案する新しい方法を共同で模索しています。 この新しいアプローチは、多段階推論を改善するだけでなく、解釈可能性、移転可能性などの利点もあります。
数値的および関係的推論問題に関する実験は、HtTが既存の方法を11〜27%高い精度で改善することを示しています。 学習したルールは、同じ問題の異なるモデルまたは異なる形式に転送することもできます。
メソッドの紹介
要約すると、HtTフレームワークは、従来の機械学習のトレーニングとテストと同様に、帰納的フェーズと演繹的フェーズの2つのフェーズで構成されています。
優れたルールベースを使用して、次のステップは、問題を解決するためにこれらのルールを適用する方法を研究することです。 この目的のために、演繹フェーズでは、この研究では、ルールベースを追加し、LLMに推論のためにルールベースからルールを取得するように依頼し、暗黙の推論を明示的な推論に変換します。
しかし、この研究では、GPT-4などの非常に強力なLLMでさえ、すべてのステップで適切なルールを取得するのに苦労していることがわかりました。 この目的のために、この研究では、LLMのコンテキスト検索機能を強化するためのXMLタグ付けトリックを開発しました。
HtTを評価するために、この研究は2つの多段階推論問題に対してベンチマークされました。 実験結果は、HtTがより少ないサンプル法を改善することを示しています。 著者らはまた、HtTのより包括的な理解を提供するために広範なアブレーション研究を実施した。
彼らは、数値的および関係的推論問題への新しいアプローチを評価します。 数値的推論では、GPT-4で精度が21.0%向上しました。 関係推論では、GPT-4は精度を13.7%向上させ、GPT-3.5はさらに多くの恩恵を受け、パフォーマンスを2倍にしました。 パフォーマンスの向上は、主に規則性の錯覚の減少からもたらされます。
GPT4のルールを使用すると、GPT3.5のCoTパフォーマンスは27.2%向上し、CoTパフォーマンスの2倍以上であり、GPT4のCoTパフォーマンスに近いことは言及する価値があります。 したがって、著者らは、HtTが強いLLMから弱いLLMへの新しい形の知識蒸留として役立つことができると信じています。